Wykrywanie obiektów przy użyciu szybkiej sieci R-CNN
Spis treści
- Podsumowanie
- Instalacja
- Uruchamianie przykładu toy
- Uruchamianie elementu Pascal VOC
- Trenowanie funkcji CNTK Fast R-CNN na własnych danych
- Szczegóły techniczne
- Szczegóły algorytmu
Podsumowanie

W tym samouczku opisano sposób używania funkcji CNTK Fast R-CNN z językiem BrainScript i cntk.exe. W tym miejscu opisano szybkie R-CNN przy użyciu interfejsu API języka Python CNTK.
Powyższe przykłady to obrazy i adnotacje obiektów dla zestawu danych spożywczych (pierwszy obraz) oraz zestaw danych Pascal VOC (drugi obraz) używany w tym samouczku.
Fast R-CNN to algorytm wykrywania obiektów proponowany przez Rossa Girshicka w 2015 roku. Dokument jest akceptowany do ICCV 2015 i archiwizowany pod adresem https://arxiv.org/abs/1504.08083. Szybka sieć R-CNN opiera się na poprzedniej pracy w celu wydajnego klasyfikowania propozycji obiektów przy użyciu głębokich sieci splotowych. W porównaniu z poprzednimi pracami funkcja Fast R-CNN wykorzystuje schemat puli zainteresowań , który umożliwia ponowne użycie obliczeń z warstw konwolucyjnych.
Dodatkowy materiał: szczegółowy samouczek dotyczący wykrywania obiektów przy użyciu funkcji CNTK Fast R-CNN z językiem BrainScript (w tym opcjonalne szkolenie SVM i publikowanie wytrenowanego modelu jako interfejsu API REST) można znaleźć tutaj.
Konfigurowanie
Aby uruchomić kod w tym przykładzie, potrzebujesz środowiska języka Python CNTK (zobacz tutaj , aby uzyskać pomoc dotyczącą konfiguracji). Ponadto należy zainstalować kilka dodatkowych pakietów. Przejdź do folderu FastRCNN i uruchom polecenie:
pip install -r requirements.txt
Znany problem: aby zainstalować bibliotekę scikit-learn, może być konieczne uruchomienie, jeśli używasz środowiska conda install scikit-learn Anaconda Python.
Aby uruchomić te przykłady, konieczne będzie dalsze Scikit-Image i OpenCV.
Pobierz odpowiednie pakiety kół i zainstaluj je ręcznie. W systemie Linux możesz conda install scikit-image opencv.
W przypadku użytkowników systemu Windows odwiedź stronę http://www.lfd.uci.edu/~gohlke/pythonlibs/i pobierz:
- Python 3.5
- scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
- opencv_python-3.2.0-cp35-cp35m-win_amd64.whl
Po pobraniu odpowiednich plików binarnych koła zainstaluj je za pomocą następujących elementów:
pip install your_download_folder/scikit_image-0.12.3-cp35-cp35m-win_amd64.whl
[! UWAGA]: jeśli podczas uruchamiania skryptów zostanie wyświetlony komunikat Brak modułu o nazwie past podczas uruchamiania skryptów, wykonaj pip install futurepolecenie .
W tym kodzie samouczka założono, że używasz 64-bitowej wersji języka Python 3.5 lub 3.6, ponieważ wymagane pliki DLL Fast R-CNN w ramach narzędzi są wstępnie utworzone dla tych wersji. Jeśli zadanie wymaga użycia innej wersji języka Python, przeprowadź ponowne skompiluj te pliki DLL samodzielnie w poprawnym środowisku (zobacz poniżej).
W samouczku założono, że folder, w którym znajduje się cntk.exe, znajduje się w zmiennej środowiskowej PATH. (Aby dodać folder do ścieżki, możesz uruchomić następujące polecenie z poziomu wiersza polecenia (przy założeniu, że folder, w którym cntk.exe znajduje się na maszynie, to C:\src\CNTK\x64\Release): set PATH=C:\src\CNTK\x64\Release;%PATH%.)
