Skorzystaj z tego artykułu, aby dowiedzieć się, jak skonfigurować wymagania dotyczące rozpoczynania od niestandardowej klasyfikacji tekstu i tworzenia projektu.
Wymagania wstępne
Przed rozpoczęciem korzystania z niestandardowej klasyfikacji tekstu potrzebne będą następujące elementy:
Tworzenie zasobu języka
Przed rozpoczęciem korzystania z niestandardowej klasyfikacji tekstu potrzebny będzie zasób języka sztucznej inteligencji platformy Azure. Zaleca się utworzenie zasobu language i połączenie z nim konta magazynu w witrynie Azure Portal. Utworzenie zasobu w witrynie Azure Portal umożliwia jednoczesne utworzenie konta usługi Azure Storage ze wszystkimi wymaganymi uprawnieniami wstępnie skonfigurowanymi. Możesz również przeczytać więcej w artykule, aby dowiedzieć się, jak używać istniejącego zasobu i skonfigurować go do pracy z niestandardową klasyfikacją tekstu.
Potrzebne będzie również konto usługi Azure Storage, na którym zostaną przekazane .txt dokumenty, które będą używane do trenowania modelu do klasyfikowania tekstu.
Uwaga
- Aby utworzyć zasób języka, musisz mieć przypisaną rolę właściciela w grupie zasobów.
- Jeśli połączysz istniejące wcześniej konto magazynu, musisz mieć przypisaną rolę właściciela .
Tworzenie zasobu języka i łączenie konta magazynu
Uwaga
Nie należy przenosić konta magazynu do innej grupy zasobów lub subskrypcji po połączeniu z zasobem Language.
Tworzenie nowego zasobu w witrynie Azure Portal
Przejdź do witryny Azure Portal, aby utworzyć nowy zasób języka sztucznej inteligencji platformy Azure.
W wyświetlonym oknie wybierz pozycję Niestandardowa klasyfikacja tekstu i niestandardowe rozpoznawanie nazwanych jednostek z funkcji niestandardowych. Wybierz pozycję Kontynuuj, aby utworzyć zasób w dolnej części ekranu.
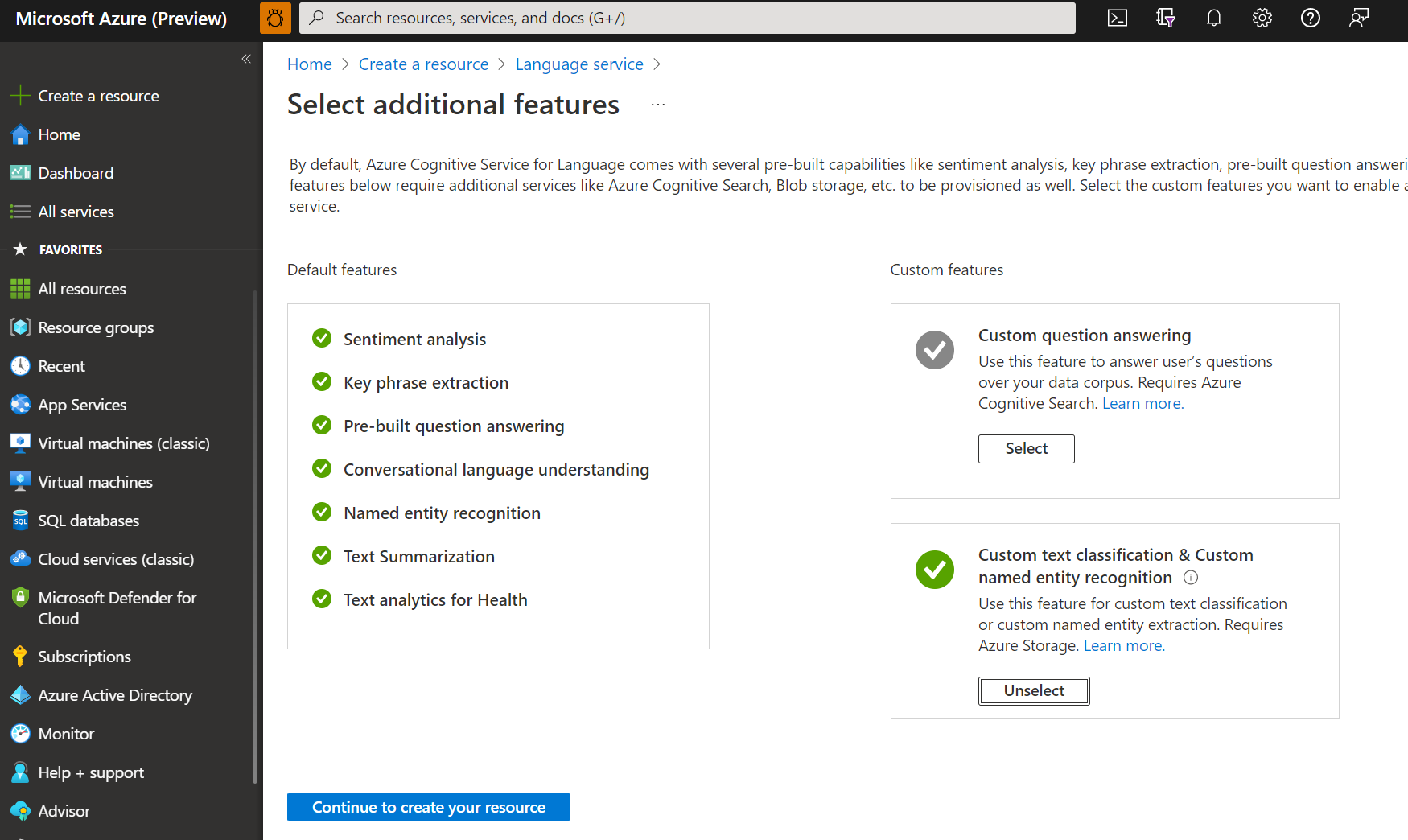
Utwórz zasób języka, postępując zgodnie z poniższymi szczegółami.
| Nazwisko |
Wartość wymagana |
| Subskrypcja |
Swoją subskrypcję platformy Azure. |
| Grupa zasobów |
Grupa zasobów, która będzie zawierać zasób. Możesz użyć istniejącej lub utworzyć nową. |
| Region (Region) |
Jeden z obsługiwanych regionów. Na przykład "Zachodnie stany USA 2". |
| Nazwisko |
Nazwa zasobu. |
| Warstwa cenowa |
Jedna z obsługiwanych warstw cenowych. Aby wypróbować usługę, możesz użyć warstwy Bezpłatna (F0). |
Jeśli zostanie wyświetlony komunikat "Twoje konto logowania nie jest właścicielem wybranej grupy zasobów konta magazynu", twoje konto musi mieć przypisaną rolę właściciela w grupie zasobów, zanim będzie można utworzyć zasób językowy. Skontaktuj się z właścicielem subskrypcji platformy Azure, aby uzyskać pomoc.
Możesz określić właściciela subskrypcji platformy Azure, wyszukując grupę zasobów i korzystając z linku do skojarzonej subskrypcji. Następnie:
- Wybierz kartę Kontrola dostępu (Zarządzanie dostępem i tożsamościami)
- Wybieranie przypisań ról
- Filtruj według roli:właściciel.
W sekcji Niestandardowa klasyfikacja tekstu i niestandardowe rozpoznawanie nazwanych jednostek wybierz istniejące konto magazynu lub wybierz pozycję Nowe konto magazynu. Należy pamiętać, że te wartości ułatwiają rozpoczęcie pracy, a niekoniecznie wartości konta magazynu, których chcesz użyć w środowiskach produkcyjnych. Aby uniknąć opóźnień podczas kompilowania projektu, połącz się z kontami magazynu w tym samym regionie co zasób języka.
| Wartość konta magazynu |
Zalecana wartość |
| Nazwa konta magazynu |
Dowolna nazwa |
| Storage account type |
Standardowa LRS |
Upewnij się, że zaznaczono powiadomienie o odpowiedzialnej sztucznej inteligencji . Wybierz pozycję Przejrzyj i utwórz w dolnej części strony.
Tworzenie nowego zasobu językowego z poziomu programu Language Studio
Jeśli po raz pierwszy się zalogujesz, zostanie wyświetlone okno w programie Language Studio , które pozwoli wybrać istniejący zasób języka lub utworzyć nowy. Zasób można również utworzyć, klikając ikonę ustawień w prawym górnym rogu, wybierając pozycję Zasoby, a następnie klikając pozycję Utwórz nowy zasób.
