Os serviços e os aplicativos distribuídos em execução na nuvem são, por natureza, partes complexas de software que incluem diversas partes em movimento. Em um ambiente de produção, é importante ser capaz de controlar a maneira como os usuários usam seu sistema, acompanhar a utilização de recursos e, de maneira geral, monitorar a integridade e o desempenho do sistema. Você pode usar essas informações como um auxílio de diagnóstico para detectar e corrigir problemas e para ajudar a identificar possíveis problemas e impedir que eles ocorram.
Cenários de monitoramento e diagnóstico
Você pode usar o monitoramento para obter uma visão geral do funcionamento de um sistema. O monitoramento é uma parte essencial da manutenção das metas de qualidade de serviço. Alguns cenários comuns para coleta de dados de monitoramento incluem:
- Garantir que o sistema permaneça íntegro.
- Monitorar a disponibilidade do sistema e dos elementos que o compõem.
- Manter o desempenho para garantir que a taxa de transferência do sistema não seja reduzida inesperadamente conforme o volume de trabalho aumentar.
- Garantir que o sistema atenda a contratos de nível de serviço (SLAs) estabelecidos com os clientes.
- Proteger a privacidade e a segurança do sistema, dos usuários e de seus dados.
- Controlar as operações executadas para fins normativos ou de auditoria.
- Monitorar o uso diário do sistema e ajudar a identificar tendências que poderão resultar em problemas se não forem tratadas.
- Rastrear problemas que ocorrem, desde o relatório inicial por meio da análise de possíveis causas à retificação, atualizações de software resultantes e implantações.
- Controlar as operações e depurar versões de software.
Observação
Esta lista não se destina a ser completamente abrangente. Este documento se concentra nesses cenários, já que são as situações mais comuns que exigem monitoramento. Pode haver outras menos comuns ou específicas para seu ambiente.
As seções a seguir descrevem esses cenários mais detalhadamente. As informações sobre cada cenário são abordadas no seguinte formato:
- Uma breve visão geral do cenário.
- Os requisitos típicos deste cenário.
- Os dados brutos de instrumentação necessários para dar suporte ao cenário e possíveis fontes dessas informações.
- Como esses dados brutos podem ser analisados e combinados para gerar informações de diagnóstico significativas.
Monitoramento da integridade
Um sistema é íntegro se ele estiver em execução e for capaz de processar solicitações. A finalidade do monitoramento da integridade é gerar um instantâneo da integridade atual do sistema para que você possa verificar se todos os componentes do sistema estão funcionando conforme o esperado.
Requisitos para monitoramento da integridade
Se qualquer parte do sistema for considerada como problemática, um operador deverá ser alertado rapidamente (em questão de segundos). O operador deve ser capaz de determinar quais partes do sistema estão funcionando normalmente e quais partes estão enfrentando problemas. A integridade do sistema pode ser realçada por meio de um sistema de semáforo:
- Vermelho para não íntegro (o sistema parou)
- Amarelo para parcialmente íntegro (o sistema está sendo executado com funcionalidade reduzida)
- Verde para completamente íntegro
Um sistema de monitoramento de integridade abrangente permite que o operador faça uma busca detalhada no sistema para exibir o status de integridade dos componentes e subsistemas. Por exemplo, se o sistema geral for representado como parcialmente íntegro, o operador deve ser capaz de ter uma visão mais detalhada para determinar qual funcionalidade está indisponível no momento.
Requisitos para coleta de dados, fontes de dados e instrumentação
Os dados brutos necessários para dar suporte ao monitoramento da integridade podem ser gerados como resultado de:
- Rastreamento da execução de solicitações do usuário. Essas informações podem ser usadas para determinar quais solicitações tiveram êxito, quais falharam e quanto tempo cada solicitação leva.
- Monitoramento de usuário sintético. Este processo simula as etapas executadas pelo usuário e segue uma série predefinida de etapas. Os resultados de cada etapa devem ser capturados.
- Logs de exceções, falhas e avisos. Essas informações podem ser capturadas como resultado de instruções de rastreamento inseridas no código do aplicativo e da recuperação de informações dos logs de eventos de qualquer serviço referenciado pelo sistema.
- Monitoramento da integridade de serviços de terceiros usados pelo sistema. Esse monitoramento pode exigir a recuperação e a análise de dados de saúde que fornecem esses serviços. Essas informações podem ter vários formatos.
- Monitoramento do ponto de extremidade. Esse mecanismo é descrito em mais detalhes na seção “Monitoramento da disponibilidade”.
- Coletando informações de desempenho do ambiente, como utilização da CPU em segundo plano ou atividades de E/S (inclusive de rede).
Analisando dados de integridade
O foco principal do monitoramento de integridade é indicar rapidamente se o sistema está em execução. A análise hot dos dados imediatos pode disparar um alerta se um componente crítico é detectado como não íntegro. Não responde a uma série consecutiva de pings, por exemplo. Em seguida, o operador pode tomar a ação corretiva apropriada.
Um sistema mais avançado pode incluir um elemento de previsão que realiza uma análise cold em cargas de trabalho recentes e atuais. Uma análise cold pode identificar tendências e determinar se o sistema provavelmente permanecerá íntegro ou se o sistema precisará de recursos adicionais. Esse elemento preditivo deve ser baseado em métricas de desempenho críticas, como:
- A taxa de solicitações dirigidas a cada serviço ou subsistema.
- Os tempos de resposta dessas solicitações.
- O volume de dados que entram e saem de cada serviço.
Se o valor de qualquer métrica ultrapassar um limite definido, o sistema poderá gerar um alerta para habilitar um operador ou o dimensionamento automático (se disponível) a fim de executar as ações preventivas necessárias para manter a integridade do sistema. Essas ações podem envolver acrescentar recursos, reiniciar um ou mais serviços que estão falhando ou aplicar limitações a solicitações de prioridade mais baixa.
Monitoramento da disponibilidade
Um sistema realmente íntegro requer que os componentes e os subsistemas que compõem o sistema estejam disponíveis. O monitoramento de disponibilidade está intimamente relacionado ao monitoramento de integridade. Mas enquanto o monitoramento da integridade fornece uma exibição imediata da integridade atual do sistema, o monitoramento da disponibilidade se ocupa de monitorar a disponibilidade do sistema e de seus componentes para gerar estatísticas sobre o tempo de atividade do sistema.
Em muitos sistemas, alguns componentes (como um banco de dados) são configurados com redundância interna para permitir um failover rápido caso ocorram falhas graves ou perda de conectividade. Idealmente, os usuários não devem estar cientes de que ocorreu uma falha. Mas, de uma perspectiva do monitoramento da disponibilidade, é necessário obter o máximo possível de informações sobre essas falhas para determinar a causa e executar ações corretivas para impedir sua recorrência.
Os dados necessários para controlar a disponibilidade podem depender de vários fatores de nível inferior. Muitos desses fatores podem ser específicos do aplicativo, do sistema e do ambiente. Um sistema de monitoramento eficaz captura os dados de disponibilidade que correspondem a esses fatores de nível inferior e os agrega para fornecer uma visão geral do sistema. Por exemplo, em um sistema de comércio eletrônico, a funcionalidade de negócios que permite que um cliente faça pedidos pode depender do repositório no qual detalhes do pedido são armazenados e do sistema de pagamento que processa as transações monetárias para pagar por esses pedidos. A disponibilidade da parte de inserção de pedidos do sistema é, portanto, uma função da disponibilidade do repositório e do subsistema de pagamento.
Requisitos para monitoramento da disponibilidade
Um operador também deve ser capaz de exibir o histórico de disponibilidade de cada sistema e subsistema e usar essas informações para identificar tendências que podem fazer com que um ou mais subsistemas falhe periodicamente. (Os serviços começam a falhar em determinado horário do dia que corresponde ao pico de processamento?)
Uma solução de monitoramento deve fornecer uma visão imediata e histórica da disponibilidade ou indisponibilidade de cada subsistema. Ele também deve ser capaz de alertar rapidamente um operador quando um ou mais serviços falham ou quando os usuários não podem se conectar aos serviços. Não se trata apenas de monitorar cada serviço, mas também de examinar as ações se elas falham ao tentar se comunicar com um serviço. Até certo ponto, um grau de falha de conectividade é normal e pode ser devido a erros temporários. Mas pode ser útil permitir que o sistema emita um alerta pelo número de falhas de conectividade para determinado subsistema que ocorrem durante um período específico.
Requisitos para coleta de dados, fontes de dados e instrumentação
Assim como com o monitoramento de integridade, os dados brutos necessários para dar suporte ao monitoramento da disponibilidade podem ser gerados como resultado do monitoramento do usuário sintético e do registro em log de exceções, falhas e avisos que possam ocorrer. Além disso, dados de disponibilidade podem ser obtidos realizando o monitoramento do ponto de extremidade. O aplicativo pode expor um ou mais pontos de extremidade de integridade, cada um deles testando o acesso a uma área funcional do sistema. O sistema de monitoramento pode executar um ping de cada ponto de extremidade seguindo um cronograma definido e coletar os resultados (sucesso ou falha).
Todas as falhas de conectividade de rede, tempos limite e novas tentativas de conexão devem ser registrados. Todos os dados devem ter selo de data/hora.
Analisando dados de disponibilidade
Os dados de instrumentação devem ser agregados e correlacionados para dar suporte aos seguintes tipos de análise:
- A disponibilidade imediata do sistema e dos subsistemas.
- As taxas de falha de disponibilidade do sistema e dos subsistemas. O ideal é que um operador seja capaz de correlacionar falhas a atividades específicas: o que estava acontecendo quando o sistema falhou?
- Uma exibição do histórico de taxas de falha do sistema ou de subsistemas em um período especificado, assim como a carga do sistema (número de solicitações de usuários, por exemplo) quando uma falha ocorreu.
- Os motivos para a indisponibilidade do sistema ou de quaisquer subsistemas. Por exemplo, os motivos podem ser a não execução do serviço, a perda de conectividade, a existência de conexão, mas atingindo o tempo limite e a existência de conexão, mas retornando erros.
Você pode calcular o percentual de disponibilidade de um serviço em um período de tempo usando a seguinte fórmula:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Isso é útil para fins de SLA. O monitoramento de SLA é descrito em mais detalhes posteriormente nestas diretrizes. A definição de tempo de inatividade depende do serviço. Por exemplo, o Serviço de Compilação do Visual Studio Team Services define o tempo de inatividade como o período (total de minutos acumulados) durante o qual o Serviço de Compilação está indisponível. Um minuto será considerado indisponível se todas as solicitações HTTP contínuas para o Serviço de Compilação realizar operações iniciadas pelo cliente durante o minuto resultarem em um código de erro ou não retornarem nenhuma resposta.
Monitoramento de desempenho
Conforme o sistema vai sendo colocado cada vez mais sob pressão pelo aumento do volume de usuários, o tamanho dos conjuntos de dados que esses usuários acessam vai crescendo, aumentando a probabilidade de uma possível falha de um ou mais componentes. Frequentemente, a falha de um componente é precedida por uma queda no desempenho. Se você conseguir detectar uma redução desse tipo, poderá tomar medidas proativas para corrigir a situação.
O desempenho do sistema depende de vários fatores. Cada fator normalmente é medido por meio de KPIs (indicadores chave de desempenho), como o número de transações de banco de dados por segundo ou o volume de solicitações de rede que são atendidas com êxito em um determinado período de tempo. Alguns desses KPIs podem estar disponíveis como medidas de desempenho específicas, enquanto outros podem ser derivados de uma combinação de métricas.
Observação
Para determinar se o desempenho é bom ou insatisfatório, você precisa compreender o nível de desempenho em que o sistema deveria ser capaz de ser executado. Para isso, é necessário observar o sistema enquanto ele está funcionando com uma carga típica e capturar os dados de cada KPI ao longo de um período de tempo. Isso pode envolver executar o sistema com uma carga simulada em um ambiente de teste e coletar os dados apropriados antes de implantar o sistema em um ambiente de produção.
Você também deve fazer com que o monitoramento para fins de desempenho não sobrecarregue o sistema. Talvez você possa ajustar dinamicamente o nível de detalhes dos dados que o processo de monitoramento de desempenho coleta.
Requisitos para monitoramento do desempenho
Para examinar o desempenho do sistema, um operador normalmente precisa consultar informações que incluam:
- As taxas de resposta para as solicitações de usuários.
- O número de solicitações de usuários simultâneas.
- O volume de tráfego de rede.
- As taxas com as quais as transações de negócios estão sendo concluídas.
- O tempo médio de processamento das solicitações.
