Rozwiązywanie problemów z wolnymi zapytaniami, których dotyczy limit czasu optymalizatora zapytań
Dotyczy: SQL Server
W tym artykule przedstawiono limit czasu optymalizatora, jego wpływ na wydajność zapytań i sposób optymalizacji wydajności.
Co to jest limit czasu optymalizatora?
Program SQL Server używa optymalizatora zapytań opartych na kosztach (QO). Aby uzyskać informacje na temat QO, zobacz Przewodnik po architekturze przetwarzania zapytań. Optymalizator zapytań oparty na kosztach wybiera plan wykonywania zapytań o najniższym koszcie po utworzeniu i ocenieniu wielu planów zapytań. Jednym z celów optymalizatora zapytań programu SQL Server jest poświęcanie rozsądnego czasu na optymalizację zapytań w porównaniu z wykonywaniem zapytań. Optymalizacja zapytania powinna być znacznie szybsza niż ich wykonywanie. Aby osiągnąć ten cel, funkcja QO ma wbudowany próg zadań do rozważenia przed zatrzymanie procesu optymalizacji. Po osiągnięciu progu przed rozważeniu wszystkich możliwych planów funkcja QO osiągnie limit czasu optymalizatora. Zdarzenie limitu czasu optymalizatora jest zgłaszane w planie zapytania jako limit czasu w obszarze Przyczyna wczesnego zakończenia optymalizacji instrukcji. Ważne jest, aby zrozumieć, że ten próg nie jest oparty na zegarze, ale na liczbie możliwości rozważanych przez optymalizator. W bieżących wersjach QO programu SQL Server ponad pół miliona zadań jest rozważanych przed osiągnięciem limitu czasu.
Limit czasu optymalizatora jest przeznaczony dla programu SQL Server, a w wielu przypadkach nie jest to czynnik wpływający na wydajność zapytań. Jednak w niektórych przypadkach wybór planu zapytania SQL może mieć negatywny wpływ na limit czasu optymalizatora, a niższa wydajność zapytań może spowodować. Gdy wystąpią takie problemy, zrozumienie mechanizmu limitu czasu optymalizatora i wpływ złożonych zapytań może pomóc w rozwiązywaniu problemów i zwiększaniu szybkości zapytań.
Wynikiem osiągnięcia progu limitu czasu optymalizatora jest to, że program SQL Server nie rozważał całego zestawu możliwości optymalizacji. Oznacza to, że może przegapić plany, które mogą produkować krótsze czasy wykonywania. Funkcja QO zostanie zatrzymana na progu i rozważy plan zapytania o najmniejszym koszcie, mimo że w tym momencie mogą istnieć lepsze, niewyeksplone opcje. Pamiętaj, że plan wybrany po osiągnięciu limitu czasu optymalizatora może spowodować rozsądny czas wykonywania zapytania. Jednak w niektórych przypadkach wybrany plan może spowodować wykonanie zapytania, które jest nieoptymalne.
Jak wykryć limit czasu optymalizatora?
Oto objawy wskazujące limit czasu optymalizatora:
Złożone zapytanie
Masz złożone zapytanie, które obejmuje wiele sprzężonych tabel (na przykład sprzężone są osiem lub więcej tabel).
Wolne zapytanie
Zapytanie może działać wolno lub wolniej niż działa w innej wersji lub systemie programu SQL Server.