Wstępnie skompilowane pliki binarne na potrzeby regresji pola ograniczenia i braku maksymalnego pomijania
Folder Examples\Image\Detection\FastRCNN\BrainScript\fastRCNN\utils zawiera wstępnie skompilowane pliki binarne wymagane do uruchamiania szybkiej sieci R-CNN. Wersje, które są obecnie zawarte w repozytorium, to Python 3.5 i 3.6, wszystkie 64-bitowe. Jeśli potrzebujesz innej wersji, możesz ją skompilować, wykonując następujące kroki:
git clone --recursive https://github.com/rbgirshick/fast-rcnn.gitcd $FRCN_ROOT/libmakemakeZamiast tego można uruchomićpython setup.py build_ext --inplacez tego samego folderu. W systemie Windows może być konieczne skomentowanie dodatkowych args kompilowania w pliku lib/setup.py:
ext_modules = [ Extension( "utils.cython_bbox", ["utils/bbox.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ), Extension( "utils.cython_nms", ["utils/nms.pyx"], #extra_compile_args=["-Wno-cpp", "-Wno-unused-function"], ) ]skopiuj wygenerowane
cython_bboxplikicython_nmsbinarne z$FRCN_ROOT/lib/utilsdo$CNTK_ROOT/Examples/Image/Detection/fastRCNN/utils.
Przykładowy model danych i linii bazowej
Używamy wstępnie wytrenowanego modelu AlexNet jako podstawy trenowania Fast-R-CNN. Wstępnie wytrenowany AlexNet jest dostępny pod adresem https://www.cntk.ai/Models/AlexNet/AlexNet.model. Zapisz model pod adresem $CNTK_ROOT/PretrainedModels. Aby pobrać dane, uruchom polecenie
python install_grocery.py
z Examples/Image/DataSets/Grocery folderu .
Uruchamianie przykładu toy
W przykładzie toy trenujemy model CNTK Fast R-CNN w celu wykrywania przedmiotów spożywczych w lodówce.
Wszystkie wymagane skrypty znajdują się w elemecie $CNTK_ROOT/Examples/Image/Detection/FastRCNN/BrainScript.
Szybki przewodnik
Aby uruchomić przykład toy, upewnij się, że w parametrze jest PARAMETERS.pydataset ustawiona wartość "Grocery".
- Uruchom polecenie ,
A1_GenerateInputROIs.pyaby wygenerować wejściowe zwroty z inwestycji na potrzeby trenowania i testowania. - Uruchom polecenie
A2_RunWithBSModel.py, aby trenować i testować przy użyciu cntk.exe i BrainScript. - Uruchom polecenie ,
A3_ParseAndEvaluateOutput.pyaby obliczyć mAP (średnia precyzja) w wytrenowanego modelu.
Dane wyjściowe skryptu A3 powinny zawierać następujące elementy:
Evaluating detections
AP for avocado = 1.0000
AP for orange = 1.0000
AP for butter = 1.0000
AP for champagne = 1.0000
AP for eggBox = 0.7500
AP for gerkin = 1.0000
AP for joghurt = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
AP for onion = 1.0000
AP for pepper = 1.0000
AP for tomato = 0.7600
AP for water = 0.5000
AP for milk = 1.0000
AP for tabasco = 1.0000
AP for mustard = 1.0000
Mean AP = 0.9173
DONE.
Aby zwizualizować pola ograniczenia i przewidywane etykiety, można uruchomić B3_VisualizeOutputROIs.py (kliknij obrazy, aby powiększyć):





Szczegóły kroku
A1: Skrypt A1_GenerateInputROIs.py najpierw generuje kandydatów roI dla każdego obrazu przy użyciu wyszukiwania selektywnego.
Następnie przechowuje je w formacie tekstowym CNTK jako dane wejściowe dla cntk.exeelementu .
Ponadto są generowane wymagane pliki wejściowe CNTK dla obrazów i etykiet podstawowej prawdy.
Skrypt generuje następujące foldery i pliki w folderze FastRCNN :
proc- folder główny dla wygenerowanej zawartości.grocery_2000— zawiera wszystkie wygenerowane foldery i pliki dla przykładugroceryprzy użyciu2000zwrotu z inwestycji. Jeśli ponownie uruchomisz polecenie z inną liczbą zwrotów z inwestycji, nazwa folderu zmieni się odpowiednio.rois— zawiera pierwotne współrzędne ROI dla każdego obrazu przechowywanego w plikach tekstowych.cntkFiles— zawiera sformatowane pliki wejściowe CNTK dla obrazów (train.txtitest.txt), współrzędne ROI () i etykiety ROI (xx.rois.txtxx.roilabels.txt) dlatrainitest. ( Poniżej podano szczegóły formatu).
