Melhorar a qualidade do pipeline de dados RAG
Este artigo discute como experimentar as opções de pipeline de dados de um ponto de vista prático na implementação de alterações de pipeline de dados.
Principais componentes do pipeline de dados
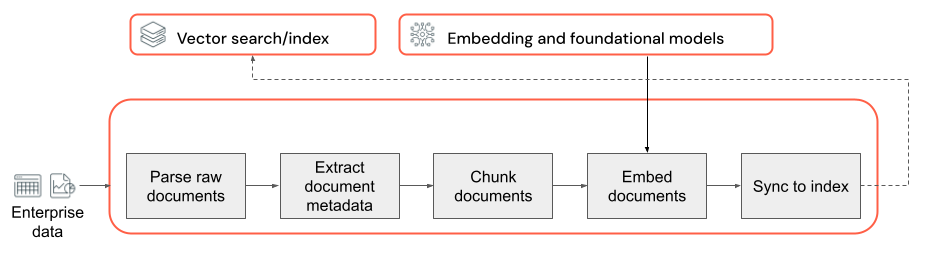
A base de todo aplicativo RAG com dados não estruturados é o pipeline de dados. Esse pipeline é responsável por preparar os dados não estruturados em um formato que possa ser de fato utilizado pelo aplicativo RAG. Embora esse pipeline de dados possa se tornar arbitrariamente complexo, os componentes a seguir são os principais que precisam ser considerados ao criar o aplicativo RAG pela primeira vez:
- Composição de corpus: seleção das fontes de dados e o conteúdo corretos com base no caso de uso específico.
- Análise: extração das informações relevantes dos dados brutos usando técnicas de análise adequadas.
- Agrupamento: divisão dos dados analisados em partes menores e gerenciáveis para recuperação eficiente.
- Inserção: conversão dos dados de texto em partes em uma representação de vetor numérico que captura seu significado semântico.
Composição de corpus
Sem o corpus de dados certo, o aplicativo RAG não pode recuperar as informações necessárias para responder a uma consulta de usuário. Os dados corretos dependem inteiramente dos requisitos e metas específicos do aplicativo, tornando crucial dedicar tempo para entender as nuances dos dados disponíveis (consulte a seção de coleta de requisitos para obter as diretrizes sobre isso).
Por exemplo, ao criar um bot de suporte ao cliente, considere incluir:
- Documentos da base de dados de conhecimento
- Perguntas frequentes (FAQs)
- Manuais e especificações do produto
- Guias de solução de problemas
Envolva especialistas de domínio e stakeholders desde o início de um projeto para ajudar a identificar e coletar conteúdo relevante que possa melhorar a qualidade e a cobertura do seu corpo de dados. Isso pode fornecer insights sobre os tipos de consultas que os usuários provavelmente enviarão e ajudar a priorizar as informações mais importantes a serem incluídas.
Análise
Tendo identificado as fontes de dados para o aplicativo RAG, a próxima etapa é extrair as informações necessárias dos dados brutos. Esse processo, conhecido como análise, envolve a transformação dos dados não estruturados em um formato que pode ser efetivamente utilizado pelo aplicativo RAG.
As técnicas e ferramentas de análise específicas que você usa dependem do tipo de dados com os quais está trabalhando. Por exemplo:
- Documentos de texto (PDFs, documentos do Word): bibliotecas já disponíveis, como as não estruturadas e PyPDF2, podem lidar com vários formatos de arquivo e fornecer opções para personalizar o processo de análise.
- Documentos HTML: bibliotecas de análise HTML como BeautifulSoup podem ser usadas para extrair conteúdo relevante de páginas da Web. Com elas, você pode navegar pela estrutura HTML, selecionar elementos específicos e extrair o texto ou os atributos desejados.
- Imagens e documentos verificados: as técnicas de OCR (reconhecimento óptico de caracteres) normalmente são necessárias para extrair texto de imagens. Bibliotecas de OCR populares incluem Tesseract,Amazon Textract, OCR de Visão da IA do Azure e API do Google Cloud Vision.
Melhores práticas para analisar dados
Ao analisar os dados, considere as seguintes melhores práticas:
- Limpeza de dados: pré-processar o texto extraído para remover toda informação irrelevante ou com ruído, como cabeçalhos, rodapés ou caracteres especiais. Saiba reduzir a quantidade de informações desnecessárias ou malformadas que sua cadeia RAG precisa processar.