Utwórz zasób języka, postępując zgodnie z poniższymi szczegółami.
| Szczegóły wystąpienia |
Wartość wymagana |
| Subskrypcja platformy Azure |
Subskrypcja platformy Azure |
| Grupa zasobów platformy Azure |
Grupa zasobów platformy Azure |
| Nazwa zasobu platformy Azure |
Nazwa zasobu platformy Azure |
| Lokalizacja |
Region, w którym zasób języka. |
| Warstwa cenowa |
Warstwa cenowa zasobu Language. |
Ważne
- Pamiętaj, aby włączyć tożsamość zarządzaną podczas tworzenia zasobu language.
- Przeczytaj i potwierdź powiadomienie o odpowiedzialnej sztucznej inteligencji
Aby użyć niestandardowej klasyfikacji tekstu, musisz połączyć zasób z kontem magazynu. Jeśli go nie masz, możesz utworzyć konto usługi Azure Storage. Wykonaj poniższe kroki, aby utworzyć pierwszy projekt i połączyć konto magazynu.
Zaloguj się do programu Language Studio. Zostanie wyświetlone okno umożliwiające wybranie subskrypcji i zasobu językowego. Wybierz zasób języka.
W sekcji Klasyfikowanie tekstu w programie Language Studio wybierz pozycję Klasyfikacja tekstu niestandardowego.
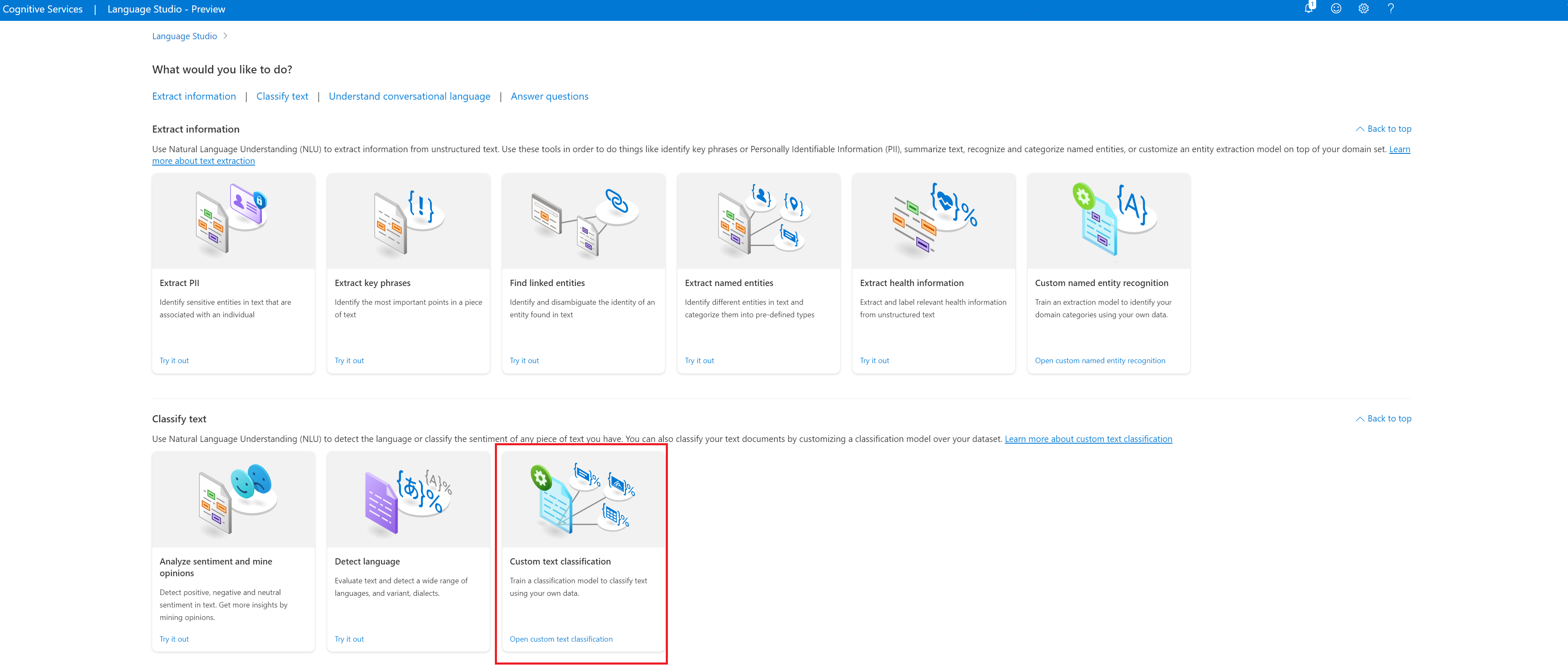
Wybierz pozycję Utwórz nowy projekt z górnego menu na stronie projektów. Utworzenie projektu umożliwi etykietowanie danych, trenowanie, ocenianie, ulepszanie i wdrażanie modeli.
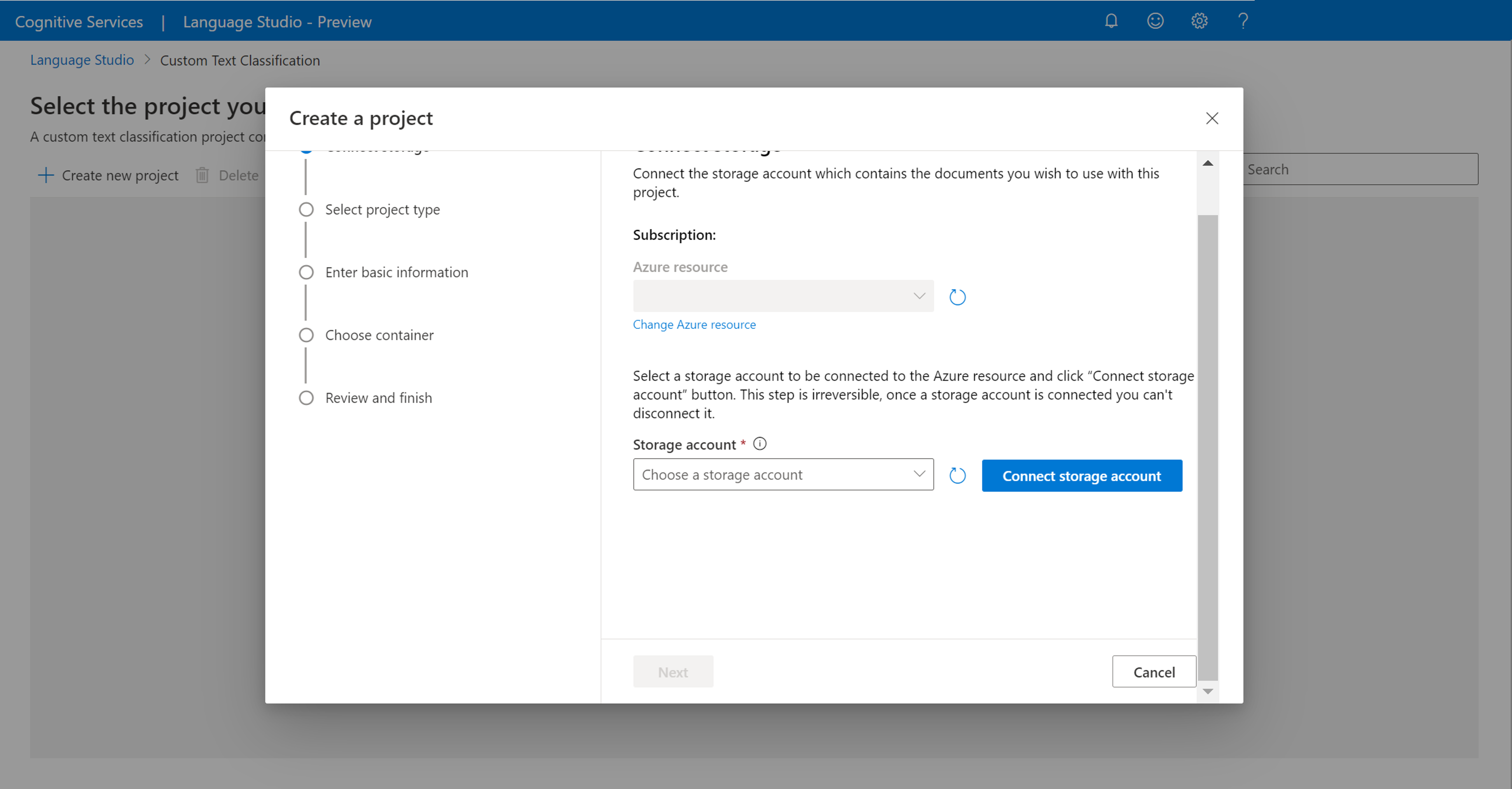
Po kliknięciu pozycji Utwórz nowy projekt zostanie wyświetlone okno umożliwiające nawiązanie połączenia z kontem magazynu. Jeśli masz już połączone konto magazynu, zobaczysz połączone konto magazynu. Jeśli nie, wybierz konto magazynu z wyświetlonej listy rozwijanej i wybierz pozycję Połącz konto magazynu. Spowoduje to ustawienie wymaganych ról dla konta magazynu. Ten krok może spowodować zwrócenie błędu, jeśli nie masz przypisanego jako właściciel konta magazynu.
