Em geral, os dados são considerados a parte mais valiosa de uma solução, pois representam suas informações comerciais importantes, além das informações de seus clientes. Portanto, é importante gerenciar cuidadosamente seus dados. Ao planejar o armazenamento ou os componentes de dados para um sistema multilocatário, você precisa decidir sobre uma abordagem para compartilhar ou isolar os dados de seus locatários.
Neste artigo, fornecemos diretrizes sobre as principais considerações e requisitos essenciais para os arquitetos de solução ao decidir uma abordagem para armazenar dados em um sistema multilocatário. Em seguida, sugerimos alguns padrões comuns para aplicar multilocação a serviços de armazenamento e dados, bem como alguns antipadrões a serem evitados. Por fim, fornecemos diretrizes para algumas situações específicas.
Considerações e requisitos
É importante considerar as abordagens que você usa para serviços de armazenamento e dados de várias perspectivas, incluindo os pilares do Azure Well-Architected Framework.
Escala
Ao trabalhar com serviços que armazenam seus dados, você deve considerar o número de locatários que você tem e o volume de dados armazenados. Se você tiver um pequeno número de locatários (como cinco ou menos), e estiver armazenando pequenas quantidades de dados para cada locatário, provavelmente será um esforço desperdiçado planejar uma abordagem de armazenamento de dados altamente escalonável ou criar uma abordagem totalmente automatizada para gerenciar seus recursos de dados. No entanto, à medida que a sua empresa cresce, você se beneficia cada vez mais por ter uma estratégia clara para escalar seus dados e recursos de armazenamento e aplicar automação ao gerenciamento deles. Quando você tem 50 locatários ou mais ou se planeja atingir esse nível de escala, é especialmente importante projetar sua abordagem de armazenamento e dados, com a escala como uma consideração fundamental.
Considere a extensão em que você planeja dimensionar e planeje claramente sua abordagem de arquitetura de armazenamento de dados para atender a esse nível de escala.
Previsibilidade de desempenho
Os serviços de armazenamento e dados multilocatário são particularmente suscetíveis ao problema de vizinho barulhento. É importante considerar se seus locatários podem afetar o desempenho uns dos outros. Por exemplo, seus locatários têm picos sobrepostos em nos padrões de uso deles ao longo do tempo? Todos os clientes usam sua solução ao mesmo tempo todos os dias ou as solicitações são distribuídas uniformemente? Esses fatores afetarão o nível de isolamento que você precisa projetar, a quantidade de recursos que você precisa provisionar e o grau em que os recursos podem ser compartilhados entre locatários.
É importante considerar as cotas de recurso e solicitação do Azure como parte dessa decisão. Por exemplo, suponha que você implante apenas uma conta de armazenamento para conter todos os dados de seus locatários. Se você exceder um número específico de operações de armazenamento por segundo, o Armazenamento do Microsoft Azure rejeitará as solicitações do aplicativo e todos os seus locatários serão afetados. Isso é chamado de comportamento de limitação. É importante que você monitore solicitações limitadas. Para saber mais, veja Diretrizes de repetição para serviços do Azure.
Isolamento dos dados
Ao criar uma solução que contém serviços de dados multilocatário, geralmente há diferentes opções e níveis de isolamento de dados, cada um com os próprios benefícios e compensações. Por exemplo:
- Ao usar o Azure Cosmos DB, você pode implantar contêineres separados para cada locatário e compartilhar bancos de dados e contas entre vários locatários. Como alternativa, você pode considerar a implantação de bancos de dados diferentes ou até mesmo contas para cada locatário, dependendo do nível de isolamento necessário.
- Ao usar o Armazenamento do Microsoft Azure para dados de blob, você pode implantar contêineres de blob separados para cada locatário ou implantar contas de armazenamento separadas.
- Ao usar o SQL do Azure, você pode usar tabelas separadas em bancos de dados compartilhados ou implantar bancos de dados ou servidores separados para cada locatário.
- Em todos os serviços do Azure, você pode considerar a implantação de recursos em apenas uma assinatura compartilhada do Azure ou usar várias assinaturas do Azure, talvez até mesmo uma por locatário.
Não há solução única que funcione para todas as situações. A opção escolhida depende de vários fatores e dos requisitos de seus locatários. Por exemplo, se seus locatários precisarem atender a padrões regulatórios ou de conformidade específicos, talvez seja necessário aplicar um nível mais alto de isolamento. Da mesma forma, você pode ter requisitos comerciais para isolar fisicamente os dados de seus clientes ou talvez seja necessário impor o isolamento para evitar o problema do vizinho barulhento. Além disso, se os locatários precisarem usar chaves de criptografia próprias, eles tiverem políticas individuais de backup e restauração ou precisarem ter os próprios dados armazenados em diferentes locais geográficos, talvez seja necessário isolá-los de outros locatários ou agrupá-los com locatários que tenham políticas semelhantes.
