Abordagens de arquitetura para IA e ML em soluções de multilocatário
Um número cada vez maior de soluções multilocatários são criadas em torno da IA (inteligência artificial) e do aprendizado de máquina (ML). Uma solução de IA/ML multilocatário é aquela que fornece recursos semelhantes baseados em ML para qualquer número de locatários. Os locatários geralmente não podem ver ou compartilhar os dados de qualquer outro locatário, mas, em algumas situações, os locatários podem usar os mesmos modelos que outros locatários.
As arquiteturas de IA/ML multilocatário precisam considerar os requisitos de dados e modelos, bem como os recursos de computação necessários para treinar modelos e executar a inferência de modelos. É importante considerar como os modelos multilocatários de IA/ML são implantados, distribuídos e orquestrados e garantir que sua solução seja precisa, confiável e escalonável.
À medida que tecnologias de IA generativa, alimentadas por grandes e pequenos modelos de linguagem, ganham popularidade, é essencial estabelecer práticas e estratégias operacionais eficazes para gerenciar esses modelos nos ambientes de produção por meio da adoção de Operações de aprendizado de máquina (MLOps) e GenAIOps (às vezes conhecidos como LLMOps).
Considerações e requisitos
Quando você trabalha com IA e ML, é importante considerar separadamente seus requisitos de treinamento e de inferência. A finalidade do treinamento é criar um modelo preditivo baseado em um conjunto de dados. Você executa a inferência ao usar o modelo para prever algo em seu aplicativo. Cada um desses processos tem requisitos diferentes. Em uma solução multilocatário, você deve considerar como seu modelo de locação afeta cada processo. Considerando cada um desses requisitos, você pode garantir que sua solução forneça resultados precisos, tenha um bom desempenho sob carga, seja econômica e possa ser dimensionada para seu crescimento futuro.
Isolamento de locatário
Verifique se os locatários não obtêm acesso não autorizado ou indesejado aos dados ou modelos de outros locatários. Trate modelos com uma sensibilidade semelhante aos dados brutos que os treinaram. Certifique-se de que seus locatários entendam como seus dados são usados para treinar modelos e como os modelos treinados nos dados de outros locatários podem ser usados para fins de inferência em suas cargas de trabalho.
Há três abordagens comuns para trabalhar com modelos de ML em soluções multilocatários: modelos específicos de locatário, modelos compartilhados e modelos compartilhados ajustados.
