Estratégias de recuperação de desastres para aplicativos que usam pools elásticos do Banco de Dados SQL do Azure
Aplica-se a: ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
O Banco de Dados SQL do Azure fornece uma série de recursos para permitir a continuidade dos negócios do seu aplicativo quando incidentes catastróficos ocorrerem. Pools elásticos e bancos de dados únicos são compatíveis com o mesmo tipo de recursos de recuperação de desastre. Este artigo descreve diversas estratégias de recuperação de desastres para pools elásticos que aproveitam esses recursos de continuidade de negócios do Banco de Dados SQL do Azure.
Este artigo usa o seguinte padrão de aplicativo de SaaS ISV canônico:
Um aplicativo Web baseado em nuvem moderno provisiona um banco de dados para cada usuário final. O ISV tem um grande número de clientes e, portanto, usa vários bancos de dados, conhecidos como bancos de dados de locatário. Como os bancos de dados do locatário normalmente têm padrões de atividade imprevisíveis, o ISV usa um pool elástico para tornar o custo do banco de dados bastante previsível por longos períodos de tempo. O pool elástico também simplifica o gerenciamento de desempenho quando há picos de atividade de usuário. Além dos bancos de dados de locatário, o aplicativo também usa vários bancos de dados para gerenciar perfis de usuário, segurança, coletar padrões de uso etc. A disponibilidade dos locatários individuais não afeta a disponibilidade do aplicativo como um todo. No entanto, a disponibilidade e o desempenho dos bancos de dados de gerenciamento são essenciais para o funcionamento do aplicativo. Se os bancos de dados de gerenciamento estiverem offline, todo o aplicativo estará offline.
Este artigo discute estratégias de DR que abrangem uma variedade de cenários de aplicativos de inicialização sensíveis ao custo para aqueles com requisitos rígidos de disponibilidade.
Observação
Se estiver utilizando bancos de dados Premium ou Comercialmente Crítico e pools elásticos, será possível torná-los resilientes a interrupções regionais convertendo-os para configuração de implantação com redundância de zona. Veja Bancos de dados com redundância de zona.
Cenário 1. Inicialização econômica
Sou uma startup e dependo muito do custo das coisas. Quero simplificar a implantação e o gerenciamento do aplicativo e desejo ter um SLA limitado para clientes individuais. No entanto, quero garantir que o aplicativo como um todo nunca fique offline.
Para satisfazer o requisito de simplicidade, implante todos os bancos de dados do locatário em um pool elástico na região do Azure de sua escolha e implante os bancos de dados de gerenciamento como bancos de dados únicos replicados geograficamente. Na recuperação de desastres de locatários, use a restauração geográfica, que é fornecida sem custo adicional. Para garantir a disponibilidade dos bancos de dados de gerenciamento, replique-os geograficamente para outra região usando um grupo de failover automático (etapa 1). O custo corrente da configuração da recuperação de desastres neste cenário é igual ao custo total dos bancos de dados secundários. Essa configuração está ilustrada no diagrama a seguir.
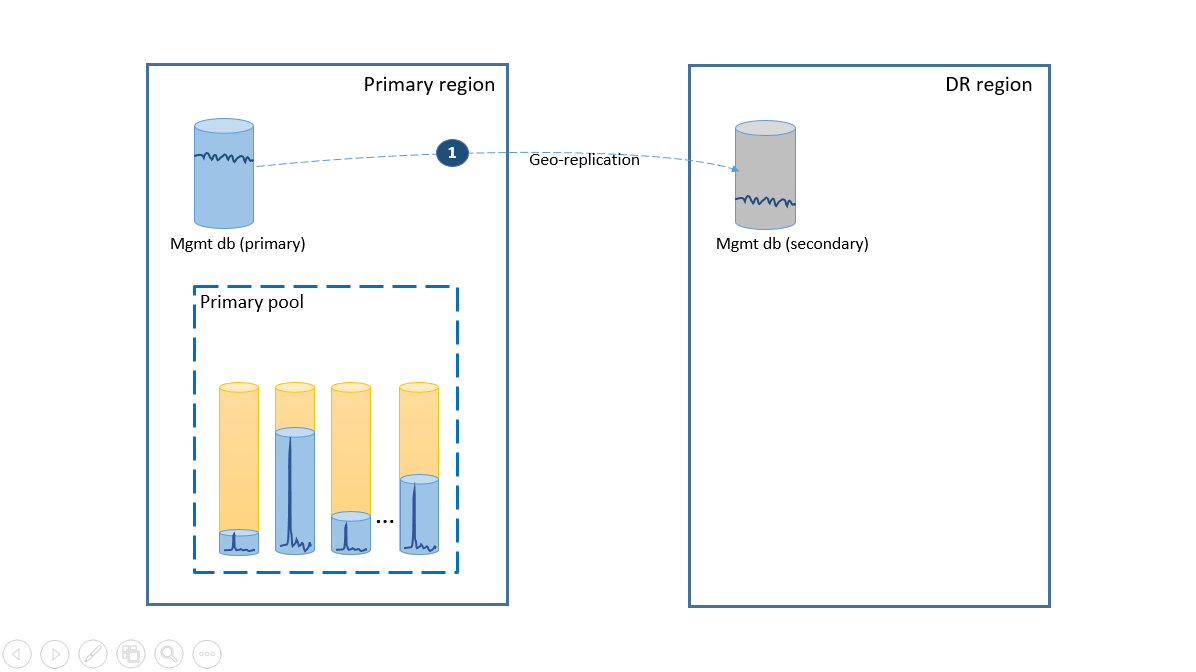
O próximo diagrama ilustra as etapas de recuperação online do seu aplicativo se uma interrupção na região primária ocorrer.
