Copiar e transformar dados no Snowflake V1 usando o Azure Data Factory ou o Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade Copy no Azure Data Factory e em pipelines do Azure Synapse para copiar dados de e para o Snowflake e como usar o Fluxo de Dados para transformar dados no Snowflake. Para mais informações, consulte o artigo introdutório do Data Factory ou do Azure Synapse Analytics.
Importante
O conector do Snowflake V2 dá suporte nativo aprimorado ao Snowflake. Se você está usando o conector do Snowflake V1 na sua solução, recomendamos atualizar o conector do Snowflake o quanto antes. Consulte esta seção para obter detalhes sobre a diferença entre V2 e V1.
Funcionalidades com suporte
Esse conector Snowflake é compatível com as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/coletor) | ① ② |
| Fluxo de dados de mapeamento (origem/coletor) | ① |
| Atividade de pesquisa | ① ② |
| Atividade de Script | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
No caso da atividade Copy, esse conector Snowflake dá suporte às seguintes funções:
- Copiar os dados do Snowflake utilizando o comando do Snowflake COPY into [location] para obter o melhor desempenho.
- Copie os dados para o Snowflake aproveitando o comando do Snowflake COPY into [table] para obter o melhor desempenho. Ele oferece suporte ao Snowflake no Azure.
- Se um proxy for necessário para se conectar ao Snowflake de um Runtime de integração auto-hospedada, você deverá configurar as variáveis de ambiente como HTTP_PROXY e HTTPS_PROXY no host do Microsoft Integration Runtime.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele. Adicione os endereços IP usados pelo runtime de integração auto-hospedada à lista de permissões.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
A conta do Snowflake usada como Origem ou Coletor deve ter o acesso USAGE necessário ao banco de dados e acesso de leitura/gravação no esquema e nas tabelas/exibições contidas nele. Além disso, ele também deve ter CREATE STAGE no esquema para poder criar o estágio Externo com a URI SAS.
Os valores de propriedades da Conta a seguir devem ser definidos
| Propriedade | Descrição | Obrigatório | Padrão |
|---|---|---|---|
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_CREATION | Especifica se é necessário exigir um objeto de integração de armazenamento como credenciais de nuvem ao criar um estágio externo nomeado (usando CREATE STAGE) para acessar um local de armazenamento em nuvem privado. | FALSE | FALSE |
| REQUIRE_STORAGE_INTEGRATION_FOR_STAGE_OPERATION | Especifica se é necessário usar um estágio externo nomeado que referencie um objeto de integração de armazenamento como credenciais de nuvem ao carregar ou descarregar dados em um local de armazenamento em nuvem privado. | FALSE | FALSE |
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao Snowflake usando a interface do usuário
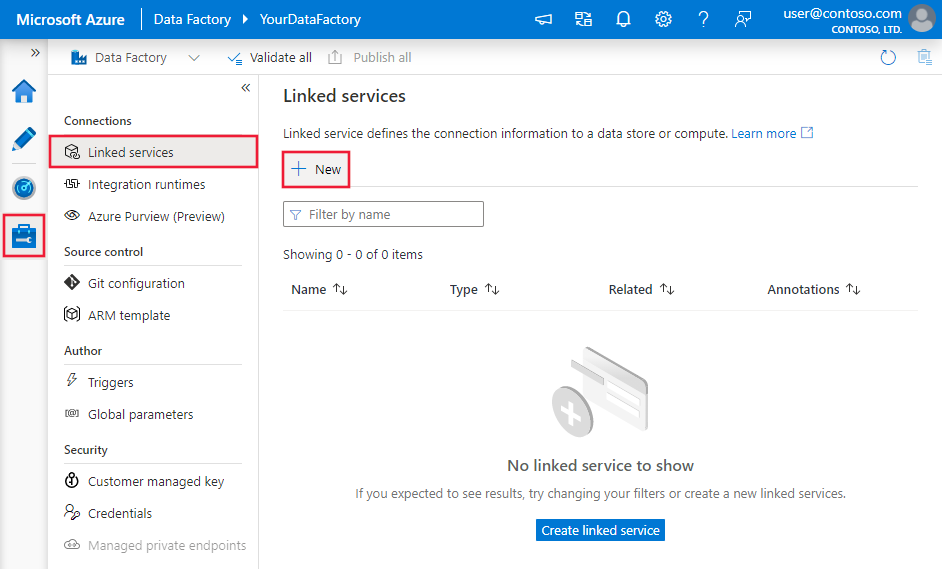