Modelos específicos de locatário
Os modelos específicos de locatário são treinados apenas nos dados de um único locatário e, em seguida, são aplicados a esse único locatário. Os modelos específicos de locatário são apropriados quando os dados de seus locatários são confidenciais ou quando há pouco escopo para aprender com os dados fornecidos por um locatário e você aplica o modelo a outro locatário. O diagrama a seguir ilustra como você pode criar uma solução com modelos específicos de locatário para dois locatários:
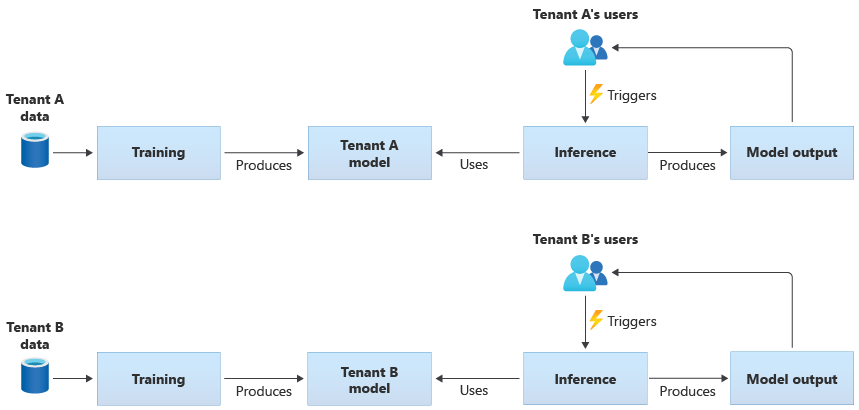
Modelos compartilhados
Em soluções que usam modelos compartilhados, todos os locatários executam inferência com base no mesmo modelo compartilhado. Modelos compartilhados podem ser modelos pré-treinados que você adquire ou obtém de uma fonte da comunidade. O diagrama a seguir ilustra como um único modelo pré-treinado pode ser usado para inferência por todos os locatários:
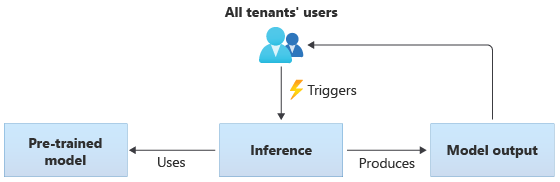
Você também pode criar seus próprios modelos compartilhados treinando-os a partir dos dados fornecidos por todos os seus locatários. O diagrama a seguir ilustra um único modelo compartilhado, que é treinado em dados de todos os locatários:
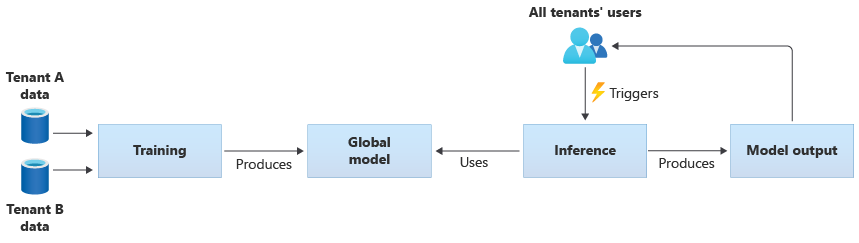
Importante
Se você treinar um modelo compartilhado a partir dos dados de seus locatários, certifique-se de que seus locatários entendam e concordem com o uso de seus dados. Certifique-se de que as informações de identificação sejam removidas dos dados de seus locatários.
Pense no que fazer, se um locatário se opuser a seus dados serem usados para treinar um modelo que será aplicado a outro locatário. Por exemplo, você poderia excluir dados de locatários específicos do conjunto de dados de treinamento?
Modelos compartilhados ajustados
Você também pode optar por adquirir um modelo base pré-treinado e, em seguida, executar um ajuste de modelo adicional para torná-lo aplicável a cada um de seus locatários, com base nos próprios dados deles. O diagrama a seguir ilustra essa abordagem:
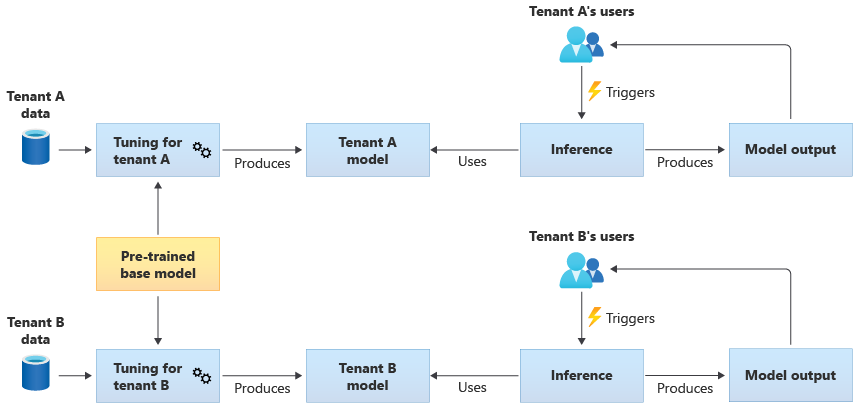
Escalabilidade
Considere como o crescimento da sua solução afeta o uso de componentes de IA e ML. O crescimento pode se referir a um aumento no número de locatários, à quantidade de dados armazenados para cada locatário, ao número de usuários e ao volume de solicitações para a sua solução.
