Use o Azure Data Share para compartilhar dados com o Azure Data Explorer
Há muitas maneiras tradicionais de compartilhar dados, como por meio de compartilhamentos de arquivos, FTP, email e APIs. Esses métodos exigem que ambas as partes criem e mantenham um pipeline de dados que move dados entre equipes e organizações. Com o Azure Data Explorer, você pode compartilhar seus dados de maneira fácil e segura com pessoas da sua empresa ou com parceiros externos. O compartilhamento ocorre quase em tempo real, sem a necessidade de criar ou manter um pipeline de dados. Todas as alterações feitas do banco de dados no lado do provedor, incluindo o esquema e os dados, são disponibilizadas instantaneamente no lado do consumidor.

O Azure Data Explorer dissocia o armazenamento e a computação, o que permite que os clientes executem várias instâncias de computação (somente leitura) no mesmo armazenamento subjacente. Você pode anexar um banco de dados como um banco de dados seguidor, que é um banco de dados somente leitura em um cluster remoto.
Configurar o compartilhamento de dados
Use o Azure Data Share para enviar e gerenciar convites e compartilhamentos em toda a empresa ou com parceiros e clientes externos. O Azure Data Share usa um banco de dados seguidor para criar um link simbólico entre o cluster do provedor e o cluster do Azure Data Explorer do consumidor. Essa opção fornece apenas um painel para exibir e gerenciar todos os seus compartilhamentos de dados entre clusters do Azure Data Explorer e outros serviços de dados. O Azure Data Share também permite que você compartilhe dados entre organizações em diferentes locatários do Microsoft Entra.
Observação
Um administrador em ambos os clusters pode configurar diretamente o banco de dados seguidor com várias APIs. Isso é útil em cenários em que você precisa de computação adicional para escalar horizontalmente para relatórios.
Você pode configurar o compartilhamento de dados para o seguinte:
- O banco de dados inteiro (padrão).
- Tabelas específicas – compartilhamento em nível de tabela.
Observação
Quando uma relação de compartilhamento é estabelecida, o Azure Data Share cria um link simbólico entre os clusters do Azure Data Explorer do provedor e do consumidor. Se o provedor de dados revogar o acesso, o link simbólico será excluído e os bancos de dados compartilhados não ficarão mais disponíveis para o consumidor.
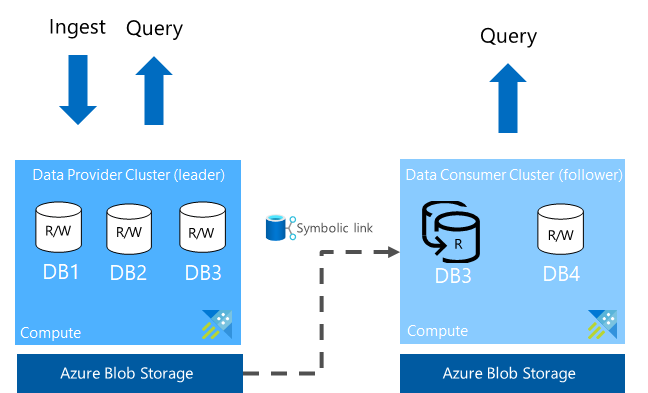
O provedor de dados pode compartilhar os dados no nível do banco de dados ou no nível do cluster. O cluster que compartilha o banco de dados é o cluster líder e o cluster que recebe o compartilhamento é o cluster seguidor. Um cluster seguidor pode seguir um ou mais bancos de dados do cluster líder. O cluster seguidor periodicamente sincroniza para verificar se há alterações. O atraso entre o líder e o seguidor varia de alguns segundos a alguns minutos, dependendo do tamanho geral dos metadados e dos dados. Os dados são armazenados em cache no cluster do consumidor e só estão disponíveis para operações de leitura ou consulta, com uma exceção para substituir a política de cache quente e as permissões de banco de dados. As consultas em execução no cluster seguidor usam o cache local e não usam os recursos do cluster líder.
Pré-requisitos
- Uma assinatura do Azure. Criar uma conta gratuita do Azure.
- Um cluster do Azure Data Explorer e um banco de dados para o líder e o seguidor. Criar um cluster e um banco de dados.
- O banco de dados líder deve conter dados. Você pode ingerir dados usando um dos métodos discutidos na visão geral da ingestão.
Fluxo de compartilhamento de dados
- O provedor usa o recurso do Azure Data Share para compartilhar um banco de dados completo ou uma tabela específica e especificar o endereço de email do destinatário.
- O Azure Data Share envia um convite por email para o destinatário.
- O destinatário abre o convite por email e seleciona o recurso do Azure Data Share.
- O destinatário usa o Azure Data Share para mapear a tabela ou o banco de dados compartilhado para o cluster apropriado.
Provedor de dados – compartilha dados
O provedor de dados pode compartilhar um banco de dados completo ou uma tabela específica com o destinatário.
Como compartilhar um banco de dados completo
Siga as instruções no vídeo para criar uma conta do Azure Data Share, adicionar um conjunto de dados e enviar um convite.
Como compartilhar tabelas
Você pode usar um modelo do Azure Resource Manager para compartilhar uma ou mais tabelas por meio do Azure Data Share.
