Tutorial: executar um arquivo Python em um cluster e como um trabalho, usando a extensão do Databricks para Visual Studio Code
Este tutorial demonstra como configurar a extensão do Databricks para Visual Studio Code e como executar o Python em um cluster do Azure Databricks como um trabalho do Azure Databricks no workspace remoto. Confira O que é a extensão do Databricks para Visual Studio Code?.
Requisitos
Este tutorial exige que:
- Você instalou a extensão do Databricks para o Visual Studio Code. Confira Instalar a extensão do Databricks para Visual Studio Code.
- Você tem um cluster remoto do Azure Databricks para usar. Anote o nome do cluster. Para exibir os clusters disponíveis, na barra lateral do workspace do Azure Databricks, clique em Computação. Consulte Computação.
Etapa 1: Criar um novo projeto do Databricks
Nesta etapa, você cria um novo projeto do Databricks e configura a conexão com seu workspace remoto do Azure Databricks.
- Inicie o Visual Studio Code, clique em Arquivo > Abrir Pasta e abra uma pasta vazia em seu computador de desenvolvimento local.
- Na barra lateral, clique no ícone do logotipo do Databricks. Isso abrirá a extensão do Databricks.
- Na exibição Configuração, clique em Migrar para um Projeto do Databricks.
- A Paleta de Comandos para configurar o workspace do Databricks é aberta. Para Host do Databricks, insira ou selecione sua URL por workspace, por exemplo
https://adb-1234567890123456.7.azuredatabricks.net. - Selecione um perfil de autenticação para o projeto. Confira Configuração de autenticação da extensão do Databricks para Visual Studio Code.
Etapa 2: Adicionar informações do cluster à extensão do Databricks e iniciar o cluster
Com a exibição Configuração já aberta, clique em Selecionar um cluster ou no ícone de engrenagem (Configurar cluster).
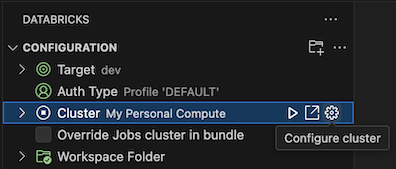
Na Paleta de Comandos, selecione o nome do cluster que você criou anteriormente.
Clique no ícone de reprodução (Iniciar cluster) se ainda não tiver sido iniciado.
Etapa 3: Criar e executar o código Python
Crie um arquivo de código Python local: na barra lateral, clique no ícone da pasta (Explorer).
No menu principal, clique em Arquivo > Novo Arquivo. Nomeie o arquivo demo.py e salve-o na raiz do projeto.
Adicione o código a seguir ao arquivo e salve-o. Esse código cria e exibe o conteúdo de um DataFrame PySpark básico:
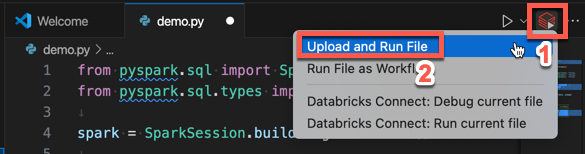
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show() # Output: # # +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Clique no ícone Executar no Databricks ao lado da lista de guias do editor e clique em Carregar e Executar Arquivo. A saída aparece na exibição Console de Depuração.
