Observação
Este artigo se baseia em uma biblioteca de código aberto hospedada no GitHub em: https://github.com/mspnp/spark-monitoring.
A biblioteca original dá suporte ao Azure Databricks Runtimes 10.x (Spark 3.2.x) e versões anteriores.
O Databricks contribuiu com uma versão atualizada para dar suporte ao Azure Databricks Runtimes 11.0 (Spark 3.3.x) e superior na l4jv2 ramificação em: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Observe que a versão 11.0 não é compatível com versões anteriores devido aos diferentes sistemas de log usados nos Databricks Runtimes. Certifique-se de usar a compilação correta para o Databricks Runtime. A biblioteca e o repositório do GitHub estão em modo de manutenção. Não há planos para lançamentos futuros, e o suporte a problemas será apenas de melhor esforço. Para quaisquer perguntas adicionais sobre a biblioteca ou o roteiro para monitoramento e registro em log de seus ambientes do Azure Databricks, entre em contato com azure-spark-monitoring-help@databricks.com.
Essa solução demonstra métricas e padrões de observabilidade para aprimorar o desempenho de processamento de um sistema de Big Data que usam o Azure Databricks.
Arquitetura

Baixe um Arquivo Visio dessa arquitetura.
Workflow
A solução envolve as seguintes etapas:
O servidor envia um arquivo GZIP grande que é agrupado pelo cliente na pasta Origem do Azure Data Lake Storage.
Em seguida, o Data Lake Storage envia um arquivo de cliente extraído com êxito para a Grade de Eventos do Azure, que transforma os dados do arquivo do cliente em várias mensagens.
A Grade de Eventos do Azure envia as mensagens ao serviço Armazenamento de Filas do Azure, que as armazena em uma fila.
O Armazenamento de Filas do Azure envia a fila para a plataforma de análise de dados do Azure Databricks para processamento.
O Azure Databricks desempacota e processa os dados da fila em um arquivo processado que ele envia novamente para o Data Lake Storage:
Se o arquivo processado for válido, ele irá para a pasta Destino.
Caso contrário, o arquivo irá para a árvore de pastas Inválido. Inicialmente, o arquivo vai para a subpasta Repetir, e o Data Lake Storage tenta processar o arquivo do cliente novamente (etapa 2). Se um par de novas tentativas ainda resultar no retorno do Azure Databricks de arquivos processados que não são válidos, o arquivo processado irá para a subpasta Falha.
Conforme o Azure Databricks desempacota e processa os dados da etapa anterior, ele também envia logs de aplicativos e métricas para o Azure Monitor para armazenamento.
Um workspace do Azure Log Analytics aplica consultas Kusto nos logs do aplicativo e nas métricas por meio do Azure Monitor para solução de problemas e diagnóstico detalhado.
Componentes
- O Azure Data Lake Storage é um conjunto de funcionalidades dedicado à análise de Big Data.
- A Grade de Eventos do Azure permite que um desenvolvedor crie aplicativos de maneira fácil com arquiteturas baseadas em eventos.
- Armazenamento de Filas do Azure é um serviço para armazenar grandes números de mensagens. Ele permite o acesso a mensagens em qualquer lugar do mundo por meio de chamadas autenticadas via HTTP ou HTTPS. Você pode usar filas para criar uma lista de pendências de trabalho para processamento assíncrono.
- O Azure Databricks é uma plataforma de análise de dados otimizada para a plataforma de nuvem do Azure. Um dos dois ambientes que o Azure Databricks oferece para o desenvolvimento de aplicativos com uso intensivo de dados é o workspace do Azure Databricks, um mecanismo de análise unificada baseado em Apache Spark para processamento de dados em grande escala.
- O Azure Monitor coleta e analisa a telemetria de aplicativo, como métricas de desempenho e logs de atividades.
- O Azure Log Analytics é uma ferramenta usada para editar e executar consultas de log com os dados.
Detalhes do cenário
Sua equipe de desenvolvimento pode usar métricas e padrões de observabilidade para encontrar gargalos e aprimorar o desempenho de um sistema de Big Data. Ela precisa fazer um teste de carga de um fluxo de alto volume de métricas em um aplicativo de grande escala.
Este cenário oferece diretrizes para ajuste de desempenho. Como o cenário apresenta um desafio de desempenho para o log por cliente, ele usa o Azure Databricks, que pode monitorar esses itens de maneira robusta:
- Métricas personalizadas do aplicativo
- Eventos de consulta de streaming
- Mensagens de log do aplicativo
O Azure Databricks pode enviar esses dados de monitoramento para diferentes serviços de log, como o Azure Log Analytics.
