Konfigurowanie środowisk na potrzeby programowania i produkcji
W ramach metodyki DevOps środowisko odwołuje się do kolekcji zasobów. Te zasoby służą do wdrażania aplikacji lub projektów uczenia maszynowego w celu wdrożenia modelu.
Używanie środowisk do ciągłego dostarczania
Liczba środowisk, z którym pracujesz, zależy od organizacji. Często istnieją co najmniej dwa środowiska: programowanie lub tworzenie i produkcja lub prod. Ponadto można dodawać środowiska między środowiskiem przejściowym lub przedprodukcyjnym (przedprodowym).
W przypadku ciągłego dostarczania typowym podejściem jest:
- Poeksperymentuj z trenowaniem modelu w środowisku projektowym.
- Przenieś najlepszy model do środowiska przejściowego lub wstępnego, aby wdrożyć i przetestować model.
- Na koniec wydaj model do środowiska produkcyjnego, aby wdrożyć model, aby użytkownicy końcowi mogli z niego korzystać.
Uwaga
W tym module odwołujemy się do interpretacji środowisk DevOps. Pamiętaj, że usługa Azure Machine Learning używa również terminów środowiska do opisania kolekcji pakietów języka Python potrzebnych do uruchomienia skryptu. Te dwie koncepcje środowisk są niezależne od siebie. Dowiedz się więcej o środowiskach usługi Azure Machine Learning.
Organizowanie środowisk usługi Azure Machine Learning
Podczas implementowania metodyki MLOps i pracy z modelami uczenia maszynowego na dużą skalę najlepszym rozwiązaniem jest praca z oddzielnymi środowiskami dla różnych etapów.
Tworzenie obrazu zespołu korzysta ze środowiska deweloperskiego, wstępnego i prod. Nie wszyscy członkowie zespołu powinni uzyskać dostęp do wszystkich środowisk. Analitycy danych mogą pracować tylko w środowisku deweloperskim z danymi nieprodukcyjnymi, podczas gdy inżynierowie uczenia maszynowego pracują nad wdrażaniem modelu w środowisku przedprodowym i prod z danymi produkcyjnymi.
Posiadanie oddzielnych środowisk ułatwi kontrolowanie dostępu do zasobów. Każde środowisko może być następnie skojarzone z oddzielnym obszarem roboczym usługi Azure Machine Learning.
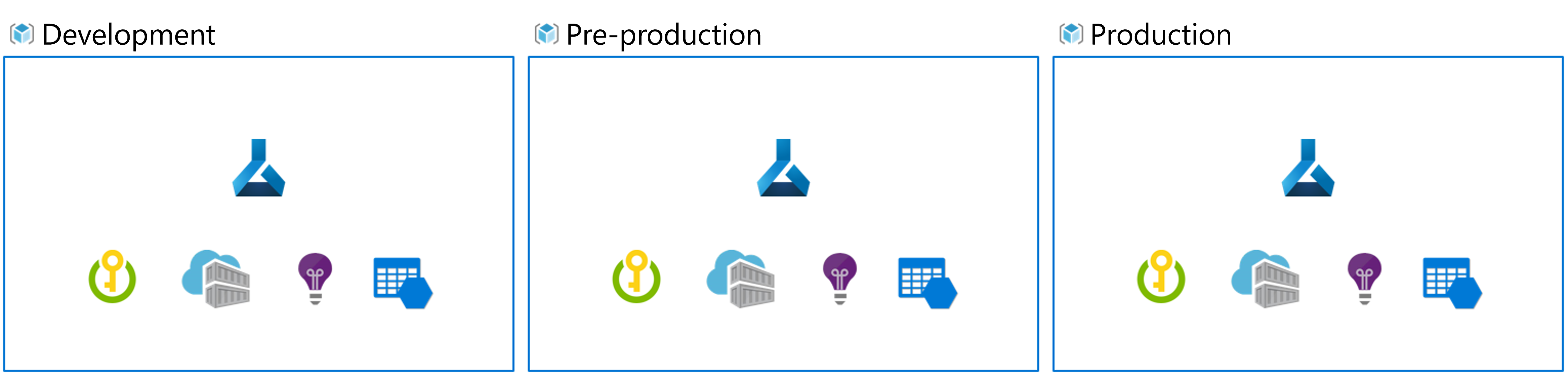
Na platformie Azure użyjesz kontroli dostępu opartej na rolach (RBAC), aby zapewnić współpracownikom odpowiedni poziom dostępu do podzbioru zasobów, z którymi muszą pracować.
