Introdução à captura de dados de alterações no repositório analítico do Azure Cosmos DB
APLICA-SE AO: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB
Use a Captura de Dados de Alterações (DCD) no repositório analítico do Azure Cosmos DB como fonte para o Azure Data Factory ou o Azure Synapse Analytics para capturar alterações específicas em seus dados.
Observação
Observe que a interface de serviço vinculada para API do Azure Cosmos DB for MongoDB ainda não está disponível no Fluxo de dados. Entretanto, você poderá usar o ponto de extremidade de documentação de sua conta com a interface de serviço vinculada ao “Azure Cosmos DB for NoSQL” como uma solução alternativa até que o serviço vinculado ao Mongo tenha suporte. Em um serviço vinculado ao NoSQL, escolha "Inserir Manualmente" para fornecer as informações da conta do Cosmos DB e usar o ponto de extremidade de documentação da conta (por exemplo: https://[your-database-account-uri].documents.azure.com:443/) em vez do ponto de extremidade do MongoDB (por exemplo: mongodb://[your-database-account-uri].mongo.cosmos.azure.com:10255/)
Pré-requisitos
- Uma conta existente do Azure Cosmos DB.
- Se você tiver uma assinatura do Azure, crie uma nova conta.
- Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
- Como alternativa, você pode experimentar o Azure Cosmos DB gratuitamente antes de confirmar.
Habilitar repositório analítico
Primeiro, habilite o Link do Azure Synapse no nível da conta e, em seguida, habilite o repositório analítico para os contêineres apropriados para sua carga de trabalho.
Habilitar o Link do Azure Synapse: habilitar o Link do Azure Synapse para uma conta do Azure Cosmos DB