Este cenário descreve a ingestão de um conjunto de dados grande que foi agrupado pelo cliente e armazenado em um arquivo GZIP. Os logs detalhados não estão disponíveis no Azure Databricks fora da interface do usuário do Apache Spark™ em tempo real, ou seja, sua equipe precisa encontrar uma forma de armazenar todos os dados de cada cliente e avaliar desempenho deles e compará-los. Com um cenário de dados grandes, é importante encontrar um pool de executor de combinação e um tamanho de VM (máquina virtual) ideais para o tempo de processamento mais rápido. Para esse cenário de negócios, o aplicativo geral depende da velocidade dos requisitos de ingestão e consulta, de modo que a taxa de transferência do sistema não seja degradada inesperadamente com o aumento do volume de trabalho. O cenário precisa garantir que o sistema atenda aos SLAs (contratos de nível de serviço) estabelecidos com seus clientes.
Possíveis casos de uso
Entre os cenários que podem se beneficiar dessa solução estão:
- Monitoramento de integridade do sistema.
- Manutenção de desempenho.
- Monitoramento do uso diário do sistema.
- Identificação de tendências que poderão causar problemas futuros se não forem corrigidas.
Considerações
Estas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios de orientação que podem ser usados para aprimorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Tenha estes pontos em mente ao considerar essa arquitetura:
O Azure Databricks pode alocar automaticamente os recursos de computação necessários para um trabalho grande, o que evita os problemas apresentados pelas outras soluções. Por exemplo, com o dimensionamento automático otimizado para Databricks no Apache Spark, o provisionamento excessivo pode causar o uso abaixo do ideal dos recursos. Ou, então, talvez você não saiba o número de executores necessários para um trabalho.
Uma mensagem de fila no Armazenamento de Filas do Azure pode ter até 64 KB. Uma fila pode conter milhões de mensagens de fila, até o limite total de capacidade de uma conta de armazenamento.
Otimização de custos
A otimização de custos é a análise de maneiras de reduzir as despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Lista de verificação de revisão de design para otimização de custos.
Use a Calculadora de preços do Azure para estimar o custo da implantação dessa solução.
Implantar este cenário
Observação
As etapas de implantação descritas aqui se aplicam somente ao Azure Databricks, ao Azure Monitor e ao Azure Log Analytics. A implantação dos outros componentes não é abordada neste artigo.
Para obter todos os logs e as informações do processo, configure o Azure Log Analytics e a biblioteca de monitoramento do Azure Databricks. A biblioteca de monitoramento transmite os eventos no nível do Apache Spark e as métricas do Streaming Estruturado do Spark dos trabalhos para o Azure Monitor. Você não precisa fazer nenhuma alteração no código do aplicativo para esses eventos e para essas métricas.
As etapas usadas para configurar o ajuste de desempenho para um sistema de Big Data são as seguintes:
No portal do Azure, crie um workspace do Azure Databricks. Copie e salve a ID da assinatura do Azure (um GUID [identificador global exclusivo]), o nome do grupo de recursos, o nome do workspace do Databricks e a URL do portal do workspace para uso posterior.
Em um navegador da Web, acesse a URL do workspace do Databricks e gere um token de acesso pessoal do Databricks. Copie e salve a cadeia de caracteres de token exibida (que começa com
dapie um valor hexadecimal de 32 caracteres) para uso posterior.Clone o repositório mspnp/spark-monitoring do GitHub no computador local. Esse repositório tem o código-fonte dos seguintes componentes:
- O modelo do Azure Resource Manager (modelo do ARM) para criar um espaço de trabalho do Azure Log Analytics, que também instala consultas predefinidas para coleta de métricas do Spark
- Bibliotecas de monitoramento do Azure Databricks
- O aplicativo de exemplo para enviar métricas e logs do aplicativo do Azure Databricks para o Azure Monitor
Usando o comando da CLI do Azure para implantar um modelo do ARM, crie um workspace do Azure Log Analytics com as consultas predefinidas de métrica do Spark. Na saída do comando, copie e salve o nome gerado para o novo workspace do Log Analytics (no formato spark-monitoring-<randomized-string>).
No portal do Azure, copie e salve a ID e a chave do workspace do Log Analytics para uso posterior.
Instale a Community Edition do IntelliJ IDEA, um IDE (ambiente de desenvolvimento integrado) que tem suporte interno para o JDK (Java Development Kit) e o Apache Maven. Adicione o plug-in do Scala.