Uwaga
- Ten krok należy wykonać tylko raz dla każdego nowego zasobu językowego, którego używasz.
- Ten proces jest nieodwracalny, jeśli połączysz konto magazynu z zasobem języka, nie możesz go odłączyć później.
- Zasób języka można połączyć tylko z jednym kontem magazynu.
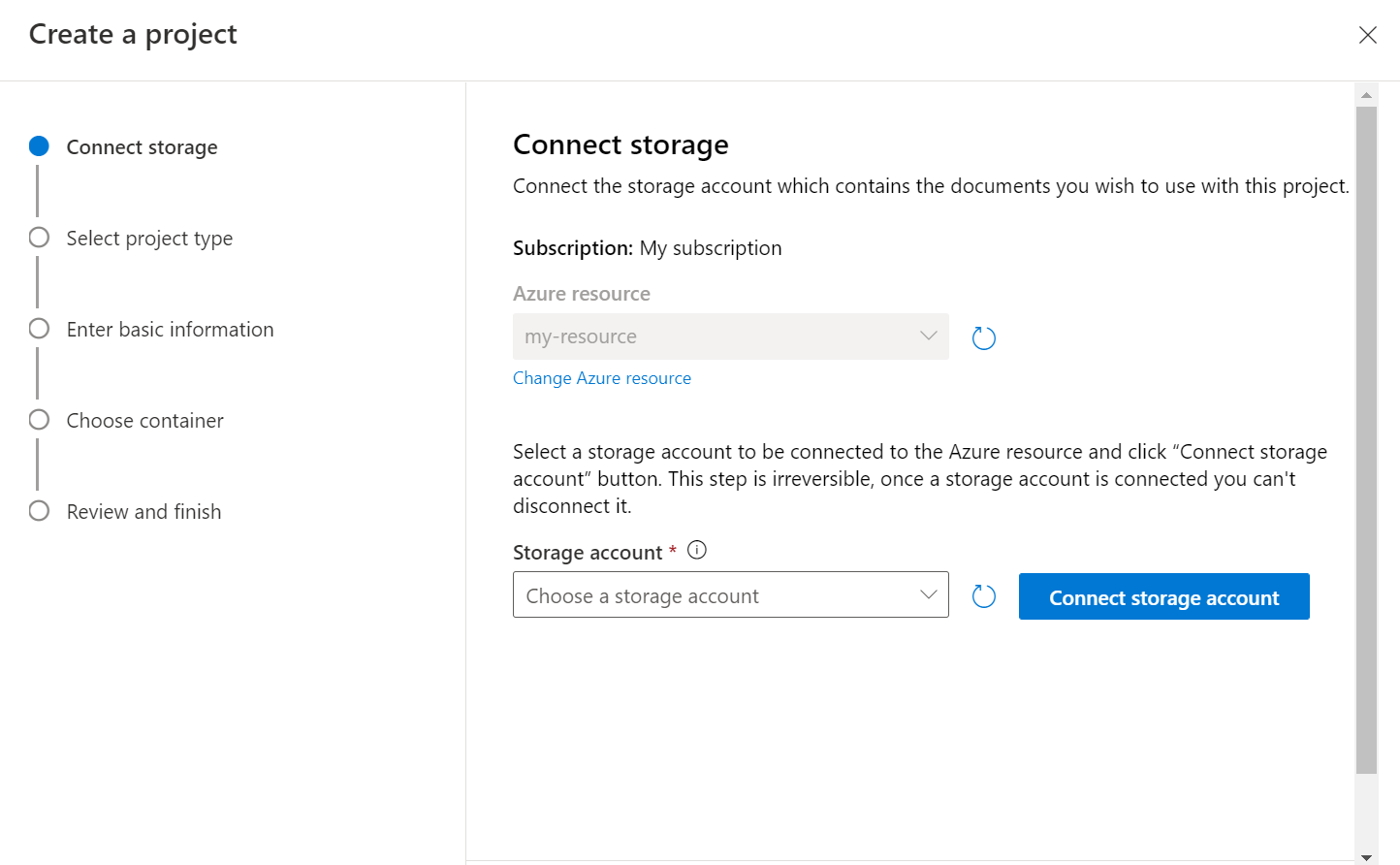
Wybierz typ projektu. Można utworzyć projekt klasyfikacji wielu etykiet, w którym każdy dokument może należeć do co najmniej jednej klasy lub projektu klasyfikacji pojedynczej etykiety, w którym każdy dokument może należeć tylko do jednej klasy. Nie można później zmienić wybranego typu. Dowiedz się więcej o typach projektów
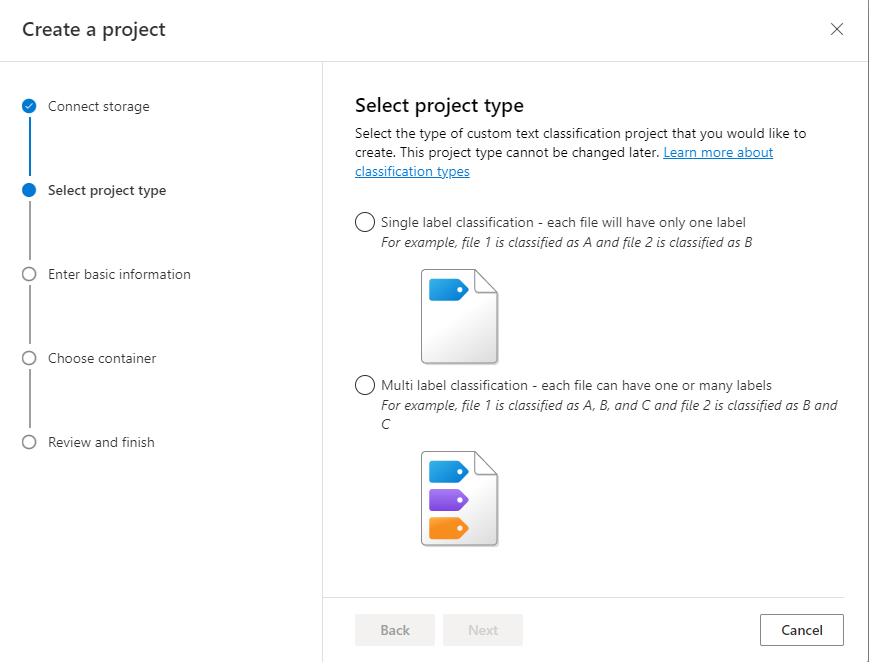
Wprowadź informacje o projekcie, w tym nazwę, opis i język dokumentów w projekcie. Jeśli używasz przykładowego zestawu danych, wybierz pozycję Angielski. Nie będzie można później zmienić nazwy projektu. Wybierz Dalej.
Napiwek
Zestaw danych nie musi być całkowicie w tym samym języku. Można mieć wiele dokumentów, z których każda ma różne obsługiwane języki. Jeśli zestaw danych zawiera dokumenty różnych języków lub jeśli oczekujesz tekstu z różnych języków w czasie wykonywania, wybierz opcję Włącz zestaw danych wielojęzyczny po wprowadzeniu podstawowych informacji dla projektu. Tę opcję można włączyć później na stronie Ustawienia projektu.
Wybierz kontener, w którym został przekazany zestaw danych.
Uwaga
Jeśli dane zostały już oznaczone etykietą, upewnij się, że jest on zgodny z obsługiwanym formatem i wybierz pozycję Tak, moje dokumenty są już oznaczone etykietami i sformatowane pliki etykiet JSON i wybierz plik etykiet z menu rozwijanego poniżej.
Jeśli używasz jednego z przykładowych zestawów danych, użyj dołączonego webOfScience_labelsFile pliku lub movieLabels json. Następnie kliknij przycisk Dalej.
Przejrzyj wprowadzone dane i wybierz pozycję Utwórz projekt.
