Grupos de disponibilidade Always On no SQL Server em VMs do Azure
Aplica-se a: ![]() SQL Server na VM do Azure
SQL Server na VM do Azure
Este artigo introduz os AGs (grupos de disponibilidade) Always On para SQL Server nas VMs (Máquinas Virtuais) do Azure.
Para começar, confira o tutorial do grupo de disponibilidade.
Visão geral
Os Grupos de disponibilidade Always On de Máquinas Virtuais do Azure são semelhantes a Grupos de disponibilidade Always On locais e dependem do Cluster de failover do Windows Server. No entanto, como as máquinas virtuais são hospedadas no Azure, há algumas considerações adicionais também, como redundância de VM e roteamento de tráfego na rede do Azure.
O seguinte diagrama ilustra um grupo de disponibilidade para SQL Server em VMs do Azure:
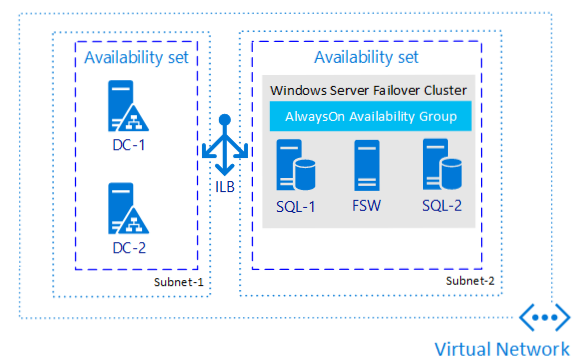
Observação
Agora é possível migrar por lift-and-shift sua solução de grupo de disponibilidade para o SQL Server em VMs do Azure usando as Migrações para Azure. Confira Migrar grupo de disponibilidade para saber mais.
Redundância de VM
Para aumentar a redundância e a alta disponibilidade, as VMs do SQL Server devem estar no mesmo conjunto de disponibilidade ou em zonas de disponibilidade diferentes.
Colocar um conjunto de VMs no mesmo conjunto de disponibilidade oferece proteção contra interrupções em um datacenter causadas por uma falha no equipamento (as VMs em um Conjunto de Disponibilidade não compartilham recursos) ou contra atualizações (as VMs em um conjunto de disponibilidade não são atualizadas ao mesmo tempo).
As Zonas de Disponibilidade oferecem proteção contra a falha de um datacenter inteiro, com cada zona representando um conjunto de datacenters dentro de uma região. Com a garantia de que os recursos serão colocados em diferentes Zonas de Disponibilidade, nenhuma interrupção no nível do datacenter poderá colocar todas as suas VMs offline.
Ao criar VMs do Azure, você precisa escolher entre configurar Conjuntos de Disponibilidade vs Zonas de Disponibilidade. Uma VM do Azure não pode participar de ambos.
Embora Zonas de Disponibilidade possam fornecer uma disponibilidade melhor em comparação a Conjuntos de Disponibilidade (99,99% vs. 99,95%), o desempenho também deve ser levado em consideração. As VMs em um Conjunto de Disponibilidade podem ser colocadas em um grupo de posicionamento por proximidade, o que garante que elas estão próximas umas das outras, minimizando a latência de rede entre elas. As VMs localizadas em diferentes Zonas de Disponibilidade terão maior latência de rede entre elas, o que pode aumentar o tempo necessário para sincronizar os dados entre as réplicas primária e secundária. Isso pode causar atrasos na réplica primária, além de aumentar a chance de perda de dados no caso de um failover não planejado. É importante testar a solução proposta sob carga e garantir que ela atenda aos SLAs para desempenho e disponibilidade.
Conectividade
Para corresponder à experiência local para se conectar ao seu ouvinte do grupo de disponibilidade, implante suas VMs do SQL Server em várias sub-redes dentro da mesma rede virtual. Ter várias sub-redes nega a necessidade da dependência extra em um Azure Load Balancer ou um DNN (nome de rede distribuída) para rotear o tráfego para o ouvinte.