Use as seguintes etapas para compartilhar tabelas:
Crie um modelo e defina os parâmetros apropriados no conjunto de dados e as restrições de tabela e especifique o destinatário do convite. Use as informações na tabela a seguir para ajudar você a configurar o modelo.
Parâmetro Descrição Exemplo accountName O nome da conta do Azure Data Share do provedor. local A localização de todos os recursos. O líder e o seguidor devem estar na mesma localização. shareName O nome do compartilhamento que será criado na conta de compartilhamento de dados. recipientEmail O email do destinatário do Azure Data Share. databaseName O nome do banco de dados do provedor. databaseResourceId A ID de recurso do banco de dados do provedor. externalTablesToExclude A lista de tabelas externas a serem excluídas. Para excluir todas as tabelas externas, use ["*"]. ["ExternalTable1ToExclude", "ExternalTable2ToExclude"]externalTablesToInclude A lista de tabelas externas a serem incluídas. Para incluir todas as tabelas externas que começam com 'Logs', use ["Logs*"]. ["ExternalTable1ToInclude", "ExternalTable2ToInclude"]materializedViewsToExclude A lista de exibições materializadas a serem excluídas. Para excluir todas as exibições materializadas, use ["*"]. ["Mv11ToExclude", "Mv22ToExclude"]materializedViewsToInclude A lista de exibições materializadas a serem incluídas. Para incluir todas as exibições materializadas que começam com 'Logs', use ["Logs*"]. ["Mv1ToInclude", "Mv2ToInclude"]tablesToExclude A lista de tabelas a serem excluídas. Para excluir todas as tabelas, use ["*"]. ["table1ToExclude", "table2ToExclude"]tablesToInclude A lista de tabelas a serem incluídas. Para excluir todas as tabelas, use ["*"]. ["table1ToInclude", "table2ToInclude"]{ "$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#", "contentVersion": "1.0.0.0", "parameters": { "accountName": { "type": "String" }, "location": { "defaultValue": "[resourceGroup().location]", "type": "String" }, "shareName": { "type": "String" }, "recipientEmail": { "type": "String" }, "databaseName": { "type": "String" }, "databaseResourceId": { "type": "String" }, "externalTablesToExclude": { "type": "Array" }, "externalTablesToInclude": { "type": "Array" }, "materializedViewsToExclude": { "type": "Array" }, "materializedViewsToInclude": { "type": "Array" }, "tablesToExclude": { "type": "Array" }, "tablesToInclude": { "type": "Array" } }, "variables": { "invitationSuffix": "[replace(replace(parameters('recipientEmail'),'@', '_'), '.', '_')]" }, "resources": [ { "type": "Microsoft.DataShare/accounts", "apiVersion": "2021-08-01", "name": "[parameters('accountName')]", "location": "[parameters('location')]", "identity": { "type": "SystemAssigned" }, "properties": {} }, { "type": "Microsoft.DataShare/accounts/shares", "apiVersion": "2021-08-01", "name": "[concat(parameters('accountName'), '/' , parameters('shareName'))]", "dependsOn": [ "[resourceId('Microsoft.DataShare/accounts', parameters('accountName'))]" ], "properties": { "shareKind": "InPlace" } }, { "type": "Microsoft.DataShare/accounts/shares/invitations", "apiVersion": "2021-08-01", "name": "[concat(parameters('accountName'), '/', parameters('shareName'), '/', concat(parameters('shareName'), variables('invitationSuffix')))]", "dependsOn": [ "[resourceId('Microsoft.DataShare/accounts/shares', parameters('accountName'), parameters('shareName'))]", "[resourceId('Microsoft.DataShare/accounts', parameters('accountName'))]" ], "properties": { "targetEmail": "[parameters('recipientEmail')]" } }, { "type": "Microsoft.DataShare/accounts/shares/dataSets", "apiVersion": "2021-08-01", "name": "[concat(parameters('accountName'), '/', parameters('shareName'), '/', parameters('databaseName'))]", "dependsOn": [ "[resourceId('Microsoft.DataShare/accounts/shares', parameters('accountName'), parameters('shareName'))]", "[resourceId('Microsoft.DataShare/accounts', parameters('accountName'))]" ], "kind": "KustoTable", "properties": { "kustoDatabaseResourceId": "[parameters('databaseResourceId')]", "tableLevelSharingProperties": { "externalTablesToExclude": "[parameters('externalTablesToExclude')]", "externalTablesToInclude": "[parameters('externalTablesToInclude')]", "materializedViewsToExclude": "[parameters('materializedViewsToExclude')]", "materializedViewsToInclude": "[parameters('materializedViewsToInclude')]", "tablesToExclude": "[parameters('tablesToExclude')]", "tablesToInclude": "[parameters('tablesToInclude')]" } } } ] }Implante o modelo do Azure Resource Manager usando o portal do Azure ou o PowerShell.
Consumidor de dados – Receber dados
Siga as instruções no vídeo para aceitar o convite, criar uma conta de compartilhamento de dados e mapeá-la para o cluster do consumidor.
Agora, o consumidor de dados pode ir para o cluster do Azure Data Explorer para conceder permissões ao usuário sobre os bancos de dados compartilhados e para acessar os dados. Os dados ingeridos usando a ingestão enfileirada no cluster de origem do Azure Data Explorer serão exibidos no cluster de destino dentro de alguns segundos a alguns minutos.