Usar réplicas somente leitura para descarregar cargas de trabalho de consulta somente leitura
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Como parte da Arquitetura de Alta Disponibilidade, cada banco de dados individual ou banco de dados do pool elástico nas camadas de serviço Premium e Comercialmente Crítico é automaticamente provisionado com uma réplica de leitura-gravação primária e uma ou mais réplicas somente leitura secundárias. As réplicas secundárias são provisionadas com o mesmo tamanho de computação que a réplica primária. O recurso escala de leitura permite que você balanceie a carga de cargas de trabalho somente leitura do Banco de Dados SQL do Microsoft Azure usando a capacidade de uma das réplicas somente leitura em vez de compartilhar a réplica de leitura-gravação. Dessa forma, algumas cargas de trabalho somente leitura podem ser isoladas das cargas de trabalho de leitura/gravação e não afetam seu desempenho. A função é pensada para aplicativos que incluem cargas de trabalho somente leitura separadas logicamente, como a análise. Nas camadas de serviço Premium e Comercialmente Crítico, os aplicativos podem obter benefícios de desempenho usando essa capacidade adicional sem custo extra.
O recurso de escala de leitura também está disponível na camada de serviço de Hiperescala quando pelo menos uma réplica secundária é adicionada. As réplicas nomeadas secundárias da Hiperescala oferecem escala independente, isolamento de acesso, isolamento da carga de trabalho, suporte para vários cenários de expansão de leitura e outros benefícios. Várias réplicas HA secundárias podem ser usadas para o equilíbrio de cargas de trabalho somente leitura que exigem mais recursos do que o disponível em uma réplica HA secundária.