Também pode ser útil fornecer ferramentas que permitem ao operador auxiliar na detecção de correlações, como:
- O número de usuários simultâneos versus os tempos de latência de solicitação (quanto tempo leva para iniciar o processamento de uma solicitação depois que o usuário a envia).
- O número de usuários simultâneos versus o tempo médio de resposta (quanto tempo leva para concluir uma solicitação após ela começar a ser processada).
- O volume de solicitações versus o número de erros de processamento.
Junto com essas informações funcionais mais amplas, o operador deve ser capaz de ter uma visão detalhada do desempenho de cada componente do sistema. Esses dados normalmente são fornecidos por meio de contadores de desempenho de nível mais detalhado que rastreiam informações como:
- Utilização da memória.
- Número de threads.
- Tempo de processamento da CPU.
- Tamanho da fila de solicitações.
- Taxas e erros de E/S de rede ou de disco.
- Número de bytes gravados ou lidos.
- Indicadores de middleware, como tamanho da fila.
Todas as visualizações devem permitir que um operador especifique um período de tempo. Os dados exibidos podem ser um instantâneo da situação atual e/ou uma exibição do histórico de desempenho.
O operador deve ser capaz de gerar um alerta baseado em qualquer medida de desempenho para qualquer valor determinado durante qualquer intervalo de tempo especificado.
Requisitos para coleta de dados, fontes de dados e instrumentação
Você pode obter dados de desempenho de alto nível (taxa de transferência, número de usuários simultâneos, número de transações de negócios, taxas de erro e assim por diante) monitorando o progresso das solicitações de usuários conforme elas chegam e passam pelo sistema. Isso envolve a incorporação de instruções de rastreamento nos pontos-chave do código do aplicativo, em conjunto com informações de tempo. Todas as falhas, exceções e avisos devem ser capturados com dados suficientes para correlacioná-los às solicitações que os causaram. O log do IIS (Serviços de Informações da Internet) é outra fonte útil.
Se possível, você também deve capturar dados de desempenho de quaisquer sistemas externos que o aplicativo utilizar. Esses sistemas externos podem fornecer seus próprios contadores de desempenho ou outros recursos para solicitação de dados de desempenho. Se isso não for possível, registre informações como a hora de início e de término de cada solicitação feita para um sistema externo, junto com o status (êxito, falha ou aviso) da operação. Por exemplo, você pode usar uma abordagem de cronômetro para solicitações de tempo: inicie um cronômetro quando a solicitação for iniciada e pare o cronômetro quando ela for concluída.
Os dados de desempenho mais detalhados para componentes individuais de um sistema podem estar disponíveis por meio de recursos e serviços como contadores de desempenho do Windows e o Diagnóstico do Azure.
Analisando dados de desempenho
Grande parte do trabalho de análise consiste em agregar dados de desempenho por tipo de solicitação de usuário e/ou subsistema ou serviço ao qual cada solicitação é enviada. Um exemplo de uma solicitação de usuário é adicionar um item a um carrinho de compras ou executar o processo de check-out em um sistema de comércio eletrônico.
Outro requisito comum é resumir os dados de desempenho em percentis selecionados. Por exemplo, um operador pode determinar os tempos de resposta para 99% das solicitações, 95% das solicitações e 70% das solicitações. Pode haver metas de SLA ou outras metas definidas para cada percentil. Os resultados em andamento devem ser relatados quase em tempo real para ajudar a detectar problemas imediatos. Os resultados também devem ser agregados durante o tempo mais longo para fins estatísticos.
No caso de problemas de latência com impacto sobre o desempenho, o operador deve ser capaz de identificar rapidamente a causa do gargalo examinando a latência de cada etapa que cada solicitação executa. Os dados de desempenho devem, portanto, fornecer um meio de correlacionar as medidas de desempenho de cada etapa associá-las a uma solicitação específica.
Dependendo dos requisitos de visualização, pode ser útil gerar e armazenar um cubo de dados que contenha exibições dos dados brutos. Esse cubo de dados pode permitir a análise das informações de desempenho e consultas ad hoc complexas.
Monitoramento de segurança
Todos os sistemas comerciais que contêm dados confidenciais devem implementar uma estrutura de segurança. A complexidade do mecanismo de segurança geralmente é uma função da confidencialidade dos dados. Em um sistema que exija que os usuários sejam autenticados, você deve registrar:
- Todas as tentativas de entrada, quer elas falhem ou tenham êxito.
- Todas as operações executadas por – e os detalhes de todos os recursos acessados por – um usuário autenticado.
- Quando um usuário encerra uma sessão e sai.
O monitoramento pode ajudar a detectar ataques ao sistema. Por exemplo, um grande número de tentativas de logon com falha pode indicar um ataque de força bruta. Um aumento inesperado de solicitações pode ser o resultado de um ataque DDoS (de negação de serviço distribuído). Você deve estar preparado para monitorar todas as solicitações para todos os recursos, independentemente da origem dessas solicitações. Um sistema que tenha uma vulnerabilidade de logon pode expor acidentalmente recursos para o mundo exterior sem exigir que um usuário realmente entre.
Requisitos para monitoramento de segurança
Os aspectos mais importantes do monitoramento de segurança devem possibilitar que o operador faça, rapidamente, o seguinte:
- Detecte tentativas de invasão por uma entidade não autenticada.
- Identifique tentativas de entidades de executar operações em dados cujo acesso não lhes foi concedido.
- Determine se o sistema ou parte dele está sob ataque de fora ou de dentro. (Por exemplo, um usuário autenticado mal-intencionado pode estar tentando derrubar o sistema).
Para dar suporte a esses requisitos, o operador deverá ser notificado se:
- Uma conta tentar entrar repetidamente com falha durante um período especificado.
- Uma conta autenticada tentar repetidamente acessar um recurso proibido durante um período especificado.
- Um grande número de solicitações não autenticadas ou não autorizadas ocorrer durante um período especificado.
As informações fornecidas a um operador devem incluir o endereço do host de origem de cada solicitação. Se as violações de segurança forem provenientes, regularmente, de determinado intervalo de endereços, esses hosts poderão ser bloqueados.
Um aspecto fundamental da manutenção da segurança de um sistema é a capacidade de detectar rapidamente ações que desviam do padrão normal. As informações como o número de solicitações de entrada com falha e/ou com êxito podem ser exibidas visualmente para ajudar a detectar se há um aumento na atividade em horário fora do comum. (Um exemplo dessa atividade mostra usuários entrando às 3h e executando um grande número de operações quando seu dia de trabalho começa às 9h). Essas informações também podem ser usadas para ajudar a configurar o dimensionamento automático baseado em tempo. Por exemplo, se o operador observar que um grande número de usuários entra regularmente em um determinado horário do dia, ele pode configurar a inicialização de serviços de autenticação adicionais para lidar com o volume de trabalho e depois desativar esses serviços quando o pico terminar.
Requisitos para coleta de dados, fontes de dados e instrumentação
A segurança é um aspecto abrangente da maioria dos sistemas distribuídos. Os dados pertinentes provavelmente serão gerados em vários pontos em um sistema. Você deve considerar a adoção de uma abordagem SIEM (gerenciamento de informações e eventos de segurança) para coletar informações relacionadas à segurança resultantes de eventos gerados pelo aplicativo, equipamento de rede, servidores, firewalls, software antivírus e outros elementos de prevenção de intrusões.
O monitoramento de segurança pode incorporar dados de ferramentas que não fazem parte do seu aplicativo. Essas ferramentas podem incluir utilitários que identificam atividades de verificação de porta por órgãos externos ou filtros de rede que detectam tentativas de acesso não autenticado ao seu aplicativo e dados.
Em todo caso, os dados coletados devem permitir que o administrador determine a natureza de qualquer ataque e tome as medidas apropriadas.
Analisando dados de segurança
Um recurso do monitoramento de segurança é a variedade de fontes das quais os dados surgem. Os diferentes formatos e níveis de detalhe geralmente exigem uma análise complexa dos dados capturados, para uni-lis em um thread de informações coerente. Além dos casos mais simples (por exemplo, a detecção de um grande número de logons com falha ou tentativas repetidas de acesso não autorizado a recursos críticos), pode não ser possível executar processamentos complexos automatizados dos dados de segurança. Em vez disso, talvez seja preferível gravar esses dados, com selo de data/hora, mas na forma original, em um repositório seguro para permitir a análise manual por especialistas.
monitoramento de SLA
Muitos sistemas comerciais que dão suporte a clientes pagantes fazem garantias quanto ao desempenho do sistema na forma de SLAs. Essencialmente, os SLAs declaram que o sistema é capaz de lidar com um volume definido de trabalho dentro de um período de tempo acordado e sem perder informações críticas. O monitoramento de SLA envolve garantir que o sistema possa atender a SLAs mensuráveis.
Observação
O monitoramento de SLA está intimamente relacionado ao monitoramento de desempenho. Mas enquanto o monitoramento de desempenho tem a finalidade de garantir que o sistema tenha um funcionamento ideal, o monitoramento de SLA é governado por uma obrigação contratual que define o que ideal realmente significa.
Os SLAs geralmente são definidos em termos de:
- Disponibilidade geral do sistema. Por exemplo, uma organização pode garantir que o sistema estará disponível 99,9% do tempo. Isso equivale a não mais que 9 horas de inatividade por ano ou aproximadamente 10 minutos por semana.
- Taxa de transferência operacional. Esse aspecto frequentemente é expresso como um ou mais limites máximos, como garantir que o sistema pode dar suporte a até 100 mil solicitações de usuários simultâneas ou de manipular 10 mil transações de negócios simultâneas.
- Tempo de resposta operacional. O sistema também pode fazer garantias em relação à taxa na qual as solicitações são processadas. Um exemplo é que 99% de todas as transações de negócios serão concluídas em dois segundos e nenhuma transação levará mais de 10 segundos.
Observação
Alguns contratos para sistemas comerciais também podem incluir SLAs de suporte ao cliente. Um exemplo é que todas as solicitações de suporte técnico obterão uma resposta dentro de cinco minutos, e que 99% de todos os problemas serão tratados totalmente dentro de um dia útil. Um acompanhamento de questões (descrito posteriormente nesta seção) eficaz é fundamental para atender a SLAs como esses.
Requisitos para monitoramento de SLA
No nível mais alto, um operador deve ser capaz de determinar rapidamente se o sistema está cumprindo os SLAs ou não. E se não estiver, o operador deve ser capaz de fazer drill down e examinar os fatores subjacentes para determinar as razões de um desempenho abaixo do padrão.
Indicadores amplos comuns que podem ser representados visualmente incluem:
- O percentual de tempo de atividade do serviço.
- A taxa de transferência do aplicativo (medida em termos de transações ou operações bem-sucedidas por segundo).
- O número de solicitações do aplicativo com êxito/falha.
- O número de falhas, exceções e avisos de aplicativo e sistema.
Todos esses indicadores devem ser capazes de ser filtrados por um período de tempo especificado.
Um aplicativo em nuvem provavelmente incluirá um número de subsistemas e componentes. O operador deve ser capaz de selecionar um indicador amplo e ver como ele é composto por meio da integridade dos elementos subjacentes. Por exemplo, se o tempo de atividade do sistema geral ficar abaixo de um valor aceitável, o operador deve ser capaz de ter uma visão detalhadas para determinar quais elementos estão contribuindo para essa falha.
Observação
O tempo de atividade do sistema precisa ser definido com cuidado. Em um sistema que usa a redundância para garantir a disponibilidade máxima, instâncias individuais de elementos podem falhar, mas o sistema pode permanecer funcional. O tempo de atividade do sistema apresentado pelo monitoramento da integridade deve indicar o tempo de atividade agregado de cada elemento, e não necessariamente se o sistema foi de fato interrompido. Além disso, as falhas podem ser isoladas. Portanto, mesmo se um sistema específico não estiver disponível, o restante do sistema poderá permanecer disponível, mas com funcionalidade reduzida. (Em um sistema de comércio eletrônico, uma falha no sistema pode impedir que o cliente faça pedidos, mas ele ainda poderá navegar pelo catálogo de produtos).
Para fins de alerta, o sistema deve ser capaz de acionar um evento se qualquer um dos indicadores amplos ultrapassar um limite especificado. Os detalhes dos diversos fatores que compõem o indicador mais amplo devem estar disponíveis como dados contextuais para o sistema de alertas.
Requisitos para coleta de dados, fontes de dados e instrumentação
Os dados brutos necessários para dar suporte ao monitoramento de SLA são semelhantes aos dados brutos necessários para monitorar o desempenho em conjunto com alguns aspectos do monitoramento da integridade e da disponibilidade. Consulte essas seções para obter mais detalhes. Você pode capturar esses dados por:
- Monitorando pontos de extremidade.
- Logs de exceções, falhas e avisos.