Alternatywnie można użyć tylko jednego obszaru roboczego usługi Azure Machine Learning. W przypadku korzystania z jednego obszaru roboczego na potrzeby programowania i produkcji będziesz mieć mniejsze obciążenie związane z platformą Azure i mniejsze obciążenie związane z zarządzaniem. Jednak kontrola dostępu oparta na rolach będzie miała zastosowanie zarówno do deweloperów, jak i prod, co może oznaczać, że dajesz ludziom zbyt mało lub zbyt dużo dostępu do zasobów.
Napiwek
Dowiedz się więcej o najlepszych rozwiązaniach dotyczących organizowania zasobów usługi Azure Machine Learning.
Aby pracować ze środowiskami na różnych etapach tworzenia modelu, możesz kierować je do środowiska podczas uruchamiania usługi Azure Pipeline lub przepływu pracy za pomocą funkcji GitHub Actions.
Środowiska usługi Azure DevOps
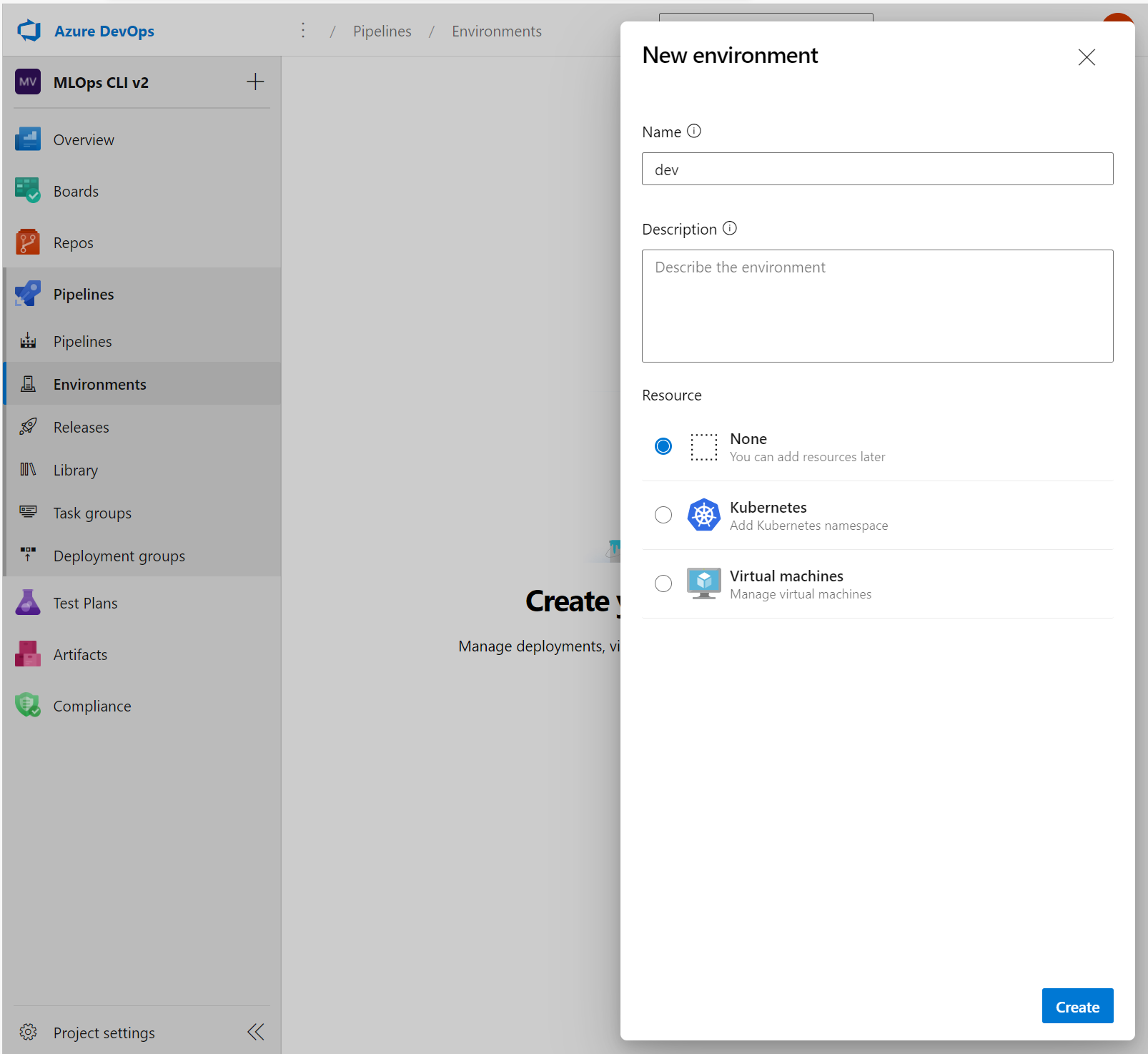
Aby pracować ze środowiskami w usłudze Azure DevOps, należy najpierw utworzyć środowiska. Następnie możesz określić środowisko, w którym chcesz wdrożyć usługę Azure Pipeline.
- W usłudze Azure DevOps rozwiń menu Potoki .
- Wybierz Środowiska.
- Utwórz nowe środowisko.
- Nadaj swojemu środowisku nazwę.