Wszystkie parametry są zawarte w elemencie PARAMETERS.py, na przykład zmień, cntk_nrRois = 2000 aby ustawić liczbę zwrotów z inwestycji używanych do trenowania i testowania. W sekcji Parametry poniżej opisano parametry.
A2: Skrypt A2_RunWithBSModel.py uruchamia plik cntk przy użyciu cntk.exe i pliku konfiguracji BrainScript (szczegóły konfiguracji).
Wytrenowany model jest przechowywany w folderze odpowiedniego proc podfolderucntkFiles/Output.
Wytrenowany model jest testowany oddzielnie zarówno w zestawie treningowym, jak i w zestawie testowym.
Podczas testowania dla każdego obrazu i każdego odpowiadającego mu zwrotu z inwestycji etykieta jest przewidywana i przechowywana w plikach test.z i train.z w folderze cntkFiles .
A3: Krok oceny analizuje dane wyjściowe CNTK i oblicza protokół mAP porównujący przewidywane wyniki z adnotacjami podstawowej prawdy.
Brak maksymalnego pomijania służy do scalania nakładających się zwrotów z inwestycji. Możesz ustawić próg braku maksymalnego pomijania w pliku PARAMETERS.py (szczegóły).
Dodatkowe skrypty
Istnieją trzy opcjonalne skrypty, które można uruchomić, aby wizualizować i analizować dane:
B1_VisualizeInputROIs.pywizualizuje dane roI danych wejściowych kandydata.B2_EvaluateInputROIs.pyoblicza wycofanie podstawowych wskaźników zwrotu z inwestycji w odniesieniu do istotnych zwrotów z inwestycji.B3_VisualizeOutputROIs.pywizualizowanie pól ograniczenia i przewidywanych etykiet.
Uruchamianie elementu Pascal VOC
Dane pascal VOC (PASCAL Visual Object Classes) to dobrze znany zestaw standardowych obrazów do rozpoznawania klas obiektów. Trenowanie lub testowanie CNTK Fast R-CNN na danych Pascal VOC wymaga procesora GPU z co najmniej 4 GB pamięci RAM. Alternatywnie można uruchomić przy użyciu procesora CPU, co zajmie jednak trochę czasu.
Pobieranie danych VOC Pascal
Potrzebne są dane z 2007 r. (trainval and test) i 2012 (trainval), a także wstępnie skompilowane zwroty z inwestycji używane w oryginalnym dokumencie.
Należy postępować zgodnie ze strukturą folderów opisaną poniżej.
Skrypty zakładają, że dane Pascal znajdują się w obiekcie $CNTK_ROOT/Examples/Image/DataSets/Pascal.
Jeśli używasz innego folderu, ustaw pascalDataDir go odpowiednio PARAMETERS.py .
- Pobierz i rozpakuj dane 2012 trainval do
DataSets/Pascal/VOCdevkit2012- Stronie internetowej: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
- Devkit: http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
- Pobierz i rozpakuj dane 2007 trainval do
DataSets/Pascal/VOCdevkit2007- Stronie internetowej: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
- Devkit: http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
- Pobieranie i rozpakowywanie danych testowych 2007 do tego samego folderu
DataSets/Pascal/VOCdevkit2007 - Pobierz i rozpakuj wstępnie skompilowane zwroty z inwestycji do
DataSets/Pascal/selective_search_data* http://dl.dropboxusercontent.com/s/orrt7o6bp6ae0tc/selective_search_data.tgz?dl=0
Folder VOCdevkit2007 powinien wyglądać następująco (podobnie w przypadku wersji 2012):
VOCdevkit2007/VOC2007
VOCdevkit2007/VOC2007/Annotations
VOCdevkit2007/VOC2007/ImageSets
VOCdevkit2007/VOC2007/JPEGImages
Uruchamianie CNTK na Pascal VOC
Aby uruchomić polecenie na danych Pascal VOC, upewnij się, że w PARAMETERS.pydataset parametrze jest ustawiona "pascal"wartość .
- Uruchom polecenie
A1_GenerateInputROIs.py, aby wygenerować pliki wejściowe w formacie CNTK na potrzeby trenowania i testowania na podstawie pobranych danych zwrotu z inwestycji. - Uruchom polecenie
A2_RunWithBSModel.py, aby wytrenować model Fast R-CNN i wyniki testu obliczeniowego. - Uruchom polecenie
A3_ParseAndEvaluateOutput.py, aby obliczyć mAP (średnia precyzja) w wytrenowanego modelu.- Należy pamiętać, że jest to praca w toku, a wyniki są wstępne, ponieważ trenujemy nowe modele linii bazowej.