- Rastreando a execução de solicitações do usuário.
- Monitorando a disponibilidade de eventuais serviços de terceiros que o sistema usa.
- Usando contadores e métricas de desempenho.
Todos os dados devem ter informações de temporização e selo de data/hora.
Analisando dados de SLA
Os dados de instrumentação devem ser agregados para gerar uma imagem do desempenho geral do sistema. Os dados agregados também devem dar suporte à busca detalhada para habilitar a análise do desempenho dos subsistemas subjacentes. Por exemplo, você deve ser capaz de:
- Calcular o número total de solicitações de usuários durante determinado período e determinar a taxa de êxito e falha dessas solicitações.
- Combinar os tempos de resposta de solicitações de usuários para gerar uma exibição geral dos tempos de resposta do sistema.
- Analisar o progresso das solicitações de usuários para decompor o tempo de resposta geral de determinada solicitação nos tempos de resposta dos itens de trabalho individuais da solicitação.
- Determinar a disponibilidade geral do sistema como um percentual de tempo de atividade para qualquer período específico.
- Analisar a disponibilidade de tempo percentual dos componentes e serviços individuais do sistema. Isso pode envolver a análise de logs gerados por serviços terceirizados.
Muitos sistemas comerciais precisam relatar os números do desempenho real em comparação com os SLAs acordados por um período específico, que normalmente é de um mês. Essas informações podem ser usadas para calcular créditos ou outras formas de reembolso para os clientes se os SLAs não forem cumpridos durante o período. Você pode calcular a disponibilidade de um serviço usando a técnica descrita na seção Analisando dados de disponibilidade.
Para fins internos, uma organização também pode controlar o número e a natureza dos incidentes que causaram a falha dos serviços. Aprender a resolver esses problemas rapidamente ou eliminá-los completamente ajudará a reduzir o tempo de inatividade e a cumprir aos SLAs.
Auditoria
Dependendo da natureza do aplicativo, pode haver exigências estatutárias ou legais que especificam os requisitos para auditoria das operações dos usuários e registro de todo o acesso aos dados. Uma auditoria pode trazer provas que vinculem clientes a solicitações específicas. O não repúdio é um fator importante em muitos sistemas de comércio eletrônico para ajudar a manter a relação de confiança entre um cliente e a organização responsável pelo aplicativo ou serviço.
Requisitos para auditoria
Um analista deve ser capaz de rastrear a sequência das operações de negócios que os usuários estão executando para que você possa reconstruir as ações deles. Isso pode ser necessário simplesmente para fins de registro ou como parte de uma investigação forense.
As informações de auditoria são altamente confidenciais. Elas provavelmente incluirão dados que identifiquem os usuários do sistema, junto com as tarefas em execução. Por esse motivo, as informações de auditoria provavelmente terão a forma de relatórios que são disponibilizados somente para analistas confiáveis, em vez de usar um sistema interativo que dê suporte a operações gráficas de busca detalhada. Um analista deve ser capaz de gerar uma variedade de relatórios. Por exemplo, relatórios podem listar as atividades de todos os usuários que ocorrem durante um período especificado, detalham a cronologia das atividades de um único usuário ou listam a sequência de operações executadas em um ou mais recursos.
Requisitos para coleta de dados, fontes de dados e instrumentação
As principais fontes de informações para auditoria podem incluir:
- O sistema de segurança que gerencia a autenticação do usuário.
- Logs de rastreamento que registram a atividade do usuário.
- Logs de segurança que rastreiam todas as solicitações de rede identificáveis e não identificáveis.
O formato dos dados de auditoria e a maneira como eles são armazenados pode ser motivado por requisitos regulatórios. Por exemplo, pode não ser possível limpar os dados de qualquer maneira. Ele deve ser gravado em seu formato original) O acesso ao repositório em que ele está mantido deve ser protegido para evitar a violação.
Analisando dados de auditoria
Um analista deve ser capaz de acessar os dados brutos em sua totalidade e em seu formato original. Além de requisito de gerar relatórios de auditoria comuns, as ferramentas usadas para analisar esses dados provavelmente deverão especializadas e mantidas externamente ao sistema.
Monitoramento de uso
O monitoramento de uso controla como os recursos e componentes de um aplicativo são usados. O operador pode usar os dados coletados para:
Determinar quais recursos são usados intensamente e identificar quaisquer possíveis pontos problemáticos no sistema. Os elementos de alto tráfego podem se beneficiar do particionamento funcional ou até mesmo da replicação para distribuir a carga de maneira mais uniforme. Um operador também pode usar essas informações para determinar quais recursos são usados com pouca frequência e são possíveis candidatos à desativação ou substituição em uma versão futura do sistema.
Obter informações sobre os eventos operacionais do sistema em situação de uso normal. Por exemplo, em um site de comércio eletrônico, você pode registrar as informações estatísticas sobre o número de transações e o volume de clientes que são responsáveis por elas. Essas informações podem ser usadas para o planejamento da capacidade à medida que o número de clientes cresce.
Detectar (possivelmente de forma indireta) a satisfação do usuário com o desempenho ou a funcionalidade do sistema. Por exemplo, se um grande número de clientes em um sistema de comércio eletrônico abandonar regularmente seus carrinhos de compras, isso pode ocorrer devido a um problema com a funcionalidade de check-out.
Gerar informações de cobrança. Um aplicativo comercial ou um serviço multilocatário pode cobrar os clientes pelos recursos que eles usam.
Aplicar cotas. Se um usuário de um sistema multilocatário ultrapassar sua cota paga de tempo de processamento ou uso de recursos durante um período especificado, seu acesso poderá ser limitado ou o processamento poderá ser reduzido.
Requisitos para monitoramento de uso
Para examinar o uso do sistema, um operador normalmente precisa consultar informações que incluem:
- O número de solicitações que são processadas por cada subsistema e direcionadas a cada recurso.
- O trabalho que cada usuário está executando.
- O volume de armazenamento de dados que cada usuário ocupa.
- Os recursos que cada usuário está acessando.
Um operador também deve ser capaz de gerar grafos. Por exemplo, um grafo pode exibir os usuários que consomem mais recursos ou os recursos do sistema ou não que são acessados com mais frequência.
Requisitos para coleta de dados, fontes de dados e instrumentação
O rastreamento de uso pode ser executado em um nível relativamente alto. Ele pode observar os horários de início e término de cada solicitação e da natureza da solicitação (ler, gravar e assim por diante, dependendo do recurso em questão). Você pode obter essas informações:
- Rastreando as atividades do usuário.
- Capturando os contadores de desempenho que medem a utilização de cada recurso.
- Monitorando o consumo de recursos por cada usuário.
Para fins de medição, também é necessário ser capaz de identificar quais usuários são responsáveis por executar quais operações. bem como os recursos que essas operações usam. As informações coletadas devem ser detalhadas o suficiente para permitir uma cobrança precisa.
Acompanhamento de problemas
Os clientes e outros usuários podem relatar problemas se eventos ou comportamentos inesperados ocorrerem no sistema. O acompanhamento de questões é voltado gerenciar esses problemas, associá-los a esforços para resolver problemas subjacentes no sistema e informar os clientes de possíveis resoluções.
Requisitos para o acompanhamento de questões
Os operadores normalmente acompanham problemas usando um sistema separado que permite que eles registrem e relatem os detalhes dos problemas relatados pelos usuários. Esses detalhes podem incluir as tarefas que o usuário estava tentando executar, sintomas do problema, a sequência dos eventos e quaisquer mensagens de aviso ou erro emitidas.
Requisitos para coleta de dados, fontes de dados e instrumentação
A fonte inicial dos dados para o acompanhamento de questões é o usuário que relatou o problema em primeiro lugar. O usuário poderá fornecer dados adicionais, como:
- Um despejo de memória (se o aplicativo incluir um componente executado no desktop do usuário).
- Um instantâneo da tela.
- A data e hora em que ocorreu o erro, junto com qualquer outra informação do ambiente, como o local do usuário.
Essas informações podem ser usadas para ajudar no esforço de depuração e na construção de uma lista de pendências para futuras versões do software.
Analisando dados de acompanhamento de problemas
Diferentes usuários podem relatar o mesmo problema. O sistema de acompanhamento deve associar relatórios comuns.
O progresso da iniciativa de depuração deve ser registrado em cada relatório de problema. Quando o problema for resolvido, o cliente pode ser informado da solução.
Se um usuário relatar um problema conhecido que tem solução conhecida no sistema de acompanhamento de questões, o operador deverá ser capaz de informar imediatamente a solução ao usuário.
Rastreando operações e depurando versões de software.
Quando um usuário relata um problema, geralmente ele só está ciente do efeito imediato em suas operações. O usuário só pode relatar os resultados de sua própria experiência a um operador responsável por manter o sistema. Essas experiências geralmente são apenas um sintoma visível de um ou mais problemas fundamentais. Em muitos casos, um analista precisará estudar a cronologia das operações subjacentes para estabelecer a causa raiz do problema. Esse processo se chama análise da causa raiz.
Observação
A análise de causa raiz pode revelar ineficiências no design de um aplicativo. Nessas situações, talvez seja possível refazer os elementos afetados e implantá-los como parte de uma versão subsequente. Esse processo requer um controle cuidadoso, e os componentes atualizados devem ser monitorados de perto.
Requisitos para rastreamento e depuração
Para rastrear eventos inesperados e outros problemas, é vital que os dados de monitoramento forneçam informações suficientes para permitir que o analista rastreie as origens desses problemas e reconstrua a sequência de eventos que ocorreram. Essas informações devem ser suficientes para permitir que o analista diagnostique a causa raiz dos problemas. Um desenvolvedor pode fazer as modificações necessárias para impedir sua repetição.
Requisitos para coleta de dados, fontes de dados e instrumentação
A solução de problemas pode envolver o rastreamento de todos os métodos (e seus parâmetros) chamados como parte de uma operação para construir uma árvore que descreva o fluxo lógico pelo sistema quando um cliente faz uma solicitação específica. Exceções e avisos que o sistema gera como resultado desse fluxo precisam ser capturados e registrados.
Para dar suporte à depuração, o sistema pode fornecer ganchos que permitem que um operador capture informações de estado em pontos importantes no sistema. Ou o sistema pode fornecer informações detalhadas passo a passo como o andamento de operações selecionadas. A captura de dados nesse nível de detalhe podem impor uma carga adicional ao sistema e deve ser um processo temporário. Um operador usa esse processo principalmente quando uma série muito incomum de eventos ocorre e é difícil de replicar, ou quando uma nova versão de um ou mais elementos em um sistema exige monitoramento cuidadoso para garantir que os elementos funcionem conforme o esperado.
O pipeline de monitoramento e diagnóstico
O monitoramento de um sistema distribuído em larga escala representa um desafio significativo. Cada um dos cenários descritos na seção anterior não devem necessariamente ser considerados isoladamente. É provável que haja uma sobreposição significativa dos dados de monitoramento e diagnóstico que são necessários para cada situação, embora esses dados possivelmente tenham que ser processados de diferentes maneiras. Por esses motivos, você deve adotar uma visão holística do monitoramento e do diagnóstico.
Você pode enxergar o processo de diagnóstico e monitoramento inteiro como um pipeline que compreende os estágios mostrados na Figura 1.
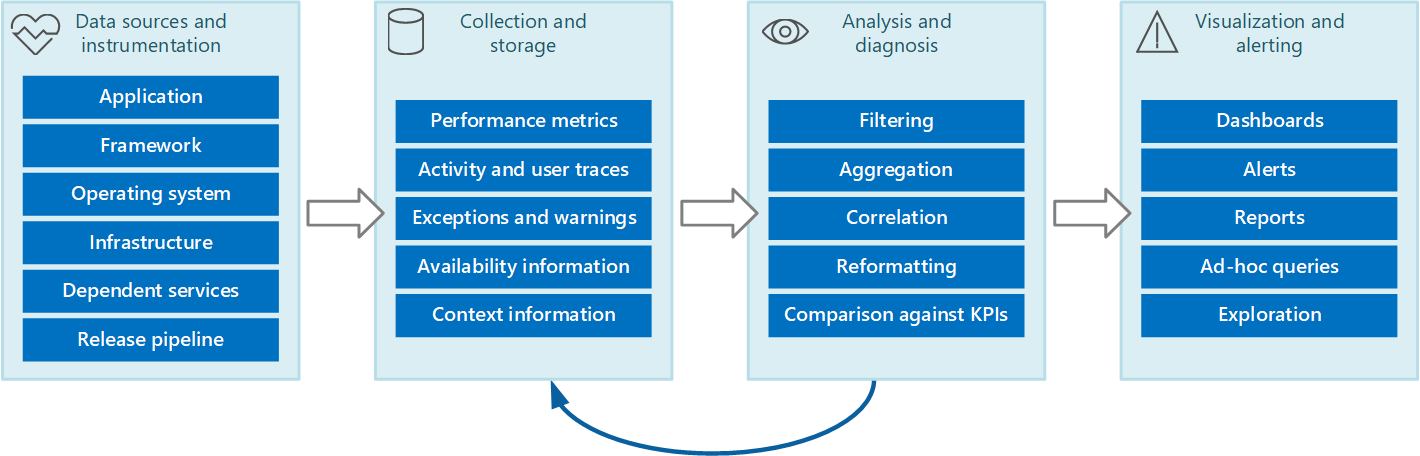
Figura 1 – Os estágios do pipeline de monitoramento e diagnóstico.