- Wybierz pozycję Brak dla zasobów. Docelowy obszar roboczy usługi Azure Machine Learning jest przeznaczony w samym potoku.
- Wybierz pozycję Utwórz.
Po utworzeniu środowisk w usłudze Azure DevOps i różnych obszarach roboczych usługi Azure Machine Learning skojarzonych z każdym środowiskiem możesz określić środowisko, do którego chcesz wdrożyć w pliku YAML usługi Azure Pipelines:
trigger:
- main
stages:
- stage: deployDev
displayName: 'Deploy to development environment'
jobs:
- deployment: publishPipeline
displayName: 'Model Training'
pool:
vmImage: 'Ubuntu-18.04'
environment: dev
strategy:
runOnce:
deploy:
steps:
- template: aml-steps.yml
parameters:
serviceconnectionname: 'spn-aml-workspace-dev'
Wartość parametru environment w pliku YAML to dev, co wskazuje, że model jest trenowany w środowisku projektowym. Za pośrednictwem połączenia z usługą należy określić obszar roboczy usługi Azure Machine Learning, którego chcesz użyć do trenowania modelu.
Napiwek
Dowiedz się więcej na temat tworzenia i określania celu środowiska za pomocą usługi Azure DevOps.
Środowiska usługi GitHub
Aby używać środowisk z funkcją GitHub Actions, należy najpierw utworzyć środowisko. Następnie możesz użyć środowiska w przepływie pracy.