A arquitetura de alta disponibilidade das camadas de serviço Básico, Padrão e Uso Geral não incluem nenhuma réplica. O recurso de escala de leitura não está disponível nessas camadas de serviço. No entanto, ao usar Banco de Dados SQL do Azure, as réplicas geográficas podem oferecer funcionalidade semelhante nessas camadas de serviço. Ao usar a Instância Gerenciada de SQL do Azure e grupos de failover, o ouvinte somente leitura do grupo de failover pode oferecer funcionalidade semelhante, respectivamente.
O diagrama a seguir ilustra o recurso para bancos de dados e instâncias gerenciadas Premium e Comercialmente Crítico.
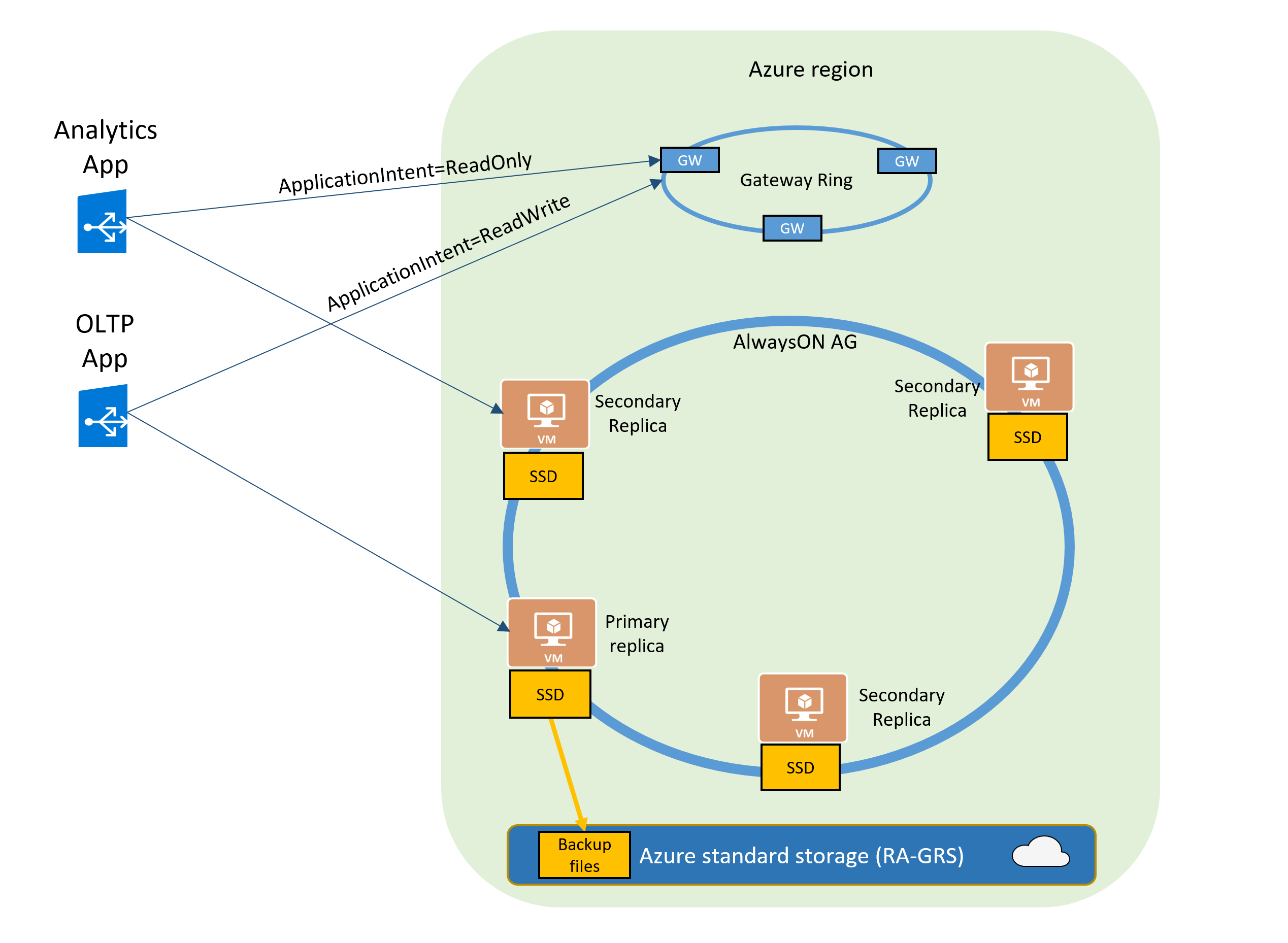
O recurso de escala de leitura é habilitado por padrão nos novos bancos de dados Premium, Comercialmente Crítico e Hiperescala.
Observação
A escala de leitura sempre está habilitada na camada de serviço Comercialmente Crítico do Instância Gerenciada de SQL e para bancos de dados de Hiperescala com pelo menos uma réplica secundária.
Se a cadeia de conexão SQL está configurada com ApplicationIntent=ReadOnly, o aplicativo é redirecionado para uma réplica somente leitura desse banco de dados ou instância gerenciada. Para obter informações sobre como usar a propriedade ApplicationIntent, consulte Especificando a Intenção do Aplicativo.
Somente para o Banco de Dados SQL do Azure, se você quiser garantir que o aplicativo se conecte à réplica primária, independentemente da configuração do ApplicationIntent na cadeia de conexão SQL, você deve desabilitar explicitamente a escala de leitura ao criar o banco de dados ou ao alterar sua configuração. Por exemplo, se você atualizar seu banco de dados da camada Standard ou Uso Geral para a camada Premium ou Comercialmente Crítico e quiser ter certeza de que todas as suas conexões continuam a ir para a réplica primária, desabilite a escala de leitura. Para obter detalhes sobre como desabilitá-lo, consulte Habilitar e desabilitar a escala de leitura.
Observação
Não há suporte para os recursos Repositório de Consultas e SQL Profiler em réplicas somente leitura.
