Co to są środowiska usługi Azure Machine Learning?
Środowiska usługi Azure Machine Learning to hermetyzacja środowiska, w którym odbywa się trenowanie lub wnioskowanie uczenia maszynowego. Określają one pakiety języka Python i ustawienia oprogramowania wokół skryptów trenowania i oceniania. Środowiska są zarządzane i wersjonowane jednostki w obszarze roboczym usługi Machine Learning, które umożliwiają odtwarzanie, inspekcję i przenośne przepływy pracy uczenia maszynowego w różnych celach obliczeniowych. Możesz użyć Environment obiektu w celu:
- Opracowywanie skryptu szkoleniowego.
- Ponowne użycie tego samego środowiska w usłudze Azure Machine Learning Compute na potrzeby trenowania modeli na dużą skalę.
- Wdróż model przy użyciu tego samego środowiska.
- Ponownie zajmij się środowiskiem, w którym został wytrenowany istniejący model.
Na poniższym diagramie pokazano, jak można użyć pojedynczego Environment obiektu zarówno w konfiguracji zadania (na potrzeby trenowania), jak i konfiguracji wnioskowania i wdrażania (w przypadku wdrożeń usług internetowych).
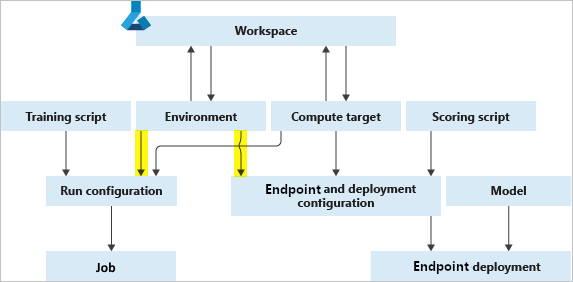
Środowisko, docelowy obiekt obliczeniowy i skrypt szkoleniowy razem tworzą konfigurację zadania: pełną specyfikację zadania szkoleniowego.
Typy środowisk
Środowiska można zasadniczo podzielić na trzy kategorie: nadzorowane, zarządzane przez użytkownika i zarządzane przez system.
Wyselekcjonowane środowiska są udostępniane przez usługę Azure Machine Learning i są domyślnie dostępne w obszarze roboczym. Przeznaczone do użycia tak, jak to jest, zawierają kolekcje pakietów i ustawień języka Python, aby ułatwić rozpoczęcie pracy z różnymi strukturami uczenia maszynowego. Te wstępnie utworzone środowiska umożliwiają również krótszy czas wdrażania. Wyselekcjonowane środowiska są hostowane w rejestrze AzureML, który jest rejestrem uczenia maszynowego hostowanym przez firmę Microsoft. Aby uzyskać pełną listę, zobacz środowiska w rejestrze AzureML.
W środowiskach zarządzanych przez użytkownika odpowiadasz za skonfigurowanie środowiska i zainstalowanie każdego pakietu wymaganego przez skrypt trenowania na docelowym obiekcie obliczeniowym. Pamiętaj również, aby uwzględnić wszystkie zależności wymagane do wdrożenia modelu. Środowisko zarządzane przez użytkownika może mieć wartość BYOC (Bring Your Own Container) lub Kontekst kompilacji platformy Docker, który deleguje materializację obrazu do usługi Azure Machine Learning. Podobnie jak w przypadku wyselekcjonowanych środowisk, można udostępniać środowiska zarządzane przez użytkownika w obszarach roboczych przy użyciu rejestru uczenia maszynowego, który tworzysz i zarządzasz.
Środowiska zarządzane przez system są używane, gdy chcesz , aby conda zarządzała środowiskiem języka Python. Nowe środowisko conda jest materializowane ze specyfikacji conda na podstawie podstawowego obrazu platformy Docker.
Tworzenie środowisk i zarządzanie nimi
Środowiska można tworzyć na podstawie zestawu SDK języka Python usługi Azure Machine Learning, interfejsu wiersza polecenia usługi Azure Machine Learning, programu Azure Machine Learning Studio i rozszerzenia programu VS Code. Każdy klient umożliwia dostosowanie obrazu podstawowego, pliku Dockerfile i warstwy języka Python w razie potrzeby.
Aby zapoznać się z konkretnymi przykładami kodu, zobacz sekcję "Tworzenie środowiska" w temacie How to use environments (Jak używać środowisk).
Środowiska są również łatwo zarządzane za pośrednictwem obszaru roboczego, co umożliwia:
- Rejestrowanie środowisk.