Treinamento: Há vários fatores que influenciam os recursos necessários para treinar seus modelos. Esses fatores incluem o número de modelos que você precisa treinar, a quantidade de dados com os quais você treina os modelos e a frequência com que você treina ou retreina os modelos. Se você criar modelos específicos de locatário, à medida que o número de locatários aumentar, a quantidade de recursos de computação e armazenamento necessários provavelmente também aumentará. Se você criar modelos compartilhados e treiná-los com base em dados de todos os seus locatários, é menos provável que os recursos para treinamento sejam dimensionados na mesma taxa que o crescimento do número de locatários. No entanto, um aumento na quantidade geral de dados de treinamento afetará os recursos consumidos, para treinar os modelos compartilhados e específicos de locatário.
Inferência: Os recursos necessários para inferência geralmente são proporcionais ao número de solicitações que acessam os modelos para inferência. À medida que o número de locatários aumenta, o número de solicitações provavelmente também aumentará.
É uma boa prática geral usar os serviços do Azure que dimensionam bem. Como as cargas de trabalho de IA/ML tendem a usar contêineres, o AKS (Serviço de Kubernetes do Azure) e ACI (Instâncias de Contêiner do Azure) tendem a ser opções comuns para cargas de trabalho de IA/ML. O AKS geralmente é uma boa opção para habilitar a alta escala e dimensionar dinamicamente seus recursos de computação com base na demanda. Para cargas de trabalho pequenas, a ACI pode ser uma plataforma de computação simples a ser configurada, embora não seja dimensionada tão facilmente quanto o AKS.
Desempenho
Considere os requisitos de desempenho para os componentes de IA/ML da sua solução, para treinamento e inferência. É importante esclarecer seus requisitos de latência e desempenho para cada processo, para que você possa medir e melhorar conforme necessário.
Treinamento: O treinamento geralmente é executado como um processo em lote, o que significa que ele pode não ser tão sensível ao desempenho quanto outras partes da sua carga de trabalho. No entanto, você precisa garantir que provisione recursos suficientes para executar seu treinamento de modelo com eficiência, inclusive conforme você dimensiona.
Inferência: A inferência é um processo sensível à latência, que geralmente exige uma resposta rápida ou até mesmo em tempo real. Mesmo que você não precise executar uma inferência em tempo real, certifique-se de monitorar o desempenho da sua solução e usar os serviços apropriados para otimizar sua carga de trabalho.
Considere a possibilidade de usar os recursos de computação de alto desempenho do Azure para suas cargas de trabalho de IA e ML. O Azure fornece muitos tipos diferentes de máquinas virtuais e outras instâncias de hardware. Considere se sua solução se beneficiaria do uso de CPUs, GPUs, FPGAs ou outros ambientes acelerados por hardware. O Azure também fornece inferência em tempo real com GPUs NVIDIA, incluindo servidores de inferência NVIDIA Triton. Para requisitos de computação de baixa prioridade, considere o uso de pools de nós spot do AKS. Para saber mais sobre como otimizar serviços de computação em uma solução multilocatário, confira Abordagens de arquitetura para computação em soluções multilocatários.
Como o treinamento de modelo normalmente requer muitas interações com seus armazenamentos de dados, também é importante considerar sua estratégia de dados e o desempenho que sua camada de dados fornece. Para obter mais informações sobre serviços de dados e multilocatários, confira Abordagens de arquitetura para armazenamento e dados em soluções multilocatários.
Considere a criação de perfil do desempenho da sua solução. Por exemplo, o Azure Machine Learning fornece recursos de criação de perfil que você pode usar ao desenvolver e instrumentar sua solução.
Complexidade da implementação
Ao criar uma solução para usar IA e ML, você pode optar por usar componentes predefinidos ou criar componentes personalizados. Há duas decisões importantes que você precisa tomar. A primeiro é a plataforma ou serviço usado para IA e ML. A segunda é se você usará modelos pré-treinados ou criará seus próprios modelos personalizados.