A Figura 1 destaca como os dados para monitoramento e diagnóstico podem vir de uma variedade de fontes. Os estágios de instrumentação e coleção tratam da identificação de origens de onde os dados precisam ser capturados, determinando quais dados capturar, como capturá-los e como formatar esses dados para que eles possam ser examinados facilmente. A fase de análise/diagnóstico usa os dados brutos para gerar informações significativas que um operador pode usar para determinar o estado do sistema. O operador pode usar essas informações para tomar decisões sobre possíveis ações a realizar e passar os resultados para os estágios de instrumentação e coleção. A fase do estágio de visualização/alerta apresenta uma exibição de consumo do estado do sistema. Ela pode exibir informações quase em tempo real por meio de uma série de painéis. E ela pode gerar relatórios e grafos para fornecer uma visão histórica dos dados que podem ajudar a identificar tendências a longo prazo. Se as informações indicarem a probabilidade de que um KPI ultrapasse os limites aceitáveis, esse estágio também pode disparar um alerta para um operador. Em alguns casos, um alerta também pode ser usado para disparar um processo automatizado que tenta realizar ações corretivas, como o dimensionamento automático.
Observe que estas etapas constituem um processo de fluxo contínuo em que os estágios acontecem em paralelo. Idealmente, todas as fases devem ser configuradas dinamicamente. Em alguns pontos, especialmente quando um sistema tiver sido implantado recentemente ou estiver com problemas, pode ser necessário reunir dados estendidos com maior frequência. Em outras ocasiões, deve ser possível voltar à captura de um nível básico de informações essenciais para verificar se o sistema está funcionando corretamente.
Além disso, todo o processo de monitoramento deve ser considerado uma solução viva, em andamento, que está sujeita a melhorias e ajustes como resultado de comentários. Por exemplo, você pode iniciar a medição de muitos fatores para determinar a integridade do sistema. A análise ao longo do tempo pode levar a um refinamento conforme você descartar medidas que não são relevantes, permitindo que se concentre mais precisamente nos dados de que precisa, minimizando o ruído de fundo.
Fontes de dados de monitoramento e diagnóstico
As informações que o processo de monitoramento usa podem vir de várias fontes, como ilustrado na Figura 1. No nível do aplicativo, as informações vêm dos logs de rastreamento incorporados no código do sistema. Os desenvolvedores devem seguir uma abordagem padrão para controlar o fluxo de controle por meio de seu código. Por exemplo, uma entrada para um método pode emitir uma mensagem de rastreamento que especifica o nome do método, a hora atual, o valor de cada parâmetro e outras informações pertinentes. Registrar as horas de entrada e saída também pode ser útil.
Você deve registrar todas as exceções e avisos e certifique-se de manter um rastreamento completo de todos os avisos e exceções aninhadas. Idealmente, você também deve capturar informações que identificam o usuário que está executando o código, juntamente com informações de correlação da atividade (para controlar solicitações à medida que passam pelo sistema). E você deverá registrar tentativas de acesso a todos os recursos, como bancos de dados, filas de mensagens, arquivos e outros serviços dependentes. Essas informações podem ser usadas para fins de auditoria e de medição.
Muitos aplicativos usam bibliotecas e estruturas para executar tarefas comuns, como acessar um armazenamento de dados ou se comunicar em uma rede. Essas estruturas podem ser configuráveis para gerar suas próprias mensagens de rastreamento e informações de diagnóstico brutas, como taxas de transação, falhas e êxitos de transmissão de dados.
Observação
Muitas estruturas modernas publicam eventos de desempenho e rastreamento automaticamente. A captura dessas informações significa simplesmente fornecer um meio para recuperá-las e armazená-las onde podem ser processadas e analisadas.
O sistema operacional que está executando o aplicativo pode ser uma fonte de informações detalhadas de todo o sistema, como contadores de desempenho que indicam o uso da CPU, a utilização da memória e as taxas de E/S. Também podem ser relatados erros do sistema operacional (por exemplo, uma falha ao abrir um arquivo corretamente).
Você também deve considerar a infraestrutura e os componentes subjacentes em que seu sistema é executado. Máquinas virtuais, redes virtuais e serviços de armazenamento podem ser fontes de importantes contadores de desempenho no nível da infraestrutura e outros dados de diagnóstico.
Se o seu aplicativo usar outros serviços externos, como um servidor Web ou sistema de gerenciamento de banco de dados, esses serviços podem publicar suas próprias informações de rastreamento, logs e contadores de desempenho. Exemplos incluem Exibições de gerenciamento dinâmico do SQL Server para rastrear as operações executadas em um banco de dados do SQL Server e logs de rastreamento do IIS para registrar as solicitações feitas a um servidor Web.
Conforme os componentes de um sistema são modificados e novas versões são implantadas, é importante ser capaz de atribuir problemas, eventos e métricas a cada versão. Essas informações devem ser vinculadas ao pipeline de versões para que os problemas de uma versão específica de um componente possam ser rastreados rapidamente e corrigidos.
Problemas de segurança podem ocorrer em qualquer ponto do sistema. Por exemplo, um usuário pode tentar entrar com uma ID de usuário ou senha inválida. Um usuário autenticado pode tentar obter acesso não autorizado a um recurso. Ou um usuário pode fornecer uma chave inválida ou desatualizada para acessar informações criptografadas. Informações de segurança sobre solicitações bem-sucedidas e falhas sempre devem ser registradas.
A seção instrumentando um aplicativo contém mais orientações sobre as informações que você deve capturar. Mas você pode usar várias estratégias para coletar essas informações:
Monitoramento de aplicativo/sistema. Essa estratégia usa fontes internas ao aplicativo, estruturas do aplicativo, sistema operacional e infra-estrutura. O código do aplicativo pode gerar seus próprios dados de monitoramento em pontos importantes durante o ciclo de vida de uma solicitação de cliente. O aplicativo pode incluir instruções de rastreamento que podem ser habilitadas ou desabilitadas seletivamente conforme as circunstâncias ditarem. Também é possível inserir diagnóstico dinamicamente usando uma estrutura de diagnóstico. Normalmente, essas estruturas fornecem plug-ins que podem se conectar a vários pontos de instrumentação em seu código e capturar dados de rastreamento nesses pontos.
Além disso, seu código ou a infraestrutura subjacente pode gerar eventos em pontos críticos. Agentes de monitoramento configurados para ouvir esses eventos podem registrar as informações do evento.
Monitoramento do usuário real. Essa abordagem registra as interações entre um usuário e o aplicativo e observa o fluxo de cada solicitação e resposta. Essas informações podem ter um propósito duplo: podem ser usadas para medir o uso por cada usuário e para determinar se os usuários estão recebendo uma qualidade de serviço adequada (por exemplo, tempos de resposta rápidos, baixa latência e pequenos erros). Você pode usar os dados capturados para identificar áreas de preocupação em que as falhas ocorrem com mais frequência. Você também pode usar os dados para identificar elementos onde o sistema fica mais lento, possivelmente devido a pontos de acesso no aplicativo ou a alguma outra forma de gargalo. Se você implementar essa abordagem com cuidado, será possível reconstruir os fluxos dos usuários pelo aplicativo para fins de teste e depuração.
Importante
Você deve considerar os dados capturados no monitoramento de usuários reais como altamente confidenciais porque podem incluir material confidencial. Se você salvar os dados capturados, armazene-os de forma segura. Se você quiser usar os dados para depuração ou monitoramento de desempenho, primeiro remova todos os dados pessoais.
Monitoramento de usuário sintético. Nessa abordagem, você deve escrever seu próprio cliente de teste, que simula um usuário e executa uma série de operações configuráveis típicas. Você pode monitorar o desempenho do cliente de teste para ajudar a determinar o estado do sistema. Você também pode usar várias instâncias do cliente de teste como parte de uma operação de teste de carga para estabelecer qual é a resposta do sistema sob cargas excessivas e que tipo de saída de monitoramento é gerada sob essas condições.
Observação
Você pode implementar o monitoramento de usuários reais e sintéticos incluindo um código que rastreie e temporize a execução de chamadas de método e outras partes essenciais de um aplicativo.
Criação de perfil. Essa abordagem se destina principalmente a monitorar e melhorar o desempenho do aplicativo. Em vez de operar no nível funcional empregado pelo monitoramento de usuários reais e sintéticos, ela captura informações mais detalhadas conforme o aplicativo é executado. Você pode implementar a criação de perfil usando amostragem periódica do estado de execução de um aplicativo (determinando qual parte do código que o aplicativo está executando em determinado momento). Você também pode usar a instrumentação que insere testes no código em momentos importantes (como no início e no fim de uma chamada de método) e registra quais métodos foram chamados, em que momento e quanto tempo cada chamada levou. Você pode analisar esses dados para determinar quais partes do aplicativo podem causar problemas de desempenho.
Monitoramento do ponto de extremidade. Essa técnica usa um ou mais pontos de extremidade de diagnóstico que o aplicativo expõe especificamente para habilitar o monitoramento. Um ponto de extremidade fornece um caminho para o código do aplicativo e pode retornar informações sobre a integridade do sistema. Pontos de extremidade diferentes podem se concentrar em diversos aspectos da funcionalidade. Você pode escrever seu próprio cliente de diagnóstico que envia solicitações periódicas para esses pontos de extremidade e assimilar as respostas. Para obter mais informações, confira o Padrão de monitoramento de ponto de extremidade de integridade.
Para uma máxima cobertura, você deve usar uma combinação dessas técnicas.
instrumentando um aplicativo
A instrumentação é uma parte essencial do processo de monitoramento. Você somente poderá tomar decisões significativas sobre o desempenho e a integridade de um sistema se capturar os dados que lhe permite tomar essas decisões primeiro. As informações reunidas usando a instrumentação devem ser suficientes para que você possa avaliar o desempenho, diagnosticar problemas e tomar decisões sem a necessidade de fazer logon em um servidor de produção remoto para executar o rastreamento (e a depuração) manualmente. Os dados de instrumentação normalmente abrangem informações e métricas que são gravadas nos logs de rastreamento.
O conteúdo de um log de rastreamento pode ser o resultado de dados textuais gravados pelo aplicativo ou de dados binários criados como resultado de um evento de rastreamento, se o aplicativo está usando o ETW (Rastreamento de Eventos para Windows). Eles também podem ser gerados dos logs do sistema que registram eventos resultantes de partes da infraestrutura, como um servidor Web. Mensagens de log textual geralmente são criadas para serem legíveis, mas também devem ser gravadas em um formato que permita que um sistema automatizado possa analisá-las facilmente.
Você também deve classificar os logs. Não grave todos os dados de rastreamento em um único log, mas use logs separados para gravar a saída do rastreamento por meio de diferentes aspectos operacionais do sistema. Você pode filtrar rapidamente as mensagens de log lendo o log adequado em vez de precisar processar um único arquivo longo. Nunca grave informações com requisitos de segurança diferentes (como informações de auditoria e dados de depuração) no mesmo log.
Observação
Um log pode ser implementado como um arquivo no sistema de arquivos ou pode ser mantido em algum outro formato, como um blob no armazenamento de blobs. Informações de log também podem ser mantidas em um armazenamento mais estruturado, como linhas em uma tabela.
As métricas geralmente são uma medida ou contagem de algum aspecto ou recurso do sistema em um momento específico, com uma ou mais marcas ou dimensões associadas (às vezes chamadas de amostra). Uma única instância de uma métrica não costuma ser útil isoladamente. Em vez disso, as métricas precisam ser capturadas ao longo do tempo. A principal questão a considerar é quais métricas você deve registrar e com que frequência. Frequentemente, gerar dados de métricas pode impor uma significativa carga adicional ao sistema, enquanto capturar métricas com pouca frequência pode causar a perda das circunstâncias que levam a um evento significativo. As considerações variam de métrica para métrica. Por exemplo, a utilização da CPU em um servidor pode variar significativamente segundo a segundo, mas a alta utilização se torna um problema apenas se for longa, durante vários minutos.