Complexidade da implementação
É importante considerar a complexidade da implementação. É uma boa prática manter sua arquitetura o mais simples possível, enquanto ainda atende aos seus requisitos. Evite se comprometer com uma arquitetura que se tornará cada vez mais complexa à medida que você dimensionar ou uma arquitetura que você não tem os recursos ou a experiência para desenvolver e manter.
Da mesma forma, se sua solução não precisar ser dimensionada para um grande número de locatários ou se você não tiver preocupações com o desempenho ou o isolamento de dados, é melhor manter sua solução simples e evitar adicionar complexidade desnecessária.
Uma preocupação específica para soluções de dados multilocatário é o nível de personalização ao qual você dá suporte. Por exemplo, um locatário pode estender seu modelo de dados ou aplicar regras de dados personalizadas? Certifique-se de projetar esse requisito antecipadamente. Evite bifurcar ou fornecer infraestrutura personalizada para locatários individuais. A infraestrutura personalizada inibe sua capacidade de escalar, testar sua solução e implantar atualizações. Em vez disso, considere usar sinalizadores de recursos e outras formas de configuração de locatário.
Complexidade de gerenciamento e operações
Considere como você planeja operar sua solução e como sua abordagem multilocatário afeta suas operações e processos. Por exemplo:
- Gerenciamento: considere operações de gerenciamento entre locatários, como atividades regulares de manutenção. Se você usar várias contas, servidores ou bancos de dados, como você iniciará e monitorará as operações de cada locatário?
- Monitoramento e medição: se você monitora ou mede seus locatários, considere como sua solução relata métricas e se elas podem ser facilmente vinculadas ao locatário que disparou a solicitação.
- Relatórios: a geração de relatórios de dados de locatários isolados podem exigir que cada locatário publique dados em um data warehouse centralizado, em vez de executar consultas em cada banco de dados individualmente e, em seguida, agregar os resultados.
- Atualizações de esquema: se você usa um banco de dados que impõe um esquema, planeje como implantará atualizações de esquema em sua propriedade. Considere como seu aplicativo sabe qual versão de esquema usar para consultas de banco de dados de um locatário específico.
- Requisitos: considere os requisitos de alta disponibilidade de seus locatários (por exemplo, SLAs ou contratos de nível de serviço de tempo de atividade) e requisitos de recuperação de desastre, por exemplo, RPOS (objetivos de tempo de recuperação) ou RPOs (objetivos de ponto de recuperação). Se os locatários tiverem expectativas diferentes, você poderá atender aos requisitos de cada locatário?
- Migração: como você migrará os locatários se eles precisarem mudar para um tipo diferente de serviço, uma implantação diferente ou outra região?
Custo
Geralmente, quanto maior a densidade de locatários para sua infraestrutura de implantação, menor o custo para provisionar essa infraestrutura. No entanto, a infraestrutura compartilhada aumenta a probabilidade de questões como o problema do vizinho barulhento, portanto, considere as desvantagens com cuidado.
Abordagens e padrões a serem considerados
Vários padrões de design do Centro de Arquitetura do Azure são relevantes para serviços de dados e armazenamento multilocatário. Você pode optar por seguir um padrão consistentemente. Ou você pode considerar a combinação e os padrões correspondentes. Por exemplo, você pode usar um banco de dados multilocatário para a maioria dos seus locatários, mas implantar selos de locatário único para locatários que pagam mais ou que têm requisitos incomuns. Da mesma forma, geralmente é uma boa prática dimensionar usando selos de implantação, mesmo quando você usa um banco de dados multilocatário ou bancos de dados fragmentados dentro de um selo.
Padrão de Carimbos de Implantação
Para obter mais informações sobre como o padrão Selos de Implantação pode ser usado para dar suporte a uma solução multilocatário, confira Visão geral.
Bancos de dados multilocatário compartilhados e repositórios de arquivos
Você pode considerar implantar um banco de dados multilocatário compartilhado, uma conta de armazenamento ou um compartilhamento de arquivos e compartilhá-lo em todos os seus locatários.