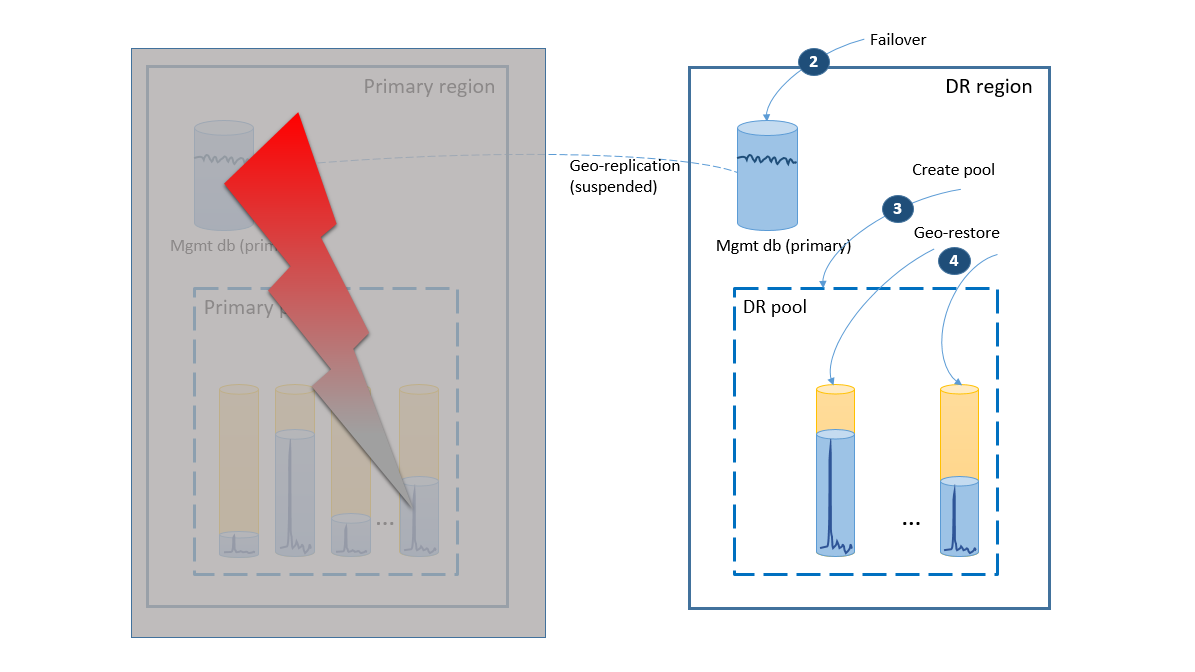
- O grupo de failover inicia o failover automático do banco de dados de gerenciamento para a região de DR. O aplicativo é reconectado automaticamente às novas contas primárias e bancos de dados de locatário serão criados na região de DR. Os clientes existentes verão os seus dados como temporariamente indisponíveis.
- Crie o pool elástico com a mesma configuração do pool original (2).
- Use a restauração geográfica para criar cópias dos bancos de dados de locatário (3). Você pode cogitar disparar as restaurações individuais pelas conexões do usuário final ou usar outro esquema de prioridade específica do aplicativo.
Neste momento, seu aplicativo está online novamente na região de DR, mas alguns clientes acessarão seus dados com algum atraso.
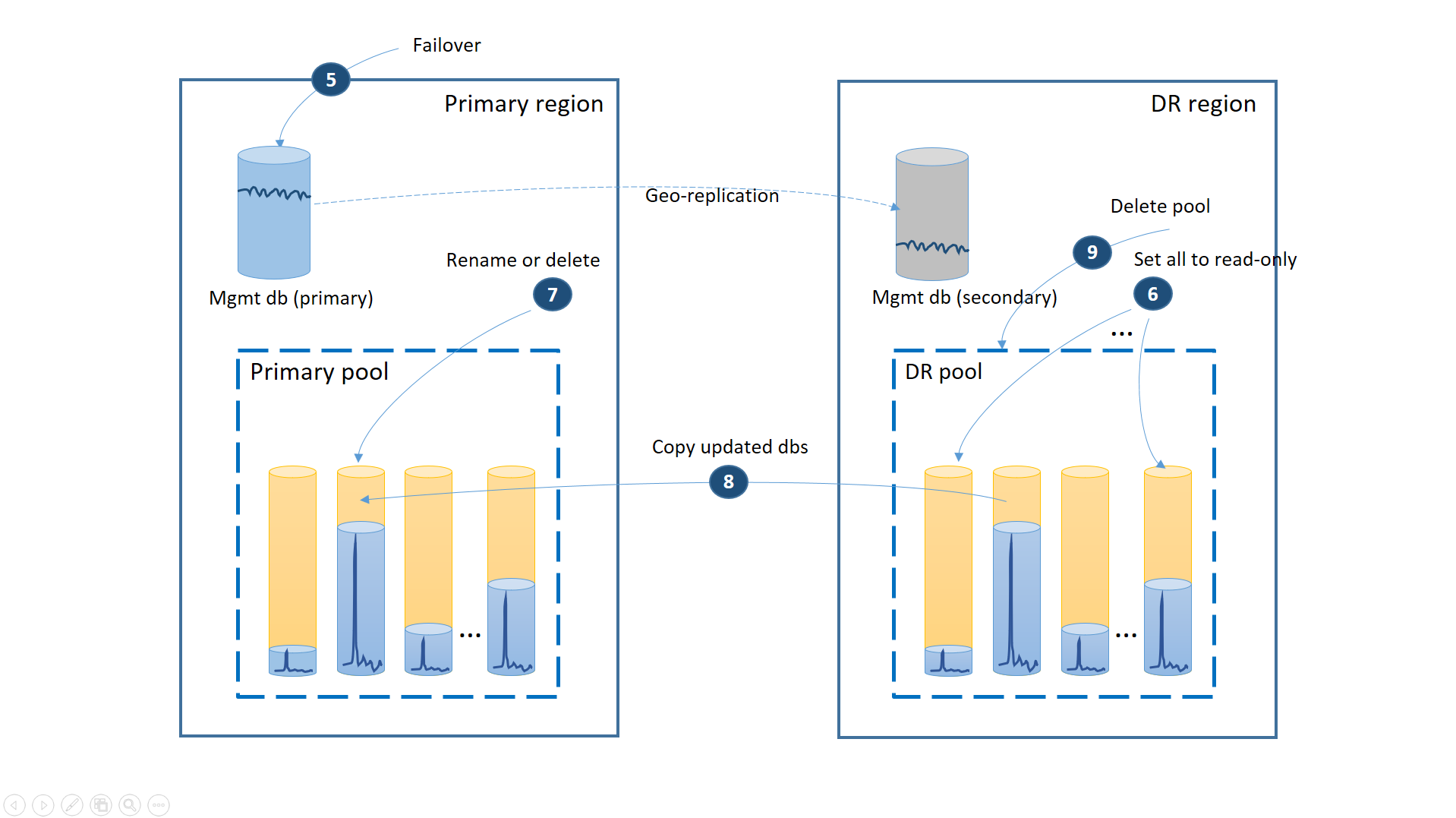
Se a interrupção foi temporária, é possível que a região primária seja recuperada pelo Azure antes de todas as restaurações do banco de dados serem concluídas na região de DR. Nesse caso, você deve organizar a mudança do aplicativo novamente para a região primária. O processo usará as etapas ilustradas no diagrama a seguir.