Se você implantar as VMs do SQL Server em uma só sub-rede, poderá configurar um VNN (nome de rede virtual) e um Azure Load Balancer ou um DNN (nome de rede distribuída) para rotear o tráfego para o ouvinte do grupo de disponibilidade. Examine as diferenças entre os dois e, em seguida, implante um DNN (nome de rede distribuída) ou um VNN (nome de rede virtual) para seu grupo de disponibilidade.
A maioria dos recursos do SQL Server funciona de forma transparente com grupos de disponibilidade ao usar o DNN, mas há alguns recursos que podem exigir uma consideração especial. Confira interoperabilidade de AG e DNN para saber mais.
Além disso, há algumas diferenças importantes de comportamento entre a funcionalidade do ouvinte do VNN e o ouvinte do DNN que devem ser observadas:
- Tempo de failover: o tempo de failover é mais rápido ao usar um ouvinte DNN, pois não há necessidade de aguardar o balanceador de carga de rede detectar o evento de falha e alterar seu roteamento.
- Conexões existentes: as conexões feitas a um banco de dados específico, dentro de um grupo de disponibilidade de failover, serão fechadas, mas outras conexões com a réplica primária permanecerão abertas, pois o DNN permanecerá online durante o processo de failover. Isso é diferente de um ambiente de VNN tradicional, em que todas as conexões com a réplica primária normalmente são fechadas quando o grupo de disponibilidade faz o failover, o ouvinte fica offline e a réplica primária faz a transição para a função secundária. Ao usar um ouvinte DNN, talvez seja necessário ajustar as cadeias de conexão do aplicativo para garantir que as conexões sejam redirecionadas para a nova réplica primária após o failover.
- Transações abertas: transações abertas em um banco de dados, em um grupo de disponibilidade, durante um failover, serão fechadas e revertidas, e você precisará se reconectar manualmente. Por exemplo, no SQL Server Management Studio, feche a janela de consulta e abra uma nova.
Observação
Quando você tem vários AGs ou FCIs no mesmo cluster e usa um ouvinte DNN ou VNN, cada AG ou FCI precisa de seu próprio ponto de conexão independente.
A configuração de um ouvinte do VNN no Azure requer um balanceador de carga. Há duas opções principais para balanceadores de carga no Azure: externo (público) ou interno. O balanceador de carga externo (público) é voltado para a Internet e é associado a um IP virtual público acessível pela Internet. Um balanceador de carga interno só oferece suporte a clientes na mesma rede virtual. Para qualquer desses dois tipos de balanceador de carga, você deve habilitar o Retorno de servidor direto.
Você pode ainda se conectar a cada réplica de disponibilidade separadamente conectando-se diretamente à instância do serviço. Além disso, como os grupos de disponibilidade são compatíveis com versões anteriores com clientes de espelhamento de banco de dados, você pode se conectar a réplicas de disponibilidade, como parceiros de espelhamento, desde que as réplicas sejam configuradas de forma semelhante ao espelhamento do banco de dados:
- Há uma réplica primária e uma réplica secundária.
- A réplica secundária é configurada como ilegível (opção Secundária Legível definida como Não).
Este é um exemplo de cadeia de conexão de cliente que corresponde a essa configuração de espelhamento de banco de dados usando ADO.NET ou o SQL Server Native Client:
Data Source=ReplicaServer1;Failover Partner=ReplicaServer2;Initial Catalog=AvailabilityDatabase;
Para obter mais informações sobre conectividade de cliente, consulte:
- Usando palavras-chave da cadeia de conexão com o SQL Server Native Client
- Conectar clientes a uma sessão de espelhamento de banco de dados (SQL Server)
- Conectando-se ao ouvinte do grupo de disponibilidade em TI híbrida
- Ouvintes do grupo de disponibilidade, conectividade de cliente e failover de aplicativo (SQL Server)
- Usando cadeias de conexão de espelhamento de banco de dados com grupos de disponibilidade
Sub-rede única requer balanceador de carga
Quando você cria um ouvinte do grupo de disponibilidade em um WSFC (Cluster de Failover do Windows Server) local tradicional, um registro DNS é criado para o ouvinte com o endereço IP que você fornece e esse endereço IP é mapeado para o endereço MAC da Réplica primária atual nas tabelas ARP de switches e roteadores na rede local. O cluster faz isso usando GARP (Gratuitous ARP), que transmite o mapeamento IP-para-MAC mais recente para a rede sempre que um novo Primário for selecionado após o failover. Nesse caso, o endereço IP é do ouvinte e o MAC é da Réplica primária atual. O GARP força uma atualização das entradas da tabela ARP nos comutadores e roteadores, e todos os usuários que se conectam ao endereço IP do ouvinte são roteado diretamente para a Réplica primária atual.
Por motivos de segurança, não é permitida a transmissão em qualquer nuvem pública (Azure, Google, AWS), portanto, não há suporte para o uso de ARPs e GARPs no Azure. Para superar essa diferença em ambientes de rede, as VMs do SQL Server em um único grupo de disponibilidade de sub-rede dependem de balanceadores de carga para rotear o tráfego para os endereços IP apropriados. Os balanceadores de carga são configurados com um endereço IP de front-end que corresponde ao ouvinte e uma porta de investigação é atribuída para que o Azure Load Balancer pesquise periodicamente o status das réplicas no grupo de disponibilidade. Como apenas a VM do SQL Server de réplica primária responde à investigação TCP, o tráfego de entrada é roteado para a VM que responde com êxito à investigação. Além disso, a porta de investigação correspondente é configurada como o IP do cluster WSFC, garantindo que a réplica Primária responda à investigação TCP.
Os grupos de disponibilidade configurados em uma única sub-rede devem usar um balanceador de carga ou um DNN (nome de rede distribuída) para rotear o tráfego para a réplica apropriada. Para evitar essas dependências, configure o grupo de disponibilidade em várias sub-redes para que o ouvinte do grupo de disponibilidade seja configurado com um endereço IP para uma réplica em cada sub-rede e possa rotear o tráfego adequadamente.
Se você já tiver criado seu grupo de disponibilidade em uma única sub-rede, poderá migrá-lo para um ambiente de várias sub-redes.
Mecanismo de concessão
Para o SQL Server, a DLL de recurso do grupo de disponibilidade determina a integridade do grupo de disponibilidade com base no mecanismo de concessão do grupo de disponibilidade e na detecção de integridade Always On. A DLL de recurso do AG expõe a integridade de recursos por meio da operação IsAlive. O monitor de recursos sonda o IsAlive no intervalo de pulsação do cluster, que é definido pelos valores CrossSubnetDelay e SameSubnetDelay em todo o cluster. Em um nó principal, o serviço de cluster iniciará o failover sempre que a chamada IsAlive à DLL de recurso retornar que o grupo de disponibilidade não é íntegro.
A DLL de recurso do AG monitora o status de componentes internos do SQL Server. O sp_server_diagnostics relata a saúde desses componentes para o SQL Server em um intervalo controlado por HealthCheckTimeout.
Ao contrário de outros mecanismos de failover, a instância do SQL Server desempenha um papel ativo no mecanismo de concessão. O mecanismo de concessão é usado como uma validação do LooksAlive entre o host de recursos de Cluster e o processo do SQL Server. O mecanismo é usado para garantir que os dois lados (o Serviço de Cluster e o SQL Server) estejam em contato frequente, verificando o estado um do outro e, por fim, impedindo um cenário de separação.
Ao configurar um AG em VMs do Azure, geralmente é preciso configurar esses limites de maneira diferente da que eles seriam configurados em um ambiente local. Para definir as configurações de limite de acordo com as práticas recomendadas para VMs do Azure, confira as melhores práticas do cluster.
Configuração de rede
Implante suas VMs do SQL Server em várias sub-redes sempre que possível para evitar a dependência de um Azure Load Balancer ou de um DNN (nome de rede distribuído) para rotear o tráfego para o ouvinte do grupo de disponibilidade.
Em um cluster de failover da VM do Azure, recomendamos uma só NIC por servidor (nó de cluster). A rede do Azure tem redundância física, o que torna desnecessárias NICs adicionais em um cluster de failover da VM do Azure. Embora o relatório de validação de cluster emita um aviso de que os nós só são acessíveis em uma única rede, esse aviso pode ser ignorado com segurança em clusters de failover da VM do Azure.
Grupo de disponibilidade básico
Como o grupo de disponibilidade básico não permite mais de uma réplica secundária e não há acesso de leitura à réplica secundária, você pode usar as cadeias de conexão de espelhamento de banco de dados para grupos de disponibilidade básicos. Ao usar a cadeia de conexão, elimina-se a necessidade de se ter ouvintes. Remover a dependência do ouvinte é útil para grupos de disponibilidade em VMs do Azure, pois elimina a necessidade de um balanceador de carga ou de adicionar outros IPs ao balanceador de carga quando você tiver vários ouvintes para bancos de dados adicionais.
Por exemplo, para se conectar explicitamente usando um TCP/IP ao banco de dados do AG AdventureWorks no Replica_A ou Replica_B de um AG básico (ou qualquer AG que tenha apenas uma réplica secundária e em que o acesso de leitura não seja permitido na réplica secundária), um aplicativo cliente pode fornecer a seguinte cadeia de conexão de espelhamento de banco de dados para se conectar com êxito ao AG
Server=Replica_A; Failover_Partner=Replica_B; Database=AdventureWorks; Network=dbmssocn
Opções de implantação
Dica
Elimine a necessidade de um Azure Load Balancer ou de um DNN (nome de rede distribuída) para o grupo de disponibilidade Always On criando suas VMs do SQL Server em várias sub-redes dentro da mesma rede virtual do Azure.
Há várias opções para implantar um grupo de disponibilidade no SQL Server em VMs do Azure, algumas com mais automação do que outras.
A seguinte tabela fornece uma comparação das opções disponíveis:
| Portal do Azure, | CLI do Azure/PowerShell | Modelos de início rápido | Manual (sub-rede única) | Manual (várias sub-redes) | |
|---|---|---|---|---|---|
| Versão do SQL Server | 2016 + | 2016 + | 2016 + | 2012 + | 2012 + |
| Edição do SQL Server | Enterprise | Enterprise | Enterprise | Enterprise, Standard | Enterprise, Standard |
| Versão do Windows Server | 2016 + | 2016 + | 2016 + | Tudo | Tudo |
| Cria o cluster para você | Sim | Sim | Sim | Não | No |
| Cria o grupo de disponibilidade e o ouvinte para você | Sim | Não | No | No | Não |
| Cria o ouvinte e o balanceador de carga de modo independente | N/D | Não | No | Sim | N/D |
| É possível criar um ouvinte DNN usando este método? | N/D | Não | No | Sim | N/D |
| Configuração de quorum do WSFC | Testemunha da nuvem | Testemunha da nuvem | Testemunha da nuvem | Tudo | Tudo |
| DR com várias regiões | Não | No | No | Sim | Sim |
| Suporte a várias sub-redes | Sim | Não | Não | N/D | Sim |
| Suporte para um AD existente | Sim | Sim | Sim | Sim | Sim |
| DR com várias zonas na mesma região | Sim | Sim | Sim | Sim | Sim |
| AG distribuído sem AD | Não | No | No | Sim | Sim |
| AG distribuído sem cluster | Não | No | No | Sim | Yes |
| Requer balanceador de carga ou DNN | No | Sim | Sim | Sim | Não |
Próximas etapas
Para começar, examine as melhores práticas do HADR e implante o grupo de disponibilidade manualmente usando o tutorial do grupo de disponibilidade.
Para obter mais informações, consulte: