Rozwiązywanie problemów z zapytaniem, które wykazuje znaczącą różnicę wydajności między dwoma serwerami
Dotyczy: SQL Server
Ten artykuł zawiera kroki rozwiązywania problemów z wydajnością, w których zapytanie działa wolniej na jednym serwerze niż na innym serwerze.
Symptomy
Załóżmy, że istnieją dwa serwery z zainstalowanym programem SQL Server. Jedno z wystąpień programu SQL Server zawiera kopię bazy danych w innym wystąpieniu programu SQL Server. Po uruchomieniu zapytania względem baz danych na obu serwerach zapytanie działa wolniej na jednym serwerze niż drugi.
Poniższe kroki mogą pomóc w rozwiązaniu tego problemu.
Krok 1. Określenie, czy jest to typowy problem z wieloma zapytaniami
Użyj jednej z następujących dwóch metod, aby porównać wydajność dla co najmniej dwóch zapytań na dwóch serwerach:
Ręcznie przetestuj zapytania na obu serwerach:
- Wybierz kilka zapytań do testowania z priorytetem ustawionym na zapytania, które są następujące:
- Znacznie szybciej na jednym serwerze niż na drugim.
- Ważne dla użytkownika/aplikacji.
- Często wykonywane lub projektowane w celu odtworzenia problemu na żądanie.
- Wystarczająco długo, aby przechwycić dane (na przykład zamiast zapytania 5 milisekund wybierz zapytanie 10 sekund).
- Uruchom zapytania na dwóch serwerach.
- Porównaj czas (czas trwania) na dwóch serwerach dla każdego zapytania.
- Wybierz kilka zapytań do testowania z priorytetem ustawionym na zapytania, które są następujące:
Analizowanie danych wydajności za pomocą narzędzia SQL Nexus.
- Zbierz dane PSSDiag/SQLdiag lub SQL LogScout dla zapytań na dwóch serwerach.
- Zaimportuj zebrane pliki danych za pomocą programu SQL Nexus i porównaj zapytania z dwóch serwerów. Aby uzyskać więcej informacji, zobacz Porównanie wydajności między dwiema kolekcjami dzienników (na przykład Powolne i Szybkie).
Scenariusz 1. Tylko jedno zapytanie wykonuje inaczej na dwóch serwerach
Jeśli tylko jedno zapytanie wykonuje inaczej, problem jest bardziej prawdopodobny dla pojedynczego zapytania, a nie dla środowiska. W takim przypadku przejdź do kroku 2: Zbieranie danych i określanie typu problemu z wydajnością.
Scenariusz 2. Wiele zapytań działa inaczej na dwóch serwerach
Jeśli wiele zapytań działa wolniej na jednym serwerze niż drugi, najbardziej prawdopodobną przyczyną są różnice w środowisku serwera lub danych. Przejdź do pozycji Diagnozowanie różnic w środowisku i sprawdź, czy porównanie między dwoma serwerami jest prawidłowe.
Krok 2. Zbieranie danych i określanie typu problemu z wydajnością
Zbieranie czasu, czasu procesora CPU i odczytów logicznych
Aby zebrać czas, który upłynął i czas procesora CPU zapytania na obu serwerach, użyj jednej z następujących metod, które najlepiej pasują do twojej sytuacji:
W przypadku aktualnie wykonywanych instrukcji sprawdź kolumny total_elapsed_time i cpu_time w sys.dm_exec_requests. Uruchom następujące zapytanie, aby pobrać dane:
SELECT req.session_id , req.total_elapsed_time AS duration_ms , req.cpu_time AS cpu_time_ms , req.total_elapsed_time - req.cpu_time AS wait_time , req.logical_reads , SUBSTRING (REPLACE (REPLACE (SUBSTRING (ST.text, (req.statement_start_offset/2) + 1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text) ELSE req.statement_end_offset END - req.statement_start_offset)/2) + 1) , CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text FROM sys.dm_exec_requests AS req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ORDER BY total_elapsed_time DESC;W przypadku poprzednich wykonań zapytania sprawdź kolumny last_elapsed_time i last_worker_time w sys.dm_exec_query_stats. Uruchom następujące zapytanie, aby pobrać dane:
SELECT t.text, (qs.total_elapsed_time/1000) / qs.execution_count AS avg_elapsed_time, (qs.total_worker_time/1000) / qs.execution_count AS avg_cpu_time, ((qs.total_elapsed_time/1000) / qs.execution_count ) - ((qs.total_worker_time/1000) / qs.execution_count) AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, (qs.total_elapsed_time/1000) AS cumulative_elapsed_time_all_executions FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE t.text like '<Your Query>%' -- Replace <Your Query> with your query or the beginning part of your query. The special chars like '[','_','%','^' in the query should be escaped. ORDER BY (qs.total_elapsed_time / qs.execution_count) DESCUwaga 16.