- Cancele todas as solicitações de restauração geográfica pendentes.
- Faça o failover dos bancos de dados de gerenciamento para a região primária (5). Observação: após a recuperação da região, os antigos primários se tornarão secundários automaticamente. Agora eles alternam funções novamente.
- Altere a cadeia de conexão do aplicativo para apontar de volta para a região primária. Agora, todas os novos bancos de dados de locatário e contas serão criados na região primária. Alguns clientes existentes verão seus dados como temporariamente indisponíveis.
- Defina todos os bancos de dados no pool da recuperação de desastres como somente leitura a fim de garantir que eles não poderão ser modificados na região da recuperação de desastres (6).
- Para cada banco de dados no pool da recuperação de desastres que foi alterado desde a recuperação, renomeie ou exclua os bancos de dados correspondentes no pool primário (7).
- Copie os bancos de dados atualizados do pool da recuperação de desastres para o pool primário (8).
- Exclua o pool da recuperação de desastres (9)
Neste momento, seu aplicativo estará online na região primária com todos os bancos de dados de locatário disponíveis no pool primário.
Benefício
A principal vantagem dessa estratégia é o baixo custo da redundância da camada de dados. O banco de dados SQL do Azure faz backup automaticamente de bancos de dados sem regravação de aplicativos nem custo adicional. O custo é incorrido apenas quando os bancos de dados elásticos são restaurados.
Compensação
O revés é que a recuperação completa de todos os bancos de dados de locatário levará um tempo significativo. O tempo de recuperação dependerá do número total de restaurações que você iniciar na região de DR e do tamanho geral dos bancos de dados do locatário. Mesmo se você priorizar a restauração de alguns locatários em detrimentos de outros, você estará competindo com todos as outras restaurações iniciadas na mesma região, já que o serviço arbitrará e restringirá para minimizar o impacto geral nos bancos de dados dos clientes existentes. Além disso, a recuperação dos bancos de dados do locatário não poderá ser iniciada até que o novo pool elástico na região da recuperação de desastres seja criado.
Cenário 2: Aplicativo maduro com o serviço em camadas
Tenho um aplicativo SaaS antigo com ofertas de serviço em camadas e diferentes SLAs para clientes de avaliação e para clientes pagantes. Para clientes de avaliação, preciso reduzir o custo tanto quanto possível. Os clientes de teste podem ter um tempo de inatividade, mas quero reduzir sua probabilidade. Para clientes pagantes, qualquer tempo de inatividade é um risco. Portanto, quero garantir que os clientes pagantes possam sempre acessar seus dados.
Para dar suporte a esse cenário, você deve separar os locatários de avaliação dos locatários pagos colocando-os em pools elásticos separados. Os clientes de avaliação têm menor eDTU ou vCores por locatário e menor SLA com um tempo de recuperação mais longo. Os clientes pagantes estão em um pool com maior eDTU ou vCores por locatário e um SLA maior. Para garantir o menor tempo de recuperação, os bancos de dados de locatário dos clientes pagantes devem ser replicados geograficamente. Essa configuração está ilustrada no diagrama a seguir.
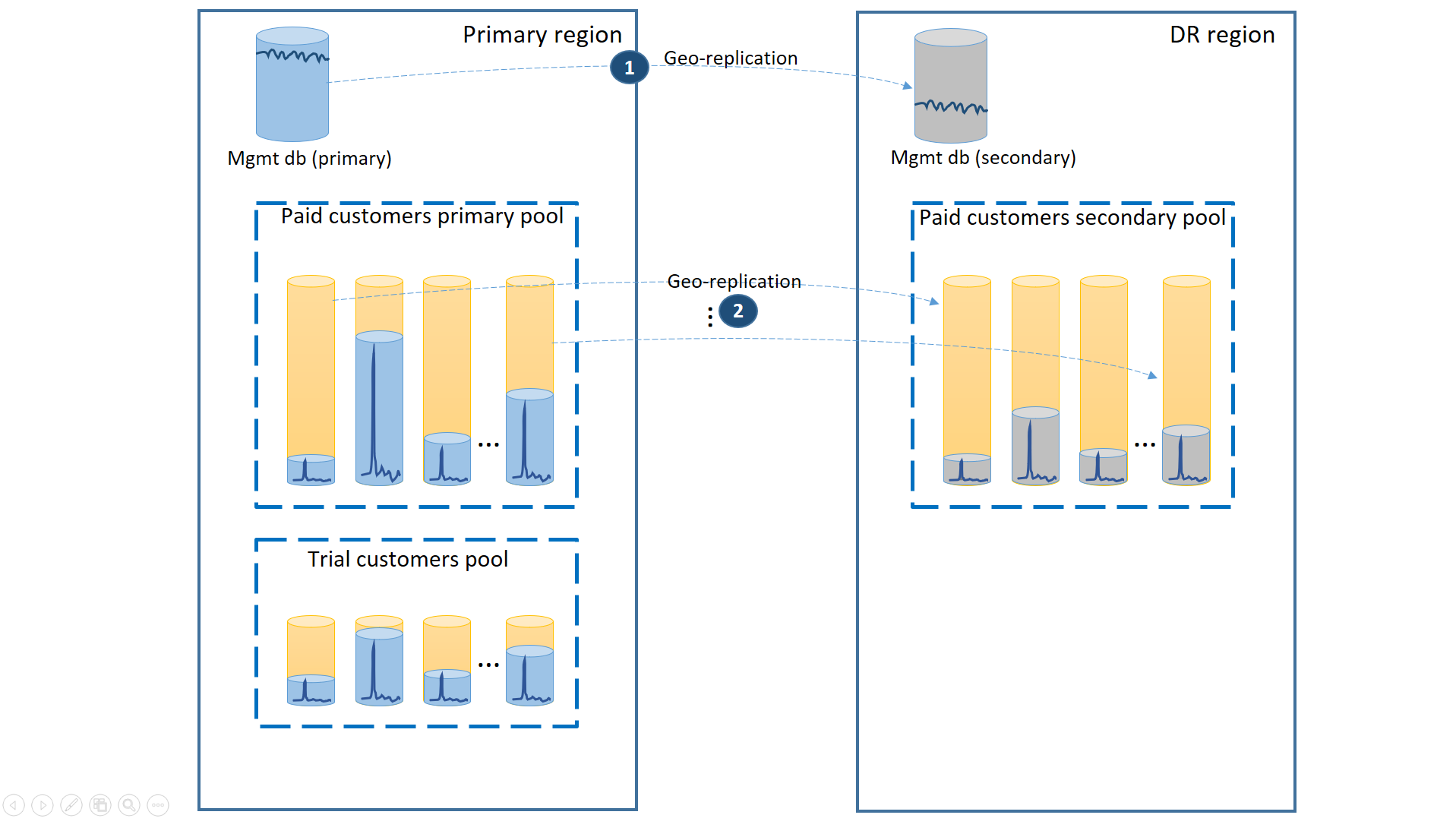
Como no primeiro cenário, os bancos de dados de gerenciamento estarão muito ativos. Portanto, use um banco de dados único replicado geograficamente para ele (1). Isso garantirá o desempenho previsível para novas assinaturas de clientes, atualizações de perfil e outras operações de gerenciamento. A região em que residem os bancos de dados de gerenciamento primários é a região primária e a região em que residem os bancos de dados de gerenciamento secundários é a região de DR.
