Niestandardowa umiejętność klasyfikacji tekstu
Niestandardowa klasyfikacja tekstu umożliwia mapowanie fragmentu tekstu na różne klasy zdefiniowane przez użytkownika. Można na przykład wytrenować model na tylnej okładce książek, aby automatycznie zidentyfikować gatunek książek. Następnie używasz tego zidentyfikowanego gatunku, aby wzbogacić wyszukiwarkę sklepu internetowego o aspekt gatunku.
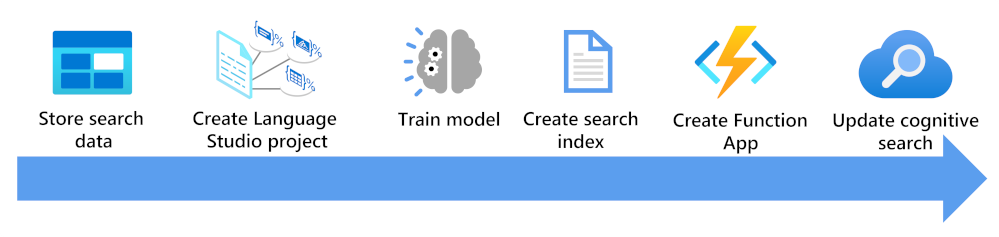
W tym miejscu zobaczysz, co należy wziąć pod uwagę, aby wzbogacić indeks wyszukiwania przy użyciu niestandardowego modelu klasyfikacji tekstu:
- Przechowuj dokumenty, aby można było uzyskiwać do nich dostęp za pomocą programu Language Studio i indeksatorów usługi Azure AI Search.
- Utwórz niestandardowy projekt klasyfikacji tekstu.
- Trenowanie i testowanie modelu.
- Utwórz indeks wyszukiwania na podstawie przechowywanych dokumentów.
- Utwórz aplikację funkcji korzystającą z wdrożonego wytrenowanego modelu.
- Zaktualizuj rozwiązanie wyszukiwania, indeks, indeksator i niestandardowy zestaw umiejętności.
Przechowywanie danych
Dostęp do usługi Azure Blob Storage można uzyskać zarówno z poziomu programu Language Studio, jak i usług Azure AI Services. Kontener musi być dostępny, więc najprostszą opcją jest wybranie pozycji Kontener, ale istnieje również możliwość używania kontenerów prywatnych z dodatkową konfiguracją.
Oprócz danych potrzebny jest również sposób przypisywania klasyfikacji dla każdego dokumentu. Program Language Studio udostępnia graficzne narzędzie, którego można użyć do klasyfikowania każdego dokumentu pojedynczo.
Można wybrać między dwoma różnymi typami projektu. Jeśli dokument jest mapowy na pojedynczą klasę, użyj projektu klasyfikacji pojedynczej etykiety. Jeśli chcesz zamapować dokument na więcej niż jedną klasę, użyj projektu klasyfikacji wielu etykiet.
Jeśli nie chcesz ręcznie klasyfikować każdego dokumentu, możesz oznaczyć wszystkie dokumenty przed utworzeniem projektu usługi Azure AI Language. Ten proces obejmuje utworzenie dokumentu JSON etykiet w tym formacie:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
Do tablicy należy dodać dowolną classes liczbę klas. Należy dodać wpis dla każdego dokumentu w tablicy, documents w tym klasy zgodne z dokumentem.
Tworzenie projektu języka sztucznej inteligencji platformy Azure
Istnieją dwa sposoby tworzenia projektu języka sztucznej inteligencji platformy Azure. Jeśli zaczniesz używać programu Language Studio bez uprzedniego utworzenia usługi językowej w witrynie Azure Portal, program Language Studio zaoferuje utworzenie tej usługi.
Najbardziej elastycznym sposobem utworzenia projektu języka sztucznej inteligencji platformy Azure jest najpierw utworzenie usługi językowej przy użyciu witryny Azure Portal. Jeśli wybierzesz tę opcję, uzyskasz opcję dodawania funkcji niestandardowych.