Informações de correlação de dados
Você pode monitorar os contadores de desempenho individuais no nível de sistema, capturar métricas de recursos e obter informações de rastreamento do aplicativo de vários arquivos de log facilmente. Mas algumas formas de monitoramento requerem o estágio de análise e diagnóstico no pipeline de monitoramento para correlacionar os dados recuperados de várias fontes. Esses dados podem assumir diversas formas como dados brutos, e o processo de análise deve ter dados de instrumentação suficientes para ser capaz de mapear essas diferentes formas. Por exemplo, no nível de estrutura de aplicativo, uma tarefa pode ser identificada por um ID de thread. Dentro de um aplicativo, o mesmo trabalho pode ser associado à ID de usuário do usuário que está executando essa tarefa.
Além disso, é improvável que haja um mapeamento individual dos threads e solicitações de usuário, uma vez que operações assíncronas podem reutilizar os mesmos threads para executar operações em nome de mais de um usuário. Para complicar ainda mais, uma única solicitação pode ser manipulada por mais de um thread ao longo de sua execução no sistema. Se possível, associe cada solicitação a uma ID de atividade exclusiva que é propagada pelo sistema como parte do contexto da solicitação. (A técnica para gerar e incluir IDs de atividade em informações de rastreamento depende da tecnologia usada para capturar os dados de rastreamento).
Todos os dados de monitoramento devem receber o selo de data/hora da mesma maneira. Para ter consistência, registre todas as datas e horas usando o Tempo Universal Coordenado. Isso ajudará você a rastrear sequências de eventos mais facilmente.
Observação
Os computadores que operam em redes e fusos horários diferentes podem não estar sincronizados. Não dependa somente do uso de selos de data/hora para correlacionar dados de instrumentação que abrangem várias máquinas.
Informações a serem incluídas nos dados de instrumentação
Considere os seguintes pontos ao decidir quais dados de instrumentação você precisa coletar:
As informações capturadas por eventos de rastreamento devem ser legíveis por pessoas e máquinas. Adote esquemas bem definidos para essas informações para facilitar o processamento automatizado de dados de log entre sistemas e dar consistência às operações e à equipe de engenharia que lê os logs. Inclua informações de ambiente, como o ambiente de implantação, a máquina na qual o processo está sendo executado, os detalhes do processo e a pilha de chamadas.
Habilite perfis somente quando necessário, pois eles podem impor uma sobrecarga significativa no sistema. A criação de perfis usando instrumentação registra um evento (como uma chamada de método) toda vez que ele ocorre, enquanto a amostragem registra apenas eventos selecionados. A seleção pode ser baseada em tempo (uma vez a cada n segundos) ou em frequência (uma vez a cada n solicitações). Se os eventos ocorrerem com muita frequência, a criação de perfis por instrumentação pode causar uma carga muito grande e ela mesma acabar afetando o desempenho geral. Nesse caso, a abordagem de amostragem pode ser preferível. No entanto, se a frequência de eventos for baixa, a amostragem poderá perdê-los. Nesse caso, a instrumentação pode ser a melhor abordagem.
Forneça contexto suficiente para permitir que o desenvolvedor ou administrador determine a origem de cada solicitação. Isso pode incluir alguma forma de ID da atividade que identifica uma instância específica de uma solicitação. Ele também pode incluir informações que podem ser usadas para correlacionar essa atividade com o trabalho computacional executado e os recursos usados. Observe que esse trabalho pode atravessar limites de processos e máquinas. Para a medição, o contexto também deve incluir (direta ou indiretamente por meio de outras informações correlacionadas) uma referência ao cliente que originou a solicitação. Esse contexto fornece informações valiosas sobre o estado do aplicativo no momento em que os dados de monitoramento foram capturados.
Registre todas as solicitações e os locais ou regiões de onde essas solicitações foram feitas. Essas informações podem ajudar a determinar se há pontos problemáticos específicos do local. Essas informações também podem ser úteis para determinar se é necessário reparticionar um aplicativo ou os dados que ele usa.
Registre e capture com cuidado os detalhes de exceções. Frequentemente, informações críticas sobre a depuração são perdidas como resultado de uma manipulação de exceções deficiente. Capture todos os detalhes de exceções que o aplicativo gera, incluindo exceções internas e outras informações de contexto. Inclua a pilha de chamadas, se possível.
Seja consistente quanto aos dados de que os diferentes elementos do seu aplicativo capturam, pois isso pode auxiliar a analisar os eventos e correlacioná-los a solicitações de usuários. Considere o uso de um pacote de registro em log abrangente e configurável para reunir informações em vez de depender de desenvolvedores para adotar a mesma abordagem ao implementar partes diferentes do sistema. Colete dados dos contadores de desempenho principais, como o volume de E/S executados, a utilização da rede, o número de solicitações, o uso da memória e a utilização da CPU. Alguns serviços de infraestrutura podem fornecer seus próprios contadores de desempenho específicos, como o número de conexões a um banco de dados, a taxa na qual as transações estão sendo executadas e o número de transações com êxito ou falha. Aplicativos também podem definir seus próprios contadores de desempenho.
Registre todas as chamadas feitas para serviços externos, como sistemas de banco de dados, serviços Web ou outros serviços de nível de sistema que são parte da infraestrutura. Registre informações sobre o tempo necessário para executar cada chamada e o êxito ou falha da chamada. Se possível, capture informações sobre todas as tentativas de repetição e as falhas para quaisquer erros transitórios que ocorrem.
Garantindo a compatibilidade com sistemas de telemetria
Em muitos casos, as informações produzidas pela instrumentação são geradas como uma série de eventos e passadas para um sistema de telemetria separado para processamento e análise. Um sistema de telemetria geralmente é independente de qualquer tecnologia ou aplicativo específico, mas espera que as informações sigam um formato específico, geralmente definido por um esquema. O esquema especifica de maneira eficaz um contrato que define os campos e os tipos de dados que o sistema de telemetria pode receber. O esquema deve ser generalizado para permitir que dados sejam recebidos de uma variedade de plataformas e dispositivos.
Um esquema comum deve incluir campos que são comuns a todos os eventos de instrumentação, como o nome do evento, a hora do evento, o endereço IP do remetente e os detalhes necessários para correlacionar com outros eventos (como uma ID de usuário, uma ID de dispositivo e uma ID de aplicativo). Lembre-se de que qualquer número de dispositivos pode gerar eventos e, portanto, o esquema não deve depender do tipo de dispositivo. Além disso, vários dispositivos podem gerar eventos para o mesmo aplicativo. O aplicativo pode dar suporte a roaming ou a alguma outra forma de distribuição entre dispositivos.
O esquema também pode incluir campos de domínio que são relevantes para um determinado cenário comum entre diferentes aplicativos. Poderiam ser informações sobre exceções, eventos de início e término do aplicativo e sucesso ou falha de chamadas à API de serviços Web. Todos os aplicativos que usam o mesmo conjunto de campos de domínio devem emitir o mesmo conjunto de eventos, permitindo que um conjunto de relatórios e análises comuns seja compilado.
Por fim, um esquema pode conter campos personalizados para capturar os detalhes de eventos específicos ao aplicativo.
Práticas recomendadas para a instrumentação de aplicativos
A lista a seguir resume as práticas recomendadas para instrumentar um aplicativo distribuído em execução na nuvem.
Logs facilitam a leitura e a análise. Use logs estruturados sempre que possível. Seja conciso e descritivo nas mensagens de log.
Em todos os logs, identifique a origem e forneça informações de contexto e de tempo conforme cada registro de log é gravado.
Use o mesmo fuso horário e formato para todos os selos de data/hora. Isso ajudará a correlacionar eventos para operações que se estendem para hardware e serviços em execução em diferentes regiões geográficas.
Categorize os logs e grave mensagens no arquivo de log apropriado.
Não divulgue informações confidenciais sobre o sistema ou informações pessoais dos usuários. Limpe essas informações antes do registro, mas certifique-se de que os detalhes relevantes sejam mantidos. Por exemplo, remover a ID e senha de qualquer cadeia de caracteres de conexão de banco de dados, mas grave as informações restantes no log para que um analista possa determinar que o sistema está acessando o banco de dados correto. Registre todas as exceções críticas, mas permita que o administrador ative e desative o registro em log para níveis mais detalhados de exceções e avisos. Além disso, capture e registre todas as informações de lógica de repetição. Esses dados podem ser úteis para monitorar a integridade temporária do sistema.
Rastreie chamadas fora do processo, como solicitações para serviços Web ou banco de dados externos.
Não misture mensagens de log com requisitos de segurança diferentes no mesmo arquivo de log. Por exemplo, não grave informações de depuração e auditoria no mesmo log.
Com exceção dos eventos de auditoria, todas as chamadas de log devem ser operações do tipo "disparar e esquecer", que não atrapalham o progresso das operações de negócios. Eventos de auditoria são excepcionais porque são essenciais para os negócios e podem ser classificados como uma parte fundamental das operações de negócios.
Verifique se o log é extensível e não tem dependências diretas em um destino concreto. Por exemplo, em vez de gravar informações usando System.Diagnostics.Trace, defina uma interface abstrata (como ILogger) que exponha métodos de registro e que possa ser implementada por qualquer meio apropriado.
Verifique se todos os logs são à prova de falhas e nunca disparam erros em cascata. O registro em log não deve lançar exceções.
Trate a instrumentação como um processo iterativo contínuo e analise os logs regularmente, não apenas quando houver um problema.
Coletando e armazenando dados
A fase de coleta do processo de monitoramento é voltada a recuperar informações geradas pela instrumentação, formatar esses dados para facilitar seu consumo pela fase de análise/computação e salvar os dados transformados em um armazenamento confiável e acessível. Os dados de instrumentação que você coletar de diferentes partes de um sistema distribuído poderão ser mantidos em diversos locais e com vários formatos. Por exemplo, o código do aplicativo pode gerar arquivos de log de rastreamento e dados de log de eventos do aplicativo, enquanto os contadores de desempenho que monitoram os principais aspectos da infraestrutura que seu aplicativo usa podem ser capturados por meio de outras tecnologias. Quaisquer componentes e serviços de terceiros que o aplicativo usar poderão fornecer informações de instrumentação em formatos diferentes, usando arquivos de rastreamento separados, armazenamento de blobs ou até mesmo um armazenamento de dados personalizado.
A coleta de dados geralmente é executada por meio de um serviço de coleta que pode ser executado de forma autônoma por meio do aplicativo que gera os dados de instrumentação. A Figura 2 ilustra um exemplo dessa arquitetura, destacando o subsistema de coleta de dados de instrumentação.
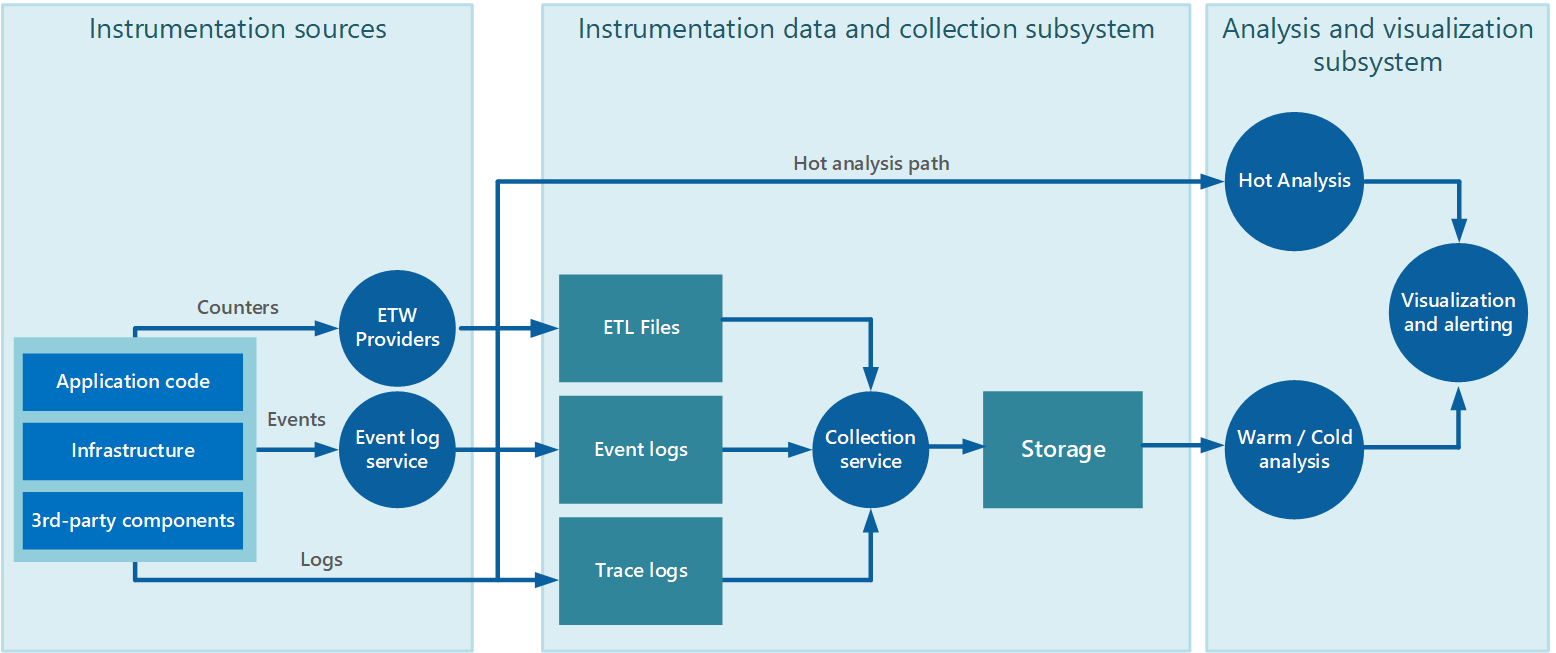
Figura 2 – Coletando dados de instrumentação.