Os bancos de dados de locatário dos clientes pagantes têm bancos de dados ativos no pool pago provisionado na região primária. Você deve provisionar um pool secundário com o mesmo nome na região de DR. Cada locatário é replicado geograficamente para o pool secundário (2). Isso permite a recuperação rápida de todos os bancos de dados do locatário usando o failover.
Se uma interrupção na região primária ocorre, as etapas de recuperação para colocar o aplicativo online estão ilustradas no seguinte diagrama:
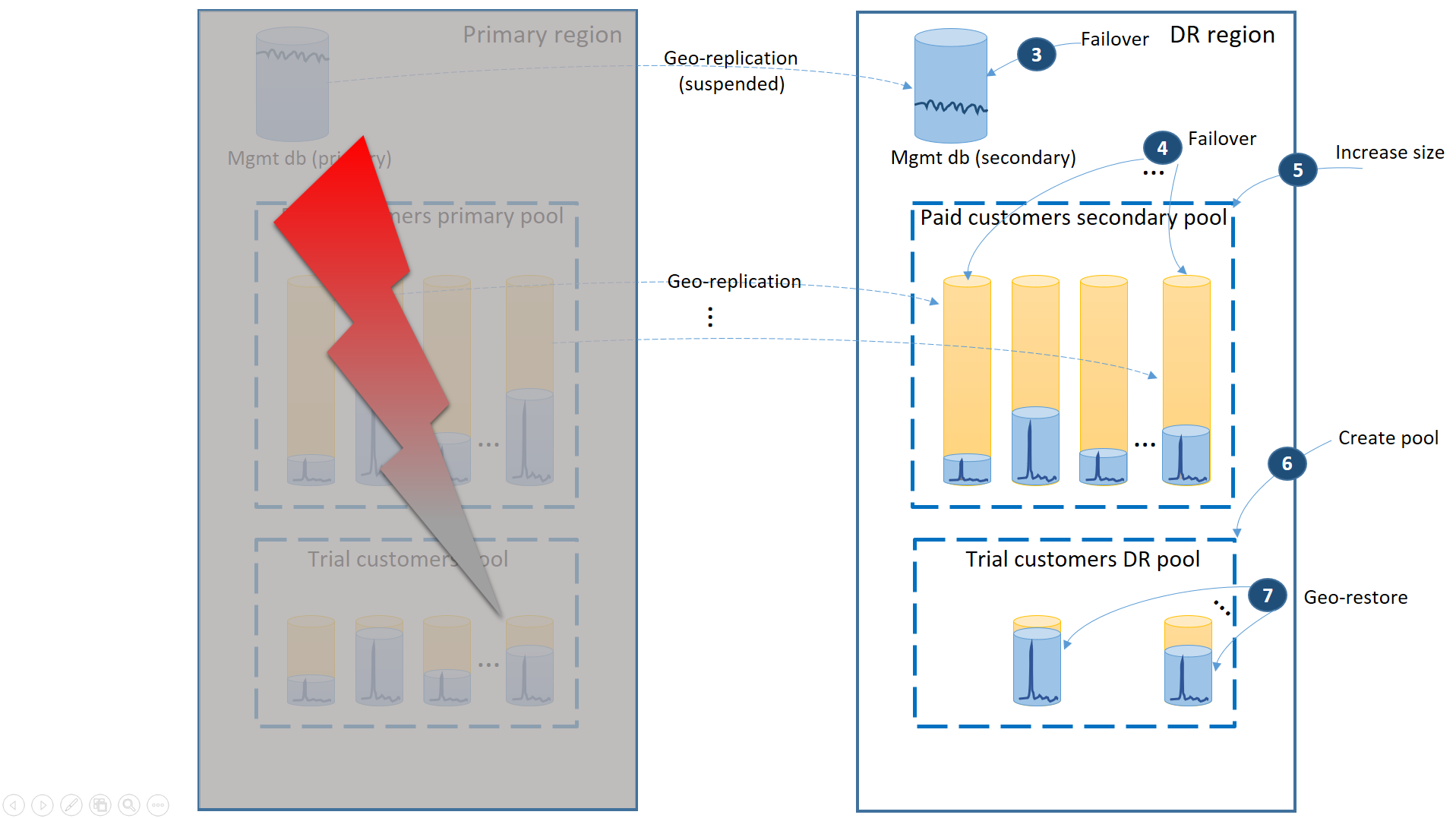
- Faça o failover imediato dos bancos de dados de gerenciamento para a região de DR (3).
- Altere a cadeia de conexão do aplicativo para apontar para a região da recuperação de desastres. Agora, todas as novas contas e bancos de dados de locatário são criados na região de DR. Os clientes de avaliação existentes verão seus dados como temporariamente indisponíveis.
- Faça o failover dos bancos de dados de locatários pagantes para o pool na região de DR para restaurar sua disponibilidade imediatamente (4). Como o failover é uma alteração rápida no nível dos metadados, você pode considerar uma otimização em que os failovers individuais são disparados sob demanda pelas conexões do usuário final.
- Se o tamanho de eDTU do pool secundário ou vCore era menor que o primário porque os bancos de dados secundários precisavam apenas da capacidade de processar os logs de alterações enquanto eram secundários, aumente imediatamente a capacidade do pool agora para acomodar a carga de trabalho completa de todos os locatários (5).
- Crie um novo pool elástico com o mesmo nome e a mesma configuração na região da recuperação de desastres para os bancos de dados dos clientes de avaliação (6).