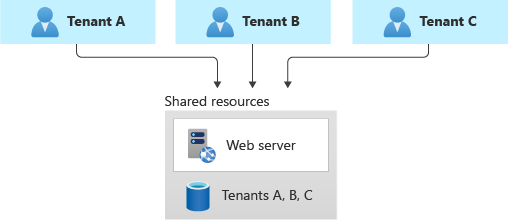
Essa abordagem fornece a maior densidade de locatários para a infraestrutura, portanto, tende a ter o menor custo de qualquer abordagem. Isso também costuma reduzir a sobrecarga de gerenciamento, pois há apenas um banco de dados ou recurso para gerenciar, fazer backup e proteger.
No entanto, quando você trabalha com a infraestrutura compartilhada, há várias restrições a serem consideradas:
- Limites de escala: ao contar com apenas um recurso, considere a escala e os limites com suporte desse recurso. Por exemplo, o tamanho máximo de um banco de dados ou repositório de arquivos, ou os limites máximos de taxa de transferência, acabará se tornando um bloqueador rígido, se sua arquitetura depender de um banco de dados individual. Considere cuidadosamente a escala máxima que você precisa alcançar e compare-a com seus limites atuais e futuros antes de selecionar esse padrão.
- Vizinhos barulhentos: o problema do vizinho barulhento pode se tornar um fator, especialmente se você tiver locatários particularmente ocupados ou gerar cargas de trabalho mais altas do que outros. Considere aplicar o Padrão de limitação ou o Padrão de limitação de taxa para atenuar esses efeitos.
- Monitoramento de cada locatário: você pode ter dificuldade em monitorar a atividade e medir o consumo de recursos para apenas um locatário. Alguns serviços, como o Azure Cosmos DB, fornecem relatórios sobre o uso de recursos para cada solicitação, para que essas informações possam ser controladas para medir o consumo de cada locatário. Outros serviços não fornecem o mesmo nível de detalhes. Por exemplo, as métricas Arquivos do Azure para capacidade de arquivo estão disponíveis por dimensão de compartilhamento de arquivo e somente quando você usa compartilhamentos Premium. No entanto, a camada Standard fornece as métricas apenas no nível da conta de armazenamento.
- Requisitos do locatário: os locatários podem ter requisitos diferentes para segurança, backup, disponibilidade ou local de armazenamento. Se eles não corresponderem à configuração do seu único recurso, talvez você não consiga acomodá-los.
- Personalização de esquema: ao trabalhar com um banco de dados relacional ou outra situação em que o esquema dos dados é importante, a personalização de esquema no nível do locatário é difícil.
Padrão de fragmentação
O padrão Sharding envolve a implantação de vários bancos de dados separados, chamados de fragmentos, cada um contendo ou mais dados de locatários. Ao contrário dos carimbos de implantação, os fragmentos não implicam que toda a infraestrutura seja duplicada. Você pode fragmentar bancos de dados sem também duplicar ou fragmentar outra infraestrutura em sua solução.
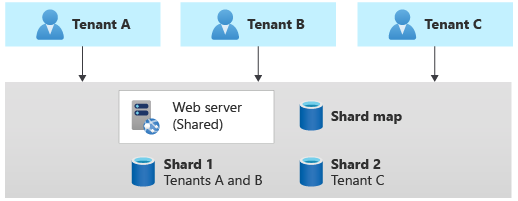
A fragmentação está intimamente relacionada ao particionamento, e os termos geralmente são usados de maneira intercambiável. Considere as Diretrizes para particionamento horizontal, vertical e funcional de dados.
O Padrão de fragmentação pode dimensionar para um número muito grande de locatários. Além disso, dependendo da carga de trabalho, você poderá obter uma alta densidade de locatários para fragmentos, de modo que o custo possa ser atraente. O padrão de fragmentação também pode ser usado para lidar com cotas, limites e restrições do serviço e assinatura do Azure.
Alguns armazenamentos de dados, como o Azure Cosmos DB, fornecem suporte nativo para fragmentação ou particionamento. Quando você trabalha com outras soluções, como o SQL do Azure, o processo de criar uma infraestrutura de fragmentação e rotear solicitações para o fragmento correto, para um determinado locatário, pode ser mais complexo.
A fragmentação também dificulta o suporte a diferenças de configuração no nível do locatário e permite que os clientes forneçam suas próprias chaves de criptografia.
Aplicativo multilocatário com bancos de dados dedicados para cada locatário
Outra abordagem comum é implantar apenas um aplicativo multilocatário, com bancos de dados dedicados para cada locatário.