Use as etapas a seguir para criar um serviço vinculado ao Snowflake na interface do usuário do portal do Microsoft Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou do Synapse e selecione Serviços Vinculados, em seguida, clique em Novo:
Pesquise por Snowflake e selecione o conector Snowflake.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
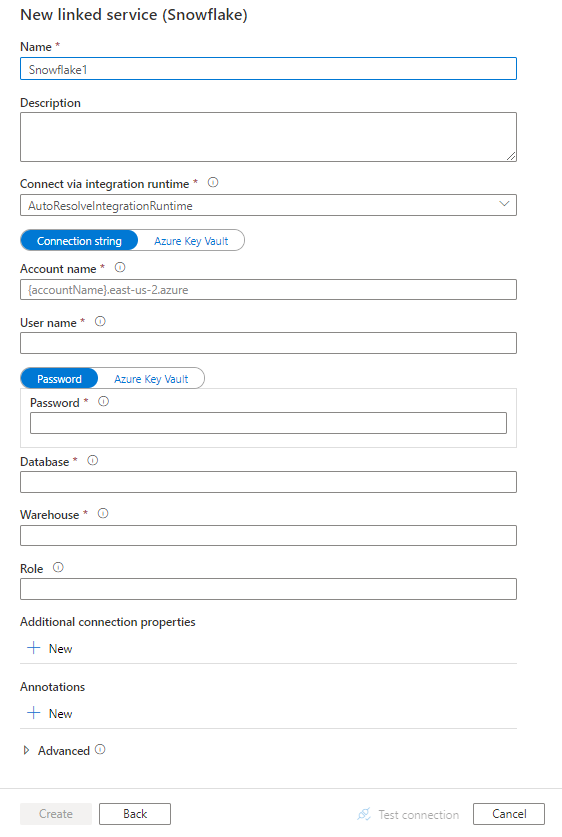
Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades específicas de um conector Snowflake.
Propriedades do serviço vinculado
Esse conector do Snowflake dá suporte aos seguintes tipos de autenticação. Consulte as seções correspondentes para obter detalhes.
Autenticação Básica
As propriedades a seguir têm suporte para um serviço vinculado do Snowflake ao usar a autenticação Básico.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como Snowflake. | Sim |
| connectionString | Especifica as informações necessárias para se conectar à instância do Snowflake. Você pode optar por colocar a senha ou a cadeia de conexão inteira no Azure Key Vault. Consulte os exemplos abaixo da tabela, e o artigo Armazenar credenciais no Azure Key Vault, para obter mais detalhes. Algumas configurações típicas: - Nome da conta: O nome completo da sua conta do Snowflake (incluindo segmentos adicionais que identificam a região e a plataforma de nuvem), por exemplo, xy12345.east-us-2.azure. - Nome de usuário: O nome de logon do usuário para a conexão. - Senha: A senha do usuário. - Banco de dados: O banco de dados padrão a ser usado depois de conectado. Ele deve ser um banco de dados existente para o qual a função especificada tem privilégios. - Warehouse: O warehouse virtual a ser usado depois de conectado. Ele deve ser um banco de dados existente para o qual a função especificada tem privilégios. - Função: A função de controle de acesso padrão a ser usada na sessão do Snowflake. A função especificada deve ser uma função existente que já foi atribuída ao usuário especificado. A função padrão é PUBLIC. |
Sim |
| authenticationType | Defina esta propriedade como Básico. | Sim |
| connectVia | O runtime de integração que é usado para se conectar ao armazenamento de dados. Você poderá usar o runtime de integração do Azure ou um runtime de integração auto-hospedada (se o seu armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o runtime de integração padrão do Azure. | Não |
Exemplo:
{
"name": "SnowflakeLinkedService",
"properties": {
"type": "Snowflake",
"typeProperties": {
"authenticationType": "Basic",
"connectionString": "jdbc:snowflake://<accountname>.snowflakecomputing.com/?user=<username>&password=<password>&db=<database>&warehouse=<warehouse>&role=<myRole>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Senha no Azure Key Vault:
{
"name": "SnowflakeLinkedService",
"properties": {
"type": "Snowflake",
"typeProperties": {
"authenticationType": "Basic",
"connectionString": "jdbc:snowflake://<accountname>.snowflakecomputing.com/?user=<username>&db=<database>&warehouse=<warehouse>&role=<myRole>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre Conjuntos de Dados.