Plataformas: Há muitos serviços do Azure que você pode usar para suas cargas de trabalho de IA e ML. Por exemplo, os Serviços de IA do Azure e o Serviço OpenAI do Azure fornecem APIs para executar uma inferência em relação a modelos predefinidos, e a Microsoft gerencia os recursos subjacentes. Os Serviços de IA do Azure permitem implantar rapidamente uma nova solução, mas fornecem menos controle sobre como o treinamento e a inferência são executados e podem não atender a todos os tipos de carga de trabalho. Por outro lado, o Azure Machine Learning é uma plataforma que permite criar, treinar e usar seus próprios modelos de ML. O Azure Machine Learning fornece controle e flexibilidade, mas aumenta a complexidade de seu design e implementação. Examine os produtos e tecnologias de aprendizado de máquina da Microsoft para tomar uma decisão informada ao selecionar uma abordagem.
Modelos: mesmo quando você não usa um modelo completo fornecido por um serviço como os Serviços de IA do Azure, você ainda pode acelerar seu desenvolvimento usando um modelo pré-treinado. Se um modelo pré-treinado não atender precisamente às suas necessidades, considere estender um modelo pré-treinado aplicando uma técnica chamada transferência de aprendizado ou ajuste fino. O aprendizado de transferência permite estender um modelo existente e aplicá-lo a um domínio diferente. Por exemplo, se você estiver criando um serviço de recomendação de música multilocatário, pode considerar a criação de um modelo pré-treinado de recomendações de música e usar o aprendizado de transferência para treinar o modelo para as preferências de música de um usuário específico.
Usando plataformas predefinidas de ML, como o Serviços de IA do Azure ou o Serviço OpenAI do Azure, ou um modelo pré-treinado, você pode reduzir significativamente os custos iniciais de pesquisa e desenvolvimento. O uso de plataformas predefinidas pode economizar muitos meses de pesquisa e evitar a necessidade de recrutar cientistas de dados altamente qualificados para treinar, projetar e otimizar modelos.
Otimização de custo
Em geral, as cargas de trabalho de IA e ML incorrem na maior proporção de seus custos dos recursos de computação necessários para treinamento e inferência de modelo. Examine Abordagens de arquitetura para computação em soluções multilocatários para entender como otimizar o custo da carga de trabalho de computação para seus requisitos.
Considere os seguintes requisitos ao planejar os custos de IA e ML:
- Determine as SKUs de computação para treinamento. Por exemplo, confira as diretrizes sobre como fazer isso com o Azure Machine Learning.
- Determine as SKUs de computação para inferência. Para obter uma estimativa de custo de exemplo para inferência, confira as diretrizes para o Azure Machine Learning.
- Monitore sua utilização. Observando a utilização dos recursos de computação, você pode determinar se deve diminuir ou aumentar sua capacidade implantando SKUs diferentes ou dimensionar os recursos de computação conforme seus requisitos mudam. Confira o Monitor do Azure Machine Learning.
- Otimize seu ambiente de clustering de computação. Ao usar clusters de computação, monitore a utilização do cluster ou configure o dimensionamento automático para reduzir horizontalmente os nós de computação.
- Compartilhe seus recursos de computação. Considere se você pode otimizar o custo dos recursos de computação compartilhando-os entre vários locatários.
- Considere seu orçamento. Entenda se você tem um orçamento fixo e monitore seu consumo adequadamente. Você pode configurar orçamentos para evitar gastos excessivos e alocar cotas com base na prioridade do locatário.
Abordagens e padrões a serem considerados
O Azure fornece um conjunto de serviços para habilitar cargas de trabalho de IA e ML. Há várias abordagens de arquitetura comuns usadas em soluções multilocatários: usar soluções de IA/ML predefinidas, criar uma arquitetura personalizada de IA/ML usando o Azure Machine Learning e usar uma das plataformas de análise do Azure.
