Tutorial: Sincronizar dados do SQL do Azure no Edge para o Armazenamento de Blobs do Azure usando o Azure Data Factory
Importante
O SQL do Azure no Edge será desativado em 30 de setembro de 2025. Para obter mais informações e opções de migração, veja o Aviso de aposentadoria.
Observação
O SQL do Azure no Edge encerrou o suporte à plataforma ARM64.
Este tutorial mostra como usar o Azure Data Factory para sincronizar dados de maneira incremental de uma tabela em uma instância do SQL do Azure no Edge para um Armazenamento de Blobs do Azure.
Antes de começar
Se você ainda não criou um banco de dados ou uma tabela em sua implantação do SQL do Azure no Edge, use um destes métodos para criar um:
Use o SQL Server Management Studio ou o Azure Data Studio para conectar-se a um SQL do Azure no Edge. Execute um script SQL para criar o banco de dados e a tabela.
Crie um banco de dados e uma tabela usando sqlcmd, conectando-se diretamente ao módulo do SQL no Edge. Para obter mais informações, confira Conectar-se ao Mecanismo de Banco de Dados usando SQLCMD.
Use SQLPackage.exe para implantar um arquivo do pacote de DAC no contêiner do SQL do Azure no Edge. Você pode automatizar esse processo especificando o URI do arquivo SqlPackage como parte da configuração das propriedades desejadas do módulo. Você também pode usar diretamente a ferramenta de cliente SqlPackage.exe para implantar um pacote de DAC no SQL do Azure no Edge.
Para obter informações sobre como baixar o SqlPackage.exe, confira Baixar e instalar o sqlpackage. A seguir estão alguns comandos de exemplo para o SqlPackage.exe. Para obter mais informações, confira a documentação do SqlPackage.exe.
Criar um pacote de DAC
sqlpackage /Action:Extract /SourceConnectionString:"Data Source=<Server_Name>,<port>;Initial Catalog=<DB_name>;User ID=<user>;Password=<password>" /TargetFile:<dacpac_file_name>Aplicar um pacote de DAC
sqlpackage /Action:Publish /Sourcefile:<dacpac_file_name> /TargetServerName:<Server_Name>,<port> /TargetDatabaseName:<DB_Name> /TargetUser:<user> /TargetPassword:<password>
Criar uma tabela SQL e um procedimento para armazenar e atualizar os níveis de marca-d'água
Uma tabela de marca-d'água é usada para armazenar o último carimbo de data/hora até o qual os dados foram sincronizados com o Armazenamento do Azure. Um procedimento armazenado T-SQL (Transact-SQL) é usado para atualizar a tabela de marca-d'água após cada sincronização.
Execute estes comandos na instância do SQL do Azure no Edge:
CREATE TABLE [dbo].[watermarktable] (
TableName VARCHAR(255),
WatermarkValue DATETIME,
);
GO
CREATE PROCEDURE usp_write_watermark @timestamp DATETIME,
@TableName VARCHAR(50)
AS
BEGIN
UPDATE [dbo].[watermarktable]
SET [WatermarkValue] = @timestamp
WHERE [TableName] = @TableName;
END
GO
Criar um pipeline do Data Factory
Nesta seção, você cria um pipeline do Azure Data Factory para sincronizar os dados de uma tabela em um SQL do Azure no Edge para um Armazenamento de Blobs do Azure.
Criar um data factory usando a interface do usuário do Data Factory
Crie um Data Factory seguindo as instruções fornecidas neste tutorial.
Criar um pipeline do Data Factory
Na página Introdução da interface do usuário do Data Factory, selecione Criar pipeline.

Na página Geral da janela Propriedades para o pipeline, para o nome, insira PeriodicSync.
Adicione a atividade Pesquisa para obter o valor antigo da marca-d'água. No painel Atividades, expanda Geral e arraste a atividade de Pesquisa para a superfície do designer de pipeline. Altere o nome da atividade para OldWatermark.