Jeśli
avg_wait_timezostanie wyświetlona wartość ujemna, jest to zapytanie równoległe.Jeśli możesz wykonać zapytanie na żądanie w programie SQL Server Management Studio (SSMS) lub Azure Data Studio, uruchom je przy użyciu funkcji SET STATISTICS TIME
ONi SET STATISTICS IOON.SET STATISTICS TIME ON SET STATISTICS IO ON <YourQuery> SET STATISTICS IO OFF SET STATISTICS TIME OFFNastępnie w obszarze Komunikaty zobaczysz czas procesora CPU, upłynął czas i odczyty logiczne w następujący sposób:
Table 'tblTest'. Scan count 1, logical reads 3, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0. SQL Server Execution Times: CPU time = 460 ms, elapsed time = 470 ms.Jeśli możesz zebrać plan zapytania, sprawdź dane we właściwościach planu wykonania.
Uruchom zapytanie z włączonym uwzględnij rzeczywisty plan wykonania.
Wybierz operator najwięcej po lewej stronie z planu wykonania.
W obszarze Właściwości rozwiń właściwość QueryTimeStats .
Sprawdź czas, który upłynął i czas procesora CPUTime.
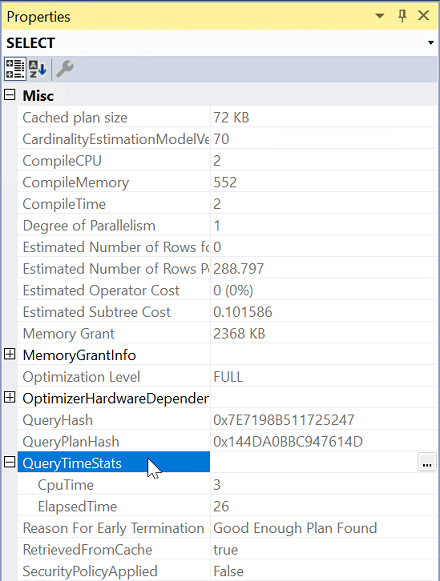
Porównaj czas, który upłynął i czas procesora CPU zapytania, aby określić typ problemu dla obu serwerów.
Typ 1: powiązany z procesorem CPU (moduł uruchamiający)
Jeśli czas procesora CPU jest bliski, równy lub wyższy niż upłynął czas, możesz traktować go jako zapytanie powiązane z procesorem CPU. Jeśli na przykład upłynął czas to 3000 milisekund (ms), a czas procesora WYNOSI 2900 ms, oznacza to, że większość czasu, który upłynął, jest poświęcana na procesor CPU. Następnie możemy powiedzieć, że jest to zapytanie powiązane z procesorem CPU.
Przykłady uruchamiania (powiązanych z procesorem CPU) zapytań:
| Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|
| 3200 | 3000 | 300000 |
| 1080 | 1000 | 20 |
Odczyty logiczne — odczytywanie stron danych/indeksów w pamięci podręcznej — są najczęściej sterownikami wykorzystania procesora CPU w programie SQL Server. Mogą istnieć scenariusze, w których użycie procesora CPU pochodzi z innych źródeł: pętla czasowa (w języku T-SQL lub innym kodzie, np. XProcs lub obiektach listy CRL SQL). Drugi przykład w tabeli ilustruje taki scenariusz, w którym większość procesora CPU nie pochodzi z operacji odczytu.
Uwaga 16.
Jeśli czas procesora CPU jest dłuższy niż czas trwania, oznacza to wykonanie zapytania równoległego; wiele wątków używa procesora CPU w tym samym czasie. Aby uzyskać więcej informacji, zobacz Zapytania równoległe — moduł uruchamiający lub kelner.