Habilitar o repositório analítico para seus contêineres:
Opção Guia Habilitar para um novo contêiner específico Habilitar o Link do Azure Synapse para seus contêineres Habilitar para um contêiner existente específico Habilitar o Link do Azure Synapse para seus contêineres existentes
Criar um recurso do Azure de destino usando fluxos de dados
O recurso de captura de dados de alterações do repositório analítico está disponível por meio do recurso de fluxo de dados do Azure Data Factory ou do Azure Synapse Analytics. Para este guia, use Azure o Data Factory.
Importante
Como alternativa, você pode usar o Azure Synapse Analytics. Primeiro,crie um workspace do Azure Synapse se ainda não tiver um. No workspace recém-criado, selecione a guia Desenvolver, selecione Adicionar novo recurso e, em seguida, selecione Fluxo de dados.
Crie um Azure Data Factory, se ainda não tiver um.
Dica
Se possível, crie o data factory na mesma região em que sua conta do Azure Cosmos DB reside.
Inicie o data factory recém-criado.
No data factory, selecione a guia Fluxos de dados e, em seguida, selecione Novo fluxo de dados.
Dê um nome exclusivo ao fluxo de dados recém-criado. Neste exemplo, o fluxo de dados é denominado
cosmoscdc.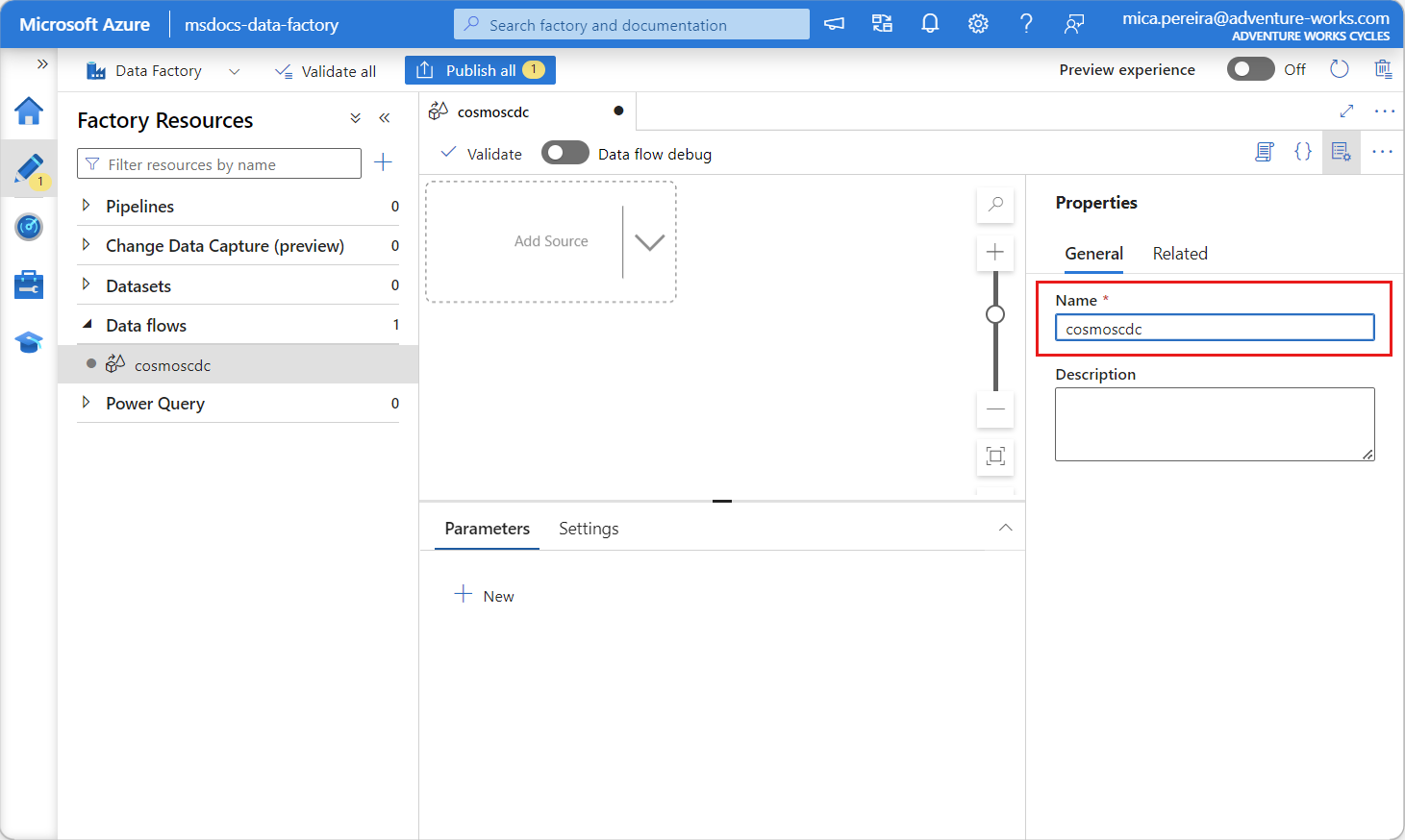

Definir as configurações de origem para o contêiner do repositório analítico
Agora, crie e configure uma origem para fluir dados do repositório analítico da conta do Azure Cosmos DB.
Selecione Adicionar origem.
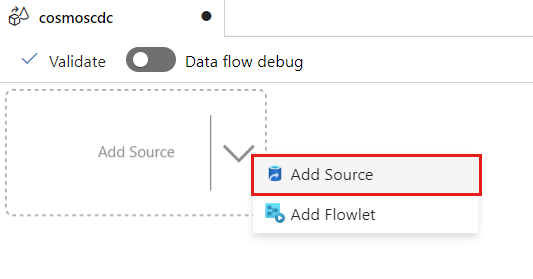
No campo Nome do fluxo de saída, insira cosmos.
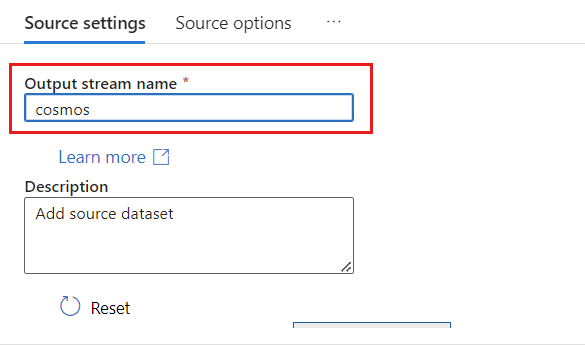
Na seção Tipo de origem, selecione Embutido.