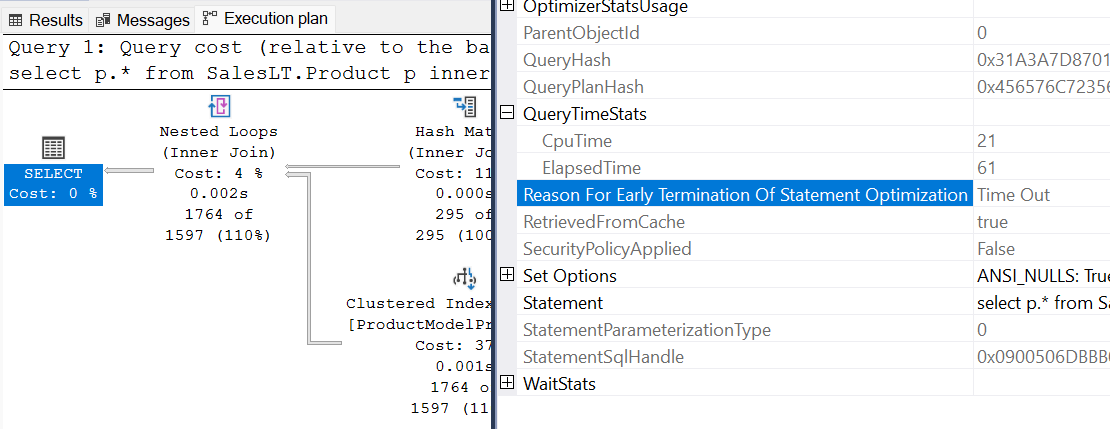
Plan zapytania przedstawia instrukcjęOptmEarlyAbortReason=Timeout
Plan zapytania jest wyświetlany
StatementOptmEarlyAbortReason="TimeOut"w planie zapytania XML.<?xml version="1.0" encoding="utf-16"?> <ShowPlanXML xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" Version="1.518" Build="13.0.5201.2" xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"> <BatchSequence> <Batch> <Statements> <StmtSimple ..." StatementOptmLevel="FULL" StatementOptmEarlyAbortReason="TimeOut" ......> ... <Statements> <Batch> <BatchSequence>Sprawdź właściwości operatora planu po lewej stronie w programie Microsoft SQL Server Management Studio. Zobaczysz wartość Reason For Early Termination of Statement Optimization (Przyczyna wczesnego zakończenia optymalizacji instrukcji ) to TimeOut (Przekroczenie limitu czasu).
Co powoduje przekroczenie limitu czasu optymalizatora?
Nie ma prostego sposobu określenia, jakie warunki mogłyby spowodować osiągnięcie lub przekroczenie progu optymalizatora. W poniższych sekcjach przedstawiono niektóre czynniki wpływające na liczbę planów eksplorowanych przez funkcję QO podczas wyszukiwania najlepszego planu.
W jakiej kolejności należy sprzężć tabele?
Oto przykład opcji wykonywania sprzężeń z trzema tabelami (
Table1,Table2,Table3):- Połącz
Table1z elementemTable2i wynikiem za pomocą poleceniaTable3 - Połącz
Table1z elementemTable3i wynikiem za pomocą poleceniaTable2 - Połącz
Table2z elementemTable3i wynikiem za pomocą poleceniaTable1
Uwaga: Większa jest liczba tabel, tym większe są możliwości.
- Połącz
Jakiej struktury dostępu sterty lub drzewa binarnego (HoBT) używa się do pobierania wierszy z tabeli?
- Indeks klastrowany
- Indeks nieklastrowany1
- Indeks nieklastrowany2
- Sterta tabeli
Jakiej metody dostępu fizycznego użyć?
- Wyszukiwanie indeksu
- Skanowanie indeksu
- Skanowanie tabeli
Jakiego operatora sprzężenia fizycznego używać?
- Sprzężenia zagnieżdżonych pętli (NJ)
- Sprzężenia skrótu (HJ)
- Scalanie sprzężenia (MJ)
- Sprzężenia adaptacyjne (począwszy od programu SQL Server 2017 (14.x))
Aby uzyskać więcej informacji, zobacz Joins (Sprzężenia).
Czy wykonać części zapytania równolegle, czy szeregowo?
Aby uzyskać więcej informacji, zobacz Przetwarzanie zapytań równoległych.