Usando o IntelliJ IDEA, crie as bibliotecas de monitoramento do Azure Databricks. Para executar a etapa de build real, selecione Exibir>Janelas de Ferramentas>Maven para mostrar a janela de ferramentas do Maven e selecione Executar Meta do Maven>pacote mvn.
Usando uma ferramenta de instalação de pacote Python, instale a CLI do Azure Databricks e configure a autenticação com o token de acesso pessoal do Databricks copiado anteriormente.
Configure o workspace do Azure Databricks modificando o script de inicialização do Databricks com os valores do Databricks e do Log Analytics copiados anteriormente e usando a CLI do Azure Databricks para copiar o script de inicialização e as bibliotecas de monitoramento do Azure Databricks para seu workspace do Databricks.
No portal do workspace do Databricks, crie e configure um cluster do Azure Databricks.
No IntelliJ IDEA, compile o aplicativo de exemplo usando o Maven. Em seguida, no portal do workspace do Databricks, execute o aplicativo de exemplo para gerar logs e métricas de exemplo para o Azure Monitor.
Enquanto o trabalho de exemplo está em execução no Azure Databricks, acesse o portal do Azure para ver e consultar os tipos de eventos (logs de aplicativos e métricas) na interface do Log Analytics:
- Selecione Tabelas>Logs Personalizados para ver o esquema de tabela dos eventos de ouvinte do Spark (SparkListenerEvent_CL), dos eventos de log do Spark (SparkLoggingEvent_CL) e das métricas do Spark (SparkMetric_CL).
- Escolha Explorador de consultas>Consultas Salvas>Métricas do Spark para ver e executar as consultas que foram adicionadas quando você criou o workspace do Log Analytics.
Leia mais sobre como ver e executar consultas predefinidas e personalizadas na próxima seção.
Consultar os logs e as métricas no Azure Log Analytics
Acessar consultas predefinidas
Os nomes das consultas predefinidas para recuperar as métricas do Spark estão listados abaixo.
- Percentual de Tempo de CPU por Executor
- Percentual de Tempo de Desserialização por Executor
- Percentual de Tempo de JVM por Executor
- Percentual de Tempo de Serialização por Executor
- Bytes de Disco Despejados
- Rastreamentos de Erro (Registro Inválido ou Arquivos Inválidos)
- Bytes do Sistema de Arquivos Lidos por Executor
- Gravação de Bytes do Sistema de Arquivos por Executor
- Erros de Trabalho por Trabalho
- Latência de Trabalho por Trabalho (Duração do Lote)
- Taxa de Transferência do Trabalho
- Executores em Execução
- Bytes em Ordem Aleatória Lidos
- Bytes em Ordem Aleatória Lidos por Executor
- Bytes em Ordem Aleatória Lidos em Disco por Executor
- Memória Direta do Cliente em Ordem Aleatória
- Memória do Cliente em Ordem Aleatória por Executor
- Bytes de Disco em Ordem Aleatória Despejados por Executor
- Memória de Heap em Ordem Aleatória por Executor
- Bytes de Memória em Ordem Aleatória Despejados por Executor
- Latência de Fase por Fase (Duração da Fase)
- Taxa de Transferência da Fase por Fase
- Erros de Streaming por Fluxo
- Latência de Streaming por Fluxo
- Linhas de Entrada da Taxa de Transferência de Streaming/s
- Linhas Processadas da Taxa de Transferência de Streaming/s
- Soma de Execução da Tarefa por Host
- Tempo de Desserialização da Tarefa
- Erros de Tarefa por Fase
- Tempo de Computação do Executor de Tarefa (Tempo de Distorção de Dados)
- Bytes de Entrada da Tarefa Lidos
- Latência da Tarefa por Fase (Duração das Tarefas)
- Tempo de Serialização do Resultado da Tarefa
- Latência de Atraso do Agendador de Tarefas
- Bytes em Ordem Aleatória da Tarefa Lidos
- Bytes em Ordem Aleatória da Tarefa Gravados
- Tempo de Leitura em Ordem Aleatória da Tarefa
- Tempo de Gravação em Ordem Aleatória da Tarefa
- Taxa de Transferência da Tarefa (Soma das Tarefas por Fase)
- Tarefas por Executor (Soma das Tarefas por Executor)
- Tarefas por Fase
Escrever consultas personalizadas
Você também pode escrever suas consultas em KQL (Linguagem de Consulta Kusto). Basta selecionar o painel central superior, que é editável, e personalizar a consulta de acordo com suas necessidades.