Observe que essa é uma exibição simplificada. O serviço de coleta não é necessariamente um único processo, e;e pode ser composto por várias partes constituintes em execução em máquinas diferentes, conforme descrito nas seções a seguir. Além disso, se a análise de alguns dados de telemetria precisar ser executada rapidamente (a análise hot, conforme descrito na seção Suporte à análise hot, warm e cold mais adiante neste documento), componentes locais que operam fora do serviço de coleta podem executar as tarefas de análise imediatamente. A figura 2 ilustra essa situação para eventos selecionados. Após o processamento analítico, os resultados podem ser enviados diretamente para o subsistema de visualização e alerta. Os dados que são sujeitados a análise warm ou cold são mantidos no armazenamento enquanto esperam o processamento.
Para serviços e aplicativos do Azure, o Diagnóstico do Azure fornece uma possível solução para a captura de dados. O Diagnóstico do Azure reúne dados das seguintes fontes para cada nó de computação, agrega-os e os carrega no Armazenamento do Azure:
- Logs do IIS
- Logs de solicitação com falha IIS
- Logs de eventos do Windows
- Contadores de desempenho
- Despejos de memória
- Logs de infraestrutura do Diagnóstico do Azure
- Logs de erros personalizados
- .NET EventSource
- ETW baseado em manifesto
Para saber mais, confira o artigo Azure: noções básicas de telemetria e solução de problemas
Estratégias para coletar dados de instrumentação
Devido à natureza elástica da nuvem e para evitar a necessidade de recuperar dados de telemetria manualmente de cada nó no sistema, você deve fazer com que os dados sejam transferidos para um local central e consolidados. Em um sistema que se estende por vários datacenters, pode ser útil primeiro coletar, consolidar e armazenar dados região por região e depois agregar os dados regionais em um único sistema central.
Para otimizar o uso da largura de banda, você pode optar por transferir dados menos urgentes em partes, como lotes. No entanto, os dados não devem ser adiados por tempo indeterminado, especialmente se contiverem informações em que o tempo faz diferença.
Receber e enviar dados de instrumentação
O subsistema de coleta de dados de instrumentação pode recuperar ativamente dados de instrumentação de logs e outras fontes para cada instância do aplicativo (o modelo pull). Ou ele pode atuar como um receptor passivo que aguarda que os dados sejam enviados dos componentes que constituem cada instância do aplicativo (o modelo push).
Uma abordagem para implementar o modelo pull é usar agentes de monitoramento em execução localmente com cada instância do aplicativo. Um agente de monitoramento é um processo separado que recupera periodicamente (recebe por pull) dados de telemetria coletados no nó local e grava essas informações diretamente no armazenamento centralizado que é compartilhado por todas as instâncias do aplicativo. Esse é o mecanismo que o Diagnóstico do Azure implementa. Cada instância de uma função de trabalho ou web do Azure pode ser configurada para capturar informações de diagnóstico e outras informações de rastreamento que são armazenadas localmente. O agente de monitoramento que é executado em cada instância copia os dados especificados para o Armazenamento do Azure. O artigo Habilitando o diagnóstico nos Serviços de Nuvem do Azure e máquinas virtuais fornece mais detalhes sobre esse processo. Alguns elementos, como logs do IIS, despejos de memória e logs de erros personalizados, são gravados no armazenamento de blobs. Os dados do log de eventos do Windows, eventos de ETW e contadores de desempenho são gravados no armazenamento de tabelas. A Figura 3 ilustra esse mecanismo.
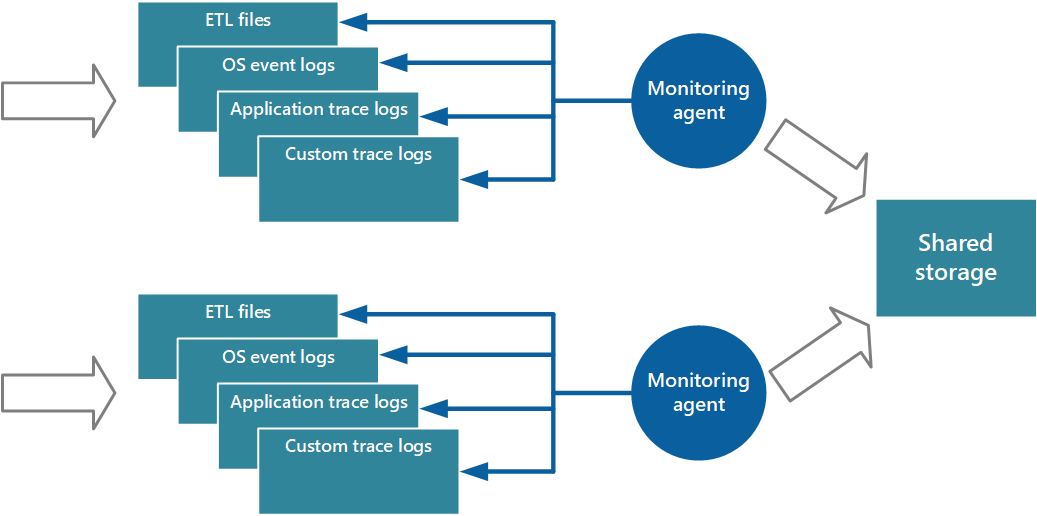
Figura 3 – Usando um agente de monitoramento para obter informações e gravar em um armazenamento compartilhado.
Observação
O uso de um agente de monitoramento é ideal para capturar dados de instrumentação obtidos naturalmente de uma fonte de dados. Um exemplo é as informações de exibições de gerenciamento dinâmico do SQL Server ou o comprimento de uma fila do Barramento de Serviço do Azure.
É viável usar a abordagem descrita para armazenar dados de telemetria de um aplicativo de pequena escala em execução em um número limitado de nós em um mesmo local. No entanto, um aplicativo em nuvem global complexo, altamente escalonável, pode gerar volumes enormes de dados de centenas de funções da Web e de trabalho, de fragmentos de bancos de dados e outros serviços. Esse fluxo de dados poderia facilmente sobrecarregar a largura de banda de E/S disponível com um único local central. Portanto, sua solução de telemetria deve ser escalonável para impedir que ela atue como um gargalo conforme o sistema se expanda. Idealmente, sua solução deverá incorporar um grau de redundância para reduzir os riscos de perda de informações de monitoramentos importantes (como dados de cobrança ou de auditoria) se parte do sistema falhar.
Para resolver esses problemas, você pode implementar o enfileiramento, conforme mostrado na Figura 4. Nessa arquitetura, o agente de monitoramento local (se puder ser configurado adequadamente) ou o serviço de coleta de dados personalizado (se não) posta os dados em uma fila. Um processo separado em execução assíncrona (o armazenamento de serviço de gravação na Figura 4) usa os dados nessa fila e grava-os no armazenamento compartilhado. Uma fila de mensagens é adequada para esse cenário porque fornece semântica "pelo menos uma vez" que ajuda a garantir que os dados na fila não serão perdidos depois que ele for lançado. Você pode implementar o serviço de gravação em armazenamento usando uma função de trabalho separada.
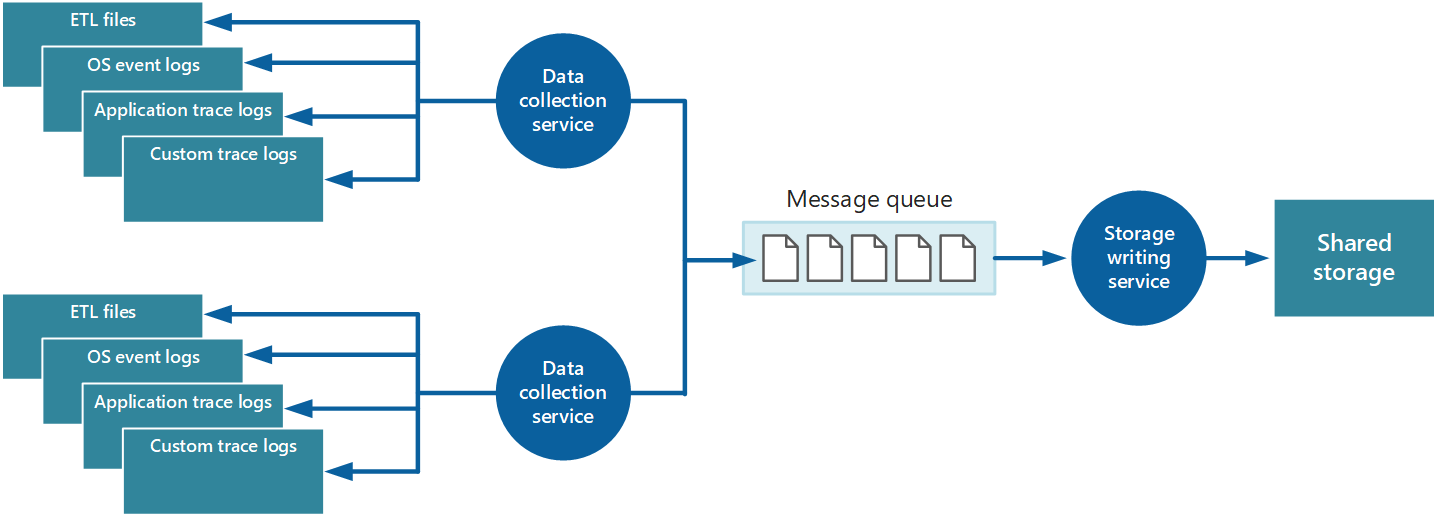
Figura 4 – Usando uma fila para armazenar dados de instrumentação em buffer.
O serviço de coleta de dados local pode adicionar dados a uma fila imediatamente após seu recebimento. A fila atua como um buffer e o serviço de gravação em armazenamento pode recuperar e gravar os dados em seu próprio ritmo. Por padrão, uma fila opera no sistema primeiro a entrar, primeiro a sair. Mas você poderá priorizar mensagens para passá-las pela fila se elas contiverem dados que devem ser tratados mais rapidamente. Para saber mais, consulte o Padrão fila de prioridade. Como alternativa, você pode usar diferentes canais (como os tópicos do Barramento de Serviço) para direcionar dados para destinos diferentes dependendo do formato do processamento analítico necessário.
Para ter dimensionalidade, você pode executar várias instâncias do serviço de gravação em armazenamento. Se houver um grande volume de eventos, você poderá usar um hub de eventos para enviar os dados para diferentes recursos de computação para processamento e armazenamento.
Consolidando dados de instrumentação
Os dados de instrumentação recuperados pelo serviço de coleta de dados de uma única instância de um aplicativo fornece uma exibição localizada da integridade e do desempenho dessa instância. Para avaliar a integridade geral do sistema, é necessário consolidar alguns aspectos dos dados dos modos de exibição locais. Você poderá executar esse procedimento depois que os dados forem armazenados, mas, em alguns casos, também poderá obter o resultado enquanto os dados são coletados. Em vez de serem gravados diretamente no armazenamento compartilhado, os dados de instrumentação podem passar por um serviço de consolidação de dados separado que combine os dados e atue como um processo de filtro e limpeza. Por exemplo, dados de instrumentação que incluem as mesmas informações de correlação, como uma ID de atividade, podem ser mesclados. É possível que um usuário comece a executar uma operação de negócios em um nó e, em seguida, seja transferido para outro nó em caso de falha de nó ou dependendo de como o balanceamento de carga está configurado.) Esse processo também pode detectar e remover dados duplicados (sempre uma possibilidade quando o serviço de telemetria usar filas de mensagens para enviar dados de instrumentação por push para o armazenamento). A Figura 5 ilustra um exemplo dessa estrutura.