Consistência de dados
As alterações de dados feitas na réplica primária são persistentes em réplicas somente leitura de maneira síncrona ou assíncrona, dependendo do tipo de réplica. No entanto, para todos os tipos de réplica, as leituras de uma réplica somente leitura são sempre assíncronas em relação à primária. Em uma sessão conectada a uma réplica somente leitura, as leituras são sempre consistentes transacionalmente. Como a latência de propagação de dados é variável, réplicas diferentes podem retornar dados em momentos um pouco diferentes com relação à principal e entre elas. Se uma réplica somente leitura ficar não disponível e uma sessão se reconectar, ela poderá se conectar a uma réplica que esteja em um momento diferente da réplica original. Da mesma forma, se um aplicativo alterar os dados usando uma sessão de leitura-gravação na primária e fizer a leitura imediata usando uma sessão somente leitura em uma réplica somente leitura, as alterações mais recentes talvez não fiquem visíveis de imediato.
A latência de propagação de dados típica entre a réplica primária e réplicas somente leitura varia no intervalo de dezenas de milissegundos a segundos de até um dígito. No entanto, não há nenhum limite superior fixo na latência da propagação de dados. Condições como alta utilização de recursos na réplica podem aumentar substancialmente a latência. Aplicativos que exigem consistência de dados garantida entre sessões ou exigem que os dados confirmados sejam legíveis imediatamente devem usar a réplica primária.
Observação
A latência de propagação de dados inclui o tempo necessário para enviar e persistir registros de log (se aplicável) para uma réplica secundária. Ela também inclui o tempo necessário para refazer (aplicar) esses registros de log a páginas de dados. Para garantir a consistência dos dados, as alterações só ficarão visíveis após a aplicação do registro de log de confirmação de transação. Quando a carga de trabalho usa transações maiores, a latência efetiva de propagação de dados é aumentada.
Para monitorar a latência da propagação de dados, confira Monitor e solucionar problemas de réplica somente leitura.
Conectar-se a uma réplica somente leitura
Quando você habilita a escala de leitura para um banco de dados, a opção ApplicationIntent na cadeia de conexão fornecida pelo cliente determina se a conexão é roteada para a réplica de gravação ou para uma réplica somente leitura. Especificamente, se o valor ApplicationIntent é ReadWrite (o valor padrão), a conexão é direcionada para a réplica de leitura-gravação do banco de dados. Isso é idêntico ao comportamento quando ApplicationIntent não está incluído na cadeia de conexão. Se o valor de ApplicationIntent é ReadOnly, a conexão é roteada para uma réplica somente leitura.
Por exemplo, a seguinte cadeia de conexão conecta o cliente a uma réplica somente leitura (substituindo os itens nos chevrons pelos valores corretos para o seu ambiente e descartando os chevrons):
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;User ID=<myLogin>;Password=<password>;Trusted_Connection=False; Encrypt=True;
Para se conectar a uma réplica somente leitura usando o SSMS (SQL Server Management Studio), selecione Opções
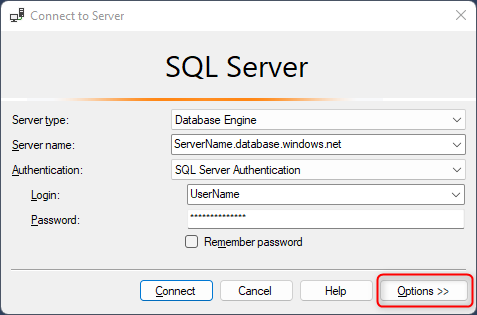
Selecione Parâmetros de Conexão Adicionais, insira ApplicationIntent=ReadOnly e escolha Conectar
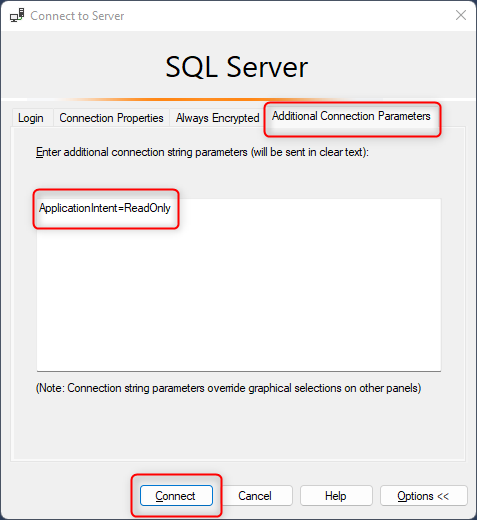