Chociaż następujące czynniki zmniejszają liczbę rozważanych metod dostępu, a tym samym możliwości, które należy uwzględnić:
- Predykaty zapytań (filtry w klauzuli
WHERE) - Istnienie ograniczeń
- Kombinacje dobrze zaprojektowanych i aktualnych statystyk
Uwaga: Fakt, że funkcja QO osiąga próg, nie oznacza, że w końcu będzie działać wolniejsze zapytanie. W większości przypadków zapytanie będzie działać dobrze, ale w niektórych przypadkach może zostać wyświetlone wolniejsze wykonanie zapytania.
Przykład sposobu, w jaki czynniki są brane pod uwagę
Aby zilustrować, weźmy przykład sprzężenia między trzema tabelami (t1, t2, i t3), a każda tabela ma indeks klastrowany i indeks nieklastrowany.
Najpierw rozważ typy sprzężenia fizycznego. W tym miejscu zaangażowane są dwa sprzężenia. Ponieważ istnieją trzy możliwości sprzężenia fizycznego (NJ, HJ i MJ), zapytanie można wykonać na 32 = 9 sposobów.
- NJ — NJ
- NJ — HJ
- NJ — MJ
- HJ — NJ
- HJ — HJ
- HJ — MJ
- MJ — NJ
- MJ — HJ
- MJ — MJ
Następnie rozważ kolejność sprzężenia, która jest obliczana przy użyciu permutacji: P (n, r). Kolejność pierwszych dwóch tabel nie ma znaczenia, więc może istnieć wartość P(3,1) = 3 możliwości:
- Dołącz do
t1polecenia , a następnie za pomocą poleceniat2t3 - Dołącz do
t1polecenia , a następnie za pomocą poleceniat3t2 - Dołącz do
t2polecenia , a następnie za pomocą poleceniat3t1
Następnie rozważ klastrowane i nieklastrowane indeksy, których można użyć do pobierania danych. Ponadto dla każdego indeksu mamy dwie metody dostępu, wyszukiwanie lub skanowanie. Oznacza to, że dla każdej tabeli istnieje 2 2 = 4 opcje. Mamy trzy tabele, więc może istnieć 43 = 64 opcje.
Wreszcie, biorąc pod uwagę wszystkie te warunki, może istnieć 9*3*64 = 1728 możliwych planów.
Teraz załóżmy, że w zapytaniu jest dołączonych n tabel, a każda tabela ma indeks klastrowany i indeks nieklastrowany. Rozważmy następujący czynniki:
- Zamówienia sprzężenia: P(n,n-2) = n!/2
- Typy sprzężenia: 3n-1
- Różne typy indeksów z metodami wyszukiwania i skanowania: 4n
Pomnóż wszystkie powyższe i możemy uzyskać liczbę możliwych planów: 2*n!*12n-1. Gdy n = 4, liczba wynosi 82 944. Gdy n = 6, liczba to 358 318 080. Dlatego wraz ze wzrostem liczby tabel zaangażowanych w zapytanie liczba możliwych planów zwiększa się geometrycznie. Ponadto, jeśli uwzględnisz możliwość równoległości i innych czynników, możesz sobie wyobrazić, ile możliwych planów będzie rozważanych. W związku z tym zapytanie z dużą liczbą sprzężeń jest bardziej prawdopodobne, aby osiągnąć próg limitu czasu optymalizatora niż jedno z mniejszą liczbą sprzężeń.
Należy pamiętać, że powyższe obliczenia ilustrują najgorszy scenariusz. Jak podkreśliliśmy, istnieją czynniki, które zmniejszają liczbę możliwości, takich jak predykaty filtrów, statystyki i ograniczenia. Na przykład predykat filtru i zaktualizowane statystyki zmniejszy liczbę metod dostępu fizycznego, ponieważ użycie indeksu wyszukiwania może być bardziej wydajne niż skanowanie. Doprowadzi to również do mniejszego wyboru sprzężeń itd.
Dlaczego widzę limit czasu optymalizatora z prostym zapytaniem?