As duas seguintes consultas extraem os dados dos eventos de log do Spark:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
Estes dois exemplos são consultas no log de métricas do Spark:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
Terminologia de consulta
A tabela a seguir explica alguns dos termos usados quando você constrói uma consulta de métricas e logs do aplicativo.
| Termo | ID | Comentários |
|---|---|---|
| Cluster_init | ID do Aplicativo | |
| Fila | ID da execução | Uma ID de execução é igual a vários lotes. |
| Batch | ID do Lote | Um lote é igual a dois trabalhos. |
| Trabalho | ID do Trabalho | Um trabalho é igual a duas fases. |
| Estágio | ID da fase | Uma fase tem 100 a 200 IDs de tarefa, dependendo da tarefa (leitura, em ordem aleatória ou gravação). |
| Tarefas | ID da Tarefa | Uma tarefa é atribuída a um executor. Uma tarefa é atribuída para fazer um partitionBy para uma partição. Para cerca de 200 clientes, deve haver 200 tarefas. |
As seções a seguir contêm as métricas típicas usadas neste cenário para monitorar a taxa de transferência do sistema, o status de execução do trabalho do Spark e o uso de recursos do sistema.
Taxa de transferência do sistema
| Nome | Medição | Unidades |
|---|---|---|
| Taxa de transferência de fluxo | Taxa de entrada média em relação à taxa média de processamento por minuto | Linhas por minuto |
| Duração do trabalho | Duração média de trabalho do Spark concluído por minuto | Durações por minuto |
| Contagem de trabalhos | Número médio de trabalhos do Spark encerrados por minuto | Número de trabalhos por minuto |
| Duração da fase | Duração média de fases concluídas por minuto | Durações por minuto |
| Contagem de fases | Número médio de fases concluídas por minuto | Número de fases por minuto |
| Duração da tarefa | Duração média de tarefas concluídas por minuto | Durações por minuto |
| Contagem de tarefas | Número médio de tarefas concluídas por minuto | Número de tarefas por minuto |
Status de execução do trabalho do Spark
| Nome | Medição | Unidades |
|---|---|---|
| Contagem de pools do agendador | Número de contagem distinta de pools do agendador por minuto (número de filas operacionais) | Número de pools do agendador |
| Número de executores em execução | Número de executores em execução por minuto | Número de executores em execução |
| Rastreamento de erro | Todos os logs de erros com o nível Error e as tarefas/ID de fase correspondentes (mostradas em thread_name_s) |
Uso de recursos do sistema
| Nome | Medição | Unidades |
|---|---|---|
| Uso médio da CPU por executor/geral | Percentual de CPU usado por executor por minuto | Percentual por minuto |
| Média de memória direta usada (MB) por host | Média de memória direta usada por executores por minuto | MB por minuto |
| Memória despejada por host | Média de memória despejada por executor | MB por minuto |
| Monitorar o impacto da distorção de dados na duração | Medir o intervalo e a diferença entre o 70º-90º percentil e o 90º-100º percentil na duração das tarefas | Diferença líquida entre 100%, 90% e 70%; diferença percentual entre 100%, 90% e 70% |
Decida como relacionar a entrada do cliente, que foi combinada em um arquivo GZIP, a determinado arquivo de saída do Azure Databricks, pois o Azure Databricks cuida de toda a operação em lote como uma unidade. Aqui, você aplicará a granularidade ao rastreamento. Você também usará métricas personalizadas para rastrear um arquivo de saída até o arquivo de entrada original.
Para obter definições mais detalhadas de cada métrica, confira Visualizações nos painéis neste site ou confira a seção Métricas na documentação do Apache Spark.
Avaliar as opções de ajuste de desempenho
Definição de linha de base
Você e sua equipe de desenvolvimento devem estabelecer uma linha de base, de modo que você possa comparar os próximos estados do aplicativo.
Meça o desempenho do seu aplicativo de maneira quantitativa. Nesse cenário, a métrica chave é a latência do trabalho, que é típica da maior parte do pré-processamento e da ingestão de dados. Tente acelerar o tempo de processamento de dados e concentre-se na medição da latência, conforme mostrado no gráfico abaixo:
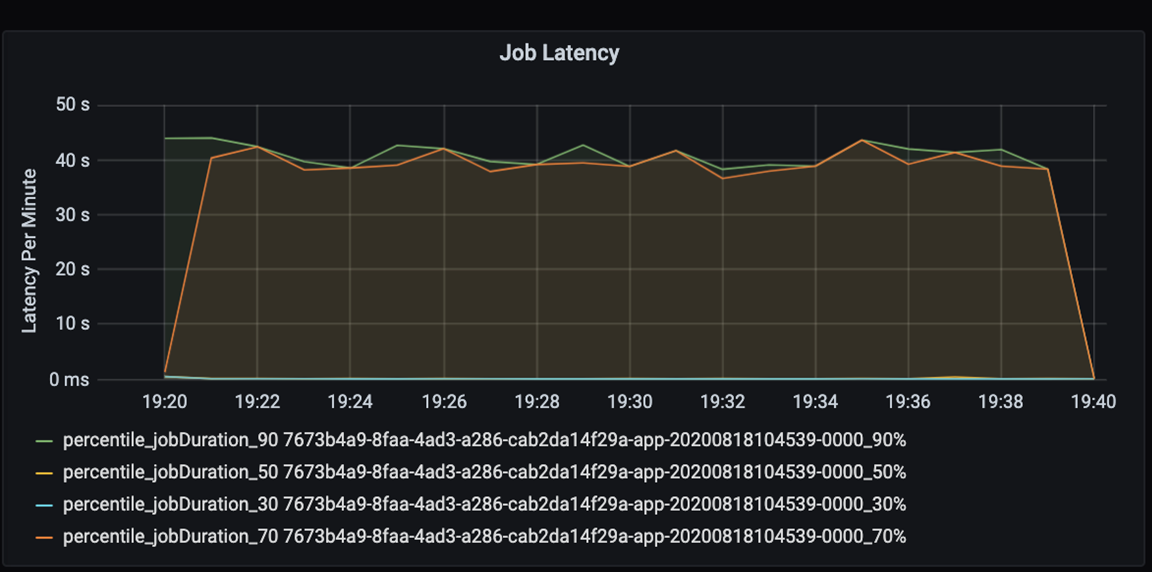
Meça a latência de execução de um trabalho: uma exibição de alta granularidade do desempenho geral do trabalho e a duração da execução do trabalho desde o início até a conclusão (tempo de microlote). No gráfico acima, na marca 19:30, são necessários cerca de 40 segundos de duração para processar o trabalho.
Se você analisar em mais detalhes esses 40 segundos, verá os dados abaixo para as fases:
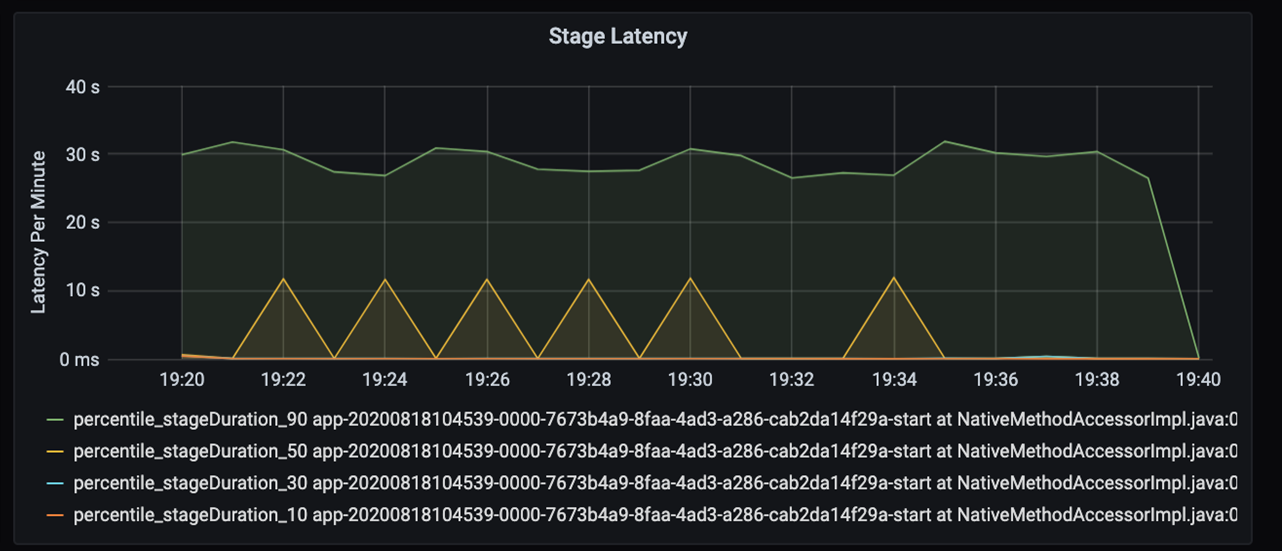
Na marca 19:30, há duas fases: uma fase laranja de 10 segundos e uma fase verde nos 30 segundos. Monitore se uma fase é um pico, porque um pico indica um atraso em uma fase.
Investigue quando uma fase específica está sendo executada lentamente. No cenário de particionamento, normalmente há, pelo menos, duas fases: uma fase para ler um arquivo e a outra para executar em ordem aleatória, particionar e gravar o arquivo. Se você tiver uma latência alta de fase na maior parte da fase de gravação, poderá ter um problema de gargalo durante o particionamento.
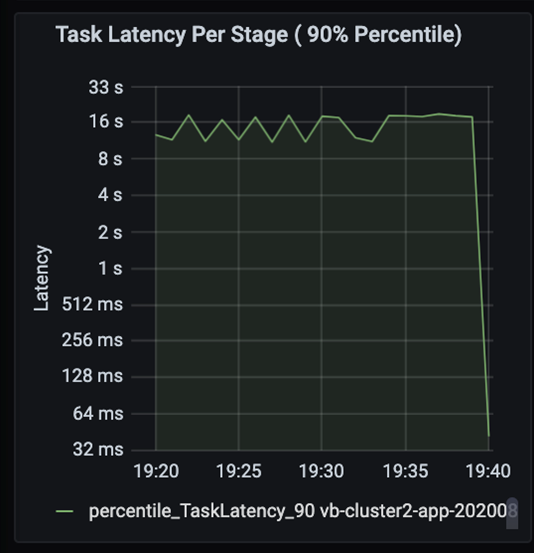
Observe as tarefas à medida que as fases de um trabalho são executadas em sequência, com as fases anteriores bloqueando as fases posteriores. Em uma fase, se uma tarefa executar uma partição em ordem aleatória mais lentamente do que outras tarefas, todas as tarefas do cluster precisarão aguardar a conclusão da tarefa mais lenta para que a fase seja concluída. As tarefas são uma forma de monitorar a distorção de dados e os possíveis gargalos. No gráfico acima, você pode ver que todas as tarefas são distribuídas de maneira uniforme.
Agora, monitore o tempo de processamento. Como você tem um cenário de streaming, examine a taxa de transferência de streaming.
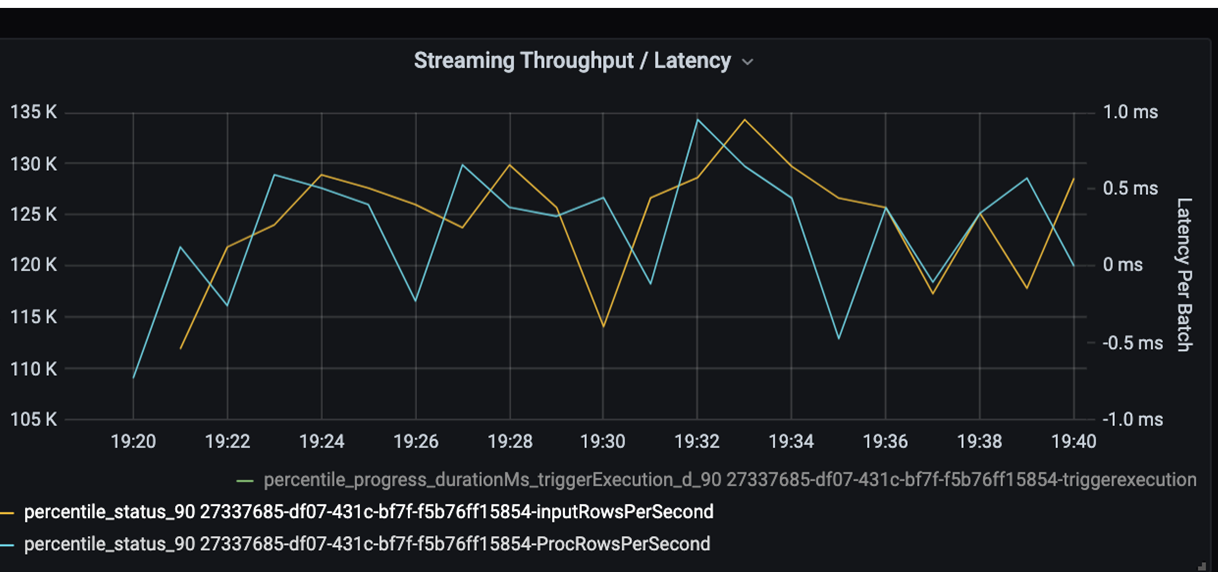
No gráfico de latência em lote/taxa de transferência de streaming acima, a linha laranja representa a taxa de entrada (linhas de entrada por segundo). A linha azul representa a taxa de processamento (linhas processadas por segundo). Em alguns pontos, a taxa de processamento não captura a taxa de entrada. O possível problema é que os arquivos de entrada estão acumulando na fila.
Como a taxa de processamento não corresponde à taxa de entrada no grafo, procure aprimorar a taxa de processo para cobrir totalmente a taxa de entrada. Um possível motivo é o desequilíbrio dos dados do cliente em cada chave de partição que resulta em um gargalo. Para uma próxima etapa e solução potencial, aproveite a escalabilidade do Azure Databricks.
Investigação de particionamento
Primeiro, identifique o número correto de executores de escala de que você precisa com o Azure Databricks. Aplique a regra de atribuição de cada partição com uma CPU dedicada nos executores em execução. Por exemplo, se você tiver 200 chaves de partição, o número de CPUs multiplicado pelo número de executores deverá ser igual a 200. (Por exemplo, oito CPUs combinadas com 25 executores seriam uma boa combinação.) Com 200 chaves de partição, cada executor pode trabalhar apenas em uma tarefa, o que reduz a chance de um gargalo.
Como algumas partições lentas estão nesse cenário, investigue a alta variação na duração das tarefas. Verifique se há picos na duração da tarefa. Uma tarefa processa uma partição. Se uma tarefa exigir mais tempo, a partição poderá ser muito grande e causar um gargalo.
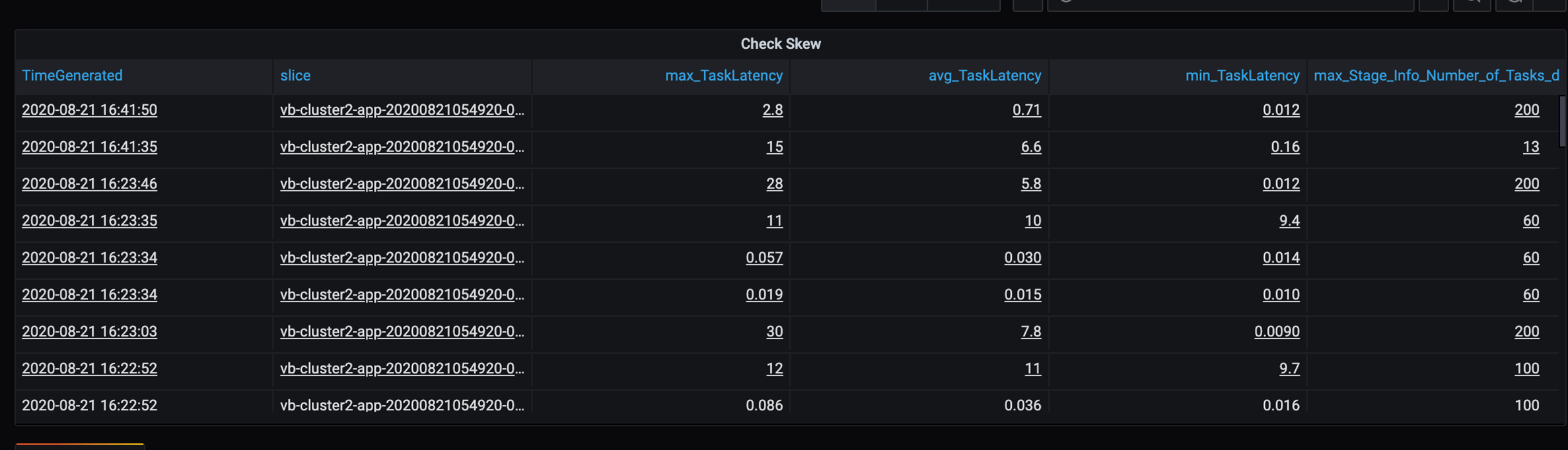
Rastreamento de erro
Adicione um painel para o rastreamento de erros de modo que você possa identificar as falhas de dados específicas do cliente. No pré-processamento de dados, há ocasiões em que os arquivos estão corrompidos e os registros de um arquivo não correspondem ao esquema de dados. O painel a seguir captura vários arquivos e registros inválidos.
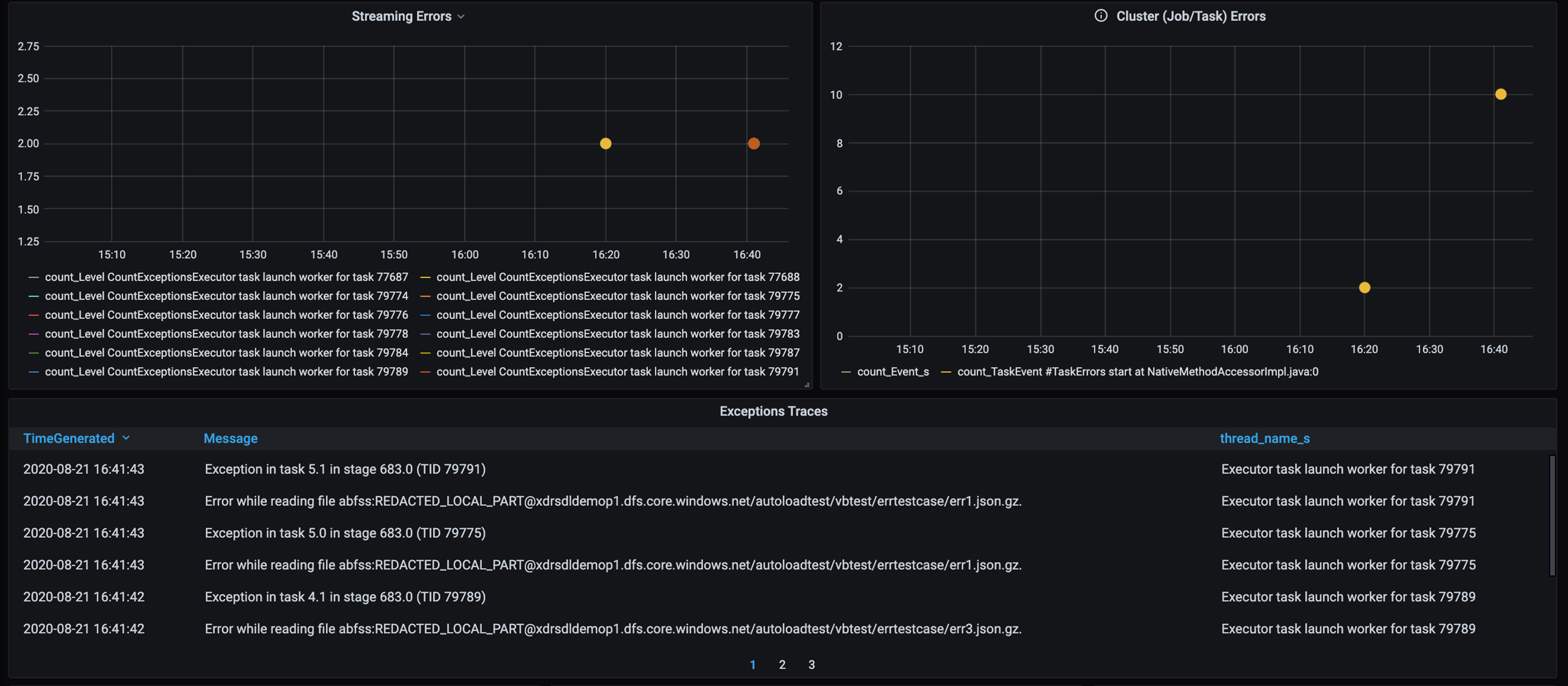
Esse painel exibe a contagem de erros, a mensagem de erro e a ID da tarefa para depuração. Na mensagem, você pode rastrear com facilidade o erro novamente para o arquivo de erro. Há vários arquivos com erro durante a leitura. Revise a primeira linha do tempo e investigue os pontos específicos no grafo (16:20 e 16:40).
Outros gargalos
Para ver mais exemplos e diretrizes, confira Solução de problemas de gargalos de desempenho no Azure Databricks.
Resumo da avaliação de ajuste de desempenho
Para esse cenário, essas métricas identificaram as seguintes observações:
- No gráfico de latência da fase, as fases de gravação usam a maior parte do tempo de processamento.
- No gráfico de latência da tarefa, a latência da tarefa é estável.
- No gráfico de taxa de transferência de streaming, a taxa de saída é menor do que a taxa de entrada em alguns pontos.
- Na tabela de duração da tarefa, há uma variação de tarefa devido ao desequilíbrio dos dados do cliente.
- Para obter um desempenho otimizado na fase de particionamento, o número de executores de escala deve corresponder ao número de partições.
- Há erros de rastreamento, como arquivos e registros inválidos.
Para diagnosticar esses problemas, você usou as seguintes métricas:
- Latência do trabalho
- Latência de preparo
- Latência da tarefa
- Taxa de transferência de streaming
- Duração da tarefa (máx., média, mín.) por fase
- Rastreamento de erro (contagem, mensagem, ID da tarefa)
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- David McGhee | Diretor Gerente de Programas
Para ver perfis não públicos do LinkedIn, entre no LinkedIn.
Próximas etapas
- Leia o tutorial do Log Analytics.
- Como monitorar o Azure Databricks em um workspace do Azure Log Analytics
- Implantação do Azure Log Analytics com as métricas do Spark
- Padrões de observabilidade