Qualquer uma das seguintes cadeias de conexão conecta o cliente a uma réplica de leitura-gravação (substituindo os itens nos chevrons pelos valores corretos para o seu ambiente e descartando os chevrons):
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadWrite;User ID=<myLogin>;Password=<password>;Trusted_Connection=False; Encrypt=True;
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;User ID=<myLogin>;Password=<password>;Trusted_Connection=False; Encrypt=True;
Verifique se uma conexão está pronta para réplica somente leitura
Você pode verificar se você está conectado a uma réplica somente leitura ao executar a consulta a seguir no contexto de sua base de dados. Ela retorna READ_ONLY quando conectado a uma réplica somente leitura.
SELECT DATABASEPROPERTYEX(DB_NAME(), 'Updateability');
Observação
Nas camadas de serviço Premium e Comercialmente Crítico, somente uma das réplicas somente leitura pode ser acessada em um determinado momento. A Hiperescala dá suporte a várias réplicas somente leitura.
Monitorar e solucionar problemas de réplicas somente leitura
Quando conectado a uma réplica somente leitura, as DMVs (exibições de gerenciamento dinâmico) refletem o estado da réplica e podem ser consultadas para fins de monitoramento e solução de problemas. O mecanismo de banco de dados fornece várias exibições para expor uma ampla variedade de dados de monitoramento.
As exibições a seguir normalmente são usadas para monitoramento e solução de problemas de réplica:
| Nome | Finalidade |
|---|---|
| sys.dm_db_resource_stats | Fornece métricas de utilização de recursos para a última hora, incluindo CPU, dados de entrada e saída, e utilização de gravação de log em relação aos limites de objetivo de serviço. |
| sys.dm_os_wait_stats | Fornece estatísticas de espera agregada para a instância do mecanismo de banco de dados. |
| sys.dm_database_replica_states | Fornece estatísticas de sincronização e estado de integridade da réplica. O tamanho da fila de refazer e a taxa de refazer servem como indicadores de latência da propagação de dados na réplica somente leitura. |
| sys.dm_os_performance_counters | Fornece contadores de desempenho do mecanismo de banco de dados. |
| sys.dm_exec_query_stats | Fornece estatísticas de execução por consulta, como número de execuções, tempo de CPU usado etc. |
| sys.dm_exec_query_plan() | Fornece planos de consulta em cache. |
| sys.dm_exec_sql_text() | Fornece texto de consulta para um plano de consulta armazenado em cache. |
| sys.dm_exec_query_profiles | Fornece o progresso de consulta em tempo real enquanto as consultas estão em execução. |
| sys.dm_exec_query_plan_stats() | Fornece o último plano de execução real conhecido, incluindo estatísticas de tempo de execução para uma consulta. |
| sys.dm_io_virtual_file_stats() | Fornece IOPS de armazenamento, taxa de transferência e estatísticas de latência para todos os arquivos de banco de dados. |
Observação
As DMVs sys.resource_stats e sys.elastic_pool_resource_stats do banco de dados master lógico retornam os dados de utilização de recursos da réplica primária.
Monitorar réplicas somente leitura com Eventos Estendidos
Uma sessão de evento estendido não pode ser criada quando conectada a uma réplica somente leitura. No entanto, no banco de dados SQL do Azure e na Instância Gerenciada de SQL do Azure, as definições de sessões de Eventos Estendidos criadas e alteradas na réplica primária no escopo do banco de dados são replicadas para réplicas somente leitura, incluindo réplicas geográficas e eventos de captura em réplicas somente leitura.