Nic z optymalizatorem zapytań jest proste. Istnieje wiele możliwych scenariuszy, a stopień złożoności jest tak wysoki, że trudno zrozumieć wszystkie możliwości. Optymalizator zapytań może dynamicznie ustawić próg limitu czasu na podstawie kosztu planu znalezionego na określonym etapie. Jeśli na przykład zostanie znaleziony plan, który wydaje się stosunkowo wydajny, limit zadań do wyszukiwania lepszego planu może zostać zmniejszony. W związku z tym niedoceniane szacowanie kardynalności (CE) może być jednym ze scenariuszy wczesnego osiągnięcia limitu czasu optymalizatora. W tym przypadku przedmiotem dochodzenia jest CE. Jest to rzadszy przypadek w porównaniu ze scenariuszem dotyczącym uruchamiania złożonego zapytania omówionego w poprzedniej sekcji, ale jest to możliwe.
Rozwiązania
Limit czasu optymalizatora wyświetlany w planie zapytania niekoniecznie oznacza, że jest to przyczyna niskiej wydajności zapytań. W większości przypadków może nie być konieczne wykonanie żadnych czynności związanych z tą sytuacją. Plan zapytania, z którym kończy się program SQL Server, może być rozsądny, a uruchomione zapytanie może działać prawidłowo. Być może nigdy nie wiesz, że napotkano limit czasu optymalizatora.
Spróbuj wykonać poniższe kroki, jeśli okaże się, że konieczne jest dostrojenie i zoptymalizowanie.
Krok 1. Ustanowienie punktu odniesienia
Sprawdź, czy możesz wykonać to samo zapytanie z tym samym zestawem danych w innej kompilacji programu SQL Server, przy użyciu innej konfiguracji CE lub w innym systemie (specyfikacje sprzętowe). Wiodącą zasadą dostrajania wydajności jest "nie ma problemu z wydajnością bez planu bazowego". W związku z tym ważne byłoby ustanowienie punktu odniesienia dla tego samego zapytania.
Krok 2. Wyszukiwanie warunków "ukrytych", które prowadzą do przekroczenia limitu czasu optymalizatora
Sprawdź szczegółowo zapytanie, aby określić jego złożoność. Po wstępnym zbadaniu może nie być oczywiste, że zapytanie jest złożone i obejmuje wiele sprzężeń. Typowym scenariuszem jest to, że są zaangażowane widoki lub funkcje wartości tabeli. Na przykład na powierzchni zapytanie może wydawać się proste, ponieważ łączy dwa widoki. Jednak podczas badania zapytań wewnątrz widoków może się okazać, że każdy widok łączy siedem tabel. W rezultacie po sprzężeniu dwóch widoków zostanie sprzężone 14-tabeli. Jeśli zapytanie używa następujących obiektów, przejdź do szczegółów każdego obiektu, aby zobaczyć, jak wyglądają zapytania bazowe wewnątrz tego obiektu:
- Widoki
- Funkcje wartości tabeli (TFV)
- Podzapytania lub tabele pochodne
- Typowe wyrażenia tabeli (CTE)
- Operatory UNION
W przypadku wszystkich tych scenariuszy najczęstszym rozwiązaniem byłoby ponowne przepisanie zapytania i podzielenie go na wiele zapytań. Zobacz Krok 7. Uściślij zapytanie , aby uzyskać więcej informacji.
Podzapytania lub tabele pochodne
Poniższe zapytanie jest przykładem, który łączy dwa oddzielne zestawy zapytań (tabel pochodnych) z 4-5 sprzężeniami w każdym z nich. Jednak po przeanalizowaniu przez program SQL Server zostanie on skompilowany w pojedyncze zapytanie z ośmioma tabelami sprzężonym.
SELECT ...
FROM
( SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
) AS derived_table1
INNER JOIN
( SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
) AS derived_table2
ON derived_table1.Co1 = derived_table2.Co10
AND derived_table1.Co2 = derived_table2.Co20
Typowe wyrażenia tabeli (CTE)
Używanie wielu typowych wyrażeń tabeli (CTE) nie jest odpowiednim rozwiązaniem, które upraszcza zapytanie i pozwala uniknąć przekroczenia limitu czasu optymalizatora. Wiele wartości CTE zwiększy tylko złożoność zapytania. W związku z tym jest to sprzeczne z produktem do użycia wartości CTE podczas rozwiązywania limitów czasu optymalizatora. Logicznie wyglądają na podział zapytań, ale zostaną one połączone w pojedyncze zapytanie i zoptymalizowane jako pojedyncze duże sprzężenie tabel.