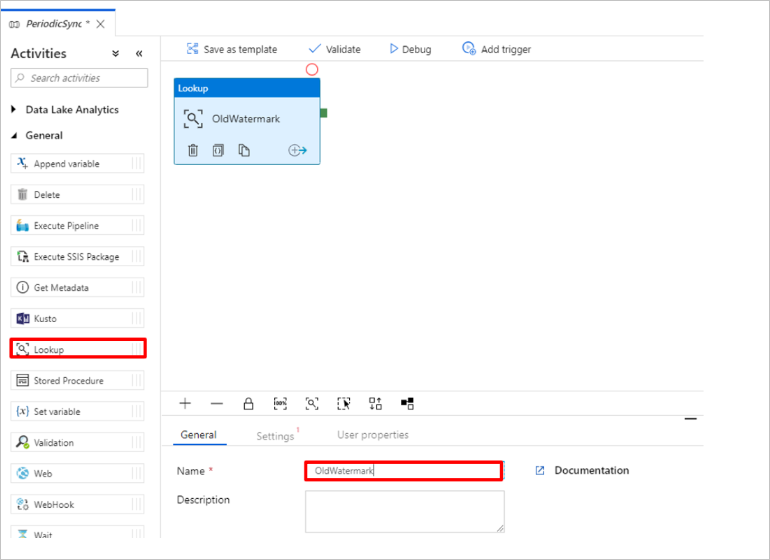
Alterne para a guia Configurações e, para o Conjunto de Dados de Origem, selecione Novo. Você criará agora um conjunto de dados para representar os dados na tabela de marca-d'água. Esta tabela contém a marca d'água antiga que foi usada na operação de cópia anterior.
Na janela Novo Conjunto de Dados, selecione SQL Server do Azure e selecione Continuar.
Na janela Definir Propriedades para o conjunto de dados, em Nome, insira WatermarkDataset.
Para Serviço Vinculado, selecione Novo e conclua estas etapas:
Em Nome, insira SQLDBEdgeLinkedService.
Em Nome do Servidor, insira os detalhes do servidor do SQL do Azure no Edge.
Selecione o Nome do banco de dados na lista.
Insira o Nome de Usuário e a Senha.
Para testar a conexão à instância do SQL do Azure no Edge, clique em Testar conexão.
Selecione Criar.
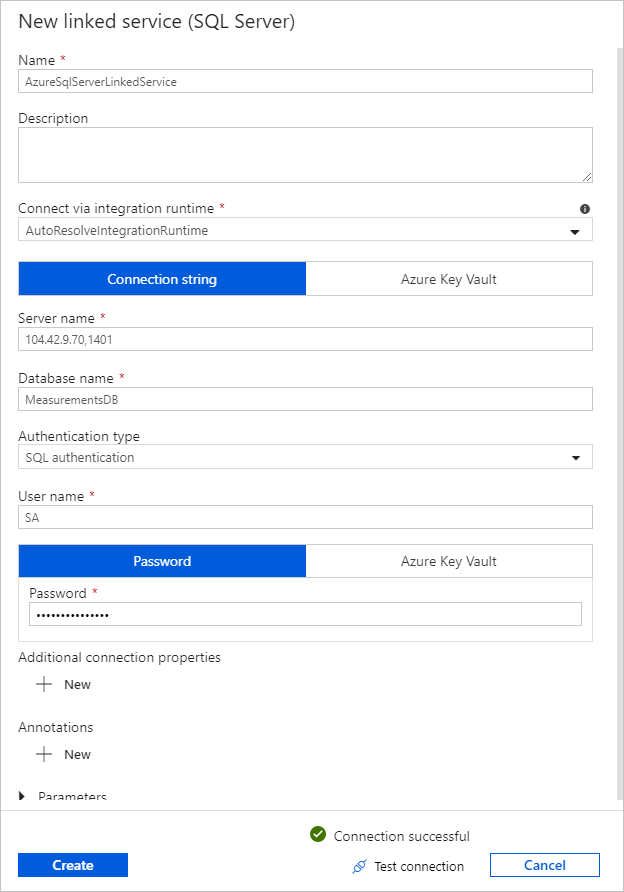
Selecione OK.
Na guia Configurações, selecione Editar.
Na guia Conexão, selecione
[dbo].[watermarktable]para Tabela. Se você quiser visualizar os dados na tabela, selecione Visualizar Dados.Alterne para o editor de pipeline selecionando a guia Pipeline na parte superior ou selecionando o nome do pipeline no modo de exibição de árvore à esquerda. Na janela Propriedades para a atividade de Pesquisa, confirme se WatermarkDataset está selecionado para o campo Conjunto de dados de origem.
No painel Atividades, expanda Geral e arraste outra atividade de Pesquisa para a superfície do designer de pipeline. Defina o nome para NewWatermark na guia geral da janela Propriedades. Esta atividade de Pesquisa obtém o novo valor de marca-d'água da tabela que contém os dados de origem para que esse valor possa ser copiado para o destino.