Usar serviços de IA/ML predefinidos
É uma boa prática tentar usar serviços de IA/ML predefinidos, onde você pode. Por exemplo, sua organização pode estar começando a examinar a IA/ML e deseja integrar-se rapidamente a um serviço útil. Ou talvez você tenha requisitos básicos que não exijam treinamento e desenvolvimento de modelo de ML personalizados. Os serviços de ML predefinidos permitem que você use a inferência sem criar e treinar seus próprios modelos.
O Azure oferece vários serviços que fornecem tecnologia de IA e ML em um intervalo de domínios, incluindo reconhecimento de linguagem, reconhecimento de fala, conhecimento, reconhecimento de documentos e formulários e visão computacional. Os serviços de IA/ML pré-criados do Azure incluem os Serviços de IA do Azure, o Serviço OpenAI do Azure, a Pesquisa de IA do Azure e o IA do Azure para Informação de Documentos. Cada serviço fornece uma interface simples para integração e uma coleção de modelos pré-treinados e testados. Como serviços gerenciados, eles fornecem contratos de nível de serviço e exigem pouca configuração ou gerenciamento contínuo. Você não precisa desenvolver ou testar seus próprios modelos para usar esses serviços.
Muitos serviços de ML gerenciados não exigem treinamento de modelo ou dados, portanto, geralmente não há preocupações de isolamento de dados de locatário. No entanto, quando você trabalha com a Pesquisa de IA em uma solução multilocatário, examine os Padrões de design para aplicativos SaaS multilocatários e Pesquisa de IA do Azure.
Considere os requisitos de escala para os componentes em sua solução. Por exemplo, muitas das APIs nos Serviços de IA do Azure dão suporte a um número máximo de solicitações por segundo. Se você implantar um único recurso dos Serviços de IA para compartilhar entre seus locatários, à medida que o número de locatários aumenta, talvez seja necessário dimensionar para vários recursos.
Observação
Alguns serviços gerenciados permitem que você treine com seus próprios dados, incluindo o serviço de Visão Personalizada, a API de Detecção Facial, os modelos personalizados para Informação de Documentos e alguns modelos do OpenAI que dão suporte à personalização e ao ajuste fino. Quando você trabalha com esses serviços, é importante considerar os requisitos de isolamento para os dados de seus locatários.
Arquitetura personalizada de IA/ML
Se sua solução exigir modelos personalizados ou você trabalhar em um domínio que não seja coberto por um serviço de ML gerenciado, considere criar sua própria arquitetura de IA/ML. O Azure Machine Learning fornece um conjunto de recursos para orquestrar o treinamento e a implantação de modelos de ML. O Azure Machine Learning dá suporte a muitas bibliotecas de machine learning de software livre, incluindo PyTorch, TensorFlow, Scikite Keras. Você pode monitorar continuamente as métricas de desempenho dos modelos, detectar o descompasso de dados e disparar o retreinamento para melhorar o desempenho do modelo. Durante todo o ciclo de vida de seus modelos de ML, o Azure Machine Learning permite a auditoria e a governança com acompanhamento interno e linhagem para todos os artefatos de ML.
Ao trabalhar em uma solução multilocatário, é importante considerar os requisitos de isolamento de seus locatários durante os estágios de treinamento e inferência. Você também precisa determinar o processo de treinamento e implantação do modelo. O Azure Machine Learning fornece um pipeline para treinar modelos e implantá-los em um ambiente a ser usado para inferência. Em um contexto multilocatário, considere se os modelos devem ser implantados em recursos de computação compartilhados ou se cada locatário tem recursos dedicados. Crie seus pipelines de implantação de modelo, com base no modelo de isolamento e no processo de implantação do locatário.
Ao usar modelos de software livre, talvez seja necessário treinar novamente esses modelos usando aprendizado de transferência ou ajuste. Considere como você gerenciará os diferentes modelos e dados de treinamento para cada locatário, bem como versões do modelo.