- Tratamento de erros e exceções: implementar mecanismos de tratamento de erros e registro em log para identificar e resolver todos os problemas encontrados durante o processo de análise. Isso ajuda a identificar e corrigir problemas rapidamente. Fazer isso geralmente aponta para problemas de upstream com a qualidade dos dados de origem.
- Personalização da lógica de análise: dependendo da estrutura e do formato dos dados, talvez seja necessário personalizar a lógica de análise para extrair as informações mais relevantes. Embora possa exigir esforço adicional antecipadamente, invista nesse tempo, se necessário, isso geralmente evita muitos problemas de qualidade downstream.
- Avaliação da qualidade da análise: avalie regularmente a qualidade dos dados analisados examinando manualmente um exemplo da saída. Isso pode ajudar a identificar todos os problemas ou áreas para aprimoramento no processo de análise.
Agrupamento
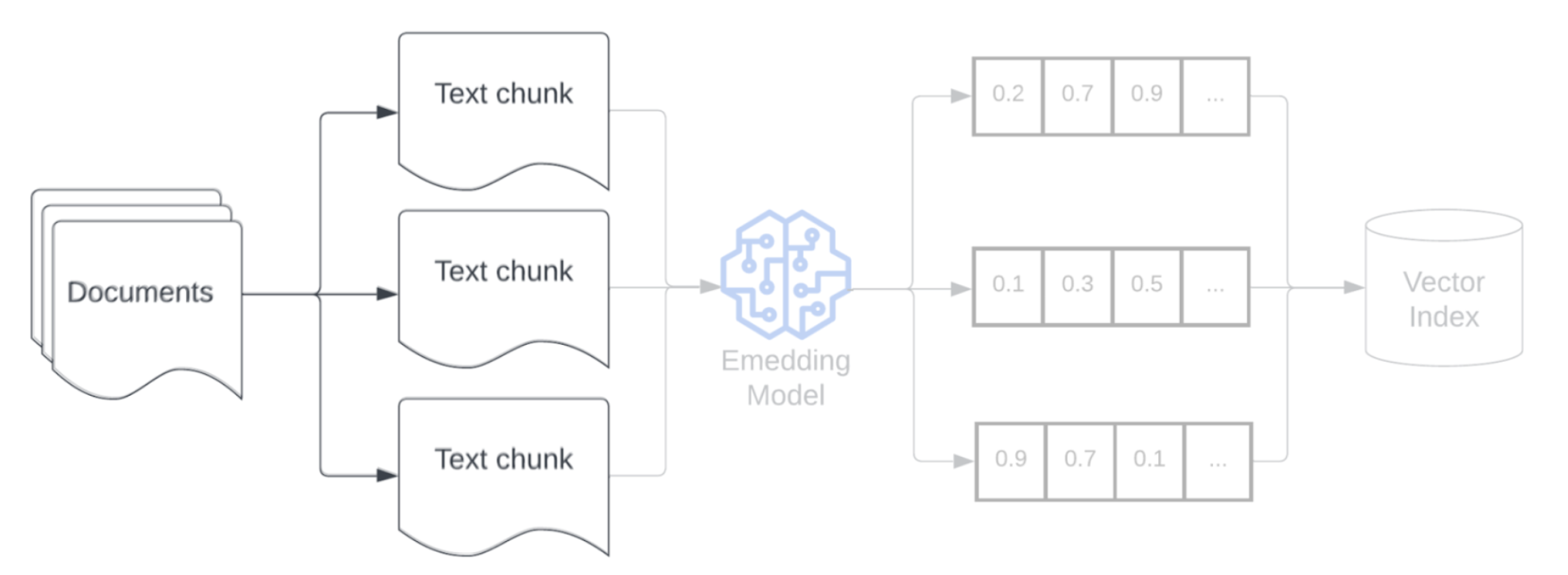
Depois de analisar os dados brutos em um formato mais estruturado, a próxima etapa é dividir isso em unidades menores e gerenciáveis chamadas partes. Segmentar documentos grandes em partes menores e semanticamente concentradas garante que os dados recuperados se ajustem ao contexto da LLM, minimizando a inclusão de informações irrelevantes ou distrativas. As escolhas feitas no agrupamento afetarão diretamente os dados recuperados fornecidos pelo LLM, tornando isso uma das primeiras camadas de otimização em um aplicativo RAG.