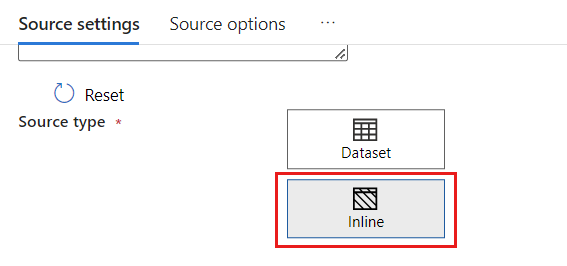
No campo Conjunto de dados, selecione Azure - Azure Cosmos DB for NoSQL.
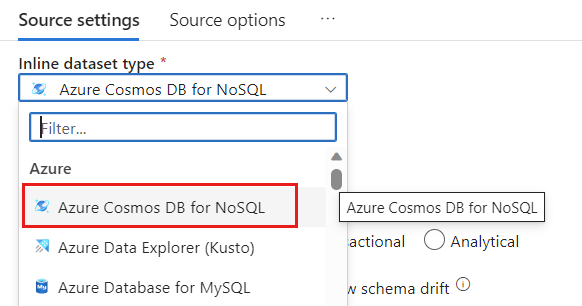
Crie um novo serviço vinculado para sua conta chamado cosmoslinkedservice. Selecione sua conta existente do Azure Cosmos DB for NoSQL na caixa de diálogo pop-up Novo serviço vinculado e selecione Ok. Neste exemplo, selecionamos uma conta pré-existente do Azure Cosmos DB for NoSQL chamada
msdocs-cosmos-sourcee um banco de dados chamadocosmicworks.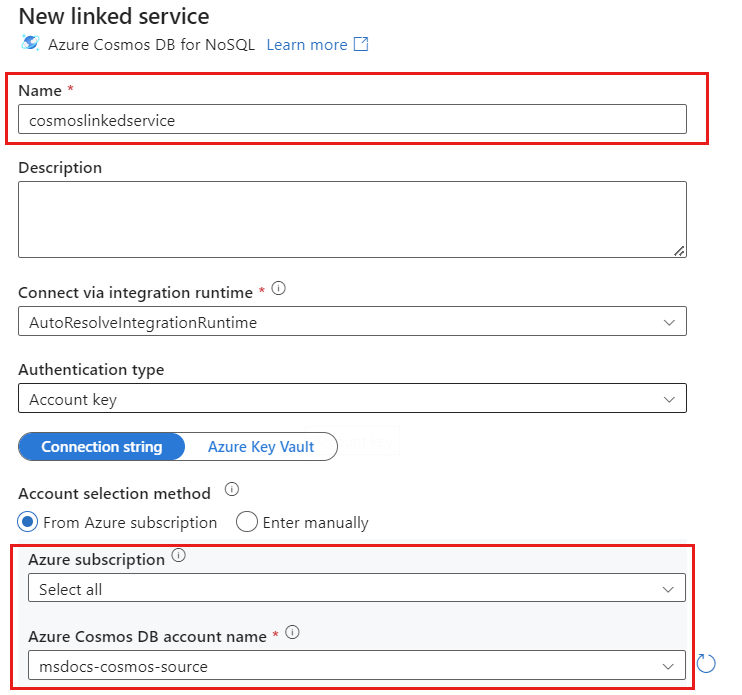
Selecione Analítico para o tipo de repositório.
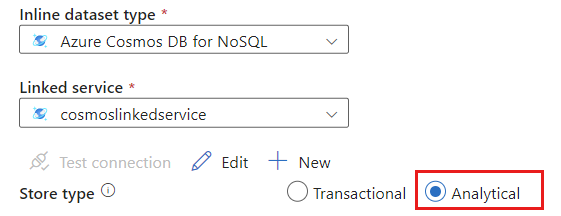
Selecione a guia Opções de origem.