- Depois de criar o pool dos clientes de avaliação, use a restauração geográfica para restaurar os bancos de dados de locatário de avaliação individuais no novo pool (7). Você pode cogitar disparar as restaurações individuais pelas conexões do usuário final ou usar outro esquema de prioridade específica do aplicativo.
Neste momento, seu aplicativo está online novamente na região da recuperação de desastres. Todos os clientes pagantes têm acesso aos dados, ao passo que os clientes de avaliação acessarão seus dados com atraso.
Quando a região primária é recuperada pelo Azure depois de você ter restaurado o aplicativo na região da recuperação de desastre, é possível continuar executando o aplicativo nessa região ou optar por fazer o failback para a região primária. Se a região primária for recuperada antes da conclusão do processo de failover, você deverá considerar fazer o failback imediatamente. O failback executará as etapas ilustradas no seguinte diagrama:
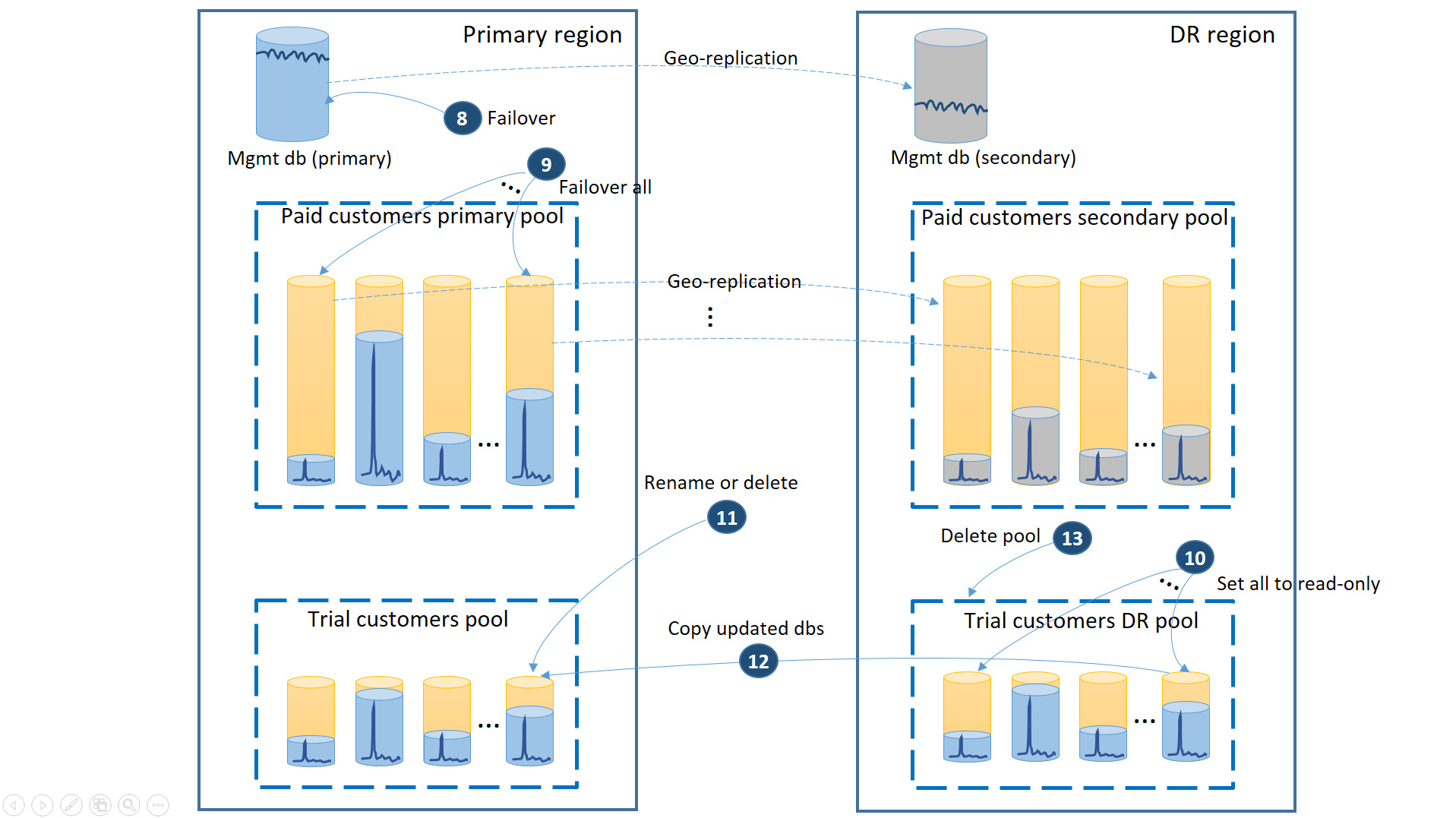
- Cancele todas as solicitações de restauração geográfica pendentes.
- Faça o failover dos bancos de dados de gerenciamento (8). Após a recuperação da região, o antigo primário se torna o secundário automaticamente. Agora, ele se tornará primário novamente.
- Faça o failover dos bancos de dados de locatário pagantes (9). Da mesma forma, após a recuperação da região, os antigos primários se tornaram secundários automaticamente. Agora, eles se tornarão primários novamente.
- Defina os bancos de dados de avaliação restaurados que foram alterados na região da recuperação de desastres como somente leitura (10).
- Para cada banco de dados no pool da recuperação de desastres dos clientes de avaliação alterados desde a recuperação, renomeie ou exclua o banco de dados correspondente no pool primário dos clientes de avaliação (11).
- Copie os bancos de dados atualizados do pool da recuperação de desastres para o pool primário (12).
- Excluir o pool da recuperação de desastres (13).
Observação
A operação de failover é assíncrona. Para minimizar o tempo de recuperação, é importante que você execute o comando de failover dos bancos de dados de locatário em lotes de pelo menos 20 bancos de dados.
Benefício
A principal vantagem dessa estratégia é que ela fornece o SLA mais alto para os clientes pagantes. Ela também garante que as novas avaliações sejam desbloqueadas assim que o pool da recuperação de desastres de avaliação seja criado.
Compensação
O revés é que essa configuração aumentará o custo total de bancos de dados do locatário pelo custo do pool da DR secundária para clientes pagantes. Além disso, se o pool secundário tiver um tamanho diferente, os clientes pagantes verão um menor desempenho depois do failover até que a atualização de pool na região de DR seja concluída.