Nowy zasób i konto magazynu można utworzyć przy użyciu następujących plików szablonu interfejsu wiersza polecenia i parametrów, które są hostowane w usłudze GitHub.
Edytuj następujące wartości w pliku parametrów:
| Nazwa parametru |
Opis wartości |
name |
Nazwa zasobu language |
location |
Region, w którym jest hostowany zasób. Aby uzyskać więcej informacji, zobacz obsługa regionów. |
sku |
Warstwa cenowa zasobu. Aby uzyskać więcej informacji, zobacz Limity usług. |
storageResourceName |
Nazwa konta magazynu |
storageLocation |
Region, w którym jest hostowane konto magazynu. |
storageSkuType |
Jednostka SKU konta magazynu. |
storageResourceGroupName |
Grupa zasobów konta magazynu |
Użyj następującego polecenia programu PowerShell, aby wdrożyć szablon usługi Azure Resource Manager (ARM) przy użyciu edytowanych plików.
New-AzResourceGroupDeployment -Name ExampleDeployment -ResourceGroupName ExampleResourceGroup `
-TemplateFile <path-to-arm-template> `
-TemplateParameterFile <path-to-parameters-file>
Zapoznaj się z dokumentacją szablonu usługi ARM, aby uzyskać informacje na temat wdrażania szablonów i plików parametrów.
Uwaga
- Proces łączenia konta magazynu z zasobem języka jest nieodwracalny. Nie można go później odłączyć.
- Zasób językowy można połączyć tylko z jednym kontem magazynu.
Korzystanie z istniejącego zasobu języka
| Wymaganie |
opis |
| Regiony |
Upewnij się, że istniejący zasób jest aprowizowany w jednym z obsługiwanych regionów. Jeśli nie masz zasobu, musisz utworzyć nowy w obsługiwanym regionie. |
| Warstwa cenowa |
Warstwa cenowa zasobu. |
| Tożsamość zarządzana |
Upewnij się, że ustawienie tożsamości zarządzanej zasobu jest włączone. W przeciwnym razie przeczytaj następną sekcję. |
Aby użyć niestandardowej klasyfikacji tekstu, musisz utworzyć konto usługi Azure Storage, jeśli jeszcze go nie masz.
Włączanie zarządzania tożsamościami dla zasobu
Aby umożliwić korzystanie z witryny Azure Portal, zasób języka musi mieć zarządzanie tożsamościami:
- Przejdź do zasobu Language
- W menu po lewej stronie w sekcji Zarządzanie zasobami wybierz pozycję Tożsamość
- Na karcie Przypisane przez system upewnij się, że ustawiono opcję Stan na Włączone
Aby umożliwić korzystanie z programu Language Studio, zasób języka musi mieć zarządzanie tożsamościami:
- Wybierz ikonę ustawień w prawym górnym rogu ekranu