Em Opções de origem, selecione o contêiner de destino e habilite a Depuração de fluxo de dados. Neste exemplo, o contêiner é chamado de
products.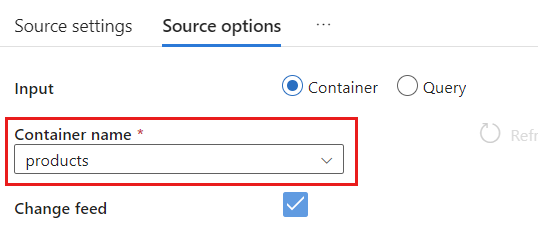
Selecione Depuração de fluxo de dados. Na caixa de diálogo pop-up Ativar depuração de fluxo de dados, mantenha as opções padrão e selecione Ok.
A guia Opções de origem também contém outras opções que talvez você queira habilitar. Esta tabela descreve essas opções:
| Opção | Descrição |
|---|---|
| Capturar atualizações intermediárias | Habilite essa opção se quiser capturar o histórico de alterações em itens, incluindo as alterações intermediárias entre as leituras de captura de dados de alterações. |
| Capturar Exclusões | Habilite essa opção para capturar registros excluídos pelo usuário e aplicá-los no Coletor. As exclusões não podem ser aplicadas no Azure Data Explorer e nos Coletores do Azure Cosmos DB. |
| Capturar TTLs do Repositório Transacional | Habilite essa opção para capturar registros TTL excluídos do repositório transacional (vida útil) do Azure Cosmos DB e aplicar no Coletor. As exclusões de TTL não podem ser aplicadas nos coletores do Azure Data Explorer e do Azure Cosmos DB. |
| Envio em lote em bytes | Essa configuração é, na verdade, gigabytes. Especifique o tamanho em gigabytes se você quiser colocar em lote os feeds de captura de dados de alteração |
| Configurações extras | Configurações adicionais do repositório analítico do Azure Cosmos DB e seus valores. (ex.: spark.cosmos.allowWhiteSpaceInFieldNames -> true) |
Trabalhando com opções de origem
Quando você marcar qualquer uma das opções Capture intermediate updates, Capture Deltes e Capture Transactional store TTLs, seu processo de CDA criará e preencherá o campo __usr_opType no coletor com os seguintes valores:
| Valor | Descrição | Opção |
|---|---|---|
| 1 | UPDATE | Capturar Atualizações intermediárias |
| 2 | INSERT | Não há uma opção para inserções, está ativada por padrão |
| 3 | USER_DELETE | Capturar Exclusões |
| 4 | TTL_DELETE | Capturar TTLs do Repositório Transacional |
Se você precisar diferenciar os registros TTL excluídos dos documentos excluídos por usuários ou aplicativos, marque as opções Capture intermediate updates e Capture Transactional store TTLs . Em seguida, você precisa adaptar seus processos ou aplicativos ou consultas de CDA para usar __usr_opType de acordo com o que é necessário para suas necessidades de negócios.
Dica
Se houver a necessidade de os consumidores downstream restaurarem a ordem das atualizações com a opção "capturar atualizações intermediárias" marcada, o campo carimbo de data/hora _ts do sistema poderá ser usado como o campo de ordenação.
Criar e definir configurações de coletor para operações de atualização e exclusão
Primeiro, crie um coletor doArmazenamento de Blobs do Azure simples e configure-o para filtrar dados apenas para operações específicas.
Crie uma conta e um contêiner Armazenamento de Blobs do Azure, se ainda não tiver uma. Para os próximos exemplos, usaremos uma conta chamada
msdocsblobstoragee um contêiner chamadooutput.Dica
Se possível, crie a conta de armazenamento na mesma região em que sua conta do Azure Cosmos DB reside.
De volta ao Azure Data Factory, crie um coletor para os dados de alteração capturados de sua origem
cosmos.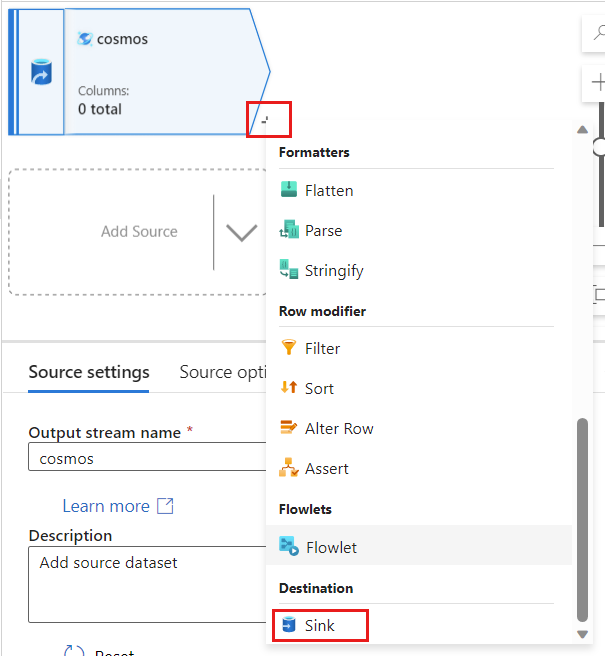
Dê um nome exclusivo ao coletor. Neste exemplo, o coletor é chamado de
storage.