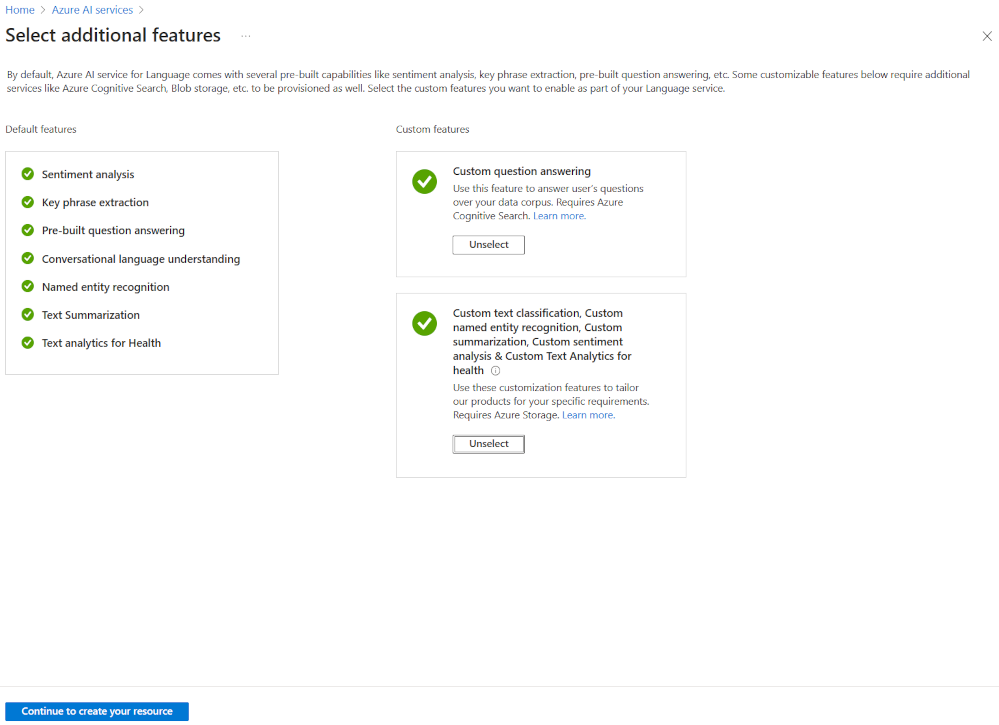
Podczas tworzenia niestandardowej klasyfikacji tekstu wybierz tę funkcję niestandardową podczas tworzenia usługi językowej. Połączysz również usługę językową z kontem magazynu przy użyciu tej metody.
Po wdrożeniu zasobu możesz przejść bezpośrednio do programu Language Studio w okienku przeglądu usługi językowej. Następnie można utworzyć nowy niestandardowy projekt klasyfikacji tekstu.
Uwaga
Jeśli usługa językowa została utworzona z poziomu programu Language Studio, może być konieczne wykonanie tych kroków. Ustaw role dla zasobu języka platformy Azure i konta magazynu, aby połączyć kontener magazynu z niestandardowym projektem klasyfikacji tekstu.
Trenowanie modelu klasyfikacji
Podobnie jak we wszystkich modelach sztucznej inteligencji, musisz zidentyfikować dane, których można użyć do trenowania. Model musi zobaczyć przykłady mapowania danych na klasę i kilka przykładów, których może użyć do przetestowania modelu. Możesz zezwolić modelowi na automatyczne podzielenie danych treningowych. Domyślnie użyje ona 80% dokumentów do wytrenowania modelu i 20% do ślepego testowania. Jeśli masz określone dokumenty, za pomocą których chcesz przetestować model, możesz oznaczyć dokumenty na potrzeby testowania.

W programie Language Studio w projekcie wybierz pozycję Etykietowanie danych. Zobaczysz wszystkie dokumenty. Wybierz każdy dokument, który chcesz dodać do zestawu testów, a następnie wybierz pozycję Testowanie wydajności modelu. Zapisz zaktualizowane etykiety, a następnie utwórz nowe zadanie szkoleniowe.