- Wybieranie zasobów
- Zaznacz pole wyboru Tożsamość zarządzana dla zasobu języka sztucznej inteligencji platformy Azure.
Włączanie niestandardowej funkcji klasyfikacji tekstu
Upewnij się, że w witrynie Azure Portal włączono funkcję niestandardowej klasyfikacji tekstu/niestandardowego rozpoznawania nazwanych jednostek.
- Przejdź do zasobu language w witrynie Azure Portal
- W menu po lewej stronie w sekcji Zarządzanie zasobami wybierz pozycję Funkcje
- Włączanie niestandardowej klasyfikacji tekstu/niestandardowej funkcji rozpoznawania nazwanych jednostek
- Łączenie konta magazynu
- Wybierz Zastosuj
Ważne
- Upewnij się, że zasób języka ma przypisaną rolę współautora danych obiektu blob magazynu na połączonym koncie magazynu.
Ustawianie ról dla zasobu języka AI platformy Azure i konta magazynu
Wykonaj poniższe kroki, aby ustawić wymagane role dla zasobu języka i konta magazynu.
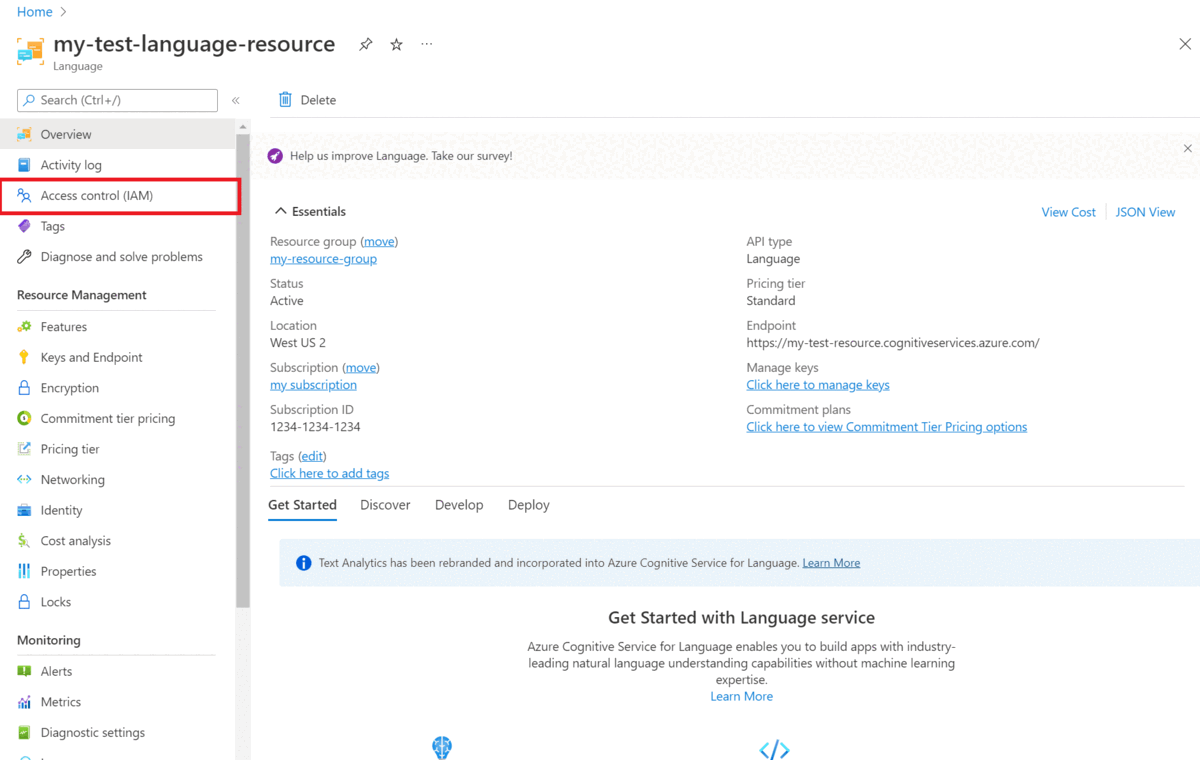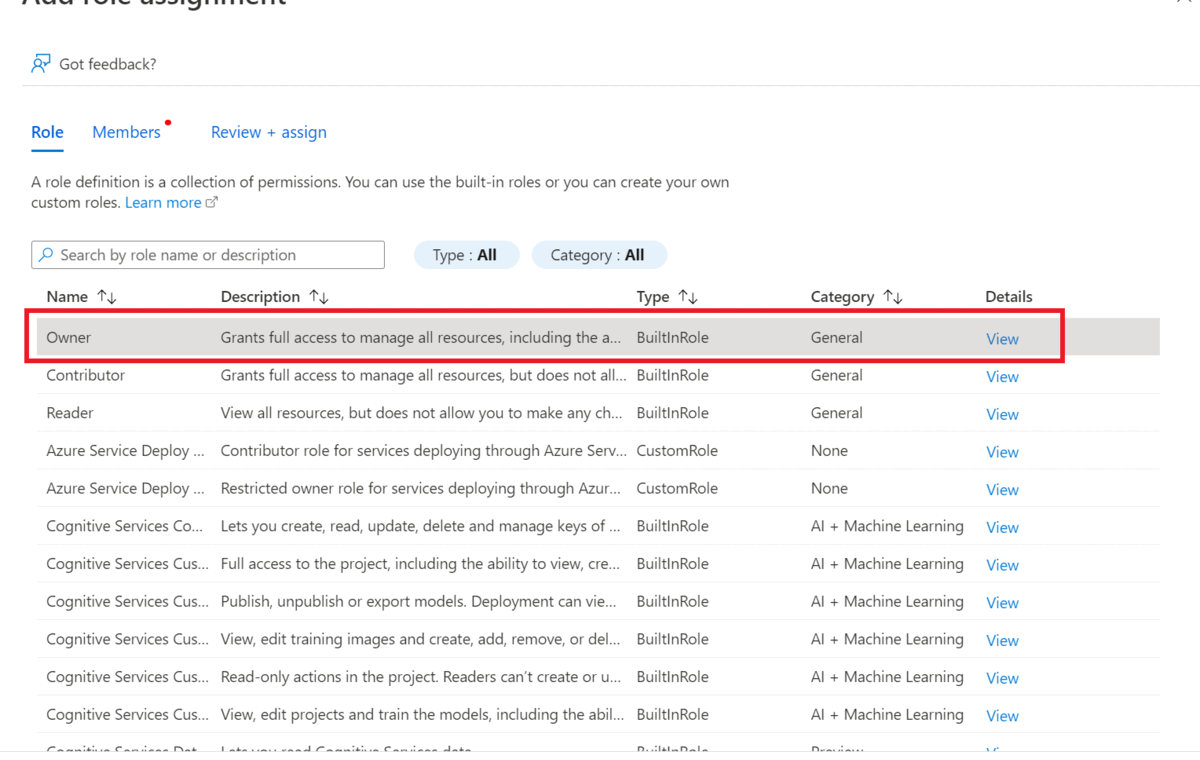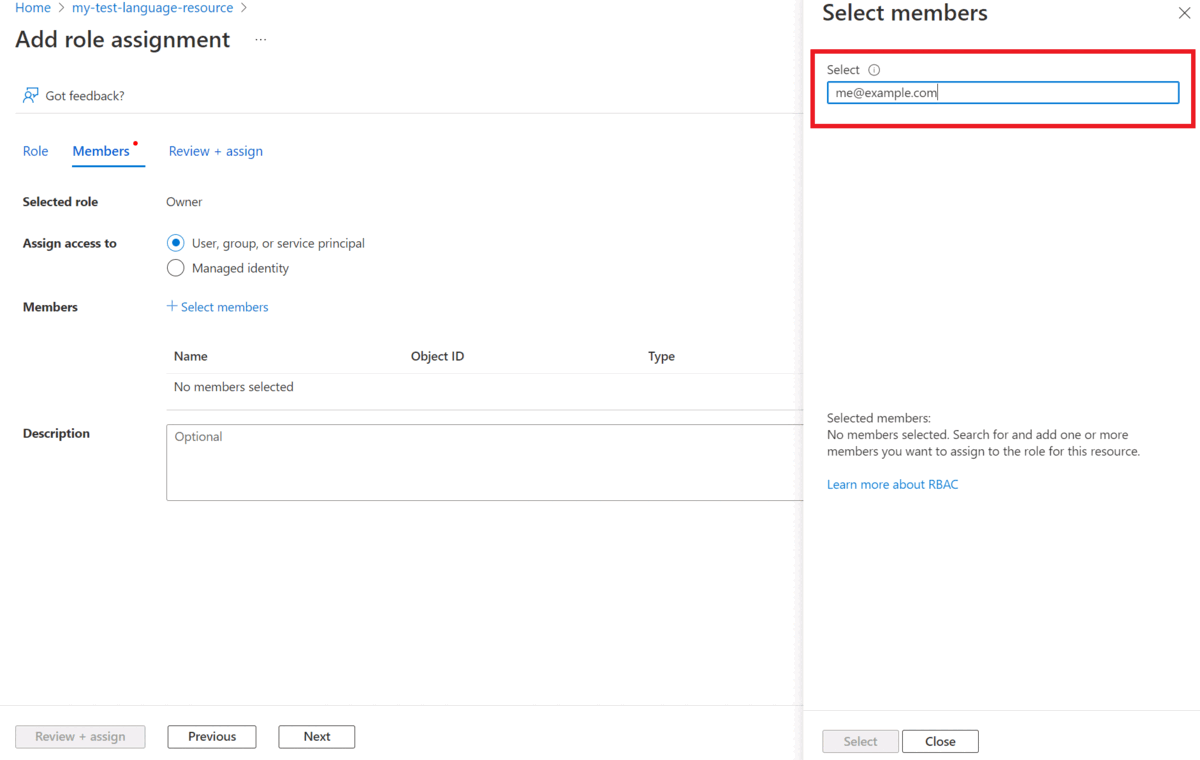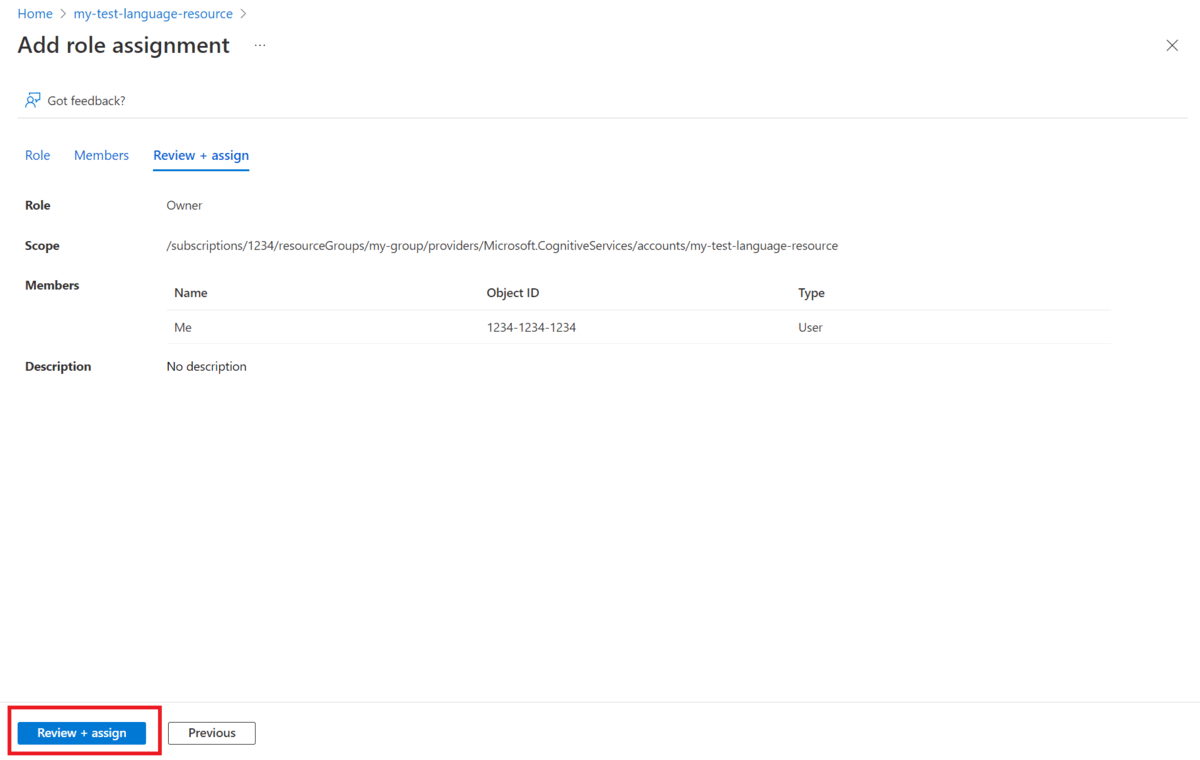
Role dla zasobu języka sztucznej inteligencji platformy Azure
Przejdź do swojego konta magazynu lub zasobu językowego w witrynie Azure Portal.
Wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami) w menu nawigacji po lewej stronie.
Wybierz pozycję Dodaj, aby dodać przypisania ról, a następnie wybierz odpowiednią rolę dla twojego konta.
Musisz mieć przypisaną rolę właściciela lub współautora w zasobie Język.
W obszarze Przypisz dostęp do wybierz pozycję Użytkownik, grupa lub jednostka usługi
Wybierz pozycję Wybierz członków
Wybierz nazwę użytkownika. Nazwy użytkowników można wyszukać w polu Wybierz . Powtórz to dla wszystkich ról.
Powtórz te kroki dla wszystkich kont użytkowników, które potrzebują dostępu do tego zasobu.
Role dla konta magazynu
- Przejdź do strony konta magazynu w witrynie Azure Portal.
- Wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami) w menu nawigacji po lewej stronie.
- Wybierz pozycję Dodaj, aby dodać przypisania ról, a następnie wybierz rolę Współautor danych obiektu blob usługi Storage na koncie magazynu.
- W obszarze Przypisz dostęp do wybierz pozycję Tożsamość zarządzana.
- Wybierz pozycję Wybierz członków
- Wybierz swoją subskrypcję i język jako tożsamość zarządzaną. Nazwy użytkowników można wyszukać w polu Wybierz .