Cenário 3: Aplicativo distribuído geograficamente com o serviço em camadas
Eu tenho um aplicativo SaaS evoluído com ofertas de serviço em camadas. Quero oferecer um SLA muito agressivo para meus clientes pagos e minimizar o risco do impacto quando ocorrerem paralisações porque mesmo uma breve interrupção pode causar a insatisfação do cliente. É essencial que os clientes pagantes sempre possam acessar seus dados. As avaliações são gratuitas e não há oferta de SLA durante o período de avaliação.
Para oferecer suporte a esse cenário, use três pools elásticos separados. Forneça dois pools de tamanho igual com eDTUs ou vCores altos por banco de dados em duas regiões diferentes para conter os bancos de dados de locatário dos clientes pagos. O terceiro pool contendo os locatários de avaliação pode ter menores eDTUs ou vCores por banco de dados e ser provisionado em uma das duas regiões.
Para garantir o menor tempo de recuperação durante as interrupções, os bancos de dados de locatário de clientes pagantes deverão ser replicados geograficamente com 50% dos bancos de dados primários em cada uma das duas regiões. Da mesma forma, cada região tem 50% dos bancos de dados secundários. Dessa forma, se uma região estivesse offline, apenas 50% dos bancos de dados dos clientes pagantes serão afetados e teriam de fazer failover. Os outros bancos de dados permanecem intactos. Essa configuração é ilustrada no diagrama abaixo:
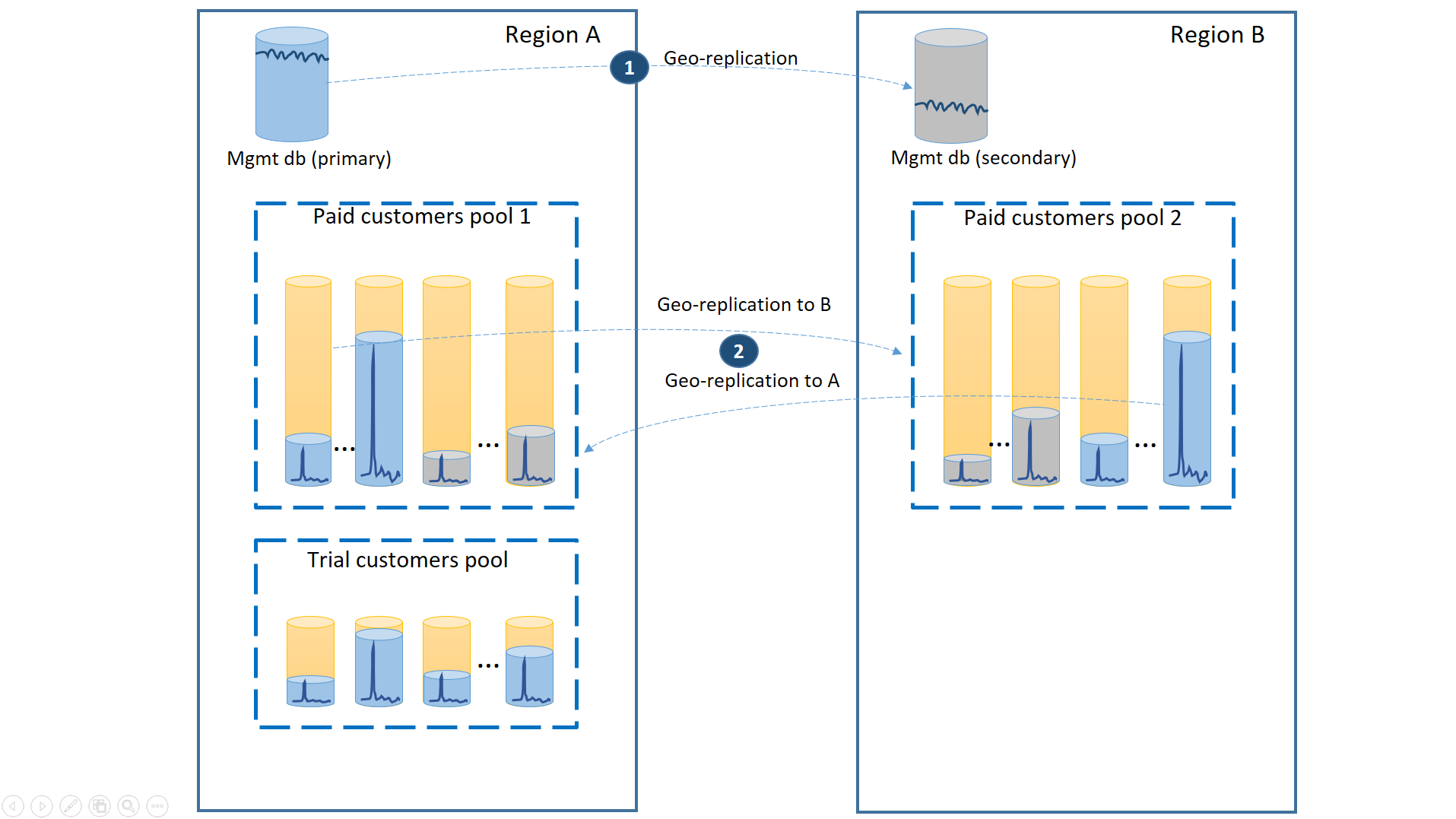
Como nos cenários anteriores, os bancos de dados de gerenciamento estarão muito ativos e, portanto, você deverá configurá-los como bancos de dados únicos replicados geograficamente (1). Isso garantirá o desempenho previsível para novas assinaturas de clientes, atualizações de perfil e outras operações de gerenciamento. A região A é a região primária para os bancos de dados de gerenciamento e a região B é usada para recuperação dos bancos de dados de gerenciamento.
Os bancos de dados de locatário dos clientes pagantes também serão replicados geograficamente, mas com primários e secundários divididos entre a região A e a região B (2). Dessa forma, os bancos de dados primários do locatário afetados pela interrupção podem fazer failover para a outra região e ficarem disponíveis. A outra metade dos bancos de dados de locatário não será afetada.
O diagrama a seguir ilustra as etapas de recuperação em caso de falha na região A.