- Pobierz środowiska z obszaru roboczego, aby użyć ich do trenowania lub wdrażania.
- Utwórz nowe wystąpienie środowiska, edytując istniejące.
- Wyświetl zmiany w środowiskach w czasie, co zapewnia powtarzalność.
- Twórz obrazy platformy Docker automatycznie ze środowisk.
Środowiska "Anonimowe" są automatycznie rejestrowane w obszarze roboczym podczas przesyłania eksperymentu. Nie są one wymienione, ale możesz użyć wersji do ich pobrania.
Przykłady kodu można znaleźć w sekcji "Zarządzanie środowiskami" w temacie How to use environments (Jak używać środowisk).
Kompilowanie, buforowanie i ponowne używanie środowiska
Usługa Azure Machine Learning tworzy definicje środowisk w obrazach platformy Docker. Buforuje również środowiska, aby mogły być ponownie używane w kolejnych zadaniach szkoleniowych i wdrożeniach punktu końcowego usługi. Zdalne uruchamianie skryptu szkoleniowego wymaga utworzenia obrazu platformy Docker. Domyślnie usługa Azure Machine Learning zarządza obiektem docelowym kompilacji obrazu w przypadku bezserwerowego limitu przydziału obliczeniowego obszaru roboczego, jeśli nie ma dedykowanego zestawu obliczeniowego dla obszaru roboczego.
Uwaga
Wszelkie ograniczenia sieci w obszarze roboczym usługi Azure Machine Learning mogą wymagać dedykowanej konfiguracji obliczeniowej kompilacji obrazów zarządzanych przez użytkownika. Wykonaj kroki, aby zabezpieczyć zasoby obszaru roboczego.
Przesyłanie zadania przy użyciu środowiska
Po pierwszym przesłaniu zadania zdalnego przy użyciu środowiska lub ręcznego utworzenia wystąpienia środowiska usługa Azure Machine Learning tworzy obraz dla podanej specyfikacji. Obraz wyniku jest buforowany w wystąpieniu rejestru kontenerów skojarzonym z obszarem roboczym. Wyselekcjonowane środowiska są już buforowane w rejestrze usługi Azure Machine Learning. Na początku wykonywania zadania docelowy obiekt obliczeniowy pobiera obraz z odpowiedniego rejestru kontenerów.
Kompilowanie środowisk jako obrazów platformy Docker
Jeśli obraz dla określonej definicji środowiska jeszcze nie istnieje w wystąpieniu rejestru kontenerów skojarzonym z obszarem roboczym usługi Azure Machine Learning, zostanie skompilowany nowy obraz. W przypadku środowisk zarządzanych przez system kompilacja obrazu składa się z dwóch kroków:
- Pobieranie obrazu podstawowego i wykonywanie dowolnych kroków platformy Docker
- Tworzenie środowiska conda zgodnie z zależnościami conda określonymi w definicji środowiska.
W przypadku środowisk zarządzanych przez użytkownika zapewniane są kompilacje kontekstu platformy Docker. W takim przypadku odpowiadasz za instalowanie dowolnych pakietów języka Python, dołączając je do obrazu podstawowego lub określając niestandardowe kroki platformy Docker.
Buforowanie obrazów i ponowne użycie
Jeśli używasz tej samej definicji środowiska dla innego zadania, usługa Azure Machine Learning ponownie używa buforowanego obrazu z rejestru kontenerów skojarzonego z obszarem roboczym.
Aby wyświetlić szczegóły buforowanego obrazu, sprawdź stronę Środowiska w usłudze Azure Machine Learning Studio lub użyj polecenia MLClient.environments , aby uzyskać i sprawdzić środowisko.
Aby określić, czy ponownie użyć buforowanego obrazu, czy utworzyć nowy, usługa Azure Machine Learning oblicza wartość skrótu z definicji środowiska. Następnie porównuje skrót z skrótami istniejących środowisk. Skrót służy jako unikatowy identyfikator środowiska i jest oparty na definicji środowiska:
- Obraz podstawowy
- Niestandardowe kroki platformy Docker
- Pakiety języka Python
Nazwa i wersja środowiska nie mają wpływu na skrót. Jeśli zmienisz nazwę środowiska lub utworzysz nowe z tymi samymi ustawieniami i pakietami co inne środowisko, wartość skrótu pozostanie taka sama. Jednak definicja środowiska zmienia się, takich jak dodawanie lub usuwanie pakietu Python lub zmiana wersji pakietu zmienia wynikową wartość skrótu. Zmiana kolejności zależności lub kanałów w środowisku zmienia skrót i wymaga nowej kompilacji obrazu. Podobnie każda zmiana w nadzorowanym środowisku powoduje utworzenie środowiska niestandardowego.
