Melhorar a qualidade do aplicativo RAG
Este artigo fornece uma visão geral de como você pode refinar cada componente para aumentar a qualidade do seu aplicativo de geração aumentada de recuperação (RAG).
Há uma infinidade de "botões" para ajustar em cada ponto do pipeline de dados offline e da cadeia RAG online. Embora existam inúmeros outros, o artigo se concentra nos botões mais importantes que têm o maior impacto sobre a qualidade do seu aplicativo RAG. O Databricks recomenda começar com esses botões.
Dois tipos de considerações sobre qualidade
De um ponto de vista conceitual, é útil visualizar os botões de qualidade do RAG por meio das lentes dos dois principais tipos de problemas de qualidade:
Qualidade da recuperação: Você está recuperando as informações mais relevantes para uma determinada consulta de recuperação?
É difícil gerar resultados de RAG de alta qualidade se o contexto fornecido ao LLM não tiver informações importantes ou contiver informações supérfluas.
Qualidade da geração: Considerando as informações recuperadas e a consulta original do usuário, o LLM está gerando a resposta mais precisa, coerente e útil possível?
Os problemas aqui podem se manifestar como alucinações, resultados inconsistentes ou falha em abordar diretamente a consulta do usuário.
Os aplicativos RAG têm dois componentes que podem ser iterados para resolver os desafios de qualidade: o pipeline de dados e a cadeia. É tentador supor uma divisão clara entre problemas de recuperação (basta atualizar o pipeline de dados) e problemas de geração (atualizar a cadeia RAG). No entanto, a realidade é mais matizada. A qualidade da recuperação pode ser influenciada tanto pela pipeline de dados (por exemplo, estratégia de análise/divisão, estratégia de metadados, modelo de incorporação) quanto pela cadeia RAG (por exemplo, transformação da consulta do usuário, número de partes recuperados, reclassificação). Da mesma forma, a qualidade da geração será invariavelmente afetada pela recuperação deficiente (por exemplo, informações irrelevantes ou ausentes que afetam a saída do modelo).
Essa sobreposição ressalta a necessidade de uma abordagem holística para a melhoria da qualidade do RAG. Ao compreender quais componentes devem ser alterados no pipeline de dados e na cadeia de RAGs, e como essas alterações afetam a solução geral, é possível fazer atualizações direcionadas para melhorar a qualidade da saída do RAG.
Considerações sobre a qualidade do pipeline de dados
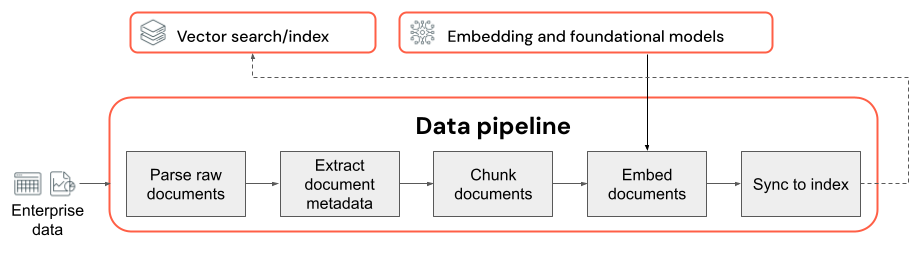
Principais considerações sobre o pipeline de dados:
- A composição do corpus de dados de entrada.
- Como os dados brutos são extraídos e transformados em um formato utilizável (por exemplo, análise de um documento PDF).
- Como os documentos são divididos em partes menores e como essas partes são formatadas (por exemplo, estratégia de divisão em partes e tamanho da parte).
- Os metadados (como título da seção ou título do documento) extraídos sobre cada documento e/ou parte. Como esses metadados são incluídos (ou não incluídos) em cada parte.
- O modelo de incorporação usado para converter texto em representações vetoriais para pesquisa de similaridade.
Cadeia RAG
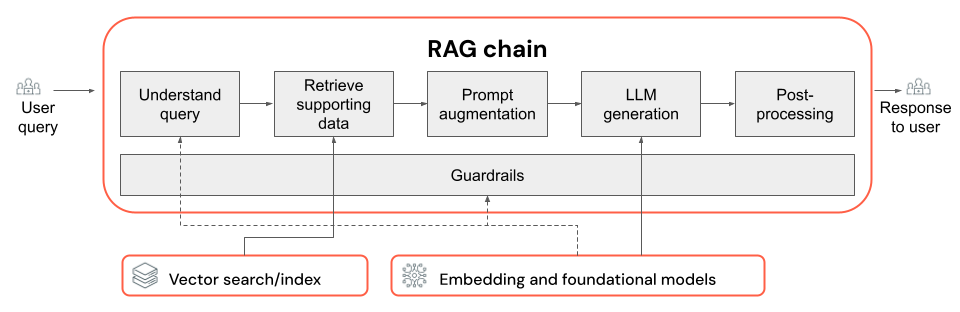
- A escolha do LLM e seus parâmetros (por exemplo, temperatura e tokens máximos).
- Os parâmetros de recuperação (por exemplo, o número de partes ou documentos recuperados).
- A abordagem de recuperação (por exemplo, pesquisa por palavra-chave vs. híbrida vs. semântica, reescrever a consulta do usuário, transformar a consulta do usuário em filtros ou reclassificação).
- Como formatar o prompt com o contexto recuperado para orientar o LLM em direção a um resultado de qualidade.