Typ 2. Oczekiwanie na wąskie gardło (kelner)
Zapytanie oczekuje na wąskie gardło, jeśli czas, który upłynął, jest znacznie większy niż czas procesora CPU. Czas, który upłynął, obejmuje czas wykonywania zapytania na procesorze CPU (czas procesora) i czas oczekiwania na zwolnienie zasobu (czas oczekiwania). Jeśli na przykład upłynął czas to 2000 ms, a czas procesora WYNOSI 300 ms, czas oczekiwania wynosi 1700 ms (2000 – 300 = 1700). Aby uzyskać więcej informacji, zobacz Typy oczekiwania.
Przykłady oczekujących zapytań:
| Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|
| 2000 | 300 | 28000 |
| 10000 | 700 | 80000 |
Zapytania równoległe — moduł uruchamiający lub kelner
Zapytania równoległe mogą używać więcej czasu procesora CPU niż całkowity czas trwania. Celem równoległości jest umożliwienie jednoczesnego uruchamiania części zapytania przez wiele wątków. W jednej sekundzie zegara zapytanie może używać ośmiu sekund czasu procesora, wykonując osiem równoległych wątków. W związku z tym trudno jest określić związane z procesorem CPU lub oczekujące zapytanie na podstawie czasu, który upłynął i różnica czasu procesora CPU. Jednak zgodnie z ogólną zasadą przestrzegaj zasad wymienionych w dwóch powyższych sekcjach. Podsumowanie to:
- Jeśli czas, który upłynął, jest znacznie większy niż czas procesora CPU, rozważ to kelnera.
- Jeśli czas procesora CPU jest znacznie większy niż czas, który upłynął, rozważ jego moduł uruchamiający.
Przykłady zapytań równoległych:
| Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|
| 1200 | 8100 | 850000 |
| 3080 | 12300 | 1500000 |
Krok 3. Porównanie danych z obu serwerów, ustalenie scenariusza i rozwiązanie problemu
Załóżmy, że istnieją dwie maszyny o nazwach Server1 i Server2. Zapytanie działa wolniej na serwerze Server1 niż w systemie Server2. Porównaj czasy z obu serwerów, a następnie postępuj zgodnie z akcjami scenariusza, które najlepiej pasują do Twoich z poniższych sekcji.
Scenariusz 1: Zapytanie na serwerze Server1 używa więcej czasu procesora CPU, a odczyty logiczne są wyższe na serwerze Server1 niż w systemie Server2
Jeśli czas procesora CPU na serwerze Server1 jest znacznie większy niż na serwerze Server2, a czas, który upłynął, jest ściśle zgodny z czasem procesora CPU na obu serwerach, nie ma głównych oczekiwań ani wąskich gardeł. Wzrost czasu procesora CPU na serwerze Server1 jest najprawdopodobniej spowodowany wzrostem liczby odczytów logicznych. Znacząca zmiana operacji odczytu logicznego zwykle wskazuje różnicę w planach zapytań. Na przykład:
| Serwer | Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|---|
| Serwer1 | 3100 | 3000 | 300000 |
| Serwer2 | 1100 | 1000 | 90200 |
Akcja: Sprawdzanie planów wykonywania i środowisk
- Porównaj plany wykonywania zapytania na obu serwerach. W tym celu użyj jednej z dwóch metod:
- Wizualnie porównaj plany wykonywania. Aby uzyskać więcej informacji, zobacz Wyświetlanie rzeczywistego planu wykonania.
- Zapisz plany wykonywania i porównaj je przy użyciu funkcji porównania planów programu SQL Server Management Studio.
- Porównanie środowisk. Różne środowiska mogą prowadzić do różnic w planie zapytań lub bezpośrednich różnic w użyciu procesora CPU. Środowiska obejmują wersje serwera, ustawienia konfiguracji bazy danych lub serwera, flagi śledzenia, licznik procesora CPU lub szybkość zegara, a maszyna wirtualna a maszyna fizyczna. Aby uzyskać szczegółowe informacje, zobacz Diagnozowanie różnic w planie zapytań .