- Upewnij się, że masz najnowszą wersję wzorca CNTK dla plików fastRCNN/pascal_voc.py i fastRCNN/voc_eval.py , aby uniknąć błędów kodowania.
Trenowanie na własnych danych
Przygotowywanie niestandardowego zestawu danych
Opcja 1: Narzędzie tagowania obiektów wizualnych (zalecane)
Visual Object Tagging Tool (VOTT) to międzyplatformowe narzędzie adnotacji do tagowania zasobów wideo i obrazów.

Usługa VOTT udostępnia następujące funkcje:
- Wspomagane komputerowo tagowanie i śledzenie obiektów w filmach wideo przy użyciu algorytmu śledzenia camshift.
- Eksportowanie tagów i zasobów do formatu CNTK Fast-RCNN na potrzeby trenowania modelu wykrywania obiektów.
- Uruchamianie i weryfikowanie wytrenowanego modelu wykrywania obiektów CNTK na nowych filmach wideo w celu wygenerowania silniejszych modeli.
Jak dodawać adnotacje za pomocą usługi VOTT:
- Pobierz najnowszą wersję
- Postępuj zgodnie z poleceniem Readme , aby uruchomić zadanie tagowania
- Po oznaczeniu tagami Eksportuj tagi do katalogu zestawu danych
Opcja 2. Używanie skryptów adnotacji
Aby wytrenować model CNTK Fast R-CNN na własnym zestawie danych, udostępniamy dwa skrypty do dodawania adnotacji do regionów prostokątnych na obrazach i przypisywania etykiet do tych regionów.
Skrypty będą przechowywać adnotacje w poprawnym formacie zgodnie z wymaganiami pierwszego kroku uruchamiania funkcji Fast R-CNN (A1_GenerateInputROIs.py).
Najpierw zapisz obrazy w następującej strukturze folderów
<your_image_folder>/negative— obrazy używane do trenowania, które nie zawierają żadnych obiektów<your_image_folder>/positive- obrazy używane do trenowania, które zawierają obiekty<your_image_folder>/testImages- obrazy używane do testowania, które zawierają obiekty
W przypadku obrazów ujemnych nie trzeba tworzyć żadnych adnotacji. W przypadku pozostałych dwóch folderów użyj podanych skryptów:
- Uruchom polecenie
C1_DrawBboxesOnImages.py, aby narysować pola ograniczenia na obrazach.- Przed uruchomieniem zestawu skryptów
imgDir = <your_image_folder>(/positivelub/testImages). - Dodaj adnotacje przy użyciu kursora myszy. Gdy wszystkie obiekty na obrazie są oznaczone adnotacjami, naciśnięcie klawisza "n" zapisuje plik .bboxes.txt, a następnie przechodzi do następnego obrazu, "u" cofa (tj. usuwa) ostatni prostokąt, a "q" zamyka narzędzie adnotacji.
- Przed uruchomieniem zestawu skryptów
- Uruchom polecenie ,
C2_AssignLabelsToBboxes.pyaby przypisać etykiety do pól ograniczenia.- W zestawie
imgDir = <your_image_folder>skryptów (/positivelub/testImages) przed uruchomieniem... - ... i dostosuj klasy w skryptzie, aby odzwierciedlały kategorie obiektów, na przykład
classes = ("dog", "cat", "octopus"). - Skrypt ładuje te ręcznie adnotacje prostokąty dla każdego obrazu, wyświetla je jeden po drugim i prosi użytkownika o podanie klasy obiektu, klikając odpowiedni przycisk po lewej stronie okna. Adnotacje prawdy podstawowej oznaczone jako "niezdecydowane" lub "wykluczanie" są w pełni wykluczone z dalszego przetwarzania.
- W zestawie
Trenowanie w niestandardowym zestawie danych
Przed uruchomieniem sieci CNN CNTK Fast R-CNN przy użyciu skryptów A1-A3 należy dodać zestaw danych do :PARAMETERS.py
- Ustawić
dataset = "CustomDataset" - Dodaj parametry zestawu danych w klasie
CustomDatasetPython . Możesz zacząć od skopiowania parametrów zGroceryParameters- Dostosuj klasy , aby odzwierciedlały kategorie obiektów. W powyższym przykładzie będzie to wyglądać następująco:
self.classes = ('__background__', 'dog', 'cat', 'octopus'). - Ustaw wartość
self.imgDir = <your_image_folder>. - Opcjonalnie można dostosować więcej parametrów, np. generowania zwrotu z inwestycji i oczyszczania (zobacz sekcję Parametry ).