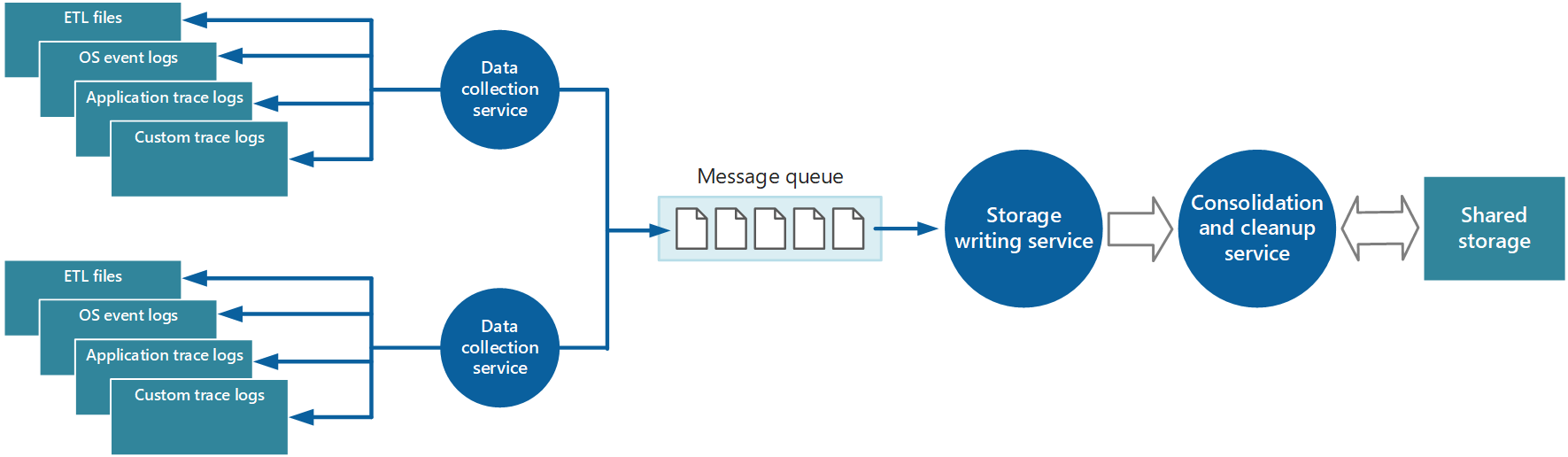
Figura 5 – Usando um serviço separado para consolidar e limpar dados de instrumentação.
Armazenando dados de instrumentação
As discussões anteriores deram uma visão bastante simplista da forma como dados de instrumentação são armazenados. Na verdade, pode fazer sentido armazenar diferentes tipos de informações usando tecnologias mais apropriadas para a maneira como cada tipo de informação provavelmente será usada.
Por exemplo, os armazenamentos de blobs e de tabelas do Azure têm algumas semelhanças na maneira como são acessados. Mas eles têm limitações nas operações que você pode executar ao usá-los, e a granularidade dos dados que eles contêm é bastante diferente. Se você precisar executar operações mais analíticas ou precisar de recursos de pesquisa de texto completo dos dados, pode ser mais adequado usar o armazenamento de dados que fornece recursos otimizados para tipos específicos de consultas e acesso de dados. Por exemplo:
- Os dados do contador de desempenho podem ser armazenados em um banco de dados SQL para habilitar uma análise ad hoc.
- Os logs de rastreamento podem ser armazenados mais adequadamente no Azure Cosmos DB.
- As informações de segurança podem ser gravadas no HDFS.
- As informações que exigem pesquisa de texto completo podem ser armazenadas por meio de Elasticsearch (que também pode agilizar pesquisas usando a indexação avançada).
Você pode implementar um serviço adicional que recupere periodicamente dados do armazenamento compartilhado, particione e filtre os dados de acordo com sua finalidade e os grave em um conjunto apropriado de armazenamentos de dados conforme mostrado na Figura 6. Uma abordagem alternativa é incluir essa funcionalidade no processo de consolidação e a limpeza e gravar os dados diretamente nesses armazenamentos conforme eles são recuperados, em vez de salvá-los em uma área de armazenamento compartilhado intermediária. Cada abordagem tem suas vantagens e desvantagens. Implementar um serviço separado de particionamento diminui a carga sobre o serviço de limpeza e a consolidação e permite que pelo menos alguns dos dados particionados sejam regenerados se necessário (dependendo da quantidade de dados mantidos no armazenamento compartilhado). No entanto, ele consome recursos adicionais. Além disso, pode haver um atraso entre o recebimento de dados de instrumentação de cada instância do aplicativo e a conversão de dados em informações acionáveis.
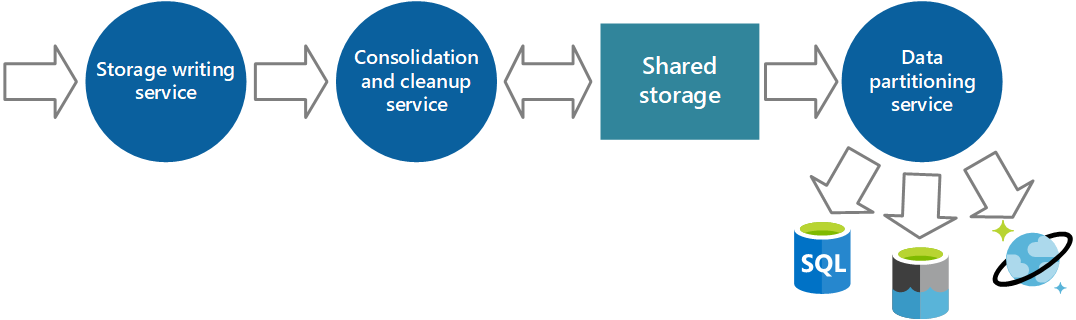
Figura 6 – Particionamento de dados de acordo com requisitos de análise e de armazenamento.
Os mesmos dados de instrumentação podem ser necessários para mais de um propósito. Por exemplo, os contadores de desempenho podem ser usados para fornecer uma exibição do histórico de desempenho do sistema ao longo do tempo. Essas informações podem ser combinadas com outros dados de uso para gerar informações de cobrança do cliente. Nessas situações, os mesmos dados podem ser enviados para mais de um destino, como um banco de dados de documento que pode atuar como um armazenamento de longo prazo para manter informações de cobrança e um armazenamento multidimensional para lidar com análises de desempenho complexas.
Você também deve a urgência com que os dados são necessários. Dados que fornecem informações para a geração de alertas têm que ser acessados rapidamente e, por isso, devem ser mantidos em um armazenamento de dados rápido e indexados ou estruturados de modo a otimizar as consultas que sistema de alertas executa. Em alguns casos, pode ser necessário que o serviço de telemetria que reúne os dados em cada nó formate e salve os dados localmente para que uma instância local do sistema de alerta possa notificar você rapidamente sobre problemas. Os mesmos dados podem ser enviados para o serviço de gravação em armazenamento mostrado nos diagramas anteriores e armazenados centralmente se também forem necessários para outras finalidades.
Informações que são usadas para análises mais consideradas, para gerar relatórios e para identificar tendências históricas são menos urgentes e podem ser armazenadas de uma forma que dê suporte à mineração de dados e a consultas ad hoc. Para saber mais, confira a seção Suporte a análises hot, warm e cold mais adiante neste documento.
Rotação de logs e retenção de dados
A instrumentação pode gerar volumes consideráveis de dados. Esses dados podem ser mantidos em diversos locais, começando pelos arquivos de log brutos, arquivos de rastreamento e outras informações capturadas em cada nó para a exibição consolidada, limpa e particionada desses dados mantidos em um armazenamento compartilhado. Em alguns casos, depois que os dados são processados e transferidos, os dados brutos de origem podem ser removidos de cada nó. Em outros casos, pode ser necessário ou simplesmente útil salvar as informações brutas. Por exemplo, pode ser melhor deixar dados gerados para fins de depuração disponíveis em sua forma bruta, mas eles poderão ser descartados bem rapidamente após os bugs serem corrigidos.
Dados de desempenho geralmente têm uma vida útil mais longa para que possam ser usados na identificação de tendências de desempenho e no planejamento de capacidade. A exibição consolidada dos dados geralmente é mantida online por um período limitado para habilitar o acesso rápido. Depois disso, ela pode ser arquivada ou descartada. Dados coletados para medição e de cobrança clientes talvez precisem ser salvos indefinidamente. Além disso, requisitos regulatórios podem exigir que as informações coletadas para fins de auditoria e segurança também sejam arquivados e salvos. Esses dados também são confidenciais e talvez precisem ser criptografados ou protegidos para evitar violações. Você nunca deve gravar as senhas dos usuários ou outras informações que podem ser usadas para cometer fraudes de identidade. Esses detalhes devem ser removidos dos dados antes do armazenamento.
Redução da resolução
É útil armazenar dados históricos para que você possa identificar tendências de longo prazo. Em vez de salvar dados antigos em sua totalidade, talvez seja possível reduzir a amostra de dados para reduzir sua resolução e economizar custos com armazenamento. Como exemplo, em vez de salvar indicadores de desempenho minuto a minuto, dados de mais de um mês podem ser consolidados para formar um modo de exibição de hora em hora.
Práticas recomendadas para coletar e armazenar informações de log
A lista a seguir resume as práticas recomendadas para capturar e armazenar informações de log:
O agente de monitoramento ou o serviço de coleta de dados deve ser executado como um serviço fora do processo e deve ser simples de implantar.
Toda a saída do agente de monitoramento ou do serviço de coleta de dados deve ter um formato independente da máquina, do sistema operacional ou do protocolo de rede. Por exemplo, emita informações em um formato autodescritivo como JSON, MessagePack ou Protobuf em vez de ETL/ETW. O uso de um formato padrão permite que o sistema construa pipelines de processamento. Componentes que leem, transformam e enviam dados no formato combinado podem ser integrados facilmente.
O processo de coleta de dados e monitoramento deve ser à prova de falhas e não deve disparar condições de erro em cascata.
Em caso de falha temporária no envio de informações para um coletor de dados, o agente de monitoramento ou o serviço de coleta de dados deve estar preparado para reorganizar os dados de telemetria a fim de que as informações mais recentes sejam enviadas primeiro. (O serviço de coleta de dados/agente de monitoramento pode optar por descartar os dados mais antigos ou salvá-lo localmente e transmiti-los posteriormente para acompanhamento, a seu próprio critério).
Analisando dados e diagnosticando problemas
Uma parte importante do processo de monitoramento e diagnóstico é analisar os dados coletados para obter uma visão do bem-estar geral do sistema. Você deve definir seus próprios KPIs e métricas de desempenho, e é importante entender como você pode estruturar os dados que foram coletados para atender às suas necessidades de análise. Também é importante entender como os dados capturados em diferentes métricas e arquivos de log estão correlacionados, pois essas informações podem ser fundamentais para rastrear uma sequência de eventos e ajudar a diagnosticar problemas que surgirem.
Conforme descrito na seção Consolidando dados de instrumentação, os dados de cada parte do sistema geralmente são capturados localmente, mas normalmente precisam ser combinados com dados gerados em outros locais que participam do sistema. Essas informações requerem uma correlação cuidadosa para garantir que os dados sejam combinados com precisão. Por exemplo, os dados de uso de uma operação podem incluir um nó que hospeda um site ao qual um usuário se conecta, um nó que executa um serviço separado acessado como parte dessa operação e o armazenamento de dados mantido em um nó adicional. Essas informações precisam ser vinculadas para fornecer uma visão geral do uso de recursos e processamento da operação. O pré-processamento e a filtragem de dados podem ocorrer no nó em que os dados são capturados, enquanto a agregação e a formatação têm maior probabilidade de ocorrer em um nó central.
Suporte à análise hot, warm e cold
Analisar e reformatar dados para visualização, geração de relatórios e alertas pode ser um processo complexo que consome seu próprio conjunto de recursos. Algumas formas de monitoramento precisam ser pontuais e requerem análise imediata dos dados para serem eficazes. Elas são conhecidas como análises hot. Exemplos incluem as análises que são necessárias para gerar alertas e alguns aspectos do monitoramento de segurança (como detectar um ataque ao sistema). Os dados que forem necessários para esses fins devem ser disponibilizados e estruturados rapidamente para um processamento eficiente. Em alguns casos, pode ser necessário mover a processamento da análise para os nós individuais onde os dados são mantidos.