No Banco de Dados SQL do Azure, uma sessão de evento estendida em uma réplica somente leitura baseada em uma definição de sessão da réplica primária pode ser iniciada e interrompida independentemente da sessão na réplica primária.
Na Instância Gerenciada do SQL do Azure, para iniciar um rastreamento em uma réplica somente leitura, você deve primeiro iniciar o rastreamento na réplica primária antes de iniciar o rastreamento na réplica somente leitura. Se você não iniciar primeiro o rastreamento na réplica primária, receberá o seguinte erro ao tentar iniciar o rastreamento na réplica somente leitura:
Msg 3906, Nível 16, Estado 2, Linha 1 Falha ao atualizar o banco de dados "mestre" porque o banco de dados é somente leitura.
Depois de iniciar o rastreamento primeiro na réplica primária e, em seguida, na réplica somente leitura, você pode interromper o rastreamento na réplica primária.
Para descartar uma sessão de evento em uma réplica somente leitura, execute estas etapas:
- Conecte o Pesquisador de Objetos do SSMS ou um período de consulta à réplica somente leitura.
- Pare a sessão na réplica somente leitura selecionando Parar Sessão no menu de contexto da sessão no Pesquisador de Objetos ou executando
ALTER EVENT SESSION [session-name-here] ON DATABASE STATE = STOP;em um período de consulta. - Conecte o Pesquisador de Objetos ou uma janela consulta à réplica primária.
- Descarte a sessão na réplica primária selecionando Excluir no menu de contexto da sessão ou executando
DROP EVENT SESSION [session-name-here] ON DATABASE;
Nível de isolamento da transação em réplicas somente leitura
As transações nas réplicas somente leitura sempre usam o nível de isolamento da transação de instantâneo, independentemente do nível de isolamento da transação da sessão e de qualquer dica de consulta. O isolamento de instantâneo usa o controle de versão de linha para evitar cenários de bloqueio onde os leitores bloqueiam gravadores.
Em casos raros, se uma transação de isolamento de instantâneo acessar os metadados de objeto que foram modificados em outra transação simultânea, ele poderá receber o erro 3961, "a transação de isolamento de instantâneo falhou no banco de dados '%. * ls ' porque o objeto acessado pela instrução foi modificado por uma instrução DDL em outra transação simultânea desde o início desta transação. Ela não é permitida porque os metadados não têm controle de versão. Uma atualização simultânea dos metadados poderá gerar inconsistências se for combinada ao isolamento de instantâneo.
Consultas de execução longa em réplicas somente leitura
As consultas em execução em réplicas somente leitura precisam acessar metadados para os objetos referenciados na consulta (tabelas, índices, estatísticas, etc.) Em casos raros, se um objeto de metadados for modificado na réplica primária enquanto uma consulta mantém um bloqueio no mesmo objeto na réplica somente leitura, a consulta pode bloquear o processo que aplica as alterações da réplica primária à réplica somente leitura. Se essa consulta fosse executada por um longo tempo, isso faria com que a réplica somente leitura fosse significativamente dessincronizada com a réplica primária. Para réplicas que são destinos de failover potenciais (réplicas secundárias nas camadas de serviço Premium e Comercialmente Crítico, réplicas de HA de Hiperescala e todas as réplicas geográficas), isso também atrasaria a recuperação do banco de dados se um failover ocorresse, causando um tempo de inatividade maior do que o esperado.
Se uma consulta de execução longa em uma réplica somente leitura causar direta ou indiretamente esse tipo de bloqueio, ela poderá ser encerrada automaticamente para evitar latência excessiva de dados e possível impacto na disponibilidade do banco de dados. A sessão recebe o erro 1219, "Sua sessão foi desconectada devido a uma operação DDL de alta prioridade", ou erro 3947, "A transação foi anulada porque a computação secundária não pôde ser refeita. Tente fazer a transação novamente."