- Dostosuj klasy , aby odzwierciedlały kategorie obiektów. W powyższym przykładzie będzie to wyglądać następująco:
Wszystko jest gotowe do trenowania na własnych danych. (Użyj tych samych kroków co w przykładzie z toną).
Szczegóły techniczne
Parametry
Główne parametry w pliku PARAMETERS.py to:
dataset— który zestaw danych ma być używanycntk_nrRois— ile zwrotów z inwestycji ma być używanych do trenowania i testowanianmsThreshold- Próg braku maksymalnej pomijania (w zakresie [0,1]). Im niższa będzie większa zwrot z inwestycji, zostanie połączona. Jest on używany zarówno do oceny, jak i wizualizacji.
Wszystkie parametry generowania zwrotu z inwestycji, takie jak minimalna i maksymalna szerokość i wysokość itp., są opisane w PARAMETERS.py klasie ParametersJęzyka Python. Wszystkie są ustawione na wartość domyślną, która jest rozsądna.
Możesz zastąpić je w # project-specific parameters sekcji odpowiadającej używanemu zestawowi danych.
Konfiguracja CNTK
Plik konfiguracji CNTK BrainScript używany do trenowania i testowania fast R-CNN to fastrcnn.cntk.
Część, która konstruuje sieć, to BrainScriptNetworkBuilder sekcja w poleceniu Train :
BrainScriptNetworkBuilder = {
network = BS.Network.Load ("../../../../../../../PretrainedModels/AlexNet.model")
convLayers = BS.Network.CloneFunction(network.features, network.conv5_y, parameters = "constant")
fcLayers = BS.Network.CloneFunction(network.pool3, network.h2_d)
model (features, rois) = {
featNorm = features - 114
convOut = convLayers (featNorm)
roiOut = ROIPooling (convOut, rois, (6:6))
fcOut = fcLayers (roiOut)
W = ParameterTensor{($NumLabels$:4096), init="glorotUniform"}
b = ParameterTensor{$NumLabels$, init = 'zero'}
z = W * fcOut + b
}.z
imageShape = $ImageH$:$ImageW$:$ImageC$ # 1000:1000:3
labelShape = $NumLabels$:$NumTrainROIs$ # 21:64
ROIShape = 4:$NumTrainROIs$ # 4:64
features = Input {imageShape}
roiLabels = Input {labelShape}
rois = Input {ROIShape}
z = model (features, rois)
ce = CrossEntropyWithSoftmax(roiLabels, z, axis = 1)
errs = ClassificationError(roiLabels, z, axis = 1)
featureNodes = (features:rois)
labelNodes = (roiLabels)
criterionNodes = (ce)
evaluationNodes = (errs)
outputNodes = (z)
}
W pierwszym wierszu wstępnie wytrenowany AlexNet jest ładowany jako model podstawowy. Następne dwie części sieci są klonowane: convLayers zawiera warstwy splotowe ze stałymi wagami, tj. nie są one dalej trenowane.
fcLayers zawiera w pełni połączone warstwy ze wstępnie wytrenowanym wagami, które zostaną wytrenowane dalej.
Nazwy network.featuresnetwork.conv5_y węzłów itp. można uzyskać na podstawie danych wyjściowych dziennika wywołania cntk.exe (zawartego w danych wyjściowych dziennika skryptuA2_RunWithBSModel.py).
Definicja modelu (model (features, rois) = ...) najpierw normalizuje funkcje, odejmując 114 dla każdego kanału i piksela.
Następnie znormalizowane funkcje są wypychane convLayers przez element ROIPooling i na fcLayerskoniec .
Kształt danych wyjściowych (width:height) warstwy puli ROI jest ustawiony na (6:6) wartość , ponieważ jest to drugi rozmiar kształtu, którego oczekuje wstępnie wytrenowany fcLayers model AlexNet. Dane wyjściowe obiektu fcLayers są przekazywane do gęstej warstwy, która przewiduje jedną wartość na etykietę (NumLabels) dla każdego zwrotu z inwestycji.