Oto przykład CTE, który zostanie skompilowany jako pojedyncze zapytanie z wieloma sprzężeniami. Może się wydawać, że zapytanie względem my_cte jest sprzężenia prostego dwudysłowego, ale w rzeczywistości istnieje siedem innych tabel połączonych w CTE.
WITH my_cte AS (
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
WHERE ... )
SELECT ...
FROM my_cte
JOIN t8 ON ...
Widoki
Upewnij się, że zostały sprawdzone definicje widoków i wszystkie zaangażowane tabele. Podobnie jak w przypadku wartości CTE i tabel pochodnych, sprzężenia mogą być ukryte wewnątrz widoków. Na przykład sprzężenia między dwoma widokami mogą być ostatecznie pojedynczym zapytaniem z ośmioma zaangażowanymi tabelami:
CREATE VIEW V1 AS
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE VIEW V2 AS
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM V1
JOIN V2 ON ...
Funkcje wartości tabeli (TVFs)
Niektóre sprzężenia mogą być ukryte wewnątrz serwerów TFV. W poniższym przykładzie pokazano, co jest wyświetlane jako sprzężenia między dwoma serwerami TFV, a tabela może być sprzężenia z dziewięcioma tabelami.
CREATE FUNCTION tvf1() RETURNS TABLE
AS RETURN
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
WHERE ...
GO
CREATE FUNCTION tvf2() RETURNS TABLE
AS RETURN
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
WHERE ...
GO
SELECT ...
FROM tvf1()
JOIN tvf2() ON ...
JOIN t9 ON ...
Unia
Operatory unii łączą wyniki wielu zapytań w jeden zestaw wyników. Łączą one również wiele zapytań w jedno zapytanie. Następnie może zostać wyświetlone pojedyncze, złożone zapytanie. W poniższym przykładzie zostanie wyświetlony pojedynczy plan zapytania obejmujący 12 tabel.
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
UNION ALL
SELECT ...
FROM t5
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
UNION ALL
SELECT ...
FROM t9
JOIN t10 ON ...
JOIN t11 ON ...
JOIN t12 ON ...
Krok 3. Jeśli masz zapytanie bazowe, które działa szybciej, użyj planu zapytania
Jeśli ustalisz, że określony plan odniesienia uzyskany z kroku 1 jest lepszy dla zapytania za pośrednictwem testowania, użyj jednej z następujących opcji, aby wymusić wybranie tego planu:
- Procedura składowana magazynu zapytań (QDS)
- Wskazówka dotycząca zapytania: OPCJA (UŻYJ PLANU N'XML_Plan<>')
- Przewodniki dotyczące planu
Krok 4. Zmniejszenie opcji planów
Aby zmniejszyć prawdopodobieństwo przekroczenia limitu czasu optymalizatora, spróbuj zmniejszyć możliwości, które należy wziąć pod uwagę podczas wybierania planu. Ten proces obejmuje testowanie zapytania przy użyciu różnych opcji wskazówek. Podobnie jak w przypadku większości decyzji dotyczących QO, wybory nie zawsze są deterministyczne na powierzchni, ponieważ należy wziąć pod uwagę wiele różnych czynników. W związku z tym nie ma jednej gwarantowanej strategii pomyślnej, a wybrany plan może poprawić lub zmniejszyć wydajność wybranego zapytania.