Na seção Tipo de coletor, selecione Embutido. No campo Conjunto de dados, selecione Delta.
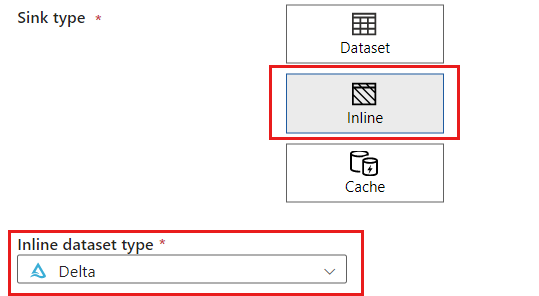
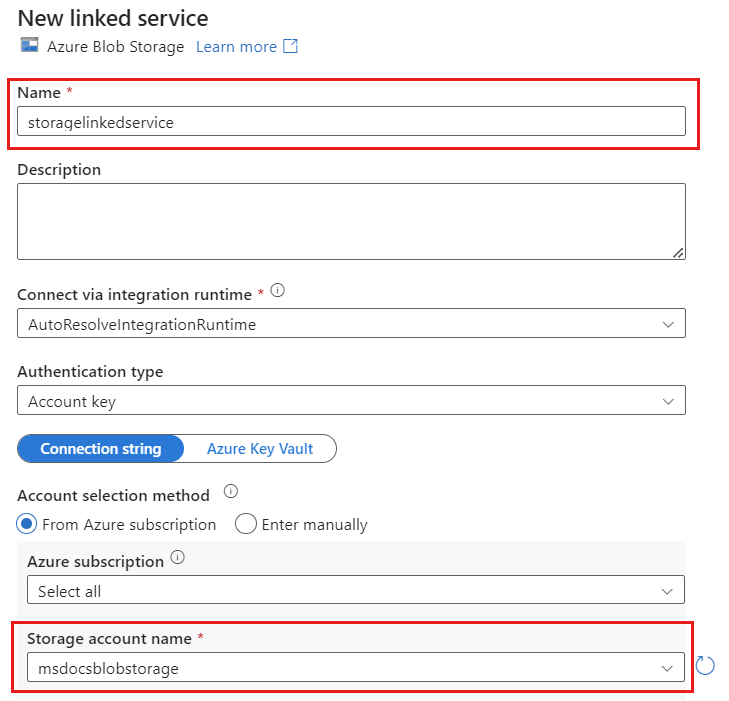
Crie um novo serviço vinculado para sua conta usando o Armazenamento de Blobs do Azure nomeado storagelinkedservice. Selecione sua conta do Azure Cosmos DB for NoSQL existente na caixa de diálogo pop-up Novo serviço vinculado e selecione Ok. Neste exemplo, selecionamos uma conta do Armazenamento de Blobs do Azure pré-existente chamada
msdocsblobstorage.
Selecione a guia Settings (Configurações).