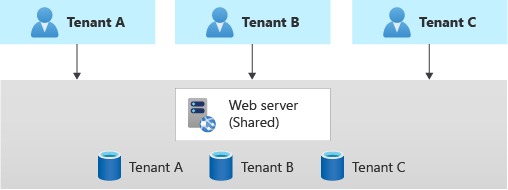
Nesse modelo, os dados de cada locatário são isolados dos outros e você pode dar suporte a algum grau de personalização para cada locatário.
Como você provisiona recursos de dados dedicados para cada locatário, o custo dessa abordagem pode ser maior do que o dos modelos de hospedagem compartilhados. No entanto, o Azure fornece várias opções que você pode considerar para compartilhar o custo de hospedagem de recursos de dados individuais em vários locatários. Por exemplo, quando você trabalha com o SQL do Azure, pode considerar o uso de pools elásticos. Para o Azure Cosmos DB, você pode provisionar a taxa de transferência de um banco de dados e a taxa de transferência é compartilhada entre os contêineres nesse banco de dados, embora essa abordagem não seja apropriada quando você precisa de desempenho garantido para cada contêiner.
Nessa abordagem, como somente os componentes de dados são implantados individualmente para cada locatário, você provavelmente pode obter alta densidade para os outros componentes em sua solução e reduzir o custo desses componentes.
É importante usar abordagens de implantação automatizadas ao provisionar bancos de dados para cada locatário.
Padrão de geode
O padrão Geode foi projetado especificamente para soluções distribuídas geograficamente, incluindo soluções multilocatário. Ele dá suporte a alta carga e altos níveis de resiliência. Se você implementar o padrão Geode, a camada de dados precisa ser capaz de replicar os dados entre regiões geográficas e deve dar suporte a gravações em várias regiões geográficas.
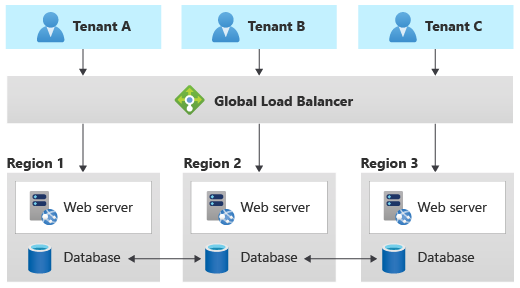
O Azure Cosmos DB fornece gravações em várias regiões para dar suporte a esse padrão e o Cassandra dá suporte a clusters em várias regiões. Em geral, outros serviços de dados não são capazes de dar suporte a esse padrão, sem personalização significativa.
Antipadrões a serem evitados
Quando você cria serviços de dados multilocatário, é importante evitar situações que inibam sua capacidade de dimensionamento.
Para bancos de dados relacionais, essas situações incluem:
- Isolamento baseado em tabela. Quando você trabalha em um banco de dados individual, evite criar tabelas individuais para cada locatário. Um banco de dados individual não será capaz de dar suporte a um número muito grande de locatários quando você usa essa abordagem, tornando cada vez mais difícil consultar, gerenciar e atualizar dados. Em vez disso, considere usar apenas um conjunto de tabelas multilocatário com uma coluna de identificador de locatário. Como alternativa, você pode usar um dos padrões descritos acima para implantar bancos de dados separados para cada locatário.
- Personalização de locatário no nível da coluna. Evite atualizações de esquema que se aplicam apenas a um locatário. Por exemplo, suponha que você tenha apenas um banco de dados multilocatário. Evite adicionar uma nova coluna para atender aos requisitos de um locatário específico. Pode ser aceitável para um pequeno número de personalizações, mas isso rapidamente se torna incontrolável quando você tem um grande número de personalizações a serem consideradas. Em vez disso, considere revisar seu modelo de dados para rastrear dados personalizados para cada locatário em uma tabela dedicada.
- Alterações de esquema manuais. Evite atualizar o esquema de banco de dados manualmente, mesmo que você tenha apenas um banco de dados compartilhado. É fácil perder o controle das atualizações aplicadas e, se você precisar escalar horizontalmente para mais bancos de dados, é desafiador identificar o esquema correto a ser aplicado. Em vez disso, crie um pipeline automatizado para implantar as alterações de esquema e use-o de maneira consistente. Acompanhe a versão do esquema usada para cada locatário em um banco de dados dedicado ou tabela de pesquisa.
- Dependências de versão. Evite que seu aplicativo tenha uma dependência de apenas uma versão do esquema de banco de dados. Conforme você dimensiona, talvez seja necessário aplicar atualizações de esquema em momentos diferentes para locatários diferentes. Em vez disso, verifique se a versão do aplicativo é compatível com pelo menos uma versão anterior do esquema e evite atualizações de esquema destrutivas.