Scenariusz 2: Zapytanie jest kelnerem na serwerze Server1, ale nie na serwerze Server2
Jeśli czas procesora CPU dla zapytania na obu serwerach jest podobny, ale upłynął czas na serwerze Server1 jest znacznie większy niż na serwerze Server2, zapytanie na serwerze Server1 poświęca znacznie dłuższy czas oczekiwania na wąskie gardło. Na przykład:
| Serwer | Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|---|
| Serwer1 | 4500 | 1000 | 90200 |
| Serwer2 | 1100 | 1000 | 90200 |
- Czas oczekiwania na serwerze 1: 4500 – 1000 = 3500 ms
- Czas oczekiwania na serwerze 2: 1100– 1000 = 100 ms
Akcja: Sprawdzanie typów oczekiwania na serwerze Server1
Zidentyfikuj i zlikwiduj wąskie gardło na serwerze Server1. Przykłady oczekiwania blokują (oczekiwania na blokadę), zatrzaskami, oczekiwaniami we/wy dysku, oczekiwaniami sieciowymi i oczekiwaniami na pamięć. Aby rozwiązać typowe problemy z wąskim gardłem, przejdź do sekcji Diagnozowanie oczekiwań lub wąskich gardeł.
Scenariusz 3. Zapytania na obu serwerach są kelnerami, ale typy oczekiwania lub czasy są różne
Na przykład:
| Serwer | Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|---|
| Serwer1 | 8000 | 1000 | 90200 |
| Serwer2 | 3000 | 1000 | 90200 |
- Czas oczekiwania na serwerze 1: 8000 – 1000 = 7000 ms
- Czas oczekiwania na serwerze 2: 3000– 1000 = 2000 ms
W tym przypadku czasy procesora CPU są podobne na obu serwerach, co oznacza, że plany zapytań są prawdopodobnie takie same. Zapytania będą działać równie na obu serwerach, jeśli nie czekają na wąskie gardła. Dlatego różnice czasu trwania pochodzą z różnych ilości czasu oczekiwania. Na przykład zapytanie czeka na blokady na serwerze Server1 przez 7000 ms podczas oczekiwania na we/wy na serwerze 2000 ms.
Akcja: Sprawdzanie typów oczekiwania na obu serwerach
Rozwiąż każde wąskie gardło czekać indywidualnie na każdym serwerze i przyspieszyć wykonywanie na obu serwerach. Rozwiązywanie tego problemu jest czasochłonne, ponieważ należy wyeliminować wąskie gardła na obu serwerach i zapewnić porównywalną wydajność. Aby rozwiązać typowe problemy z wąskim gardłem, przejdź do sekcji Diagnozowanie oczekiwań lub wąskich gardeł.
Scenariusz 4. Zapytanie na serwerze Server1 używa więcej czasu procesora CPU niż na serwerze Server2, ale operacje odczytu logicznego są zamykane
Na przykład:
| Serwer | Czas upływu (ms) | Czas procesora CPU (ms) | Odczyty (logiczne) |
|---|---|---|---|
| Serwer1 | 3000 | 3000 | 90200 |
| Serwer2 | 1000 | 1000 | 90200 |
Jeśli dane są zgodne z następującymi warunkami:
- Czas procesora CPU na serwerze Server1 jest znacznie większy niż na serwerze Server2.
- Czas, który upłynął, jest ściśle zgodny z czasem procesora CPU na każdym serwerze, co nie wskazuje oczekiwania.
- Odczyty logiczne, zazwyczaj najwyższy sterownik czasu procesora CPU, są podobne na obu serwerach.
Następnie dodatkowy czas procesora CPU pochodzi z innych działań związanych z procesorem CPU. Ten scenariusz jest najrzadszym ze wszystkich scenariuszy.
Przyczyny: śledzenie, funkcje zdefiniowane przez użytkownika i integracja środowiska CLR
Ten problem może być spowodowany przez:
- Śledzenie XEvents/SQL Server, szczególnie w przypadku filtrowania kolumn tekstowych (nazwa bazy danych, nazwa logowania, tekst zapytania itd.). Jeśli śledzenie jest włączone na jednym serwerze, ale nie na drugim, może to być przyczyna różnicy.
- Funkcje zdefiniowane przez użytkownika (UDF) lub inny kod języka T-SQL, który wykonuje operacje związane z procesorem CPU. Zazwyczaj jest to przyczyna, gdy inne warunki są inne na serwerze Server1 i Server2, takie jak rozmiar danych, szybkość zegara procesora CPU lub plan zasilania.