Na janela Propriedades da segunda atividade de Pesquisa, alterne para a guia Configurações e selecione Novo para criar um conjunto de dados que aponte para a tabela de origem que contém o novo valor de marca-d'água.
Na janela Novo Conjunto de Dados, selecione a instância do SQL do Azure no Edge e selecione Continuar.
Na janela Definir propriedades, em Nome, insira SourceDataset. Em Serviço vinculado, selecione SQLDBEdgeLinkedService.
Em Tabela, selecione a tabela que você deseja sincronizar. Você também pode especificar uma consulta para esse conjunto de dados, conforme mencionado mais adiante neste tutorial. A consulta terá precedência sobre a tabela que você especificar nesta etapa.
Selecione OK.
Alterne para o editor de pipeline selecionando a guia Pipeline na parte superior ou selecionando o nome do pipeline no modo de exibição de árvore à esquerda. Na janela Propriedades para a atividade de Pesquisa, confirme se SourceDataset está selecionado na lista Conjunto de dados de origem.
Selecione Consulta em Usar consulta. Atualize o nome da tabela na consulta a seguir e, em seguida, insira a consulta. Você está selecionando apenas o valor máximo de
timestampda tabela. Verifique se você selecionou Somente primeira linha.SELECT MAX(timestamp) AS NewWatermarkValue FROM [TableName];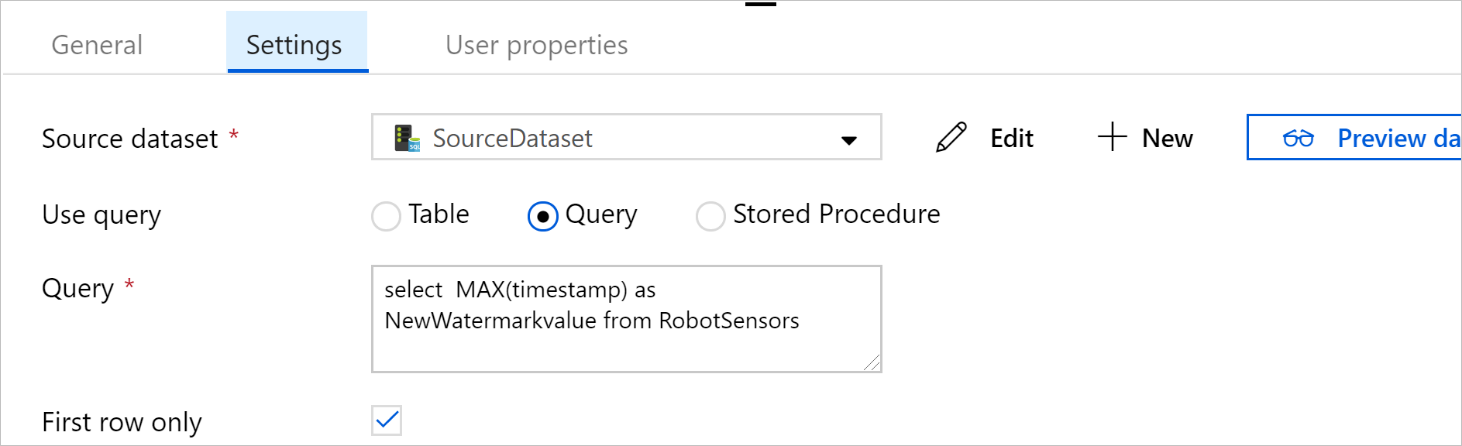
No painel Atividades, expanda Mover e Transformar e arraste a atividade Copiar do painel Atividades para a superfície do designer. Defina o nome da atividade como IncrementalCopy.
Conecte ambas as atividades de Pesquisa à atividade de Cópia arrastando o botão verde anexado às atividades de Pesquisa para a atividade de Cópia. Solte o botão do mouse quando a cor da borda da atividade de Cópia ficar azul.
Selecione a atividade de Cópia e confirme se você vê as propriedades da atividade na janela Propriedades.
Alterne para a guia Fonte na janela Propriedades e conclua estas etapas:
Na caixa Conjunto de dados de origem, selecione SourceDataset.
Em Usar consulta, selecione Consulta.
Insira a consulta SQL na caixa Consulta. Aqui está um exemplo de consulta:
SELECT * FROM TemperatureSensor WHERE timestamp > '@{activity(' OldWaterMark ').output.firstRow.WatermarkValue}' AND timestamp <= '@{activity(' NewWaterMark ').output.firstRow.NewWatermarkvalue}';Na guia Coletor, selecione Novo em Conjunto de Dados do Coletor.
Neste tutorial, o armazenamento de dados do coletor é um armazenamento de dados do Armazenamento de Blobs do Azure. Selecione Armazenamento de Blobs do Azure depois selecione Continuar na janela Novo Conjunto de Dados.
Na janela Selecionar Formato, selecione o formato dos seus dados e depois selecione Continuar.
Na janela Definir Propriedades, em Nome, insira SinkDataset. Em Serviço vinculado, selecione Novo. Você agora criará uma conexão (um serviço vinculado) ao Armazenamento de Blobs do Azure.
Na janela Novo Serviço Vinculado (Armazenamento de Blobs do Azure) , conclua estas etapas:
Na caixa Nome, insira AzureStorageLinkedService.
Em Nome da Conta de Armazenamento, selecione a conta do Armazenamento do Microsoft Azure para a sua assinatura do Azure.
Teste a conexão e selecione Concluir.
Na janela Definir Propriedades, confirme se AzureStorageLinkedService está selecionado em Serviço vinculado. Selecione Criar e OK.
Na guia Coletor, selecione Editar.
Vá para a guia Conexão de SinkDataset e conclua estas etapas:
No caminho do arquivo, insira
asdedatasync/incrementalcopy, ondeasdedatasyncé o nome do contêiner de blob eincrementalcopyé o nome da pasta. Crie o contêiner caso ele não exista ou use o nome de um contêiner existente. O Azure Data Factory cria automaticamente a pasta de saídaincrementalcopyse ela não existir. Você também pode usar o botão Procurar para o Caminho de arquivo para navegar até uma pasta em um contêiner de blob.Para a parte referente ao Arquivo do Caminho de arquivo, selecione Adicionar conteúdo dinâmico [Alt+P] e, em seguida, insira
@CONCAT('Incremental-', pipeline().RunId, '.txt')na janela que se abre. Selecione Concluir. Neste tutorial, o nome do arquivo é gerado dinamicamente pela expressão. Cada execução de pipeline possui uma ID exclusiva. A atividade de Cópia usa a ID de execução para gerar o nome do arquivo.
Alterne para o editor de pipeline selecionando a guia Pipeline na parte superior ou selecionando o nome do pipeline no modo de exibição de árvore à esquerda.
No painel Atividades, expanda Geral e arraste a atividade de Procedimento armazenado do painel Atividades para a superfície de designer do pipeline. Conecte a saída verde (bem-sucedida) da atividade de Cópia à atividade de Procedimento Armazenado.
Selecione Atividade de Procedimento Armazenado no designer de pipeline e altere seu nome para
SPtoUpdateWatermarkActivity.Alterne para a guia Conta SQL e selecione *QLDBEdgeLinkedService em Serviço vinculado.
Alterne para a guia Procedimento Armazenado e conclua estas etapas:
Em Nome do procedimento armazenado, selecione
[dbo].[usp_write_watermark].Para especificar valores para os parâmetros de procedimento armazenado, selecione Importar parâmetro e insira estes valores para os parâmetros:
Nome Tipo Valor LastModifiedTime Datetime @{activity('NewWaterMark').output.firstRow.NewWatermarkvalue}TableName String @{activity('OldWaterMark').output.firstRow.TableName}Para validar as configurações de pipeline, selecione Validar na barra de ferramentas. Confirme se não houver nenhum erro de validação. Para fechar a janela Relatório de Validação do Pipeline selecione >>.
Publique as entidades (serviços vinculados, conjuntos de dados e pipelines) para o serviço de Azure Data Factory selecionando o botão Publicar Tudo. Aguarde até que você veja uma mensagem confirmando que a operação de publicação foi bem-sucedida.
Disparar um pipeline com base em uma agenda
Na barra de ferramentas do pipeline, clique em Adicionar Gatilho, selecione Novo/Editar e Novo.
Nomeie seu gatilho HourlySync. Em Tipo, selecione Agendamento. Defina a Recorrência para a cada uma hora.
Selecione OK.
Selecione Publicar Tudo.
Selecione Disparar Agora.
Alterne para a guia Monitorar à esquerda. Você pode ver o status da execução do pipeline disparado pelo gatilho manual. Selecione Atualizar para atualizar a lista.
## Conteúdo relacionado
- O pipeline do Azure Data Factory neste tutorial copia os dados de uma tabela em uma instância do SQL do Azure no Edge para uma localização no Armazenamento de Blobs do Azure uma vez a cada hora. Para saber mais sobre como usar Data Factory em outros cenários, confira estes tutoriais.