Uwaga
Nie będzie można przesłać żadnych lokalnych zmian w środowisku wyselekcjonowanych bez zmiany nazwy środowiska. Prefiksy "AzureML-" i "Microsoft" są zarezerwowane wyłącznie dla wyselekcjonowanych środowisk, a przesyłanie zadania zakończy się niepowodzeniem, jeśli nazwa zaczyna się od jednej z nich.
Obliczona wartość skrótu środowiska jest porównywana z skrótami w rejestrze kontenerów obszaru roboczego. Jeśli istnieje dopasowanie, buforowany obraz zostanie ściągnięty i użyty, w przeciwnym razie zostanie wyzwolona kompilacja obrazu.
Na poniższym diagramie przedstawiono trzy definicje środowiska. Dwa z nich mają różne nazwy i wersje, ale identyczne obrazy podstawowe i pakiety języka Python, co powoduje ten sam skrót i odpowiadający im obraz w pamięci podręcznej. Trzecie środowisko ma różne pakiety i wersje języka Python, co prowadzi do innego skrótu i buforowanego obrazu.
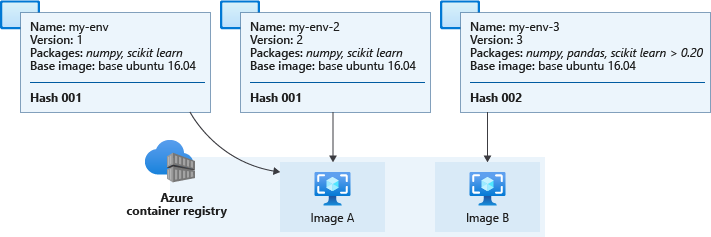
Rzeczywiste obrazy buforowane w rejestrze kontenerów obszaru roboczego mają nazwy podobne do azureml/azureml_e9607b2514b066c851012848913ba19f tych, które pojawiają się na końcu.
Ważne
Jeśli tworzysz środowisko z odpiętą zależnością pakietu (na przykład
numpy), środowisko używa wersji pakietu, która była dostępna podczas tworzenia środowiska. Każde przyszłe środowisko korzystające z zgodnej definicji będzie używać oryginalnej wersji.Aby zaktualizować pakiet, określ numer wersji, aby wymusić ponowne kompilowanie obrazu. Przykładem może być zmiana
numpywartości nanumpy==1.18.1. Nowe zależności — w tym zagnieżdżone — zostaną zainstalowane i mogą spowodować przerwanie wcześniej działającego scenariusza.Użycie przypiętego obrazu podstawowego, takiego jak
mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04w definicji środowiska, może spowodować ponowne skompilowanie obrazu za każdym razem, gdylatesttag jest aktualizowany. Ułatwia to obrazowi otrzymywanie najnowszych poprawek i aktualizacji systemowych.
Stosowanie poprawek obrazów
Firma Microsoft jest odpowiedzialna za stosowanie poprawek obrazów podstawowych pod kątem znanych luk w zabezpieczeniach. Aktualizacje obsługiwanych obrazów są wydawane co dwa tygodnie z zobowiązaniem niewłaszczanych luk w zabezpieczeniach starszych niż 30 dni w najnowszej wersji obrazu. Poprawione obrazy są wydawane przy użyciu nowego niezmiennego tagu, a :latest tag jest aktualizowany do najnowszej wersji poprawionego obrazu.
Musisz zaktualizować skojarzone zasoby usługi Azure Machine Learning, aby użyć nowo poprawionego obrazu. Na przykład podczas pracy z zarządzanym punktem końcowym online należy ponownie wdrożyć punkt końcowy, aby użyć poprawionego obrazu.
Jeśli udostępniasz własne obrazy, odpowiadasz za ich aktualizowanie i aktualizowanie zasobów usługi Azure Machine Learning, które ich używają.
Aby uzyskać więcej informacji na temat obrazów podstawowych, zobacz następujące linki:
- Repozytorium GitHub obrazów podstawowych usługi Azure Machine Learning.
- Wdrażanie modelu w punkcie końcowym online przy użyciu niestandardowego kontenera
- Zarządzanie środowiskami i obrazami kontenerów
Powiązana zawartość
- Dowiedz się, jak tworzyć środowiska i używać ich w usłudze Azure Machine Learning.
- Zobacz dokumentację referencyjną zestawu SDK języka Python dla klasy środowiska.