- Integracja środowiska SQL Server CLR lub rozszerzone procedury składowane (XPs), które mogą obsługiwać procesor CPU, ale nie wykonują operacji odczytu logicznego. Różnice w bibliotekach DLL mogą prowadzić do różnych czasów procesora CPU.
- Różnica w funkcjonalności programu SQL Server, która jest powiązana z procesorem CPU (np. kod manipulowania ciągami).
Akcja: Sprawdzanie śladów i zapytań
Sprawdź ślady na obu serwerach, aby uzyskać następujące informacje:
- Jeśli na serwerze Server1 włączono jakiekolwiek ślady, ale nie na serwerze Server2.
- Jeśli jakiekolwiek śledzenie jest włączone, wyłącz śledzenie i uruchom zapytanie ponownie na serwerze Server1.
- Jeśli zapytanie działa szybciej tym razem, włącz śledzenie z powrotem, ale usuń z niego filtry tekstowe, jeśli istnieją.
Sprawdź, czy zapytanie używa zdefiniowanych przez użytkownika funkcji zdefiniowanych przez użytkownika, które wykonują manipulacje ciągami lub wykonują obszerne przetwarzanie w kolumnach danych na
SELECTliście.Sprawdź, czy zapytanie zawiera pętle, rekursje funkcji lub zagnieżdżenia.
Diagnozowanie różnic w środowisku
Sprawdź następujące pytania i ustal, czy porównanie między dwoma serwerami jest prawidłowe.
Czy dwa wystąpienia programu SQL Server są w tej samej wersji lub kompilacji?
Jeśli nie, mogą istnieć pewne poprawki, które spowodowały różnice. Uruchom następujące zapytanie, aby uzyskać informacje o wersji na obu serwerach:
SELECT @@VERSIONCzy ilość pamięci fizycznej jest podobna na obu serwerach?
Jeśli jeden serwer ma 64 GB pamięci, a drugi ma 256 GB pamięci, będzie to znacząca różnica. Dzięki większej ilości pamięci dostępnej do buforowania stron danych/indeksów i planów zapytań zapytanie można zoptymalizować inaczej na podstawie dostępności zasobów sprzętowych.
Czy konfiguracje sprzętowe związane z procesorem CPU są podobne na obu serwerach? Na przykład:
Liczba procesorów CPU różni się między maszynami (24 procesory CPU na jednej maszynie a 96 procesorów CPU w drugiej).
Plany zasilania — zrównoważona i wysoka wydajność.
Maszyna wirtualna a maszyna fizyczna (bez systemu operacyjnego).
Funkcja Hyper-V a program VMware — różnica w konfiguracji.
Różnica szybkości zegara (niższa szybkość zegara w porównaniu z wyższą szybkością zegara). Na przykład 2 GHz a 3,5 GHz może mieć wpływ. Aby uzyskać szybkość zegara na serwerze, uruchom następujące polecenie programu PowerShell:
Get-CimInstance Win32_Processor | Select-Object -Expand MaxClockSpeed
Użyj jednego z następujących dwóch sposobów, aby przetestować szybkość procesora CPU serwerów. Jeśli nie generują porównywalnych wyników, problem znajduje się poza programem SQL Server. Może to być różnica w planie zasilania, mniejsza liczba procesorów CPU, problem z oprogramowaniem maszyn wirtualnych lub różnica szybkości zegara.
Uruchom następujący skrypt programu PowerShell na obu serwerach i porównaj dane wyjściowe.
$bf = [System.DateTime]::Now for ($i = 0; $i -le 20000000; $i++) {} $af = [System.DateTime]::Now Write-Host ($af - $bf).Milliseconds " milliseconds" Write-Host ($af - $bf).Seconds " Seconds"Uruchom następujący kod Języka Transact-SQL na obu serwerach i porównaj dane wyjściowe.
SET NOCOUNT ON DECLARE @spins INT = 0 DECLARE @start_time DATETIME = GETDATE(), @time_millisecond INT WHILE (@spins < 20000000) BEGIN SET @spins = @spins +1 END SELECT @time_millisecond = DATEDIFF(millisecond, @start_time, getdate()) SELECT @spins Spins, @time_millisecond Time_ms, @spins / @time_millisecond Spins_Per_ms
Diagnozowanie oczekiwań lub wąskich gardeł
Aby zoptymalizować zapytanie oczekujące na wąskie gardła, zidentyfikuj czas oczekiwania i miejsce wąskiego gardła (typ oczekiwania). Po potwierdzeniu typu oczekiwania zmniejsz czas oczekiwania lub całkowicie zlikwiduj oczekiwanie.