As propriedades a seguir têm suporte para o conjunto de dados do Snowflake.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como: SnowflakeTable. | Sim |
| esquema | Nome do esquema. Observe que o nome do esquema diferencia maiúsculas de minúsculas. | Não para origem, Sim para coletor |
| tabela | Nome da tabela/exibição. Observe que o nome da tabela diferencia maiúsculas de minúsculas. | Não para origem, Sim para coletor |
Exemplo:
{
"name": "SnowflakeDataset",
"properties": {
"type": "SnowflakeTable",
"typeProperties": {
"schema": "<Schema name for your Snowflake database>",
"table": "<Table name for your Snowflake database>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte na origem e no coletor do Snowflake.
Snowflake como a origem
O conector Snowflake utiliza o comando do Snowflake COPY into [location] para obter o melhor desempenho.
Se o armazenamento de dados e o formato do coletor tiverem suporte nativo do comando COPY do Snowflake, você poderá usar a atividade Copy para copiar diretamente do Snowflake para o coletor. Para obter detalhes, consulte Cópia direta do Snowflake. Caso contrário, use a Cópia preparada do Snowflake.
Ao copiar os dados do Snowflake, as seguintes propriedades têm suporte na seção de origem da atividade Copy.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da origem da atividade Copy deve ser definida como SnowflakeSource. | Sim |
| Consulta | Especifica a consulta SQL para ler os dados do Snowflake. Se os nomes do esquema, tabela e colunas contiverem letras minúsculas, mencione o identificador de objeto na consulta, por exemplo, select * from "schema"."myTable".Não há suporte para a execução de procedimentos armazenados. |
Não |
| exportSettings | Configurações avançadas usadas para recuperar dados do Snowflake. Configure aqueles com suporte no comando COPY into pelos quais o serviço passará quando você invocar a instrução. | Sim |
Em exportSettings: |
||
| type | O tipo de comando de exportação, definido como SnowflakeExportCopyCommand. | Yes |
| additionalCopyOptions | Opções de cópia adicionais, fornecidas como um dicionário de pares chave-valor. Exemplos: MAX_FILE_SIZE, OVERWRITE. Para mais informações, consulte Opções de cópia do Snowflake. | No |
| additionalFormatOptions | Opções de formato de arquivo adicionais que são fornecidas ao comando COPY como um dicionário de pares chave-valor. Exemplos: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Para mais informações, consulte Opções de tipo de formato do Snowflake. | No |
Observação
Verifique se você tem permissão para executar o comando a seguir e acessar o esquema INFORMATION_SCHEMA e a tabela COLUMNS.
COPY INTO <location>
Cópia direta a partir do Snowflake
Se o armazenamento de dados e o formato do coletor atenderem aos critérios descritos nesta seção, você poderá usar a atividade Copy para copiar diretamente do Snowflake para o coletor. O serviço verifica as configurações e falha na execução da atividade Copy se os critérios a seguir não forem atendidos:
O serviço vinculado do coletor é o Armazenamento de Blobs do Azure com autenticação de assinatura de acesso compartilhado. Se desejar copiar dados diretamente para o Azure Data Lake Storage Gen2 no formato com suporte a seguir, você pode criar um serviço vinculado de blob do Azure com a autenticação SAS em sua conta do ADLS Gen2 e assim evitar o uso da cópia preparada do Snowflake.
O formato de dados do coletor é de Parquet, texto delimitado ou JSON, com as seguintes configurações:
- Para o formato Parquet, o codec de compactação é Nenhum, Snappy ou Lzo.