Em Configurações, defina o Caminho da pasta como o nome do contêiner de blob. Neste exemplo, o nome do contêiner é
output.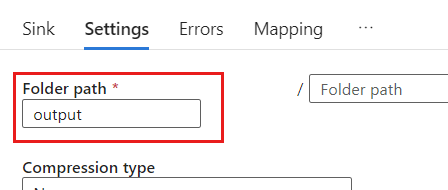
Localize a seção Método de atualização e altere as seleções para permitir apenas operações de exclusão e de atualização. Além disso, especifique as Colunas de chave como uma Lista de colunas por meio do campo
{_rid}como o identificador exclusivo.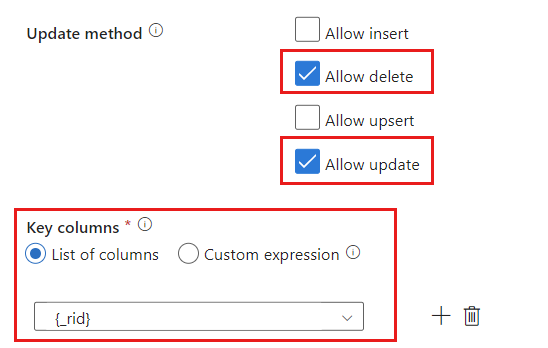
Selecione Validar para garantir que você não tenha cometido erros ou omissões. Selecione Publicar para publicar o fluxo de dados.
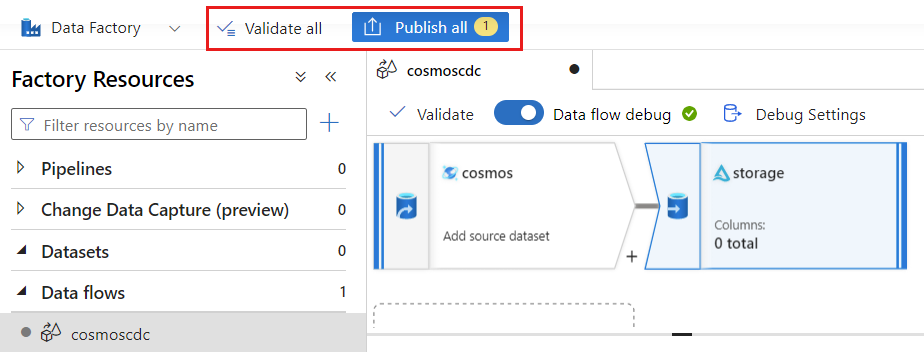
Agendar a execução da captura de dados de alterações
Depois que um fluxo de dados for publicado, você poderá adicionar um novo pipeline para mover e transformar seus dados.
Criar um pipeline. Dê um nome exclusivo ao pipeline Neste exemplo, o pipeline é chamado de
cosmoscdcpipeline.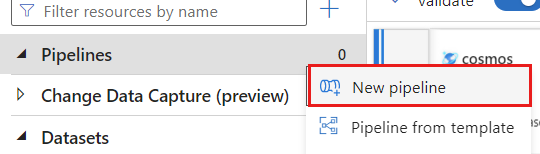
Na seção Atividades, expanda a opção Mover e Transformar e selecione Fluxo de dados.
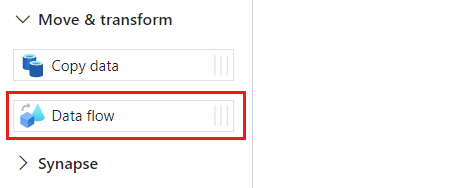
Dê um nome exclusivo à atividade de fluxo de dados. Neste exemplo, a atividade é chamada de
cosmoscdcactivity.Na guia Configurações, selecione o fluxo de dados chamado
cosmoscdccriado anteriormente neste guia. Em seguida, selecione um tamanho de computação com base no volume de dados e na latência necessária para sua carga de trabalho.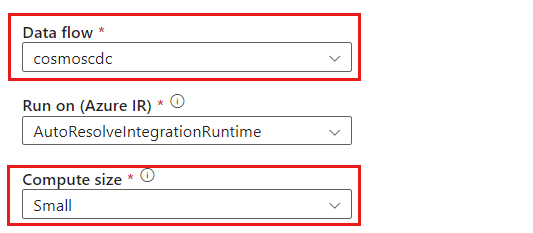
Dica
Para tamanhos de dados incrementais maiores que 100 GB, recomendamos o tamanho Personalizado com uma contagem de núcleos de 32 (+16 núcleos de driver).