Ważne
Jeśli masz sieć wirtualną lub prywatny punkt końcowy, wybierz pozycję Zezwalaj usługom platformy Azure na liście zaufanych usług, aby uzyskać dostęp do tego konta magazynu w witrynie Azure Portal.
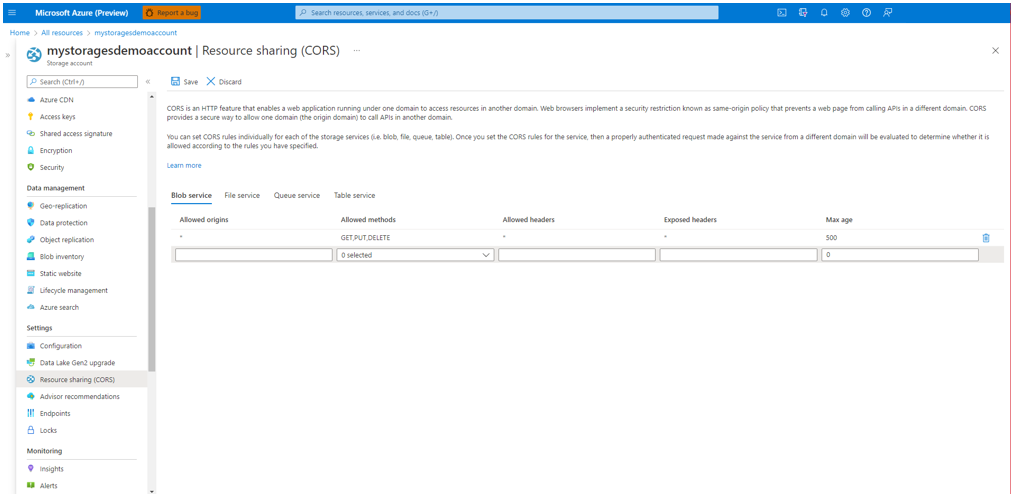
Włączanie mechanizmu CORS dla konta magazynu
Upewnij się, że metody (GET, PUT, DELETE) są dozwolone podczas włączania współużytkowania zasobów między źródłami (CORS).
Ustaw pole dozwolonych źródeł na https://language.cognitive.azure.comwartość . Zezwalaj na wszystkie nagłówki przez dodanie * do dozwolonych wartości nagłówka i ustaw maksymalny wiek na 500wartość .
Tworzenie niestandardowego projektu klasyfikacji tekstu
Po skonfigurowaniu zasobu i kontenera magazynu utwórz nowy niestandardowy projekt klasyfikacji tekstu. Projekt to obszar roboczy umożliwiający tworzenie niestandardowych modeli sztucznej inteligencji na podstawie danych. Dostęp do projektu można uzyskać tylko do Ciebie i innych osób, które mają dostęp do używanego zasobu platformy Azure. Jeśli masz etykiety danych, możesz je zaimportować, aby rozpocząć pracę.
Zaloguj się do programu Language Studio. Zostanie wyświetlone okno umożliwiające wybranie subskrypcji i zasobu językowego. Wybierz zasób języka.
W sekcji Klasyfikowanie tekstu w programie Language Studio wybierz pozycję Klasyfikacja tekstu niestandardowego.
Wybierz pozycję Utwórz nowy projekt z górnego menu na stronie projektów. Utworzenie projektu umożliwi etykietowanie danych, trenowanie, ocenianie, ulepszanie i wdrażanie modeli.
Po kliknięciu pozycji Utwórz nowy projekt zostanie wyświetlone okno umożliwiające nawiązanie połączenia z kontem magazynu. Jeśli masz już połączone konto magazynu, zobaczysz połączone konto magazynu. Jeśli nie, wybierz konto magazynu z wyświetlonej listy rozwijanej i wybierz pozycję Połącz konto magazynu. Spowoduje to ustawienie wymaganych ról dla konta magazynu. Ten krok może spowodować zwrócenie błędu, jeśli nie masz przypisanego jako właściciel konta magazynu.
Uwaga
- Ten krok należy wykonać tylko raz dla każdego nowego zasobu językowego, którego używasz.
- Ten proces jest nieodwracalny, jeśli połączysz konto magazynu z zasobem języka, nie możesz go odłączyć później.
- Zasób języka można połączyć tylko z jednym kontem magazynu.
Wybierz typ projektu. Można utworzyć projekt klasyfikacji wielu etykiet, w którym każdy dokument może należeć do co najmniej jednej klasy lub projektu klasyfikacji pojedynczej etykiety, w którym każdy dokument może należeć tylko do jednej klasy. Nie można później zmienić wybranego typu. Dowiedz się więcej o typach projektów
Wprowadź informacje o projekcie, w tym nazwę, opis i język dokumentów w projekcie. Jeśli używasz przykładowego zestawu danych, wybierz pozycję Angielski. Nie będzie można później zmienić nazwy projektu. Wybierz Dalej.
Napiwek
Zestaw danych nie musi być całkowicie w tym samym języku. Można mieć wiele dokumentów, z których każda ma różne obsługiwane języki. Jeśli zestaw danych zawiera dokumenty różnych języków lub jeśli oczekujesz tekstu z różnych języków w czasie wykonywania, wybierz opcję Włącz zestaw danych wielojęzyczny po wprowadzeniu podstawowych informacji dla projektu. Tę opcję można włączyć później na stronie Ustawienia projektu.
Wybierz kontener, w którym został przekazany zestaw danych.
Uwaga
Jeśli dane zostały już oznaczone etykietą, upewnij się, że jest on zgodny z obsługiwanym formatem i wybierz pozycję Tak, moje dokumenty są już oznaczone etykietami i sformatowane pliki etykiet JSON i wybierz plik etykiet z menu rozwijanego poniżej.
Jeśli używasz jednego z przykładowych zestawów danych, użyj dołączonego webOfScience_labelsFile pliku lub movieLabels json. Następnie kliknij przycisk Dalej.
Przejrzyj wprowadzone dane i wybierz pozycję Utwórz projekt.
Aby rozpocząć tworzenie niestandardowego modelu klasyfikacji tekstu, należy utworzyć projekt. Utworzenie projektu umożliwi etykietowanie danych, trenowanie, ocenianie, ulepszanie i wdrażanie modeli.
Uwaga
Nazwa projektu uwzględnia wielkość liter dla wszystkich operacji.
Utwórz żądanie PATCH przy użyciu następującego adresu URL, nagłówków i treści JSON, aby utworzyć projekt.
Adres URL żądania
Użyj następującego adresu URL, aby utworzyć projekt. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Symbol zastępczy |
Wartość |
Przykład |
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Zobacz Cykl życia modelu, aby dowiedzieć się więcej o innych dostępnych wersjach interfejsu API. |
2022-05-01 |
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key |
Wartość |
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść
Użyj następującego kodu JSON w żądaniu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "customMultiLabelClassification",
"description": "Project description",
"multilingual": "True",
"storageInputContainerName": "{CONTAINER-NAME}"
}
| Klucz |
Symbol zastępczy |
Wartość |
Przykład |
| projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
| język |
{LANGUAGE-CODE} |
Ciąg określający kod języka dokumentów używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości dokumentów. Zobacz Obsługa języka, aby dowiedzieć się więcej na temat obsługiwanych kodów języków. |
en-us |
| projectKind |
customMultiLabelClassification |
Rodzaj projektu. |
customMultiLabelClassification |
| wielojęzyczny |
true |
Wartość logiczna, która umożliwia posiadanie dokumentów w wielu językach w zestawie danych, a po wdrożeniu modelu można wykonywać zapytania względem modelu w dowolnym obsługiwanym języku (niekoniecznie zawarte w dokumentach szkoleniowych. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. |
true |
| storageInputContainerName |
{CONTAINER-NAME} |
Nazwa kontenera usługi Azure Storage, w którym zostały przekazane dokumenty. |
myContainer |
{
"projectName": "{PROJECT-NAME}",
"language": "{LANGUAGE-CODE}",
"projectKind": "customSingleLabelClassification",
"description": "Project description",
"multilingual": "True",
"storageInputContainerName": "{CONTAINER-NAME}"
}
| Klucz |
Symbol zastępczy |
Wartość |
Przykład |
| projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
| język |
{LANGUAGE-CODE} |
Ciąg określający kod języka dokumentów używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości dokumentów. Zobacz Obsługa języka, aby dowiedzieć się więcej na temat obsługiwanych kodów języków. |
en-us |
| projectKind |
customSingleLabelClassification |
Rodzaj projektu. |
customSingleLabelClassification |
| wielojęzyczny |
true |
Wartość logiczna, która umożliwia posiadanie dokumentów w wielu językach w zestawie danych, a po wdrożeniu modelu można wykonywać zapytania względem modelu w dowolnym obsługiwanym języku (niekoniecznie zawarte w dokumentach szkoleniowych. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. |
true |
| storageInputContainerName |
{CONTAINER-NAME} |
Nazwa kontenera usługi Azure Storage, w którym zostały przekazane dokumenty. |
myContainer |
To żądanie zwróci odpowiedź 201, co oznacza, że projekt zostanie utworzony.