Wymuszanie zamówienia JOIN
Użyj OPTION (FORCE ORDER) polecenia , aby wyeliminować permutacje zamówień:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
OPTION (FORCE ORDER)
Zmniejszanie możliwości JOIN
Jeśli inne alternatywy nie pomogły, spróbuj zmniejszyć kombinacje planu zapytania, ograniczając opcje operatorów sprzężeń fizycznych z wskazówkami sprzężenia. Na przykład: OPTION (HASH JOIN, MERGE JOIN), OPTION (HASH JOIN, LOOP JOIN) lub OPTION (MERGE JOIN).
Uwaga: podczas korzystania z tych wskazówek należy zachować ostrożność.
W niektórych przypadkach ograniczenie optymalizatora z mniejszą liczbą opcji sprzężenia może spowodować, że najlepsza opcja sprzężenia nie będzie dostępna i może rzeczywiście spowolnić zapytanie. Ponadto w niektórych przypadkach określone sprzężenie jest wymagane przez optymalizator (na przykład cel wiersza), a zapytanie może nie wygenerować planu, jeśli to sprzężenie nie jest opcją. W związku z tym po wybraniu wskazówek sprzężenia dla określonego zapytania sprawdź, czy znajdziesz kombinację, która oferuje lepszą wydajność i eliminuje limit czasu optymalizatora.
Oto dwa przykłady używania takich wskazówek:
Użyj
OPTION (HASH JOIN, LOOP JOIN)polecenia , aby zezwolić tylko na sprzężenia skrótów i pętli oraz uniknąć sprzężenia scalania w zapytaniu:SELECT ... FROM t1 JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ... OPTION (HASH JOIN, LOOP JOIN)Wymuszanie określonego sprzężenia między dwiema tabelami:
SELECT ... FROM t1 INNER MERGE JOIN t2 ON ... JOIN t3 ON ... JOIN t4 ON ... JOIN t5 ON ...
Krok 5. Zmiana konfiguracji CE
Spróbuj zmienić konfigurację CE, przełączając się między legacy CE i New CE. Zmiana konfiguracji CE może spowodować wybranie innej ścieżki podczas oceniania i tworzenia planów zapytań przez program SQL Server. Tak więc, nawet jeśli wystąpi problem z limitem czasu optymalizatora, możliwe, że skończysz z planem, który wykonuje bardziej optymalnie niż wybrany przy użyciu alternatywnej konfiguracji CE. Aby uzyskać więcej informacji, zobacz Jak aktywować najlepszy plan zapytania (szacowanie kardynalności).
Krok 6. Włączanie poprawek optymalizatora
Jeśli nie włączono poprawek optymalizatora zapytań, rozważ ich włączenie przy użyciu jednej z następujących dwóch metod:
- Poziom serwera: użyj flagi śledzenia T4199.
- Poziom bazy danych: użyj
ALTER DATABASE SCOPED CONFIGURATION ..QUERY_OPTIMIZER_HOTFIXES = ONlub zmień poziomy zgodności bazy danych dla programu SQL Server 2016 i nowszych wersji.
Poprawki QO mogą spowodować, że optymalizator podejmie inną ścieżkę w eksploracji planu. W związku z tym może wybrać bardziej optymalny plan zapytania. Aby uzyskać więcej informacji, zobacz SQL Server query optimizer hotfix trace flag 4199 servicing model (Flaga śledzenia poprawek programu SQL Server 4199).
Krok 7. Uściślij zapytanie
Rozważ podzielenie pojedynczego zapytania z wieloma tabelami na wiele oddzielnych zapytań przy użyciu tabel tymczasowych. Podzielenie zapytania to tylko jeden ze sposobów uproszczenia zadania optymalizatora. Zobacz poniższy przykład:
SELECT ...
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...
Aby zoptymalizować zapytanie, spróbuj podzielić pojedyncze zapytanie na dwa zapytania, wstawiając część wyników sprzężenia w tabeli tymczasowej:
SELECT ...
INTO #temp1
FROM t1
JOIN t2 ON ...
JOIN t3 ON ...
JOIN t4 ON ...
GO
SELECT ...
FROM #temp1
JOIN t5 ON ...
JOIN t6 ON ...
JOIN t7 ON ...
JOIN t8 ON ...