Ao agrupar os dados, considere os seguintes fatores:
- Estratégia de agrupamento: o método usado para dividir o texto original em partes. Isso pode envolver técnicas básicas, como divisão por frases, parágrafos ou contagens específicas de caractere/token, até estratégias de divisão específicas de documentos mais avançadas.
- Tamanho da parte: partes menores podem se concentrar em detalhes específicos, mas perder algumas informações ao redor. Partes maiores podem capturar mais contexto, mas também podem incluir informações irrelevantes.
- Sobreposição entre partes: para garantir que informações importantes não sejam perdidas ao dividir os dados em partes, considere incluir alguma sobreposição entre partes adjacentes. A sobreposição pode garantir a continuidade e a preservação do contexto entre as partes.
- Coerência semântica: quando possível, procure criar partes semanticamente coerentes, quer dizer, que elas contêm informações relacionadas e podem ficar por conta própria como uma unidade significativa de texto. Isso pode ser feito considerando a estrutura dos dados originais, como parágrafos, seções ou limites de tópico.
- Metadados: incluir metadados relevantes em cada parte, como o nome do documento de origem, o título da seção ou os nomes do produto, pode melhorar o processo de recuperação. Essas informações adicionais na parte podem ajudar a corresponder consultas de recuperação a partes.
Estratégias de agrupamento de dados
Encontrar o método de agrupamento correto é iterativo e depende de contexto. Não existe uma abordagem de tamanho único. O tamanho e o método de partes ideais dependerão do caso de uso específico e da natureza dos dados que estão sendo processados. No geral, as estratégias de agrupamento podem ser visualizadas como as seguintes:
- Agrupamento de tamanho fixo: dividir o texto em partes de um tamanho predeterminado, como um número fixo de caracteres ou tokens (por exemplo, LangChain CharacterTextSplitter). Embora a divisão por um número arbitrário de caracteres/tokens seja rápida e fácil de configurar, normalmente não resultará em partes consistentes semanticamente coerentes.
- Agrupamento baseado em parágrafo: usar os limites de parágrafo naturais no texto para definir partes. Esse método pode ajudar a preservar a coerência semântica das partes, pois os parágrafos geralmente contêm informações relacionadas (por exemplo, LangChain RecursiveCharacterTextSplitter).
- Agrupamento específico por formato: formatos como markdown ou HTML têm uma estrutura inerente dentro deles que pode ser usada para definir limites de partes (por exemplo, cabeçalhos de markdown). Ferramentas como MarkdownHeaderTextSplitter do LangChain ou divisores baseados em seção de /cabeçalho HTML podem ser usados para essa finalidade.
- Agrupamento semântico: técnicas como modelagem de tópicos podem ser aplicadas para identificar seções semanticamente coerentes no texto. Essas abordagens analisam o conteúdo ou a estrutura de cada documento para determinar os limites de partes mais adequados com base em turnos no tópico. Embora mais envolvido do que abordagens mais básicas, o agrupamento semântico pode ajudar a criar partes mais alinhadas com as divisões semânticas naturais no texto (consulte LangChain SemanticChunker para obter um exemplo disso).