To żądanie zwróci błąd, jeśli:
- Wybrany zasób nie ma odpowiednich uprawnień dla konta magazynu.
Importowanie niestandardowego projektu klasyfikacji tekstu
Jeśli masz już oznaczone dane, możesz użyć ich do rozpoczęcia pracy z usługą. Upewnij się, że dane oznaczone etykietami są zgodne z akceptowanymi formatami danych.
Zaloguj się do programu Language Studio. Zostanie wyświetlone okno umożliwiające wybranie subskrypcji i zasobu językowego. Wybierz zasób języka.
W sekcji Klasyfikowanie tekstu w programie Language Studio wybierz pozycję Klasyfikacja tekstu niestandardowego.
Wybierz pozycję Utwórz nowy projekt z górnego menu na stronie projektów. Utworzenie projektu umożliwi etykietowanie danych, trenowanie, ocenianie, ulepszanie i wdrażanie modeli.
Po wybraniu pozycji Utwórz nowy projekt zostanie wyświetlony ekran umożliwiający nawiązanie połączenia z kontem magazynu. Jeśli nie możesz znaleźć konta magazynu, upewnij się, że utworzono zasób, wykonując zalecane kroki. Jeśli masz już połączone konto magazynu z zasobem language, zobaczysz połączone konto magazynu.
Uwaga
- Ten krok należy wykonać tylko raz dla każdego nowego zasobu językowego, którego używasz.
- Ten proces jest nieodwracalny, jeśli połączysz konto magazynu z zasobem języka, nie możesz go odłączyć później.
- Zasób języka można połączyć tylko z jednym kontem magazynu.
Wybierz typ projektu. Można utworzyć projekt klasyfikacji wielu etykiet, w którym każdy dokument może należeć do co najmniej jednej klasy lub projektu klasyfikacji pojedynczej etykiety, w którym każdy dokument może należeć tylko do jednej klasy. Nie można później zmienić wybranego typu.
Wprowadź informacje o projekcie, w tym nazwę, opis i język dokumentów w projekcie. Nie będzie można później zmienić nazwy projektu. Wybierz Dalej.
Napiwek
Zestaw danych nie musi być całkowicie w tym samym języku. Można mieć wiele dokumentów, z których każda ma różne obsługiwane języki. Jeśli zestaw danych zawiera dokumenty różnych języków lub jeśli oczekujesz tekstu z różnych języków w czasie wykonywania, wybierz opcję Włącz zestaw danych wielojęzyczny po wprowadzeniu podstawowych informacji dla projektu. Tę opcję można włączyć później na stronie Ustawienia projektu.
Wybierz kontener, w którym został przekazany zestaw danych.
Wybierz pozycję Tak, moje dokumenty są już oznaczone etykietami i sformatowano plik etykiet JSON i wybierz plik etykiet z menu rozwijanego poniżej, aby zaimportować plik etykiet JSON. Upewnij się, że jest zgodny z obsługiwanym formatem.
Wybierz Dalej.
Przejrzyj wprowadzone dane i wybierz pozycję Utwórz projekt.
Prześlij żądanie POST przy użyciu następującego adresu URL, nagłówków i treści JSON, aby zaimportować plik etykiet. Upewnij się, że plik etykiet jest zgodne z akceptowanym formatem.
Jeśli projekt o tej samej nazwie już istnieje, dane tego projektu zostaną zastąpione.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Symbol zastępczy |
Wartość |
Przykład |
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API |
2022-05-01 |
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key |
Wartość |
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść
Użyj następującego kodu JSON w żądaniu. Zastąp poniższe wartości symboli zastępczych własnymi wartościami.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Klucz |
Symbol zastępczy |
Wartość |
Przykład |
| api-version |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Używana tutaj wersja musi być tą samą wersją interfejsu API w adresie URL. Dowiedz się więcej o innych dostępnych wersjach interfejsu API |
2022-05-01 |
| projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
| projectKind |
customMultiLabelClassification |
Rodzaj projektu. |
customMultiLabelClassification |
| język |
{LANGUAGE-CODE} |
Ciąg określający kod języka dokumentów używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości dokumentów. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. |
en-us |
| wielojęzyczny |
true |
Wartość logiczna, która umożliwia posiadanie dokumentów w wielu językach w zestawie danych, a po wdrożeniu modelu można wykonywać zapytania względem modelu w dowolnym obsługiwanym języku (niekoniecznie zawarte w dokumentach szkoleniowych. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. |
true |
| storageInputContainerName |
{CONTAINER-NAME} |
Nazwa kontenera usługi Azure Storage, w którym zostały przekazane dokumenty. |
myContainer |
| obiektów |
[] |
Tablica zawierająca wszystkie klasy, które znajdują się w projekcie. Są to klasy, do których chcesz sklasyfikować dokumenty. |
[] |
| documents |
[] |
Tablica zawierająca wszystkie dokumenty w projekcie i klasy oznaczone dla tego dokumentu. |
[] |
| lokalizacja |
{DOCUMENT-NAME} |
Lokalizacja dokumentów w kontenerze magazynu. Ponieważ wszystkie dokumenty znajdują się w katalogu głównym kontenera, powinien to być nazwa dokumentu. |
doc1.txt |
| zestaw danych |
{DATASET} |
Zestaw testowy, do którego ten dokument zostanie podzielony przed rozpoczęciem trenowania. Aby uzyskać więcej informacji na temat dzielenia danych, zobacz Jak wytrenować model . Możliwe wartości dla tego pola to Train i Test. |
Train |
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customSingleLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customSingleLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"class": {
"category": "Class2"
}
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"class": {
"category": "Class1"
}
}
]
}
}
| Klucz |
Symbol zastępczy |
Wartość |
Przykład |
| api-version |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Używana tutaj wersja musi być tą samą wersją interfejsu API w adresie URL. |
2022-05-01 |
| projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
| projectKind |
customSingleLabelClassification |
Rodzaj projektu. |
customSingleLabelClassification |
| język |
{LANGUAGE-CODE} |
Ciąg określający kod języka dokumentów używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości dokumentów. Zobacz Obsługa języka, aby dowiedzieć się więcej na temat obsługiwanych kodów języków. |
en-us |
| wielojęzyczny |
true |
Wartość logiczna, która umożliwia posiadanie dokumentów w wielu językach w zestawie danych, a po wdrożeniu modelu można wykonywać zapytania względem modelu w dowolnym obsługiwanym języku (niekoniecznie zawarte w dokumentach szkoleniowych. Zobacz Obsługa języków, aby dowiedzieć się więcej o obsłudze wielojęzycznej. |
true |
| storageInputContainerName |
{CONTAINER-NAME} |
Nazwa kontenera usługi Azure Storage, w którym zostały przekazane dokumenty. |
myContainer |
| obiektów |
[] |
Tablica zawierająca wszystkie klasy, które znajdują się w projekcie. Są to klasy, do których chcesz sklasyfikować dokumenty. |
[] |
| documents |
[] |
Tablica zawierająca wszystkie dokumenty w projekcie i klasę, do której należy ten dokument. |
[] |
| lokalizacja |
{DOCUMENT-NAME} |
Lokalizacja dokumentów w kontenerze magazynu. Ponieważ wszystkie dokumenty znajdują się w katalogu głównym kontenera, powinien to być nazwa dokumentu. |
doc1.txt |
| zestaw danych |
{DATASET} |
Zestaw testowy, do którego ten dokument zostanie podzielony przed rozpoczęciem trenowania. Zobacz Jak wytrenować model , aby dowiedzieć się więcej na temat dzielenia danych. Możliwe wartości dla tego pola to Train i Test. |
Train |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 , że zadanie zostało przesłane poprawnie. W nagłówkach odpowiedzi wyodrębnij operation-location wartość. Zostanie on sformatowany w następujący sposób:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} służy do identyfikowania żądania, ponieważ ta operacja jest asynchroniczna. Użyjesz tego adresu URL, aby uzyskać stan zadania importu.