Observação
Se você receber os erros 3961, 1219 ou 3947 ao executar consultas em uma réplica somente leitura, repita a consulta. Como alternativa, evite operações que modifiquem metadados de objeto (alterações de esquema, manutenção de índice, atualizações de estatísticas etc.) na réplica primária enquanto as consultas de longa execução são executadas em réplicas secundárias.
Dica
Nas camadas de serviço Premium e Comercialmente Crítico, quando conectado a uma réplica somente leitura, as colunas redo_queue_size e redo_rate no sys.dm_database_replica_states DMV podem ser usadas para monitorar o processo de sincronização de dados, servindo como indicadores de latência de propagação de dados na réplica somente leitura.
Habilitar e desabilitar o dimensionamento de leitura para Banco de Dados SQL
Para Instância Gerenciada de SQL, a escala de leitura é habilitada automaticamente na camada de serviço Comercialmente Crítico e não está disponível na camada de serviço Uso Geral. Não é possível desabilitar e reenviar a escala de leitura.
Para Banco de Dados SQL, a escala de leitura é habilitada por padrão nas camadas de serviço Premium, Comercialmente Crítico e Hiperescala. Ela não pode ser habilitada nas camadas de serviço Basic, Standard ou Uso Geral. A Escala de leitura é desabilitada automaticamente em bancos de dados de Hiperescala configurados com zero réplicas secundárias.
Para bancos de dados individuais e em pool no Banco de Dados SQL do Azure, você pode desabilitar e habilitar novamente a escala de leitura nas camadas de serviço Premium ou Comercialmente Crítico usando o portal do Azure e o Azure PowerShell. Essas opções não estão disponíveis para Instância Gerenciada de SQL, pois a escala de leitura não pode ser desabilitada.
Observação
Para bancos de dados individuais e bancos de dados de pool elástico, a capacidade de desabilitar a escala de leitura é fornecida para compatibilidade com versões anteriores. A escala de leitura não pode ser desabilitada nas instâncias gerenciadas na camada Comercialmente Crítico.
Portal do Azure
Para o Banco de Dados SQL do Azure, você pode gerenciar a configuração de expansão de leitura no painel de banco de dados Computação + armazenamento, disponível em Configurações. O uso do portal do Azure para habilitar ou desabilitar a escala de leitura não está disponível para Instância Gerenciada de SQL do Azure.
PowerShell
Importante
O módulo do Azure Resource Manager do PowerShell ainda tem suporte, mas todo o desenvolvimento futuro destina-se ao módulo Az.Sql. O módulo Azure Resource Manager continuará a receber as correções de bugs até pelo menos dezembro de 2020. Os argumentos para os comandos no módulo Az e nos módulos Azure Resource Manager são substancialmente idênticos. Para saber mais sobre a compatibilidade entre eles, confira Apresentação do novo módulo Az do Azure PowerShell.
Gerenciar a escala de leitura no Microsoft Azure PowerShell requer a versão de dezembro de 2016 do Microsoft Azure PowerShell ou mais recente. Para a versão mais recente do PowerShell, consulte Azure PowerShell.
No Banco de Dados SQL do Azure, você pode habilitar ou desabilitar a escala de leitura no Azure PowerShell invocando o cmdlet Set-AzSqlDatabase e passando o valor desejado (Enabled ou Disabled) para o parâmetro -ReadScale. A desabilitação da escala de leitura para a Instância Gerenciada de SQL não está disponível.