Następujące sześć wierszy definiuje dane wejściowe:
- obraz o rozmiarze 1000 x 1000 x 3 (
$ImageH$:$ImageW$:$ImageC$), - podstawowe etykiety prawdy dla każdego zwrotu z inwestycji (
$NumLabels$:$NumTrainROIs$) - i cztery współrzędne na roi (
4:$NumTrainROIs$) odpowiadające (x, y, w, h), wszystkie względne względem pełnej szerokości i wysokości obrazu.
z = model (features, rois)Przesyła obrazy wejściowe i zwroty z inwestycji do zdefiniowanego modelu sieciowego i przypisuje dane wyjściowe do .z
Zarówno kryterium (CrossEntropyWithSoftmax), jak i błąd (ClassificationError) są określone za pomocą axis = 1 polecenia , aby uwzględnić błąd przewidywania na zwrot z inwestycji.
Poniżej wymieniono sekcję czytelnika konfiguracji CNTK. Używa trzech deserializatorów:
ImageDeserializeraby odczytać dane obrazu. Pobiera on nazwy plików obrazu ztrain.txt, skaluje obraz do żądanej szerokości i wysokości przy zachowaniu współczynnika proporcji (dopełnianie pustych obszarów114za pomocą ) i transponuje tensor do prawidłowego kształtu wejściowego.- Jeden
CNTKTextFormatDeserializerdo odczytania współrzędnych zwrotu z .train.rois.txt - Sekunda
CNTKTextFormatDeserializerodczytu etykiet zwrotu z inwestycji z .train.roislabels.txt
Formaty plików wejściowych zostały opisane w następnej sekcji.
reader = {
randomize = false
verbosity = 2
deserializers = ({
type = "ImageDeserializer" ; module = "ImageReader"
file = train.txt
input = {
features = { transforms = (
{ type = "Scale" ; width = $ImageW$ ; height = $ImageW$ ; channels = $ImageC$ ; scaleMode = "pad" ; padValue = 114 }:
{ type = "Transpose" }
)}
ignored = {labelDim = 1000}
}
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.rois.txt
input = { rois = { dim = $TrainROIDim$ ; format = "dense" } }
}:{
type = "CNTKTextFormatDeserializer" ; module = "CNTKTextFormatReader"
file = train.roilabels.txt
input = { roiLabels = { dim = $TrainROILabelDim$ ; format = "dense" } }
})
}
Format pliku wejściowego CNTK
Istnieją trzy pliki wejściowe dla nazwy CNN CNN CNTK Fast R-CNN odpowiadające trzem deserializatorom opisanym powyżej:
train.txtElement zawiera w każdym wierszu najpierw numer sekwencji, a następnie nazwy plików obrazów, a na koniec znak0(który jest obecnie nadal potrzebny ze starszych powodów elementu ImageReader).
0 image_01.jpg 0
1 image_02.jpg 0
...
train.rois.txt(Format tekstu CNTK) zawiera w każdym wierszu najpierw numer sekwencji, a następnie|roisidentyfikator, po którym następuje sekwencja liczb. Są to grupy czterech liczb odpowiadających (x, y, w, h) zwrotu z inwestycji, wszystkie względne względem pełnej szerokości i wysokości obrazu. Istnieje łącznie 4 * liczba numerów rois na wiersz.
0 |rois 0.2185 0.0 0.165 0.29 ...
train.roilabels.txt(Format tekstu CNTK) zawiera w każdym wierszu najpierw numer sekwencji, a następnie|roiLabelsidentyfikator, po którym następuje sekwencja liczb. Są to grupy liczb z liczbami etykiet (zero lub jeden) na roI kodując klasę prawdy naziemnej w reprezentacji z gorącą jedyną wartością. Istnieje łączna liczba etykiet * liczba numerów rois na wiersz.
0 |roiLabels 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ...
Szczegóły algorytmu
Szybka nazwa sieci R-CNN
R-CNNs for Object Detection zostały po raz pierwszy przedstawione w 2014 roku przez RossA Girshick et al., i pokazano, aby przewyższać poprzednie najnowocześniejsze podejścia do jednego z głównych wyzwań rozpoznawania obiektów w tej dziedzinie: Pascal VOC. Od tego czasu opublikowano dwa dokumenty kontynuacji, które zawierają znaczące ulepszenia prędkości: Fast R-CNN i Faster R-CNN.