Como alternativa, na exibição do Gerenciador, clique com o botão direito do mouse no arquivo
demo.pye, em seguida, clique em Executar no Databricks>Carregar e Executar Arquivo.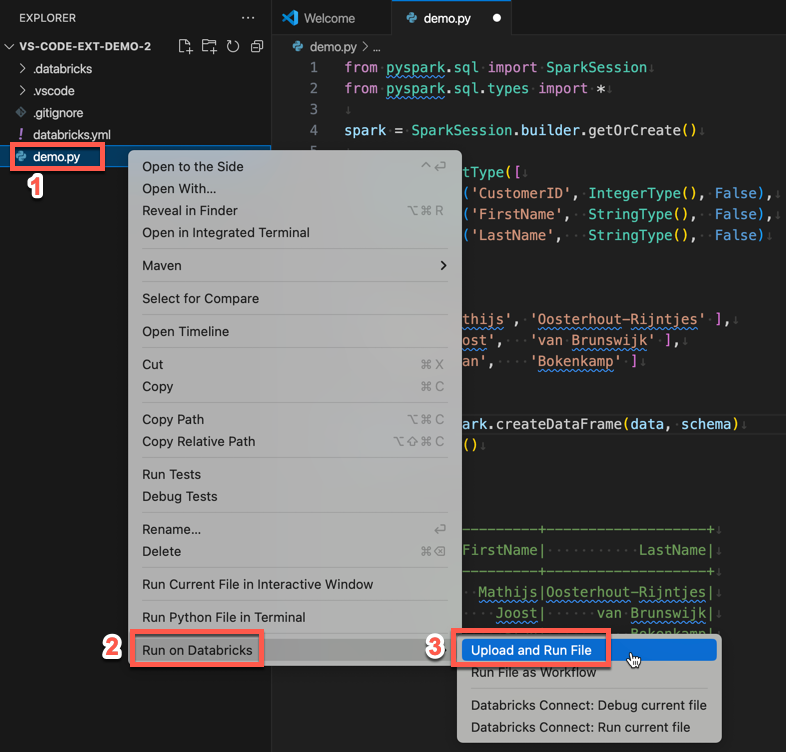
Etapa 4: Executar o código como um trabalho
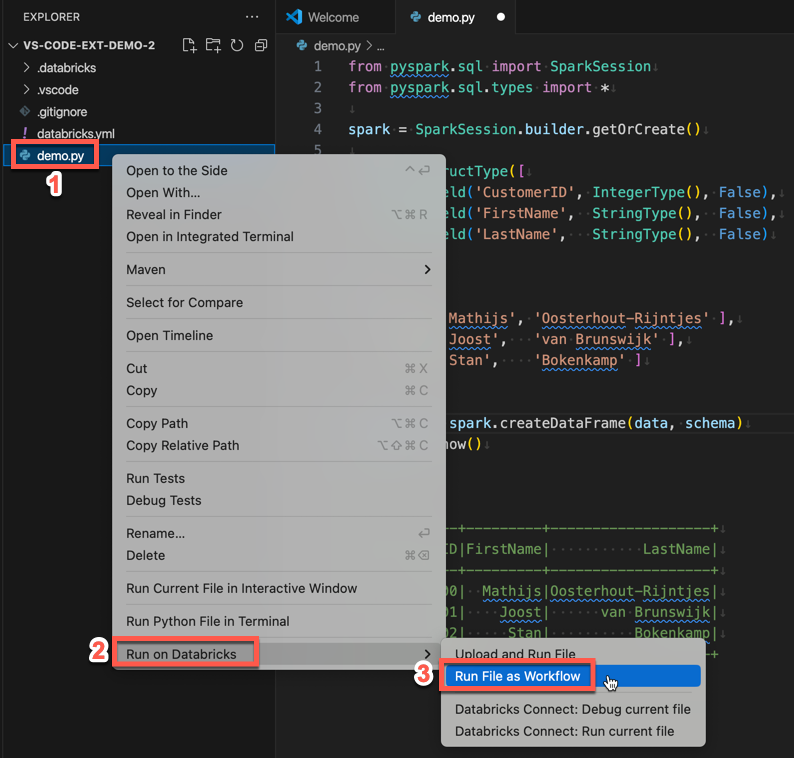
Para executar demo.py como um trabalho, clique no ícone Executar no Databricks ao lado da lista de guias do editor e clique em Executar Arquivo como Fluxo de Trabalho. A saída aparece em uma guia de editor separada próxima ao editor de arquivos demo.py.
![]()
Como alternativa, clique com o botão direito do mouse no arquivo demo.py no painel Gerenciador e selecione Executar no Databricks>Executar Arquivo como Fluxo de Trabalho.
Próximas etapas
Agora que você usou com sucesso a extensão do Databricks para o Visual Studio Code para carregar um arquivo Python local e executá-lo remotamente, você também pode:
- Explore os recursos e as variáveis dos Pacotes de Ativos do Databricks usando a interface do usuário da extensão. Confira Recursos de extensão dos Pacotes de Ativos do Databricks.
- Executar ou depurar código Python com o Databricks Connect. Confira Depurar código usando o Databricks Connect da extensão do Databricks para Visual Studio Code.
- Execute um arquivo ou um notebook como um trabalho do Azure Databricks. Consulte Executar um arquivo em um cluster, um arquivo ou um notebook como um trabalho usando a extensão do Databricks para Visual Studio Code.
- Execute testes com o
pytest. Confira Executar testes com o pytest para a extensão do Databricks para Visual Studio Code.