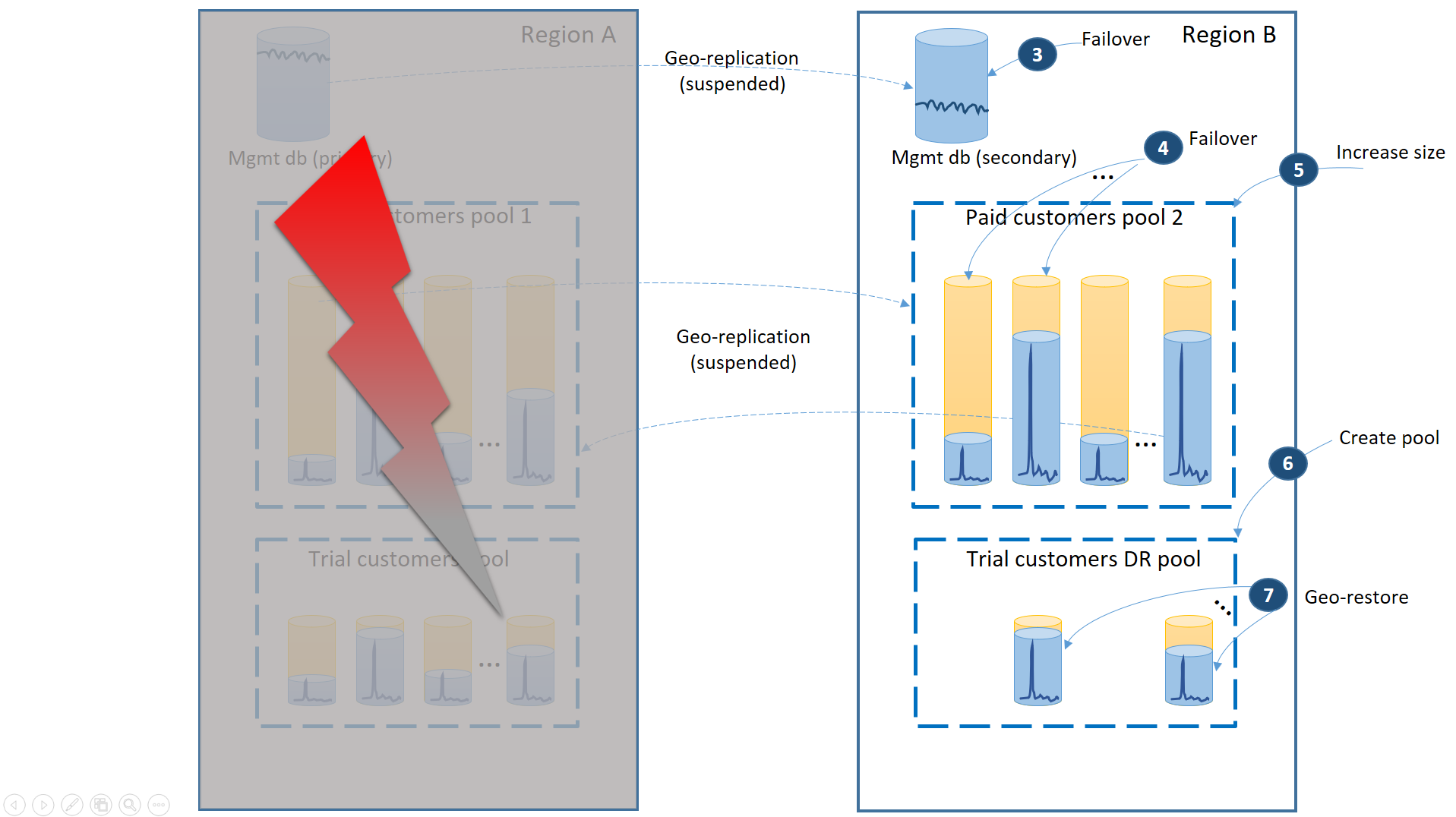
- Faça imediatamente o failover dos bancos de dados de gerenciamento para a região B (3).
- Altere a cadeia de conexão do aplicativo para apontar para os bancos de dados de gerenciamento na região B. Modifique os bancos de dados de gerenciamento para garantir que as novas contas e bancos de dados de locatário sejam criados na região B e que os bancos de dados existentes do inquilino estejam lá também. Os clientes de avaliação existentes verão seus dados como temporariamente indisponíveis.
- Faça o failover dos bancos de dados de locatários pagantes para o pool 2 na região B para restaurar imediatamente sua disponibilidade (4). Como o failover é uma alteração rápida no nível dos metadados, você pode considerar uma otimização em que os failovers individuais são disparados sob demanda pelas conexões do usuário final.
- Como agora o pool 2 contém apenas bancos de dados primários, a carga de trabalho total no pool aumenta e pode aumentar imediatamente o tamanho de eDTU (5) ou o número de vCores.
- Crie um novo pool elástico com o mesmo nome e a mesma configuração na região B para bancos de dados dos clientes de avaliação (6).
- Depois de criar o pool, use a restauração geográfica para restaurar os bancos de dados de locatário de avaliação individuais no pool (7). Você pode cogitar disparar as restaurações individuais pelas conexões do usuário final ou usar outro esquema de prioridade específica do aplicativo.
Observação
A operação de failover é assíncrona. Para minimizar o tempo de recuperação, é importante que você execute o comando de failover dos bancos de dados de locatário em lotes de pelo menos 20 bancos de dados.
Neste ponto, seu aplicativo está novamente online na região B. Todos os clientes pagantes terão acesso aos dados, ao passo que os clientes de avaliação acessarão seus dados com atraso.
Quando a região A for recuperada, você precisará decidir se deseja usar a região B para clientes de avaliação ou fazer o failback usando o pool de clientes de avaliação na região A. Um critério poderia ser a % dos bancos de dados de locatário de avaliação modificados desde a recuperação. Independentemente dessa decisão, você precisará balancear novamente os locatários pagantes entre dois pools. O próximo diagrama ilustra o processo quando os bancos de dados de locatário fazem failback para a região A.