- Para formato de texto delimitado:
-
rowDelimiteré \r\n, ou qualquer caractere único. -
compressionpode ser sem compactação, gzip, bzip2 ou deflate. -
encodingNameé deixado como padrão ou definido como utf-8. -
quoteCharé aspas duplas,aspas simplesou cadeia de caracteres vazia (sem char de aspas).
-
- Para o formato JSON, a cópia direta dá suporte apenas ao caso em que o resultado da consulta ou tabela Snowflake de origem tenha apenas uma coluna e o tipo de dados dessa coluna for VARIANT,OBJECTou ARRAY.
-
compressionpode ser sem compactação, gzip, bzip2 ou deflate. -
encodingNameé deixado como padrão ou definido como utf-8. -
filePatternno coletor da atividade de cópia é deixado como padrão ou definido como setOfObjects.
-
Na origem da atividade Copy,
additionalColumnsnão está especificado.O mapeamento de colunas não está especificado.
Exemplo:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM MYTABLE",
"exportSettings": {
"type": "SnowflakeExportCopyCommand",
"additionalCopyOptions": {
"MAX_FILE_SIZE": "64000000",
"OVERWRITE": true
},
"additionalFormatOptions": {
"DATE_FORMAT": "'MM/DD/YYYY'"
}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Cópia preparada a partir do Snowflake
Quando o formato ou o armazenamento de dados do coletor não for nativamente compatível com o comando COPY do Snowflake, conforme mencionado na última seção, habilite a cópia em etapas integrada usando uma instância provisória do Armazenamento de Blobs do Azure. O recurso de cópia em etapas também proporciona uma melhor taxa de transferência. O serviço exporta dados do Snowflake para o armazenamento de preparo, em seguida copia os dados para o coletor e, por fim, limpa os dados temporários do armazenamento de preparo. Confira Cópia preparada para obter detalhes sobre a cópia de dados por meio do preparo.
Para usar esse recurso, crie um serviço vinculado do Armazenamento de Blobs do Azure que se refira à conta de armazenamento do Azure como sendo o armazenamento de preparo. Em seguida, especifique as propriedades enableStaging e stagingSettings na atividade Copy.
Observação
O serviço vinculado do Armazenamento de Blob do Azure de preparo deve usar a autenticação de assinatura de acesso compartilhado, conforme exigido pelo comando COPY do Snowflake. Conceda a permissão de acesso adequada ao Snowflake no Armazenamento de Blobs do Azure de preparo. Para saber mais sobre isso, consulte este artigo.
Exemplo:
"activities":[
{
"name": "CopyFromSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Snowflake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SnowflakeSource",
"query": "SELECT * FROM MyTable",
"exportSettings": {
"type": "SnowflakeExportCopyCommand"
}
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Snowflake como coletor
O conector Snowflake utiliza o comando do Snowflake COPY into [table] para obter o melhor desempenho. No Azure, ele dá suporte à escrita de dados no Snowflake.
Se o armazenamento de dados e o formato do coletor tiverem suporte nativo do comando COPY do Snowflake, você poderá usar a atividade Copy para copiar diretamente da origem para o Snowflake. Para obter detalhes, consulte Cópia direta para o Snowflake. Caso contrário, use a Cópia preparada para o Snowflake interna.
Para copiar dados para o Snowflake, as seguintes propriedades têm suporte na seção de coletor da atividade Copy.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do coletor da atividade Copy deve ser definida como SnowflakeSink. | Yes |
| preCopyScript | Especifique uma consulta SQL para a atividade Copy a ser executada antes de gravar dados no Snowflake em cada execução. Use essa propriedade para limpar os dados pré-carregados. | Não |
| importSettings | Configurações avançadas usadas para gravar dados no Snowflake. Configure aqueles com suporte no comando COPY into pelos quais o serviço passará quando você invocar a instrução. | Sim |
Em importSettings: |
||
| type | O tipo de comando de exportação, definido como SnowflakeExportCopyCommand. | Yes |
| additionalCopyOptions | Opções de cópia adicionais, fornecidas como um dicionário de pares chave-valor. Exemplos: ON_ERROR, FORCE, LOAD_UNCERTAIN_FILES. Para mais informações, consulte Opções de cópia do Snowflake. | No |
| additionalFormatOptions | Opções de formato de arquivo adicionais que são fornecidas ao comando COPY como um dicionário de pares chave-valor. Exemplos: DATE_FORMAT, TIME_FORMAT, TIMESTAMP_FORMAT. Para mais informações, consulte Opções de tipo de formato do Snowflake. | No |
Observação
Verifique se você tem permissão para executar o comando a seguir e acessar o esquema INFORMATION_SCHEMA e a tabela COLUMNS.
SELECT CURRENT_REGION()COPY INTO <table>SHOW REGIONSCREATE OR REPLACE STAGEDROP STAGE
Cópia direta para o Snowflake
Se o armazenamento e o formato de dados de origem atenderem aos critérios descritos nesta seção, você poderá usar a atividade Copy para copiar diretamente da origem para o Snowflake. O serviço verifica as configurações e falha na execução da atividade Copy se os critérios a seguir não forem atendidos:
O serviço vinculado do coletor é o Armazenamento de Blobs do Azure com autenticação de assinatura de acesso compartilhado. Para copiar dados diretamente do Azure Data Lake Storage Gen2 no formato compatível a seguir, crie um serviço vinculado de Blob do Azure com a autenticação SAS na conta do ADLS Gen2 a fim de evitar o uso da cópia preparada para Snowflake.
O formato de dados do coletor é de Parquet, texto delimitado ou JSON, com as seguintes configurações:
Para o formato Parquet, o codec de compactação é Nenhum ou Snappy.
Para formato de texto delimitado:
-
rowDelimiteré \r\n, ou qualquer caractere único. Se o delimitador de linha não for "\r\n",firstRowAsHeaderprecisará ser false, eskipLineCountnão estar especificado. -
compressionpode ser sem compactação, gzip, bzip2 ou deflate. -
encodingNameé deixado como padrão ou definido como "UTF-8", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "BIG5", "EUC-JP", "EUC-KR", "GB18030", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255". -
quoteCharé aspas duplas,aspas simplesou cadeia de caracteres vazia (sem char de aspas).
-
Para o formato JSON, a cópia direta dá suporte apenas ao caso em que a tabela Snowflake do coletor tenha apenas uma coluna e o tipo de dados dessa coluna for VARIANT,OBJECTou ARRAY.
-
compressionpode ser sem compactação, gzip, bzip2 ou deflate. -
encodingNameé deixado como padrão ou definido como utf-8. - O mapeamento de colunas não está especificado.
-
Na origem da atividade Copy:
-
additionalColumnsnão está especificado. - Se sua origem for uma pasta,
recursiveé definido como verdadeiro. -
prefix,modifiedDateTimeStart,modifiedDateTimeEnd, eenablePartitionDiscoverynão especificado.
-
Exemplo:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeSink",
"importSettings": {
"type": "SnowflakeImportCopyCommand",
"copyOptions": {
"FORCE": "TRUE",
"ON_ERROR": "SKIP_FILE"
},
"fileFormatOptions": {
"DATE_FORMAT": "YYYY-MM-DD"
}
}
}
}
}
]
Cópia preparada para o Snowflake
Quando o formato ou o armazenamento de dados de origem não for nativamente compatível com o comando Snowflake COPY, conforme mencionado na última seção, habilite a cópia temporária interna usando uma instância de Armazenamento de Blobs do Azure. O recurso de cópia em etapas também proporciona uma melhor taxa de transferência. O serviço converte automaticamente os dados para atender aos requisitos de formato de dados do Snowflake. Em seguida, ele invoca o comando COPY para carregar dados no Snowflake. Finalmente, ele limpa seus dados temporários do armazenamento de blobs. Confira Cópia preparada para obter detalhes sobre a cópia de dados por meio do preparo.
Para usar esse recurso, crie um serviço vinculado do Armazenamento de Blobs do Azure que se refira à conta de armazenamento do Azure como sendo o armazenamento de preparo. Em seguida, especifique as propriedades enableStaging e stagingSettings na atividade Copy.
Observação
O serviço vinculado do Armazenamento de Blob do Azure de preparo deve usar a autenticação de assinatura de acesso compartilhado, conforme exigido pelo comando COPY do Snowflake.
Exemplo:
"activities":[
{
"name": "CopyToSnowflake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Snowflake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SnowflakeSink",
"importSettings": {
"type": "SnowflakeImportCopyCommand"
}
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Propriedades do fluxo de dados de mapeamento
Ao transformar dados no fluxo de dados de mapeamento, você pode ler e gravar em tabelas no Snowflake. Para obter mais informações, confira transformação de origem e transformação do coletor nos fluxos de dados de mapeamento. Você pode optar por usar um conjunto de dados do Snowflake ou um conjunto de dados embutido como origem e tipo de coletor.
Transformação de origem
A tabela abaixo lista as propriedades com suporte por uma Snowflake. Você pode editar essas propriedades na guia Opções de origem. O conector utiliza a transferência de dados internado Snowflake.
| Name | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Tabela | Se você selecionar Tabela como entrada, o fluxo de dados buscará todos os dados da tabela especificada no conjunto de dados do Snowflake ou nas opções de origem ao usar o conjunto de dados embutido. | Não | String |
(somente para o conjuntos de dados em linha) tableName schemaName |
| Consulta | Se você selecionar Consulta como entrada, insira uma consulta para buscar dados do Snowflake. Essa configuração substitui qualquer tabela que você tenha escolhido no conjunto de dados. Se os nomes do esquema, tabela e colunas contiverem letras minúsculas, mencione o identificador de objeto na consulta, por exemplo, select * from "schema"."myTable". |
Não | String | consulta |
| Habilitar a extração incremental (versão prévia) | Use esta opção para informar ao ADF para processar apenas as linhas que foram alteradas desde a última vez que o pipeline executou. | Não | Boolean | enableCdc |
| Coluna Incremental | Ao usar o recurso de extração incremental, será necessário escolher a coluna de data/hora/numérica que você deseja usar como marca d'água na tabela de origem. | Não | String | waterMarkColumn |
| Habilitar o Controle de Alterações do Snowflake (versão prévia) | Essa opção permite que o ADF aproveite a tecnologia de captura de dados de alterações do Snowflake para processar apenas os dados delta desde a última execução do pipeline. Essa opção carrega automaticamente os dados delta com operações de inserção, atualização e exclusão de linhas sem a necessidade de nenhuma coluna incremental. | Não | Boolean | enableNativeCdc |
| Alterações Líquidas | Ao usar o controle de alterações do Snowflake, você pode usar essa opção para obter linhas alteradas desduplicadas ou alterações exaustivas. As linhas alteradas desduplicadas mostrarão apenas as versões mais recentes das linhas que foram alteradas desde um determinado momento no tempo, enquanto as alterações exaustivas mostrarão todas as versões de cada linha que foi alterada, incluindo aquelas que foram excluídas ou atualizadas. Por exemplo, se você atualizar uma linha, verá uma versão de exclusão e uma versão de inserção em alterações exaustivas, mas somente a versão de inserção em linhas alteradas com deduções. Dependendo do seu caso de uso, você pode escolher a opção que atenda às suas necessidades. A opção padrão é false, o que significa alterações exaustivas. | Não | Boolean | netChanges |
| Incluir Colunas do sistema | Ao usar o controle de alterações do Snowflake, você pode usar a opção systemColumns para controlar se as colunas de fluxo de metadados fornecidas pelo Snowflake estão incluídas ou excluídas na saída de controle de alterações. Por padrão, systemColumns está definido como true, o que significa que as colunas de fluxo de metadados estão incluídas. Você pode definir systemColumns como false se quiser excluí-las. | Não | Boolean | systemColumns |
| Iniciar a leitura desde o início | Definir essa opção com extração incremental e controle de alterações instruirá o ADF a ler todas as linhas na primeira execução de um pipeline com extração incremental ativada. | Não | Boolean | skipInitialLoad |
Exemplos de script de origem do Snowflake
Quando você usa um conjunto de dados do Snowflake como tipo de origem, o script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
query: 'select * from MYTABLE',
format: 'query') ~> SnowflakeSource
Se você usar um conjuntos de dados embutido, o script de fluxo de dados associado será:
source(allowSchemaDrift: true,
validateSchema: false,
format: 'query',
query: 'select * from MYTABLE',
store: 'snowflake') ~> SnowflakeSource
Controle de Alterações Nativo
O Azure Data Factory agora dá suporte a um recurso nativo no Snowflake conhecido como controle de alterações, que envolve o acompanhamento de mudanças na forma de logs. Esse recurso do Snowflake nos permite acompanhar as alterações nos dados ao longo do tempo, tornando-os úteis para o carregamento incremental de dados e para fins de auditoria. Para utilizar esse recurso, quando você habilita a Captura de dados de alterações e seleciona o Controle de Alterações do Snowflake, criamos um objeto Stream para a tabela de origem que permite o controle de alterações na tabela de origem do Snowflake. Posteriormente, usamos a cláusula CHANGES em nossa consulta para buscar apenas os dados novos ou atualizados da tabela de origem. Além disso, é recomendável agendar o pipeline de modo que as alterações sejam consumidas dentro do intervalo de tempo de retenção de dados definido para a tabela de origem do Snowflake, caso contrário, o usuário poderá ver um comportamento inconsistente nas alterações capturadas.
Transformação de coletor
A tabela abaixo lista as propriedades com suporte por um coletor do Snowflake. Você pode editar essas propriedades na guia Configurações. Ao usar o conjunto de dados em linha, você verá configurações adicionais, que são as mesmas que as propriedades descritas na seção propriedades do conjunto de dados. O conector utiliza a transferência de dados interna doSnowflake.
| Name | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Método Update | Especifique quais são as operações permitidas no seu destino do Snowflake. Para atualizar, fazer upsert ou excluir linhas, uma transformação Alter row é necessária para marcar as linhas para essas ações. |
Sim |
true ou false |
deletable insertable Pode ser atualizado upsertable |
| Colunas de chaves | Para atualizações, upserts e exclusões, é necessário selecionar uma coluna de chave ou colunas para determinar qual linha alterar. | No | Array | chaves |
| Ação tabela | determina se deve-se recriar ou remover todas as linhas da tabela de destino antes da gravação. - None: nenhuma ação será feita na tabela. - Recreate: a tabela será descartada e recriada. Necessário ao criar uma tabela dinamicamente. - Truncate: todas as linhas da tabela de destino serão removidas. |
Não |
true ou false |
recreate truncate |
Exemplos de script do coletor do Snowflake
Quando você usa um conjunto de dados do Snowflake como tipo de origem, o script de fluxo de dados associado é:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Se você usar um conjuntos de dados embutido, o script de fluxo de dados associado será:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
format: 'table',
tableName: 'table',
schemaName: 'schema',
deletable: true,
insertable: true,
updateable: true,
upsertable: false,
store: 'snowflake',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SnowflakeSink
Otimização de Pushdown de consulta
Ao definir o Nível de Registros em Log do pipeline como Nenhum, excluímos a transmissão de métricas de transformação intermediárias, evitando possíveis obstáculos para as otimizações do Spark e possibilitando a otimização de pushdown de consulta fornecida pelo Snowflake. Essa otimização de pushdown permite melhorias substanciais de desempenho para grandes tabelas do Snowflake com conjuntos de dados extensos.
Observação
Não damos suporte a tabelas temporárias no Snowflake, pois elas são locais para a sessão ou usuário que as cria, tornando-as inacessíveis a outras sessões e propensas a serem substituídas como tabelas regulares pelo Snowflake. Embora o Snowflake ofereça tabelas transitórias como alternativa, acessíveis globalmente, elas exigem exclusão manual, contradizendo nosso principal objetivo de usar tabelas temporárias, que é evitar quaisquer operações de exclusão no esquema de origem.
Pesquisar propriedades de atividade
Para obter mais informações sobre as propriedades, confira Atividade de pesquisa.
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como fontes e coletores por atividade Copy, consulte armazenamentos e formatos de dados compatíveis.