Aby obliczyć przybliżony czas oczekiwania, odejmij czas procesora CPU (czas procesu roboczego) od czasu, który upłynął w zapytaniu. Zazwyczaj czas procesora CPU to rzeczywisty czas wykonywania, a pozostała część okresu istnienia zapytania oczekuje.
Przykłady obliczania przybliżonego czasu trwania oczekiwania:
| Czas upływu (ms) | Czas procesora CPU (ms) | Czas oczekiwania (ms) |
|---|---|---|
| 3200 | 3000 | 200 |
| 7080 | 1000 | 6080 |
Identyfikowanie wąskiego gardła lub oczekiwania
Aby zidentyfikować historyczne długotrwałe zapytania (na przykład >20% ogólnego czasu oczekiwania, czyli czas oczekiwania), uruchom następujące zapytanie. To zapytanie używa statystyk wydajności dla buforowanych planów zapytań od początku programu SQL Server.
SELECT t.text, qs.total_elapsed_time / qs.execution_count AS avg_elapsed_time, qs.total_worker_time / qs.execution_count AS avg_cpu_time, (qs.total_elapsed_time - qs.total_worker_time) / qs.execution_count AS avg_wait_time, qs.total_logical_reads / qs.execution_count AS avg_logical_reads, qs.total_logical_writes / qs.execution_count AS avg_writes, qs.total_elapsed_time AS cumulative_elapsed_time FROM sys.dm_exec_query_stats qs CROSS apply sys.Dm_exec_sql_text (sql_handle) t WHERE (qs.total_elapsed_time - qs.total_worker_time) / qs.total_elapsed_time > 0.2 ORDER BY qs.total_elapsed_time / qs.execution_count DESCAby zidentyfikować aktualnie wykonywane zapytania z oczekiwaniami dłuższymi niż 500 ms, uruchom następujące zapytanie:
SELECT r.session_id, r.wait_type, r.wait_time AS wait_time_ms FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s ON r.session_id = s.session_id WHERE wait_time > 500 AND is_user_process = 1Jeśli możesz zebrać plan zapytania, sprawdź wartości WaitStats z właściwości planu wykonywania w programie SSMS:
- Uruchom zapytanie z włączonym uwzględnij rzeczywisty plan wykonania .
- Kliknij prawym przyciskiem myszy operator najbardziej po lewej stronie na karcie Plan wykonania
- Wybierz pozycję Właściwości , a następnie właściwość WaitStats .
- Sprawdź wartości WaitTimeMs i WaitType.
Jeśli znasz scenariusze PSSDiag/SQLdiag lub SQL LogScout LightPerf/GeneralPerf, rozważ użycie jednej z nich do zbierania statystyk wydajności i identyfikowania oczekujących zapytań w wystąpieniu programu SQL Server. Zebrane pliki danych można zaimportować i przeanalizować dane wydajności za pomocą narzędzia SQL Nexus.
Odwołania pomagające wyeliminować lub zmniejszyć oczekiwania
Przyczyny i rozwiązania dla każdego typu oczekiwania różnią się. Nie ma jednej ogólnej metody rozpoznawania wszystkich typów oczekiwania. Poniżej przedstawiono artykuły umożliwiające rozwiązywanie typowych problemów z typem oczekiwania:
- Omówienie i rozwiązywanie problemów z blokowaniem (LCK_M_*)
- Omówienie i rozwiązywanie problemów z blokowaniem usługi Azure SQL Database
- Rozwiązywanie problemów z niską wydajnością programu SQL Server spowodowanych problemami we/wy (PAGEIOLATCH_*, WRITELOG, IO_COMPLETION, BACKUPIO)
- Rozwiązywanie problemu ze wstawianiem ostatniej strony PAGELATCH_EX w programie SQL Server
- Pamięć udziela wyjaśnień i rozwiązań (RESOURCE_SEMAPHORE)
- Rozwiązywanie problemów z powolnymi zapytaniami, które wynikają z typu oczekiwania ASYNC_NETWORK_IO
- Rozwiązywanie problemów z wysokim typem oczekiwania HADR_SYNC_COMMIT z zawsze włączonymi grupami dostępności
- Jak to działa: CMEMTHREAD i debugowanie
- Wykonywanie równoległości czeka na działanie (CXPACKET i CXCONSUMER)
- OCZEKIWANIE NA PULĘ WĄTKÓW
Opisy wielu typów oczekiwania i wskazywanych przez nie elementów można znaleźć w tabeli Typy oczekiwania.
