Pozyskiwanie i przekształcanie danych w czasie rzeczywistym
Strumienie zdarzeń w usłudze Microsoft Fabric służą do przechwytywania, przekształcania i ładowania danych w czasie rzeczywistym z szerokiej gamy źródeł danych przesyłanych strumieniowo. Podczas konfigurowania strumienia zdarzeń w systemie definiuje się aparat przetwarzania danych, który jest uruchamiany w sposób ciągły w celu pozyskiwania i przekształcania danych w czasie rzeczywistym. Informujesz, skąd mają być pobierane dane, skąd mają być wysyłane, oraz jak zmienić je w razie potrzeby.
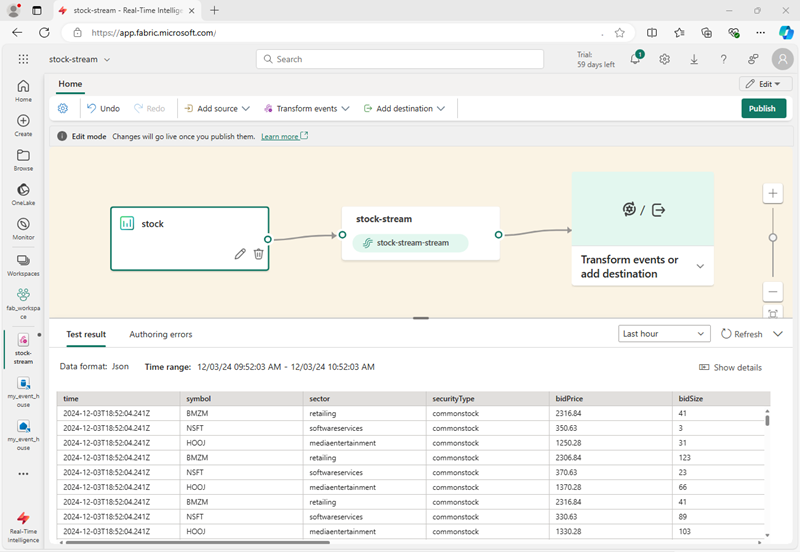
Źródła danych dla strumieni zdarzeń
Strumienie zdarzeń w usłudze Microsoft Fabric obsługują szeroką gamę źródeł danych, w tym:
- Usługi zewnętrzne, takie jak Azure Storage, Azure Event Hubs, Azure IoT Hubs, Apache Kafka Hubs, Zestawienia przechwytywania zmian danych (CDC) w usługach relacyjnej bazy danych i innych.
- Zdarzenia sieci szkieletowej, takie jak zmiany elementów w obszarze roboczym sieć szkieletowa, zmiany danych w magazynach danych usługi OneLake i zdarzenia skojarzone z zadaniami sieci szkieletowej.
- Przykładowe dane, które obejmują szereg przykładów, które mogą ułatwić eksplorowanie scenariuszy analizy w czasie rzeczywistym w usłudze Microsoft Fabric.
Napiwek
Aby uzyskać więcej informacji na temat obsługiwanych źródeł, zobacz Obsługiwane źródła dla centrum w czasie rzeczywistym sieci szkieletowej.
Przekształcenia danych w strumieniach zdarzeń
Dane można przekształcić w miarę ich przepływu w strumieniu zdarzeń, umożliwiając filtrowanie, podsumowywanie i przekształcanie ich przed ich zapisaniem. Dostępne przekształcenia obejmują:
- Filtr: użyj przekształcenia Filtr, aby filtrować zdarzenia na podstawie wartości pola w danych wejściowych. W zależności od typu danych (liczby lub tekstu) przekształcenie zachowuje wartości zgodne z wybranym warunkiem, na przykład is
nulllubis not null. - Zarządzanie polami: ta transformacja umożliwia dodawanie, usuwanie, zmienianie typu danych lub zmienianie nazw pól przychodzących z danych wejściowych lub innej transformacji.
- Agregacja: użyj przekształcenia Agregacja, aby obliczyć agregację (Suma, Minimum, Maksimum lub Średnia) za każdym razem, gdy nowe zdarzenie występuje w danym okresie. Ta operacja umożliwia również zmianę nazw tych kolumn obliczeniowych oraz filtrowanie lub fragmentowanie agregacji na podstawie innych wymiarów w danych. W tej samej transformacji można mieć co najmniej jedną agregację.
- Grupuj według: użyj przekształcenia Grupuj według, aby obliczyć agregacje we wszystkich zdarzeniach w określonym przedziale czasu. Można grupować według wartości w co najmniej jednym polu. Jest to podobne do przekształcenia Agregacja umożliwia zmianę nazw kolumn, ale udostępnia więcej opcji agregacji i zawiera bardziej złożone opcje dla okien czasowych. Podobnie jak agregacja, można dodać więcej niż jedną agregację na transformację.
- Unia: użyj przekształcenia Unii, aby połączyć co najmniej dwa węzły i dodać zdarzenia z polami udostępnionymi (o tej samej nazwie i typie danych) do jednej tabeli. Pola, które nie są zgodne, są porzucane i nie są uwzględniane w danych wyjściowych.
- Rozwiń: użyj tego przekształcenia tablicy, aby utworzyć nowy wiersz dla każdej wartości w tablicy.
- Sprzężenie: jest to przekształcenie w celu połączenia danych z dwóch strumieni na podstawie zgodnego warunku między nimi.
Napiwek
Aby uzyskać więcej informacji na temat obsługiwanych przekształceń, zobacz Przetwarzanie danych zdarzeń za pomocą edytora procesora zdarzeń.
Miejsca docelowe danych w strumieniach zdarzeń
Dane ze strumienia można załadować do następujących miejsc docelowych:
- Eventhouse: To miejsce docelowe umożliwia pozyskiwanie danych zdarzeń w czasie rzeczywistym do magazynu zdarzeń, w którym można użyć język zapytań Kusto (KQL) do wykonywania zapytań i analizowania danych.
- Lakehouse: To miejsce docelowe zapewnia możliwość przekształcania zdarzeń w czasie rzeczywistym przed pozyskiwaniem ich do jeziora. Zdarzenia w czasie rzeczywistym są konwertowane na format usługi Delta Lake, a następnie przechowują je w wyznaczonych tabelach lakehouse.
- Strumień pochodny: strumień pochodny służy do przekierowywania danych wyjściowych strumienia zdarzeń do innego strumienia zdarzeń. Strumień pochodny reprezentuje przekształcony domyślny strumień po przetwarzaniu strumienia.
- Aktywacja sieci szkieletowej: to miejsce docelowe umożliwia bezpośrednie połączenie danych zdarzeń w czasie rzeczywistym z aktywatorem sieci szkieletowej, który jest inteligentnym agentem, który może automatyzować akcje na podstawie wartości w strumieniu.
- Niestandardowy punkt końcowy: za pomocą tego miejsca docelowego można kierować zdarzenia w czasie rzeczywistym do niestandardowego punktu końcowego. To miejsce docelowe jest przydatne, gdy chcesz kierować dane w czasie rzeczywistym do systemu zewnętrznego lub niestandardowej aplikacji poza usługą Microsoft Fabric.
Napiwek
Aby uzyskać więcej informacji na temat obsługiwanych źródeł, zobacz Dodawanie miejsca docelowego i zarządzanie nim w strumieniu zdarzeń.