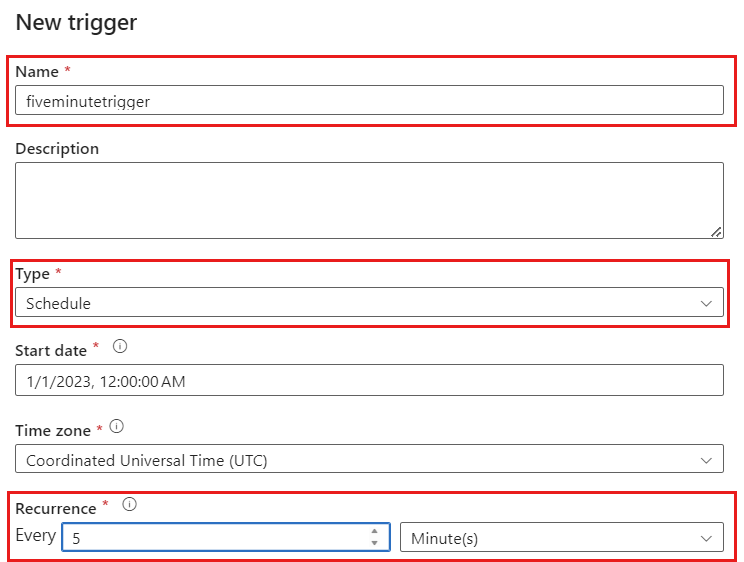
Selecione Adicionar gatilho. Agende esse pipeline para ser executado em uma cadência que faça sentido para sua carga de trabalho. Neste exemplo, o pipeline é configurado para ser executado a cada cinco minutos.
Observação
A janela de recorrência mínima para execuções de captura de dados de alteração é de um minuto.
Selecione Validar para garantir que você não tenha cometido erros ou omissões. Selecione Publicar para publicar o modelo:
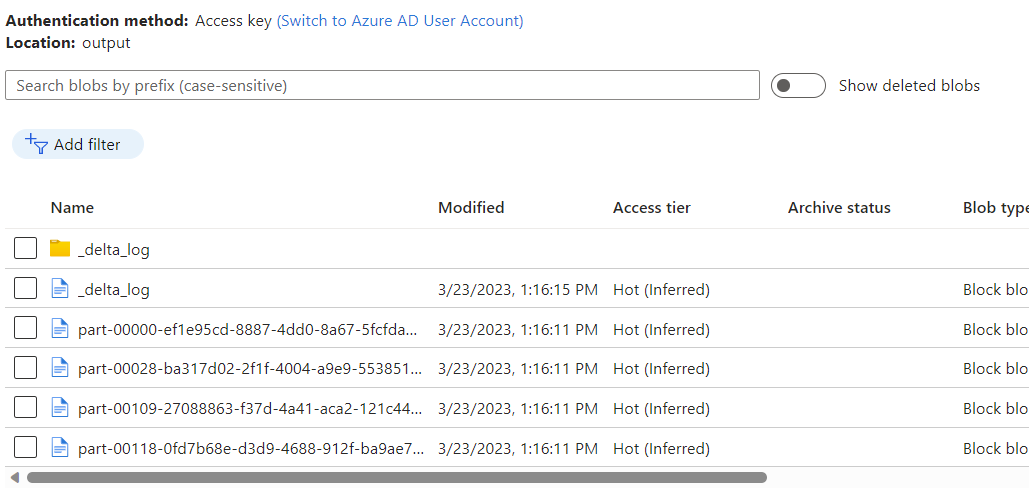
Observe os dados colocados no contêiner do Armazenamento de Blobs do Azure como uma saída do fluxo de dados usando a captura de dados de alteração do repositório analítico do Azure Cosmos DB.
Observação
A inicialização do cluster pode levar até três minutos. Para evitar o tempo de inicialização do cluster nas execuções subsequentes de captura de dados de alteração, configure o valor Vida útil do cluster de fluxo de dados. Para saber mais sobre como criar um runtime de integração, consulte Runtime de Integração no Azure Data Factory.
Trabalhos simultâneos
O tamanho do lote nas opções de origem, ou situações em que o coletor está lento para ingerir o fluxo de alterações, pode causar a execução de vários trabalhos ao mesmo tempo. Para evitar essa situação, defina a opção Simultaneidade como 1 nas configurações do pipeline para garantir que novas execuções não sejam disparadas até que a execução atual seja concluída.