Diagnozowanie różnic w planie zapytań
Poniżej przedstawiono niektóre typowe przyczyny różnic w planach zapytań:
Różnice rozmiaru danych lub wartości danych
Czy ta sama baza danych jest używana na obu serwerach — przy użyciu tej samej kopii zapasowej bazy danych? Czy dane zostały zmodyfikowane na jednym serwerze w porównaniu z innymi? Różnice między danymi mogą prowadzić do różnych planów zapytań. Na przykład łączenie tabeli T1 (1000 wierszy) z tabelą T2 (2 000 000 wierszy) różni się od łączenia tabeli T1 (100 wierszy) z tabelą T2 (2 000 000 wierszy). Typ i szybkość
JOINoperacji mogą być znacznie różne.Różnice statystyczne
Czy statystyki zostały zaktualizowane w jednej bazie danych, a nie w drugiej? Czy statystyki zostały zaktualizowane przy użyciu innej częstotliwości próbkowania (na przykład 30% w porównaniu do 100% pełnego skanowania)? Upewnij się, że statystyki są aktualizowane po obu stronach z taką samą częstotliwością próbkowania.
Różnice na poziomie zgodności bazy danych
Sprawdź, czy poziomy zgodności baz danych różnią się między dwoma serwerami. Aby uzyskać poziom zgodności bazy danych, uruchom następujące zapytanie:
SELECT name, compatibility_level FROM sys.databases WHERE name = '<YourDatabase>'Różnice wersji/kompilacji serwera
Czy wersje lub kompilacje programu SQL Server różnią się między dwoma serwerami? Czy na przykład jeden serwer PROGRAMU SQL Server w wersji 2014 i drugi program SQL Server w wersji 2016? Mogą istnieć zmiany produktów, które mogą prowadzić do zmian w sposobie wybierania planu zapytania. Upewnij się, że porównasz tę samą wersję i kompilację programu SQL Server.
SELECT ServerProperty('ProductVersion')Różnice wersji narzędzia do szacowania kardynalności (CE)
Sprawdź, czy starszy narzędzie do szacowania kardynalności jest aktywowane na poziomie bazy danych. Aby uzyskać więcej informacji na temat ce, zobacz Szacowanie kardynalności (SQL Server).
SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'LEGACY_CARDINALITY_ESTIMATION'Poprawki optymalizatora włączone/wyłączone
Jeśli poprawki optymalizatora zapytań są włączone na jednym serwerze, ale wyłączone na drugim, można wygenerować różne plany zapytań. Aby uzyskać więcej informacji, zobacz SQL Server query optimizer hotfix trace flag 4199 servicing model (Flaga śledzenia poprawek programu SQL Server 4199).