Bancos de dados
Há alguns recursos que podem ser úteis para multilocação. No entanto, eles não estão disponíveis em todos os serviços de banco de dados. Considere se você precisa deles quando decidir sobre o serviço a ser usado para seu cenário:
A segurança em nível de linha pode fornecer isolamento de segurança para dados de locatários específicos em um banco de dados multilocatário compartilhado. Esse recurso está disponível em alguns bancos de dados, como SQL do Azure e Postgres Flex.
Ao usar a segurança em nível de linha, você precisa garantir que a identidade do usuário e a identidade do locatário sejam propagadas por meio do aplicativo e no armazenamento de dados com cada consulta. Essa abordagem pode ser complexa de projetar, implementar, testar e manter. Muitas soluções multilocatários não usam segurança em nível de linha devido a essas complexidades.
A criptografia no nível do locatário pode ser necessária para dar suporte a locatários que fornecem as próprias chaves de criptografia para os dados deles. Esse recurso está disponível no SQL do Azure como parte do Always Encrypted. O Azure Cosmos DB fornece chaves gerenciadas pelo cliente no nível da conta e também dá suporte a Always Encrypted.
O pool de recursos fornece a capacidade de compartilhar recursos e custos, entre vários bancos de dados ou contêineres. Esse recurso está disponível nos pools elásticos e instâncias gerenciadas do SQL do Azure e na taxa de transferência de banco de dados do Azure Cosmos DB, embora cada opção tenha limitações das quais você deve estar ciente.
A fragmentação e o particionamento têm suporte nativo mais forte em alguns serviços do que em outros. Esse recurso está disponível no Azure Cosmos DB, usando o particionamento lógico e físico. Embora o SQL do Azure não dê suporte nativo à fragmentação, ele fornece ferramentas de fragmentação para dar suporte a esse tipo de arquitetura.
Além disso, quando você trabalha com bancos de dados relacionais ou outros bancos de dados baseados em esquema, considere onde o processo de atualização de esquema deve ser disparado quando você mantém uma frota de bancos de dados. Em um pequeno acervo de bancos de dados, você pode considerar o uso de um pipeline de implantação para implantar alterações de esquema. Conforme o número de bancos de dados cresce, talvez seja melhor para sua camada de aplicativo detectar a versão do esquema de um banco de dados específico e iniciar o processo de atualização.
Armazenamento de arquivos e blobs
Considere a abordagem que você usa para isolar dados em uma conta de armazenamento. Por exemplo, você pode implantar contas de armazenamento separadas para cada locatário ou compartilhar contas de armazenamento e implantar contêineres individuais. Como alternativa, você pode criar contêineres de blob compartilhados e, em seguida, usar o caminho do blob para separar os dados para cada locatário. Considere os limites e cotas de assinatura do Azure e planeje cuidadosamente seu crescimento para garantir que seus recursos do Azure sejam dimensionados para dar suporte às suas necessidades futuras.
Se você usar contêineres compartilhados, planeje cuidadosamente sua estratégia de autenticação e autorização para garantir que os locatários não possam acessar os dados uns dos outros. Considere o padrão Chave Limitada ao fornecer aos clientes acesso aos recursos do Armazenamento do Microsoft Azure.
Alocação de custos
Considere como você medirá o consumo e alocará custos aos locatários para o uso de serviços de dados compartilhados. Sempre que possível, procure usar métricas internas em vez de calcular métricas próprias. No entanto, com a infraestrutura compartilhada, torna-se difícil dividir a telemetria para locatários individuais e talvez você precise considerar a medição personalizada no nível do aplicativo.
Em geral, os serviços nativos de nuvem, como o Azure Cosmos DB e o Armazenamento de Blobs do Azure, fornecem métricas mais granulares para acompanhar e modelar o uso de um locatário específico. Por exemplo, o Azure Cosmos DB fornece a taxa de transferência consumida para cada solicitação e resposta.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- John Downs | Engenheiro de software principal
Outros colaboradores:
- Paul Burpo | Engenheiro de cliente principal, FastTrack para Azure
- Daniel Scott-Raynsford | Estrategista de Tecnologia Do Parceiro
- Arsen Vladimirskiy | Engenheiro de Cliente Principal, FastTrack for Azure
Para ver perfis não públicos do LinkedIn, entre no LinkedIn.
Próximas etapas
Para obter mais informações sobre multilocatário e serviços específicos do Azure, confira: