Para fazer failover, primeiro você precisa alternar os modos de replicação da instância do SQL Server usando Transact-SQL (T-SQL).
Em seguida, você pode fazer failover e alternar funções usando o PowerShell.
Alternar o modo de replicação (Failover para MI de SQL)
A replicação entre SQL Server e SQL Instância Gerenciada é assíncrona por padrão. Se você estiver fazendo failover do SQL Server para a Instância Gerenciada de SQL do Azure, antes de fazer failover do banco de dados, alterne o link para o modo síncrono no SQL Server usando Transact-SQL (T-SQL).
Observação
- Pule esta etapa caso esteja fazendo failover da Instância Gerenciada de SQL para o SQL Server 2022.
- A replicação síncrona entre grandes distâncias de rede pode retardar as transações na réplica primária.
Execute o script T-SQL abaixo no SQL Server para alterar o modo de replicação do grupo de disponibilidade distribuída de assíncrono para síncrono. Substitua:
<DAGName> com o nome do grupo de disponibilidade distribuído (usado para criar o link).<AGName> com o nome do grupo de disponibilidade criado no SQL Server (usado para criar o link).<ManagedInstanceName> pelo nome da instância gerenciada.
-- Run on SQL Server
-- Sets the distributed availability group to a synchronous commit.
-- ManagedInstanceName example: 'sqlmi1'
USE master
GO
ALTER AVAILABILITY GROUP [<DAGName>]
MODIFY
AVAILABILITY GROUP ON
'<AGName>' WITH
(AVAILABILITY_MODE = SYNCHRONOUS_COMMIT),
'<ManagedInstanceName>' WITH
(AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);
Para confirmar se você alterou o modo de replicação do link com êxito, use a exibição de gerenciamento dinâmico a seguir. Os resultados indicam o estado SYNCHRONOUS_COMMIT.
-- Run on SQL Server
-- Verifies the state of the distributed availability group
SELECT
ag.name, ag.is_distributed, ar.replica_server_name,
ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc,
ars.operational_state_desc, ars.synchronization_health_desc
FROM
sys.availability_groups ag
join sys.availability_replicas ar
on ag.group_id=ar.group_id
left join sys.dm_hadr_availability_replica_states ars
on ars.replica_id=ar.replica_id
WHERE
ag.is_distributed=1
Agora que você alternou o SQL Server para o modo de commit síncrono, a replicação entre as duas instâncias é síncrona. Se você precisar reverter esse estado, siga as mesmas etapas e defina o AVAILABILITY_MODE como ASYNCHRONOUS_COMMIT.
Verificar os valores de LSN no SQL Server e na Instância Gerenciada de SQL
Para concluir o failover ou a migração, confirme se a replicação para a secundária foi concluída. Para isso, você precisa verificar os LSNs (números de sequência de log) nos registros de log para o SQL Server e a Instância Gerenciada de SQL são iguais.
Inicialmente, espera-se que o LSN na primária seja maior do que o LSN na secundária. A latência da rede pode retardar um pouco a replicação em relação à primária. Como a carga de trabalho foi interrompida na primária, o LSN vai corresponder e parar de mudar após algum tempo.
Use a consulta T-SQL a seguir no SQL Server para ler o LSN do último log de transações gravado. Substitua:
<DatabaseName> com o nome do banco de dados e procure o último número LSN protegido.
-- Run on SQL Server
-- Obtain the last hardened LSN for the database on SQL Server.
SELECT
ag.name AS [Replication group],
db.name AS [Database name],
drs.database_id AS [Database ID],
drs.group_id,
drs.replica_id,
drs.synchronization_state_desc AS [Sync state],
drs.end_of_log_lsn AS [End of log LSN],
drs.last_hardened_lsn AS [Last hardened LSN]
FROM
sys.dm_hadr_database_replica_states drs
inner join sys.databases db on db.database_id = drs.database_id
inner join sys.availability_groups ag on drs.group_id = ag.group_id
WHERE
ag.is_distributed = 1 and db.name = '<DatabaseName>'
Use a consulta T-SQL a seguir na Instância Gerenciada de SQL para ler o último LSN protegido do banco de dados. Substitua <DatabaseName> pelo nome do Banco de Dados SQL.
Essa consulta funciona em uma Instância Gerenciada de SQL de Uso Geral. Para a Instância Gerenciada de SQL Comercialmente Crítica, você precisará remover o comentário de and drs.is_primary_replica = 1 no final do script. Na camada de serviço Comercialmente Crítico, esse filtro garante que apenas os detalhes da réplica primária sejam lidos.
-- Run on SQL managed instance
-- Obtain the LSN for the database on SQL Managed Instance.
SELECT
db.name AS [Database name],
drs.database_id AS [Database ID],
drs.group_id,
drs.replica_id,
drs.synchronization_state_desc AS [Sync state],
drs.end_of_log_lsn AS [End of log LSN],
drs.last_hardened_lsn AS [Last hardened LSN]
FROM
sys.dm_hadr_database_replica_states drs
inner join sys.databases db on db.database_id = drs.database_id
WHERE
db.name = '<DatabaseName>'
-- for Business Critical, add the following as well
-- AND drs.is_primary_replica = 1
Como alternativa, também é possível usar o comando Get-AzSqlInstanceLink do PowerShell ou o comando az sql mi link show da CLI do Azure para buscar a propriedade LastHardenedLsn do link na Instância Gerenciada de SQL e obter as mesmas informações que a consulta T-SQL anterior.