Aby uzyskać stan poprawek optymalizatora zapytań, uruchom następujące zapytanie:
-- Check at server level for TF 4199 DBCC TRACESTATUS (-1) -- Check at database level USE <YourDatabase> SELECT name, value, is_value_default FROM sys.database_scoped_configurations WHERE name = 'QUERY_OPTIMIZER_HOTFIXES'Różnice flag śledzenia
Niektóre flagi śledzenia wpływają na wybór planu zapytania. Sprawdź, czy na jednym serwerze są włączone flagi śledzenia, które nie są włączone. Uruchom następujące zapytanie na obu serwerach i porównaj wyniki:
-- Check at server level for trace flags DBCC TRACESTATUS (-1)Różnice sprzętowe (liczba procesorów, rozmiar pamięci)
Aby uzyskać informacje o sprzęcie, uruchom następujące zapytanie:
SELECT cpu_count, physical_memory_kb/1024/1024 PhysicalMemory_GB FROM sys.dm_os_sys_infoRóżnice sprzętowe zgodnie z optymalizatorem zapytań
OptimizerHardwareDependentPropertiesSprawdź plan zapytania i sprawdź, czy różnice sprzętowe są uznawane za istotne dla różnych planów.WITH xmlnamespaces(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan') SELECT txt.text, t.OptHardw.value('@EstimatedAvailableMemoryGrant', 'INT') AS EstimatedAvailableMemoryGrant , t.OptHardw.value('@EstimatedPagesCached', 'INT') AS EstimatedPagesCached, t.OptHardw.value('@EstimatedAvailableDegreeOfParallelism', 'INT') AS EstimatedAvailDegreeOfParallelism, t.OptHardw.value('@MaxCompileMemory', 'INT') AS MaxCompileMemory FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_query_plan(cp.plan_handle) AS qp CROSS APPLY qp.query_plan.nodes('//OptimizerHardwareDependentProperties') AS t(OptHardw) CROSS APPLY sys.dm_exec_sql_text (CP.plan_handle) txt WHERE text Like '%<Part of Your Query>%'Limit czasu optymalizatora
Czy występuje problem z limitem czasu optymalizatora ? Optymalizator zapytań może przestać oceniać opcje planu, jeśli wykonywane zapytanie jest zbyt złożone. Po zatrzymaniu wybiera plan z najniższym kosztem dostępnym w tym czasie. Może to prowadzić do tego, co wydaje się być dowolnym wyborem planu na jednym serwerze, a innym.
OPCJE ZESTAWU
Niektóre opcje ZESTAWU mają wpływ na plan, na przykład SET ARITHABORT. Aby uzyskać więcej informacji, zobacz USTAWIANIE opcji.
Różnice w wskazówkach dotyczących zapytań
Czy jedno zapytanie używa wskazówek dotyczących zapytań, a drugie nie? Sprawdź tekst zapytania ręcznie, aby ustanowić obecność wskazówek dotyczących zapytań.
Plany wrażliwe na parametry (problem z sniffingiem parametru)
Czy testujesz zapytanie przy użyciu dokładnie tych samych wartości parametrów? Jeśli nie, możesz zacząć tam. Czy plan został skompilowany wcześniej na jednym serwerze na podstawie innej wartości parametru? Przetestuj te dwa zapytania przy użyciu wskazówki zapytania RECOMPILE, aby upewnić się, że nie ma ponownego użycia planu. Aby uzyskać więcej informacji, zobacz Badanie i rozwiązywanie problemów z uwzględnieniem parametrów.
Różne opcje bazy danych/ustawienia konfiguracji o określonym zakresie
Czy te same opcje bazy danych lub ustawienia konfiguracji o określonym zakresie są używane na obu serwerach? Niektóre opcje bazy danych mogą mieć wpływ na opcje planu. Na przykład zgodność bazy danych, starsza wersja CE i domyślny ce oraz wąchanie parametrów. Uruchom następujące zapytanie z jednego serwera, aby porównać opcje bazy danych używane na dwóch serwerach:
-- On Server1 add a linked server to Server2 EXEC master.dbo.sp_addlinkedserver @server = N'Server2', @srvproduct=N'SQL Server' -- Run a join between the two servers to compare settings side by side SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value_in_use AS srv1_value_in_use, s2.value_in_use AS srv2_value_in_use, Variance = CASE WHEN ISNULL(s1.value_in_use, '##') != ISNULL(s2.value_in_use,'##') THEN 'Different' ELSE '' END FROM sys.configurations s1 FULL OUTER JOIN [server2].master.sys.configurations s2 ON s1.name = s2.name SELECT s1.name AS srv1_config_name, s2.name AS srv2_config_name, s1.value srv1_value_in_use, s2.value srv2_value_in_use, s1.is_value_default, s2.is_value_default, Variance = CASE WHEN ISNULL(s1.value, '##') != ISNULL(s2.value, '##') THEN 'Different' ELSE '' END FROM sys.database_scoped_configurations s1 FULL OUTER JOIN [server2].master.sys.database_scoped_configurations s2 ON s1.name = s2.namePrzewodniki dotyczące planu
Czy jakiekolwiek przewodniki dotyczące planu są używane dla zapytań na jednym serwerze, ale nie na drugim? Uruchom następujące zapytanie, aby ustanowić różnice:
SELECT * FROM sys.plan_guides