Outras formas de análise são menos críticas e podem exigir um pouco de computação e agregação após os dados brutos serem recebidos. Isso é chamado de análise warm. A análise de desempenho normalmente se encaixa nesta categoria. Nesse caso, é improvável que um evento de desempenho único e isolado seja estatisticamente relevante. Pode ser causado por um pico repentino ou uma falha. Os dados de uma série de eventos devem apresentar uma imagem mais confiável do desempenho do sistema.
A análise warm também pode ser usada para ajudar a diagnosticar problemas de integridade. Um evento de integridade normalmente é processado por meio de análises hot e pode gerar um alerta imediatamente. Um operador deve ser capaz de analisar as razões do evento de integridade examinando os dados do caminho warm. Esses dados devem conter informações sobre os eventos que levaram ao problema que causou o evento de integridade.
Alguns tipos de monitoramento geram dados mais de longo prazo. Essa análise pode ser executada em uma data posterior, possivelmente de acordo com uma programação predefinida. Em alguns casos, talvez a análise precise executar a filtragem complexa de grandes volumes de dados capturados em um período de tempo. Isso é chamado de análise cold. O principal requisito é que os dados sejam armazenados em segurança após serem capturados. Por exemplo, a auditoria e o monitoramento de uso exigem uma imagem precisa do estado do sistema em momentos regulares, mas essas informações de estado não precisam estar disponíveis para processamento imediatamente após serem coletadas.
A análise cold também pode ser usada a fim de fornecer dados para análise de previsão de integridade. O operador pode coletar informações de histórico durante um período especificado e usá-las em conjunto com os dados atuais de integridade (recuperados do afunilamento) para identificar tendências que em breve poderão causar problemas de integridade. Nesses casos, pode ser necessário emitir um alerta para que a ação corretiva possa ser executada.
Correlacionando dados
Os dados capturados pela instrumentação podem fornecer um instantâneo do estado do sistema, mas o objetivo da análise é tornar esses dados acionáveis. Por exemplo:
- O que causou uma intensa carga de E/S no nível do sistema em um momento específico?
- Trata-se do resultado de um grande número de operações de banco de dados?
- Isso é refletido nos tempos de resposta do banco de dados, no número de transações por segundo e nos tempos de resposta do aplicativo ao mesmo tempo?
Se sim, uma ação corretiva que pode reduzir a carga pode ser fragmentar os dados em mais servidores. Além disso, exceções podem surgir como resultado de uma falha em qualquer nível do sistema. Uma exceção em um nível normalmente dispara outra falha no nível acima.
Por esses motivos, você precisa ser capaz de correlacionar os diferentes tipos de dados de monitoramento em cada nível para produzir uma visão geral do estado do sistema e dos aplicativos que são executados nele. Você pode usar essas informações para tomar decisões sobre se o sistema está funcionando de forma aceitável ou não e determinar o que pode ser feito para melhorar a qualidade do sistema.
Conforme descrito na seção Informações para correlação de dados, você deve garantir que os dados brutos de instrumentação incluam informações suficientes de contexto e ID de atividades para dar suporte às agregações necessárias para a correlação de eventos. Além disso, esses dados podem ser mantidos em formatos diferentes e pode ser necessário analisar essas informações para convertê-los em um formato padronizado para análise.
Solução de problemas e diagnósticos
O diagnóstico exige a capacidade de determinar a causa das falhas ou comportamentos inesperados, incluindo a realização de análise da causa raiz. As informações necessárias geralmente incluem:
- Informações detalhadas de logs de eventos e rastreamentos para todo o sistema ou para um subsistema especificado durante um período especificado.
- Rastreamentos de pilha completos, resultantes de exceções e falhas de qualquer nível especificado que ocorrerem tanto dentro do sistema ou em um subsistema especificado durante um período especificado.
- Despejos de memória para todos os processos com falha em qualquer parte do sistema ou de um subsistema especificado durante um período especificado.
- Logs de atividades que gravaram as operações executadas por todos os usuários ou por usuários selecionados durante um período especificado.
A análise de dados para fins de solução de problemas normalmente requer um conhecimento técnico profundo da arquitetura do sistema e dos vários componentes que compõem a solução. Como resultado, frequentemente é necessário um alto grau de intervenção manual para interpretar os dados, estabelecer a causa dos problemas e recomendar uma estratégia apropriada para corrigi-los. Pode ser apropriado simplesmente armazenar uma cópia dessas informações em seu formato original e torná-la disponível para análise cold por um especialista.
Visualizando dados e gerando alertas
Um aspecto importante de qualquer sistema de monitoramento é a capacidade de apresentar os dados de forma que um operador possa identificar problemas ou tendências rapidamente. Também é importante a capacidade de informar rapidamente um operador em caso de evento significativo que possa exigir atenção.
A apresentação de dados pode ter diversos formatos, incluindo a visualização usando painéis, alertas e relatórios.
Visualização usando painéis
A maneira mais comum para visualizar dados é usar painéis que podem exibir informações como uma série de tabelas, grafos ou de alguma outra maneira ilustrada. Esses itens podem ser parametrizados e um analista deve ser capaz de selecionar os parâmetros importantes (como o período de tempo) para qualquer situação específica.
Os painéis podem ser organizados hierarquicamente. Os painéis de nível superior podem dar uma visão geral de cada aspecto do sistema, mas permitem ao operador fazer drill down. Por exemplo, um painel que mostra a E/S de disco geral para o sistema deve permitir que um analista veja as taxas de E/S para cada disco individual para determinar se um ou mais dispositivos específicos são responsáveis por um volume desproporcional de tráfego. O ideal é que o painel também exiba informações relacionadas, como a origem de cada solicitação (o usuário ou atividade) que está gerando a E/S. Essas informações podem ser usadas para determinar se (e como) é necessário distribuir a carga de forma mais uniforme entre os dispositivos e se o sistema teria um desempenho melhor se mais dispositivos fossem adicionados.
Um painel também pode usar codificação por cores ou outras indicações visuais para indicar valores que parecem anormais ou que estão fora de um intervalo esperado. Usando o exemplo anterior:
- Um disco com uma taxa de E/S que está atingindo sua capacidade máxima por um longo período (um disco hot) pode ser destacado em vermelho.
- Um disco com uma taxa de E/S que é executado periodicamente no seu limite máximo por curtos períodos (um disco warm) pode ser destacado em amarelo.
- Um disco que está apresentando uso normal pode ser exibido em verde.
Observe que, para que um sistema de painéis funcione de maneira eficaz, ele deve ter dados brutos com os quais trabalhar. Se estiver criando seu próprio sistema de painéis ou usando um painel desenvolvido por outra empresa, você deve compreender quais dados de instrumentação precisa coletar, em quais níveis de granularidade e como eles deve ser formatados para consumo pelo painel.
Um bom painel não exibe apenas informações, ele permite que um analista faça perguntas ad hoc sobre essas informações. Alguns sistemas oferecem ferramentas de gerenciamento que o operador pode usar para executar essas tarefas e explorar os dados subjacentes. Como alternativa, dependendo do repositório usado para manter essas informações, talvez seja possível consultar os dados diretamente ou importá-los para ferramentas como o Microsoft Excel para análises e relatórios posteriores.
Observação
Você deve restringir o acesso aos painéis a pessoal autorizado, já que essas informações podem ser confidenciais comercialmente. Você também deve proteger os dados subjacentes para que o painel de controle impeça que os usuários os alterem.
Gerando alertas
Gerar alertas é o processo de analisar os dados de instrumentação e monitoramento e gerar uma notificação se for detectado um evento significativo.
A geração de alertas ajuda a garantir que o sistema permaneça íntegro, responsivo e seguro. Trata-se de uma parte importante de qualquer sistema que faz garantias de desempenho, disponibilidade e privacidade para os usuários e cujos dados precisem ser acionados imediatamente. Talvez seja necessário notificar o operador do evento que disparou o alerta. Os alertas também podem ser usados para invocar funções do sistema, como o dimensionamento automático.
A geração de alertas normalmente depende dos seguintes dados de instrumentação:
- Eventos de segurança. Se os logs de eventos indicarem que falhas repetidas autenticação ou autorização estão ocorrendo, o sistema pode estar sob ataque e um operador deve ser informado.
- Métricas de desempenho. O sistema deve responder rapidamente se uma métrica de desempenho específica ultrapassar um limite especificado.
- Informações de disponibilidade. Se uma falha for detectada, talvez seja necessário reiniciar rapidamente um ou mais subsistemas ou fazer um failover para um recurso de backup. Falhas repetidas em um subsistema podem indicar problemas mais graves.
Operadores podem receber informações de alerta por meio de vários canais de distribuição, como emails, mensagens de texto SMS ou um dispositivo de pager. Um alerta também pode incluir uma indicação de quão crítica é a situação. Muitos sistemas de alertas dão suporte a grupos de assinantes e todos os operadores que são membros do mesmo grupo podem receber o mesmo conjunto de alertas.
Um sistema de alertas deve ser personalizável e os valores apropriados dos dados de instrumentação subjacentes podem ser fornecidos como parâmetros. Essa abordagem permite que o operador filtre dados e se concentra nos limites ou combinações de valores que são de seu interesse. Observe que, em alguns casos, os dados brutos de instrumentação podem ser fornecidos para o sistema de alertas. Em outras situações, pode ser melhor fornecer dados agregados. (Por exemplo, um alerta poderá ser disparado se a utilização da CPU de um nó tiver excedido 90% nos últimos 10 minutos). Os detalhes fornecidos para o sistema de alertas também devem incluir informações de resumo e contexto apropriados. Esses dados podem ajudar a reduzir a possibilidade de que eventos que são falso positivo disparem um alerta.
Reporting
A emissão de relatórios é usada para gerar uma visão geral do sistema. Eles podem incorporar dados históricos além das informações atuais. Os requisitos para a geração de relatórios se enquadram em duas categorias amplas: relatórios operacionais e relatórios de segurança.
Relatórios operacionais geralmente incluem os seguintes aspectos:
- Agregar estatísticas que você pode usar para compreender a utilização de recursos do sistema geral ou de subsistemas especificados durante um período especificado.
- Identificar tendências na utilização de recursos do sistema geral ou de subsistemas específicos durante um período especificado.
- Monitorar as exceções que ocorreram em todo o sistema ou em subsistemas especificados durante um período especificado.
- Determinar a eficiência do aplicativo em termos dos recursos implantados e compreender se o volume de recursos (e seu custo associado) pode ser reduzido sem afetar o desempenho desnecessariamente.
Os relatórios de segurança tratam do uso do sistema de controle pelo cliente. Eles podem incluir:
- Auditoria de operações do usuário. Isso requer a gravação de solicitações individuais que cada usuário realiza, além de datas e horas. Os dados devem ser estruturados para permitir que um administrador reconstrua rapidamente a sequência de operações executadas por um usuário específico em um período especificado.
- Controle do uso do recurso pelo usuário. Isso requer a gravação de como cada solicitação de um usuário acessa os vários recursos que compõem o sistema e por quanto tempo. Um administrador deve ser capaz de usar esses dados para gerar um relatório de utilização por usuário por um período especificado, possivelmente para fins de cobrança.
Em muitos casos, os processos em lotes podem gerar relatórios de acordo com um agendamento definido. A latência não costuma ser um problema. Mas eles também devem estar disponíveis para a geração de uma base ad hoc, se necessário. Por exemplo, se estiver armazenando dados em um banco de dados relacional, como o Banco de Dados SQL do Azure, você pode usar uma ferramenta como o SQL Server Reporting Services para extrair e formatar dados e apresentá-lo como um conjunto de relatórios.
Próximas etapas
- Visão geral do Azure Monitor
- Monitoramento, diagnóstico e solução de problemas de Armazenamento do Microsoft Azure
- Visão geral dos alertas no Microsoft Azure
- Exibir as notificações de integridade do serviço usando o Portal do Azure
- O que é o Application Insights?
- Diagnóstico de desempenho de máquinas virtuais do Azure
- Baixe e instale o SSDT (SQL Server Data Tools) para Visual Studio
Recursos relacionados
- diretrizes de dimensionamento automático descrevem como diminuir a sobrecarga de gerenciamento ao reduzir a necessidade de um operador monitorar o desempenho de um sistema continuamente e tomar decisões sobre como adicionar ou remover recursos.
- Padrão de monitoramento de ponto de extremidade de integridade descreve como implementar verificações funcionais dentro de um aplicativo que ferramentas externas podem acessar por meio de pontos de extremidade expostos em intervalos regulares.
- Padrão de fila de prioridade mostra como priorizar mensagens em fila para que solicitações urgentes sejam recebidas e possam ser processadas antes de mensagens menos urgentes.