Exemplo: agrupamento do tamanho da correção
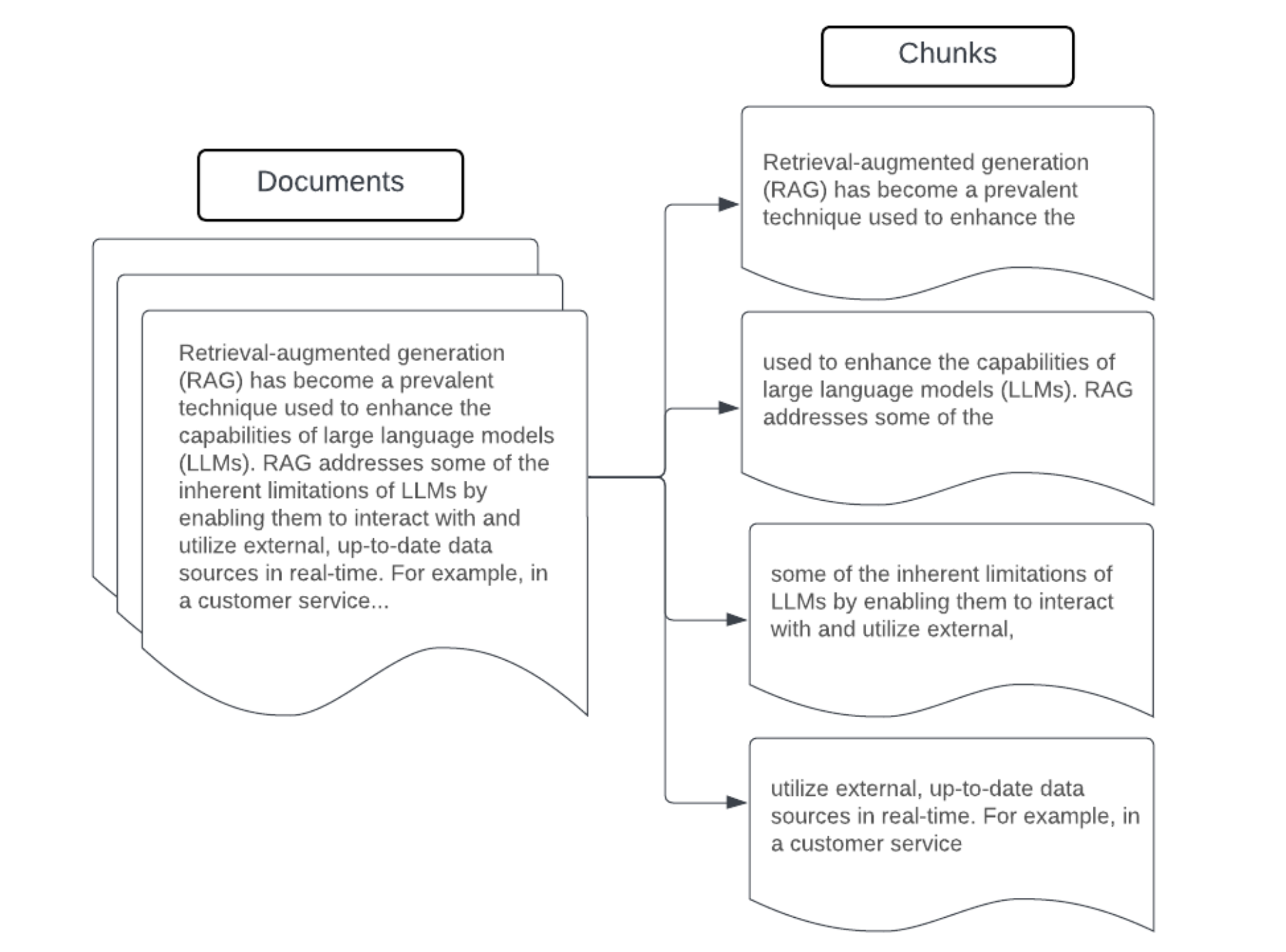
Exemplo de agrupamento de tamanho fixo usando RecursiveCharacterTextSplitter do LangChain com chunk_size=100 e chunk_overlap=20. O ChunkViz fornece uma maneira interativa de visualizar como valores de tamanho de parte e sobreposição de partes diferentes com os divisores de caracteres de Langchain afetam partes resultantes.