Tworzenie indeksu wyszukiwania
Nie ma niczego konkretnego, co należy zrobić, aby utworzyć indeks wyszukiwania, który zostanie wzbogacony przez niestandardowy model klasyfikacji tekstu. Wykonaj kroki opisane w temacie Tworzenie rozwiązania azure AI Search. Po utworzeniu aplikacji funkcji zaktualizujesz indeks, indeksator i umiejętności niestandardowe.
Tworzenie aplikacji funkcji platformy Azure
Możesz wybrać język i technologie, które mają być używane w aplikacji funkcji. Aplikacja musi mieć możliwość przekazania kodu JSON do niestandardowego punktu końcowego klasyfikacji tekstu, na przykład:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
Następnie przetwórz odpowiedź JSON z modelu, na przykład:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
Następnie funkcja zwraca ustrukturyzowany komunikat JSON z powrotem do niestandardowego zestawu umiejętności w wyszukiwaniu sztucznej inteligencji, na przykład:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
Aplikacja funkcji musi wiedzieć o pięciu elementach:
- Tekst do sklasyfikowania.
- Punkt końcowy dla wytrenowanej niestandardowej klasyfikacji tekstu wdrożonego modelu.
- Klucz podstawowy projektu niestandardowej klasyfikacji tekstu.
- Nazwa projektu.
- Nazwa wdrożenia.
Tekst, który ma zostać sklasyfikowany, jest przekazywany z niestandardowego zestawu umiejętności w usłudze AI Search do funkcji jako danych wejściowych. Pozostałe cztery elementy można znaleźć w programie Language Studio.

Nazwa punktu końcowego i wdrożenia znajduje się w okienku wdrażania modelu.

Nazwa projektu i klucz podstawowy znajdują się w okienku ustawień projektu.
Aktualizowanie rozwiązania azure AI Search
W witrynie Azure Portal należy wprowadzić trzy zmiany, aby wzbogacić indeks wyszukiwania:
- Musisz dodać pole do indeksu, aby przechowywać niestandardowe wzbogacanie klasyfikacji tekstu.
- Musisz dodać niestandardowy zestaw umiejętności, aby wywołać aplikację funkcji przy użyciu tekstu, który ma zostać sklasyfikowany.
- Musisz zamapować odpowiedź z zestawu umiejętności na indeks.
Dodawanie pola do istniejącego indeksu
W witrynie Azure Portal przejdź do zasobu wyszukiwania sztucznej inteligencji, wybierz indeks i dodasz kod JSON w następującym formacie:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
Ten kod JSON dodaje pole złożone do indeksu w celu przechowywania klasy w category polu, które można przeszukiwać. Drugie confidenceScore pole przechowuje procent ufności w podwójnym polu.
Edytowanie niestandardowego zestawu umiejętności
W witrynie Azure Portal wybierz zestaw umiejętności i dodaj kod JSON w następującym formacie:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
Ta WebApiSill definicja umiejętności określa, że język i zawartość dokumentu są przekazywane jako dane wejściowe do aplikacji funkcji. Aplikacja zwróci tekst JSON o nazwie class.
Mapowanie danych wyjściowych z aplikacji funkcji na indeks
Ostatnia zmiana polega na mapowanie danych wyjściowych na indeks. W witrynie Azure Portal wybierz indeksator i edytuj kod JSON, aby mieć nowe mapowanie danych wyjściowych:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
Indeksator wie teraz, że dane wyjściowe z aplikacji document/class funkcji powinny być przechowywane w classifiedtext polu. Ponieważ zostało to zdefiniowane jako pole złożone, aplikacja funkcji musi zwrócić tablicę JSON zawierającą category pole i confidenceScore .
Teraz możesz wyszukać wzbogacony indeks wyszukiwania dla niestandardowego tekstu sklasyfikowanego.