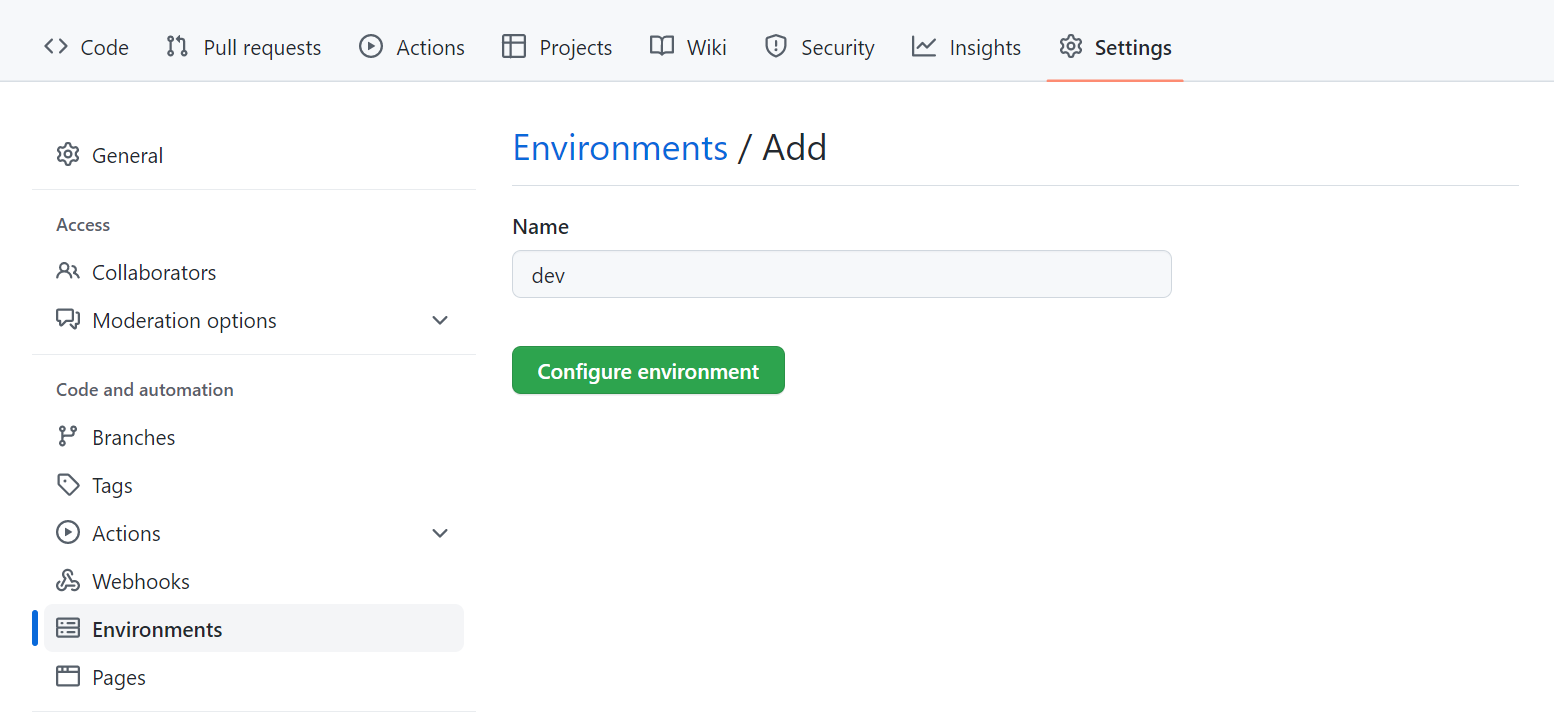
Aby utworzyć środowisko w repozytorium GitHub (repozytorium):
- Przejdź do karty Ustawienia w repozytorium.
- Wybierz Środowiska.
- Utwórz nowe środowisko.
- Wprowadź nazwę.
- Wybierz pozycję Konfiguruj środowisko.
Aby skojarzyć środowisko z określonym obszarem roboczym usługi Azure Machine Learning, możesz utworzyć wpis tajny środowiska, aby zapewnić dostęp tylko do obszaru roboczego usługi Azure Machine Learning.
Aby użyć środowiska w przepływie pracy, możesz dodać środowisko, do którego chcesz wdrożyć, dołączając je do pliku YAML:
name: Train model
on:
push:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
environment:
name: dev
steps:
- name: check out repo
uses: actions/checkout@v2
- name: install az ml extension
run: az extension add -n ml -y
- name: azure login
uses: azure/login@v1
with:
creds: ${{secrets.AZURE_CREDENTIALS}}
- name: set current directory
run: cd src
- name: run pipeline
run: az ml job create --file src/aml_service/pipeline-job.yml --resource-group dev-ml-rg --workspace-name dev-ml-ws
W tym przykładzie wpis AZURE_CREDENTIALS tajny zawiera informacje o połączeniu z obszarem roboczym usługi Azure Machine Learning używanym w tym środowisku.
Napiwek
Dowiedz się więcej o tworzeniu i używaniu środowiska za pomocą funkcji GitHub Actions.