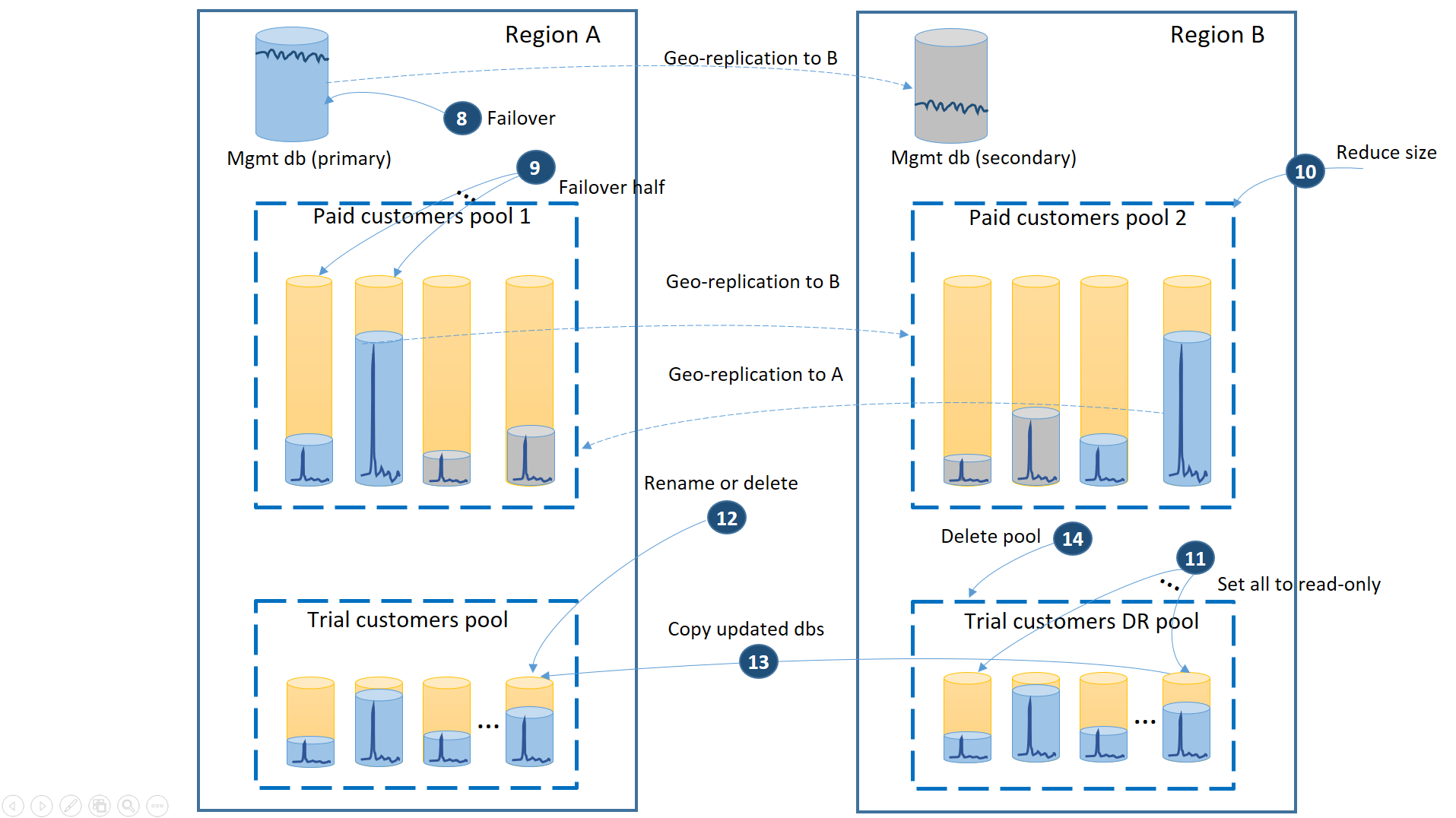
- Cancele todas as solicitações de restauração geográfica pendentes para o pool da recuperação de desastres de avaliação.
- Faça o failover do banco de dados de gerenciamento (8). Após a recuperação da região, o antigo primário se torna secundário automaticamente. Agora, ele se tornará primário novamente.
- Escolha quais bancos de dados de locatário pagantes farão failback para o pool 1 e iniciarão o failover para seus secundários (9). Após a recuperação da região, todos os bancos de dados no pool 1 se tornam secundários automaticamente. Agora, 50% deles se tornarão primários novamente.
- Reduza o tamanho do pool 2 para a eDTU original (10) ou o número de vCores.
- Defina todos os bancos de dados de avaliação na região B como somente leitura (11).
- Para cada banco de dados no pool da DR de avaliação que foi alterado desde a recuperação, renomeie ou exclua os bancos de dados correspondentes no pool primário de avaliação (12).
- Copie os bancos de dados atualizados do pool da recuperação de desastres para o pool primário (13).
- Excluir o pool da recuperação de desastres (14).
Benefício
As principais vantagens dessa estratégia são:
- Ela dá suporte ao SLA mais agressivo para os clientes pagantes porque faz com que uma interrupção não possa afetar mais de 50% dos bancos de dados de locatário.
- Ela faz com que as novas avaliações sejam desbloqueadas assim que a trilha do pool da recuperação de desastres for criada durante a recuperação.
- Ela permite um uso mais eficiente da capacidade do pool, já que 50% dos bancos de dados secundários nos pools 1 e 2 são garantidamente menos ativos que os bancos de dados primários.
Compensações
Os principais poréns são:
- As operações CRUD em relação aos bancos de dados de gerenciamento terão menor latência para os usuários finais conectados à região A que para os usuários finais conectados à região B, já que elas serão executadas em relação ao primário dos bancos de dados de gerenciamento.
- Ele requer um design mais complexo do banco de dados de gerenciamento. Por exemplo, cada registro de locatário precisa ter um rótulo de local que tem que ser alterado durante o failover e o failback.
- Os clientes pagantes podem sentir um desempenho menor que o normal até que a atualização do pool na região B seja concluída.
Resumo
Este artigo aborda as estratégias de recuperação de desastres para a camada de banco de dados usada por um aplicativo ISV SaaS multilocatário. A estratégia escolhida é baseada nas necessidades do aplicativo, como o modelo de negócios, o SLA que você deseja oferecer a seus clientes, restrição de orçamento etc. Cada estratégia descrita descreve os benefícios e a compensação para que você possa tomar uma decisão informada. Além disso, seu aplicativo específico provavelmente incluirá outros componentes do Azure. Sendo assim, você deve examinar suas diretrizes de continuidade de negócios e coordenar com elas a recuperação da camada de banco de dados. Para saber mais sobre o gerenciamento da recuperação de aplicativos de banco de dados no Azure, confira Como criar soluções de nuvem para recuperação de desastres.
Próximas etapas
- Para saber mais sobre backups automatizados do Banco de Dados SQL do Azure, confira Backups automatizados do Banco de Dados SQL do Azure.
- Para obter uma visão geral e os cenários de continuidade dos negócios, consulte Visão geral da continuidade dos negócios.
- Para saber mais sobre como usar backups automatizados para recuperação, consulte Restaurar um banco de dados de backups iniciados pelo serviço.
- Para saber mais sobre opções de recuperação mais rápidas, consulte Replicação geográfica ativa e Grupos de failover.
- Para saber mais sobre como usar backups automatizados para arquivamento, confira Cópia de banco de dados.