Modelo de inserção
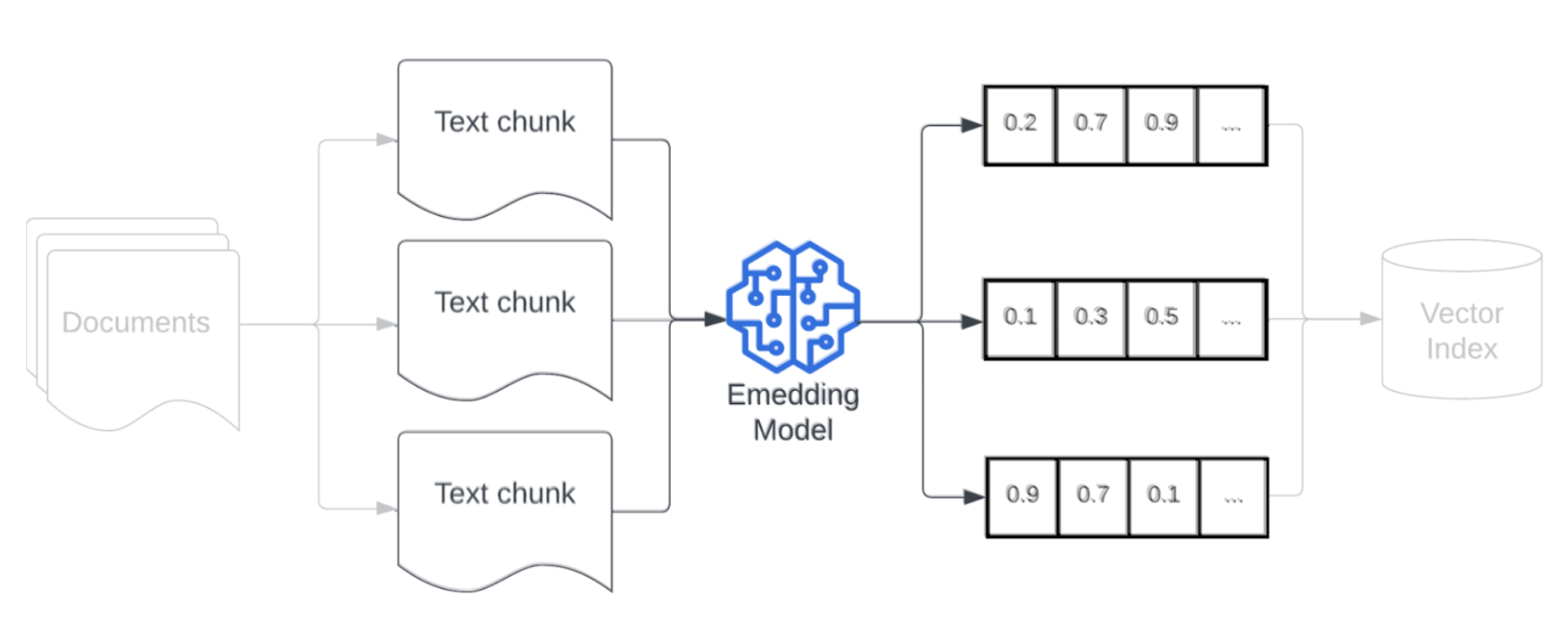
Depois de agrupar os dados, a próxima etapa é converter as partes de texto em uma representação de vetor usando um modelo de inserção. Um modelo de inserção é usado para converter cada parte de texto em uma representação de vetor que captura seu significado semântico. Ao representar partes como vetores densos, as inserções permitem a recuperação rápida e precisa das partes mais relevantes com base em sua semelhança semântica com uma consulta de recuperação. No momento da consulta, a consulta de recuperação será transformada usando o mesmo modelo de inserção usado para inserir partes no pipeline de dados.
Ao selecionar um modelo de inserção, considere os seguintes fatores:
- Escolha do modelo: cada modelo de inserção tem suas nuances, além disso os parâmetros de comparação disponíveis podem não capturar as características específicas dos seus dados. Experimente diferentes modelos de inserção já disponíveis, mesmo aqueles que podem ter uma classificação inferior nos placares de líderes padrão, como MTEB. Alguns exemplos a serem considerados incluem:
- Tokens máximos: verifique o limite máximo de token para o modelo de inserção escolhido. Se você passar partes que excederem esse limite, elas serão truncadas, potencialmente perdendo informações importantes. Por exemplo, bge-large-en-v1.5 tem um limite máximo de token de 512.
- Tamanho do modelo: modelos de inserção maiores geralmente oferecem melhor desempenho, mas exigem mais recursos computacionais. Encontre um equilíbrio entre desempenho e eficiência com base em seu caso de uso específico e recursos disponíveis.
- Ajuste fino: se o aplicativo RAG lida com linguagem específica do domínio (por exemplo, acrônimos internos da empresa ou terminologia), considere ajustar o modelo de inserção em dados específicos do domínio. Isso pode ajudar o modelo a capturar melhor as nuances e a terminologia de seu domínio específico e geralmente pode levar a um melhor desempenho de recuperação.