Para desabilitar a escala de leitura para um banco de dados existente (substituindo os itens nos colchetes pelos valores corretos para o seu ambiente e descartando os colchetes):
Set-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Disabled
Para desabilitar a escala de leitura para um banco de dados existente (substituindo os itens nos colchetes pelos valores corretos para o seu ambiente e descartando os colchetes):
New-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Disabled -Edition Premium
Para desabilitar a escala de leitura para um banco de dados existente (substituindo os itens nos colchetes pelos valores corretos para o seu ambiente e descartando os colchetes):
Set-AzSqlDatabase -ResourceGroupName <resourceGroupName> -ServerName <serverName> -DatabaseName <databaseName> -ReadScale Enabled
API REST
Para criar um banco de dados com expansão de leitura desabilitada ou para alterar a configuração de um banco de dados existente, use o método a seguir com a propriedade readScale definida como Enabled ou Disabled, como na solicitação de exemplo a seguir.
Method: PUT
URL: https://management.azure.com/subscriptions/{SubscriptionId}/resourceGroups/{GroupName}/providers/Microsoft.Sql/servers/{ServerName}/databases/{DatabaseName}?api-version= 2014-04-01-preview
Body: {
"properties": {
"readScale":"Disabled"
}
}
Para obter mais informações, consulte Bancos de dados - Criar ou Atualizar.
Usar o banco de dados tempdb em uma réplica somente leitura
O banco dados tempdb na réplica primária não é replicado para as réplicas somente leitura. Cada réplica tem seu próprio banco de dados tempdb que é criado quando a réplica é criada. Isso garante que tempdb é atualizável e pode ser modificado durante a execução da consulta. Se sua carga de trabalho somente leitura depender do uso de objetos tempdb, você deverá criar esses objetos como parte da mesma carga de trabalho, enquanto estiver conectado a uma réplica somente leitura.
Usar escala de leitura com bancos de dados replicados geograficamente
Os bancos de dados secundários replicados geograficamente têm a mesma arquitetura de alta disponibilidade que os bancos de dados primários. Se você está se conectando ao banco de dados secundário replicado geograficamente com expansão de leitura habilitada, suas sessões com ApplicationIntent=ReadOnly são roteadas para uma das réplicas de alta disponibilidade da mesma maneira que são roteadas no banco de dados gravável primário. As sessões sem ApplicationIntent=ReadOnly são roteadas para a réplica primária do secundário replicado geograficamente, que também é somente leitura.
Dessa forma, a criação de uma réplica geográfica pode fornecer várias réplicas adicionais somente leitura para um banco de dados primário de leitura/gravação. Cada réplica geográfica adicional fornece outro par de réplicas somente leitura. As réplicas geográficas podem ser criadas em qualquer região do Azure, incluindo a região do banco de dados primário.
Observação
Não há nenhum round robin automático ou qualquer outro roteamento com balanceamento de carga entre as réplicas de um banco de dados secundário com replicação geográfica, com exceção de uma réplica geográfica de Hiperescala com mais de uma réplica de HA. Nesse caso, as sessões com intenção somente leitura são distribuídas em todas as réplicas de HA de uma réplica geográfica.
Suporte a recursos em réplicas somente leitura
Veja abaixo uma lista do comportamento de alguns recursos em réplicas somente leitura:
- A auditoria em réplicas somente leitura é habilitada automaticamente. Para obter mais informações sobre a hierarquia das pastas de armazenamento, as convenções de nomenclatura e o formato do log, confira Formato do log de auditoria do Banco de Dados SQL.
- Análise de Desempenho de Consultas se baseia em dados do Repositório de Consultas, que atualmente não rastreia a atividade na réplica somente leitura. A Análise de Desempenho de Consultas mostra consultas que são executadas na réplica somente leitura.
- O ajuste automático depende do Repositório de Consultas, conforme detalhado no documento Ajuste automático. O ajuste automático só funciona para cargas de trabalho em execução na réplica primária.
Próximas etapas
- Para obter informações sobre a oferta de Hiperescala do Banco de Dados SQL, consulte Camada de serviço de Hiperescala.