Podstawową ideą R-CNN jest utworzenie głębokiej sieci neuronowej, która została pierwotnie wytrenowana do klasyfikacji obrazów przy użyciu milionów obrazów z adnotacjami i zmodyfikowania jej w celu wykrywania obiektów. Podstawowy pomysł z pierwszego papieru R-CNN jest przedstawiony na rysunku poniżej (pobrany z papieru): (1) Biorąc pod uwagę obraz wejściowy, (2) w pierwszym kroku, generowanych jest duża liczba propozycji regionów. (3) Te propozycje regionów lub regiony interesów (ROI) są następnie niezależnie wysyłane za pośrednictwem sieci, która generuje wektor 4096 wartości zmiennoprzecinkowych dla każdego zwrotu. Na koniec (4) klasyfikator uczy się, który przyjmuje reprezentację roI zmiennoprzecinkowego 4096 jako dane wejściowe i wyjściowe etykietę oraz pewność siebie dla każdego zwrotu z inwestycji.
Chociaż takie podejście działa dobrze pod względem dokładności, obliczenia są bardzo kosztowne, ponieważ sieć neuronowa musi być oceniana dla każdego zwrotu z inwestycji. Szybka sieć R-CNN rozwiązuje tę wadę, oceniając tylko większość sieci (aby być specyficzna: warstwy konwolucji) pojedynczo na obraz. Według autorów, prowadzi to do 213-krotnego przyspieszenia podczas testowania i 9-krotnego przyspieszenia podczas trenowania bez utraty dokładności. Jest to osiągane przy użyciu warstwy puli ROI, która projektuje zwrot z inwestycji na mapie funkcji splotowych i wykonuje maksymalną pulę w celu wygenerowania żądanego rozmiaru danych wyjściowych oczekiwanego przez następującą warstwę. W przykładzie AlexNet używanym w tym samouczku warstwa buforowania roI jest umieszczana między ostatnią warstwą splotu a pierwszą w pełni połączoną warstwą (zobacz kod BrainScript).
Oryginalna implementacja Caffe używana w dokumentach R-CNN można znaleźć w witrynie GitHub: RCNN, Fast R-CNN i Faster R-CNN. W tym samouczku użyto kodu z tych repozytoriów, zwłaszcza (ale nie wyłącznie) na potrzeby trenowania maszyn wirtualnych i oceny modelu.
Trenowanie svm vs NN
Patrick Buehler zawiera instrukcje dotyczące trenowania maszyny nośnej na danych wyjściowych CNTK Fast R-CNN (przy użyciu funkcji 4096 z ostatniej w pełni połączonej warstwy), a także dyskusji na temat zalet i wad tutaj.
Wyszukiwanie selektywne
Wyszukiwanie selektywne to metoda znajdowania dużego zestawu możliwych lokalizacji obiektów na obrazie niezależnie od klasy rzeczywistego obiektu. Działa przez klastrowanie pikseli obrazu w segmenty, a następnie wykonywanie klastrowania hierarchicznego w celu łączenia segmentów z tego samego obiektu w propozycje obiektów.



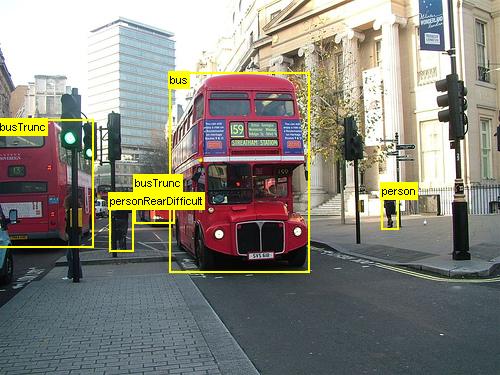
Aby uzupełnić wykryte zwroty z wyszukiwania selektywnego, dodamy wskaźniki ROI, które jednolite obejmują obraz w różnych skalach i współczynnikach proporcji. Pierwszy obraz przedstawia przykładowe dane wyjściowe wyszukiwania selektywnego, gdzie każda możliwa lokalizacja obiektu jest wizualizowana przez zielony prostokąt. Zwroty z inwestycji, które są zbyt małe, zbyt duże itp., są odrzucane (drugi obraz) i wreszcie zwroty z inwestycji, które jednolicie pokrywają obraz, są dodawane (trzeci obraz). Te prostokąty są następnie używane jako regiony zainteresowań (ROI) w potoku R-CNN.