Importante
Verifique novamente se sua carga de trabalho foi interrompida no primário. Verifique se os LSNs no SQL Server e na Instância Gerenciada de SQL correspondem e permanecem correspondentes e inalterados por algum tempo. Os LSNs estáveis em ambas as instâncias indicam que o log final foi replicado para a secundária e a carga de trabalho foi efetivamente interrompida.
Fazer failover de um banco de dados
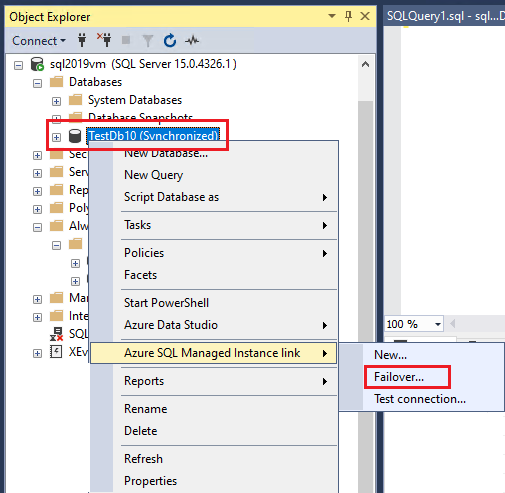
Se você deseja usar o PowerShell para fazer failover de um banco de dados entre o SQL Server 2022 e a Instância Gerenciada de SQL mantendo o link, ou para fazer failover com perda de dados em qualquer versão do SQL Server, use o assistente Failover entre o SQL Server e a Instância Gerenciada no SSMS para gerar o script específico para o seu ambiente. É possível fazer um failover planejado a partir da réplica primária ou secundária. Para fazer um failover forçado, conecte-se à réplica secundária.
Para quebrar o link e interromper a replicação ao fazer failover ou migrar seu banco de dados, independentemente da versão do SQL Server, use o comando Remove-AzSqlInstanceLink do PowerShell ou o comando az sql mi link delete da CLI do Azure.
Cuidado
- Antes de fazer failover, pare a carga de trabalho no banco de dados de origem para permitir que o banco de dados replicado seja completamente atualizado e passe por failover sem perda de dados. Se você realizar um failover forçado ou quebrar o link antes que os LSNs correspondam, pode haver perda de dados.
- O failover de um banco de dados no SQL Server 2019 e em versões anteriores quebra e remove o link entre as duas réplicas. Não é possível realizar o failback para a primária inicial.
O script de exemplo a seguir quebra o link e encerra a replicação entre as réplicas, tornando o banco de dados de leitura/gravação em ambas as instâncias. Substitua:
<ManagedInstanceName> pelo nome da instância gerenciada.<DAGName> com o nome do link que você está passando por failover (saída da propriedade Name do comando Get-AzSqlInstanceLink executado anteriormente acima).
# Run in Azure Cloud Shell (select PowerShell console)
# =============================================================================
# POWERSHELL SCRIPT TO FAIL OVER OR MIGRATE DATABASE TO AZURE
# ===== Enter user variables here ====
# Enter your managed instance name – for example, "sqlmi1"
$ManagedInstanceName = "<ManagedInstanceName>"
$LinkName = "<DAGName>"
# ==== Do not customize the following cmdlet ====
# Find out the resource group name
$ResourceGroup = (Get-AzSqlInstance -InstanceName $ManagedInstanceName).ResourceGroupName
# Failover the specified link
Remove-AzSqlInstanceLink -ResourceGroupName $ResourceGroup |
-InstanceName $ManagedInstanceName -Name $LinkName -Force
Quando o failover é bem-sucedido, o link é descartado e não existe mais. O banco de dados do SQL Server e o banco de dados da Instância Gerenciada de SQL podem executar cargas de trabalho de leitura/gravação já que agora estão completamente independentes.
Importante
Após o failover bem-sucedido para a Instância Gerenciada de SQL, reencaminhe manualmente a cadeia de conexão da aplicação para o FQDN da Instância Gerenciada de SQL para concluir o processo de migração ou falha e continuar executando no Azure.
Depois que o link for descartado, você poderá manter o grupo de disponibilidade no SQL Server, mas deverá descartar o grupo de disponibilidade distribuída para remover os metadados do link do SQL Server. Essa etapa adicional só é necessária durante o failover usando o PowerShell, já que o SSMS executa essa ação para você.
Para descartar o grupo de disponibilidade distribuída, substitua o seguinte valor e execute o código de T-SQL de exemplo:
<DAGName> com o nome do grupo de disponibilidade distribuído no SQL Server (usado para criar o link).
-- Run on SQL Server
USE MASTER
GO
DROP AVAILABILITY GROUP <DAGName>
GO