O diagrama a seguir ilustra uma arquitetura de exemplo que usa o Azure Machine Learning. O exemplo usa a abordagem de isolamento de modelos específicos do locatário.
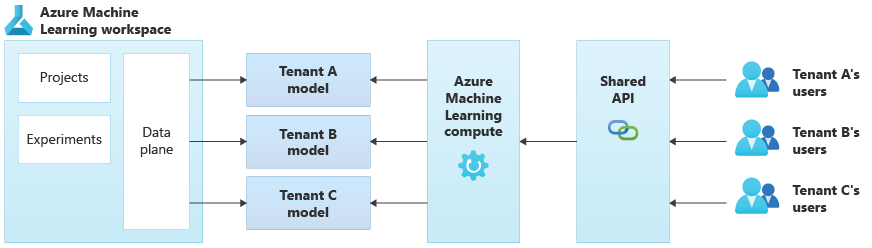
Soluções integradas de IA/ML
O Azure fornece várias plataformas de análise avançadas que podem ser usadas para uma variedade de finalidades. Essas plataformas incluem o Azure Synapse Analytics, Databricks e Apache Spark.
Você pode considerar o uso dessas plataformas para IA/ML, quando precisar dimensionar seus recursos de ML para um número muito grande de locatários e quando precisar de computação e orquestração em larga escala. Você também pode considerar o uso dessas plataformas para IA/ML, quando precisar de uma plataforma de análise ampla para outras partes da sua solução, como análise de dados e integração com relatórios por meio do Microsoft Power BI. Você pode implantar uma única plataforma que abrange todas as suas necessidades de análise e IA/ML. Ao implementar plataformas de dados em uma solução multilocatário, examine Abordagens de arquitetura para armazenamento e dados em soluções multilocatários.
Modo operacional de ML
Ao adotar a IA e o aprendizado de máquina, incluindo práticas de IA generativa, é recomendável melhorar e avaliar continuamente suas capacidades organizacionais ao gerenciá-las. A introdução de MLOps e GenAIOps fornece objetivamente uma estrutura para expandir continuamente os recursos das práticas de IA e ML na sua organização. Revise os documentos Modelo de maturidade do MLOps e Modelo de maturidade do LLMOps para obter mais orientações.
Antipadrões a serem evitados
- Falha ao considerar os requisitos de isolamento. É importante considerar cuidadosamente como você isola os dados e modelos dos locatários, tanto para treinamento quanto para inferência. Não fazer isso pode violar requisitos legais ou contratuais. Isso também pode reduzir a precisão de seus modelos para treinar entre os dados de vários locatários, se os dados forem substancialmente diferentes.
- Vizinhos barulhentos. Considere se os processos de treinamento ou inferência podem estar sujeitos ao problema do Vizinho Barulhento. Por exemplo, se você tiver vários locatários grandes e um único locatário pequeno, verifique se o treinamento de modelo para os locatários grandes não consome inadvertidamente todos os recursos de computação e enfraquecer os locatários menores. Use a governança de recursos e o monitoramento para atenuar o risco da carga de trabalho de computação de um locatário afetada pela atividade dos outros locatários.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- Kevin Ashley | Engenheiro de cliente sênior, FastTrack para Azure
Outros colaboradores:
- Paul Burpo | Engenheiro de cliente principal, FastTrack para Azure
- John Downs | Engenheiro de software principal
- Daniel Scott-Raynsford | Estrategista de Tecnologia Do Parceiro
- Arsen Vladimirskiy | Engenheiro principal de atendimento ao cliente, FastTrack for Azure
- Vic Perdana | Brasil | Arquiteto de soluções de parceiros ISV
Próximas etapas
- Revise Abordagens de arquitetura para computação em soluções de multilocatário.
- Para saber mais sobre como criar pipelines do Azure Machine Learning para dar suporte a vários locatários, consulte Uma solução para pipeline de ML em várias locações.