Możliwe scenariusze błędów dla tego żądania:
- Wybrany zasób nie ma odpowiednich uprawnień dla konta magazynu.
- Określona
storageInputContainerName wartość nie istnieje.
- Jest używany nieprawidłowy kod języka lub jeśli typ kodu języka nie jest ciągiem.
multilingual wartość jest ciągiem, a nie wartością logiczną.
Pobieranie szczegółów projektu
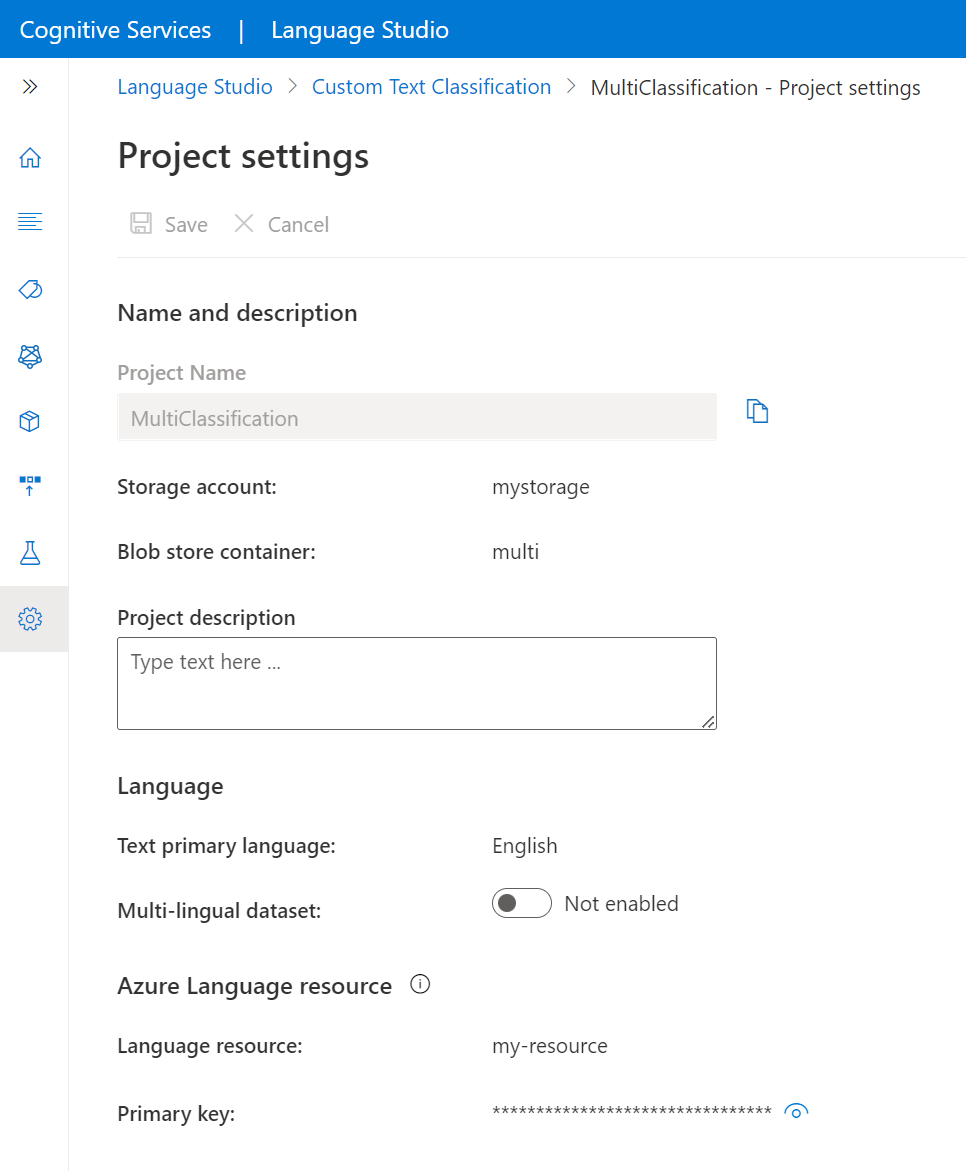
Przejdź do strony ustawień projektu w programie Language Studio.
Możesz wyświetlić szczegóły projektu.
Na tej stronie można zaktualizować opis projektu i włączyć/wyłączyć wielojęzyczny zestaw danych w ustawieniach projektu.
Możesz również wyświetlić połączone konto magazynu i kontener do zasobu Language.
Możesz również pobrać klucz podstawowy zasobu z tej strony.
Aby uzyskać niestandardowe szczegóły projektu klasyfikacji tekstu, prześlij żądanie GET przy użyciu następującego adresu URL i nagłówków. Zastąp wartości symboli zastępczych własnymi wartościami.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}?api-version={API-VERSION}
| Symbol zastępczy |
Wartość |
Przykład |
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartością, do których odwołuje się tutaj, jest najnowsza wydana wersja modelu. |
2022-05-01 |
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key |
Wartość |
Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Treść odpowiedzi
Po wysłaniu żądania otrzymasz następującą odpowiedź.
{
"createdDateTime": "2022-04-23T13:39:09.384Z",
"lastModifiedDateTime": "2022-04-23T13:39:09.384Z",
"lastTrainedDateTime": "2022-04-23T13:39:09.384Z",
"lastDeployedDateTime": "2022-04-23T13:39:09.384Z",
"projectKind": "customSingleLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": true,
"description": "Project description",
"language": "{LANGUAGE-CODE}"
}
| Wartość |
Symbol zastępczy |
opis |
Przykład |
projectKind |
customSingleLabelClassification |
Rodzaj projektu. |
Może to być customSingleLabelClassification wartość lub customMultiLabelClassification. |
storageInputContainerName |
{CONTAINER-NAME} |
Nazwa kontenera usługi Azure Storage, w którym zostały przekazane dokumenty. |
myContainer |
projectName |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
multilingual |
|
Wartość logiczna, która umożliwia posiadanie dokumentów w wielu językach w zestawie danych. Po wdrożeniu modelu można wykonywać zapytania dotyczące modelu w dowolnym obsługiwanym języku (niekoniecznie zawarte w dokumentach szkoleniowych). Aby uzyskać więcej informacji na temat obsługi wielojęzycznej, zobacz obsługa języków. |
true |
language |
{LANGUAGE-CODE} |
Ciąg określający kod języka dokumentów używanych w projekcie. Jeśli projekt jest projektem wielojęzycznym, wybierz kod języka większości dokumentów. Zobacz Obsługa języka, aby dowiedzieć się więcej na temat obsługiwanych kodów języków. |
en-us |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 200 powodzenie i treść odpowiedzi JSON ze szczegółami projektu.
Usuwanie projektu
Jeśli projekt nie jest już potrzebny, możesz usunąć projekt przy użyciu programu Language Studio. Wybierz pozycję Niestandardowa klasyfikacja tekstu u góry , a następnie wybierz projekt, który chcesz usunąć. Wybierz pozycję Usuń z górnego menu, aby usunąć projekt.
Jeśli projekt nie jest już potrzebny, możesz go usunąć za pomocą następującego żądania DELETE . Zastąp wartości symboli zastępczych własnymi wartościami.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Symbol zastępczy |
Wartość |
Przykład |
{ENDPOINT} |
Punkt końcowy do uwierzytelniania żądania interfejsu API. |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nazwa projektu. Ta wartość jest uwzględniana w wielkości liter. |
myProject |
{API-VERSION} |
Wersja wywoływanego interfejsu API. Wartość, do których odwołuje się tutaj, dotyczy najnowszej wersji wydanej. Dowiedz się więcej o innych dostępnych wersjach interfejsu API |
2022-05-01 |
Użyj następującego nagłówka, aby uwierzytelnić żądanie.
| Key |
Wartość |
| Ocp-Apim-Subscription-Key |
Klucz do zasobu. Służy do uwierzytelniania żądań interfejsu API. |
Po wysłaniu żądania interfejsu API otrzymasz odpowiedź wskazującą 202 powodzenie, co oznacza, że projekt został usunięty. Wyniki pomyślnego wywołania z nagłówkiem Operation-Location służącym do sprawdzania stanu zadania.
Następne kroki
Musisz mieć pomysł na schemat projektu, którego będziesz używać do etykietowania danych.
Po utworzeniu projektu można rozpocząć etykietowanie danych, co poinformuje model klasyfikacji tekstu o sposobie interpretowania tekstu i jest używany do trenowania i oceny.