Celem generowania roI jest znalezienie małego zestawu zwrotów z inwestycji, które jednak ściśle obejmują jak najwięcej obiektów na obrazie. To obliczenie musi być wystarczająco szybkie, a jednocześnie znajdowanie lokalizacji obiektów w różnych skalach i współczynnikach proporcji. Wyszukiwanie selektywne zostało pokazane, aby dobrze wykonać to zadanie, z dobrą dokładnością do przyspieszenia kompromisów.
NMS (bez maksymalnego pomijania)
Metody wykrywania obiektów często generują wiele wykryć, które w pełni lub częściowo obejmują ten sam obiekt na obrazie.
Te zwroty z inwestycji należy scalić, aby móc zliczać obiekty i uzyskiwać ich dokładne lokalizacje na obrazie.
Jest to tradycyjnie wykonywane przy użyciu techniki o nazwie Non Maximum Suppression (NMS). Używana wersja NMS (i używana również w publikacjach R-CNN) nie scala zwrotów z inwestycji, ale zamiast tego próbuje zidentyfikować, które wskaźniki ROI najlepiej obejmują rzeczywiste lokalizacje obiektu i odrzuca wszystkie inne zwroty z inwestycji. Jest to implementowane przez iteracyjne wybieranie zwrotu z najwyższą ufnością i usuwanie wszystkich innych zwrotów z inwestycji, które znacząco nakładają się na ten zwrot i są klasyfikowane jako tej samej klasy. Próg nakładania się można ustawić w PARAMETERS.py (szczegóły).
Wyniki wykrywania przed (pierwszy obraz) i po (drugi obraz) Bez maksymalnej pomijania:

mAP (średnia precyzja)
Po wytrenowanym jakości modelu można mierzyć przy użyciu różnych kryteriów, takich jak precyzja, kompletność, dokładność, krzywa pod powierzchnią itp. Typową metryką używaną dla wyzwania rozpoznawania obiektów Pascal VOC jest pomiar średniej precyzji (AP) dla każdej klasy. Poniższy opis średniej precyzji jest pobierany z Everingham i in. Średnia precyzja (mAP) jest obliczana przez przejęcie średniej na poziomie APs wszystkich klas.
Dla danego zadania i klasy krzywa precyzji/kompletności jest obliczana na podstawie danych wyjściowych sklasyfikowanych przez metodę. Kompletność jest definiowana jako proporcja wszystkich pozytywnych przykładów sklasyfikowanych powyżej danej rangi. Precyzja jest proporcją wszystkich przykładów powyżej tej rangi, która pochodzi z klasy dodatniej. Ap podsumowuje kształt krzywej precyzji/kompletności i jest definiowany jako średnia precyzja w zestawie 10 poziomów odwołań o równym odstępie [0,0,1, . . . ,1]:
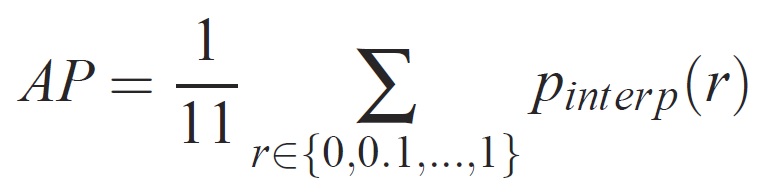
Precyzja na każdym poziomie odwołania r jest interpolowana przez zastosowanie maksymalnej dokładności mierzonej dla metody, dla której odpowiednie wycofanie przekracza r:
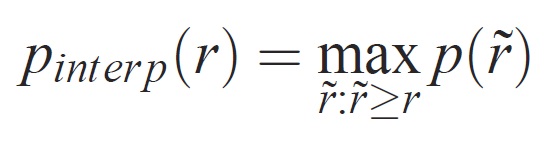
gdzie p( ̃r) jest mierzoną dokładnością przy odwołaniu ̃r. Celem interpolowania krzywej precyzji/kompletności w ten sposób jest zmniejszenie wpływu "wiggles" w krzywej precyzji/kompletności, spowodowane małymi różnicami w rankingu przykładów. Należy zauważyć, że aby uzyskać wysoką ocenę, metoda musi mieć precyzję na wszystkich poziomach kompletności — te metody karzeją, które pobierają tylko podzestaw przykładów o wysokiej precyzji (np. widoki boczne samochodów).