Wykrywanie obiektów przy użyciu szybkiej sieci R-CNN
Spis treści
- Podsumowanie
- Instalacja
- Uruchamianie przykładu toy
- Trenowanie na danych Pascal VOC
- Trenowanie funkcji CNTK Fast R-CNN na własnych danych
- Szczegóły techniczne
- Szczegóły algorytmu
Podsumowanie

W tym samouczku opisano, jak używać szybkiej nazwy R-CNN w interfejsie API języka Python CNTK. W tym miejscu opisano szybkie R-CNN przy użyciu języka BrainScript i cnkt.exe.
Poniżej przedstawiono przykłady obrazów i adnotacji obiektów dla zestawu danych spożywczych (po lewej) oraz zestawu danych Pascal VOC (po prawej) używanego w tym samouczku.
Fast R-CNN to algorytm wykrywania obiektów proponowany przez Rossa Girshicka w 2015 roku. Dokument jest akceptowany do ICCV 2015 i archiwizowany pod adresem https://arxiv.org/abs/1504.08083. Szybka sieć R-CNN opiera się na poprzedniej pracy w celu wydajnego klasyfikowania propozycji obiektów przy użyciu głębokich sieci splotowych. W porównaniu z poprzednimi pracami funkcja Fast R-CNN wykorzystuje schemat puli zainteresowań , który umożliwia ponowne użycie obliczeń z warstw konwolucyjnych.
Konfigurowanie
Aby uruchomić kod w tym przykładzie, potrzebujesz środowiska języka Python CNTK (zobacz tutaj , aby uzyskać pomoc dotyczącą konfiguracji). Zainstaluj następujące dodatkowe pakiety w środowisku języka Python cntk
pip install opencv-python easydict pyyaml dlib
Wstępnie skompilowane pliki binarne na potrzeby regresji pola ograniczenia i braku maksymalnego pomijania
Folder Examples\Image\Detection\utils\cython_modules zawiera wstępnie skompilowane pliki binarne wymagane do uruchamiania szybkiej sieci R-CNN. Wersje, które są obecnie zawarte w repozytorium, to Python 3.5 dla systemów Windows i Python 3.5, 3.6 dla systemu Linux, wszystkie 64-bitowe. Jeśli potrzebujesz innej wersji, możesz ją skompilować, wykonując kroki opisane w temacie
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Skopiuj wygenerowane cython_bbox pliki binarne i cpu_nms (i/lub gpu_nms) z $FRCN_ROOT/lib/utils do $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules.
Przykładowy model danych i linii bazowej
Używamy wstępnie wytrenowanego modelu AlexNet jako podstawy trenowania Fast-R-CNN (w przypadku modeli VGG lub innych modeli bazowych zobacz Korzystanie z innego modelu podstawowego. Przykładowy zestaw danych i wstępnie wytrenowany model AlexNet można pobrać, uruchamiając następujące polecenie języka Python z folderu FastRCNN:
python install_data_and_model.py
- Dowiedz się, jak używać innego modelu podstawowego
- Dowiedz się, jak uruchomić fast R-CNN na danych Pascal VOC
- Dowiedz się, jak uruchomić fast R-CNN na własnych danych
Uruchamianie przykładu toy
Aby wytrenować i ocenić szybkie uruchomienie R-CNN
python run_fast_rcnn.py
Wyniki trenowania z 2000 zwrotami z inwestycji w artykułach spożywczych przy użyciu AlexNet jako modelu podstawowego powinny wyglądać podobnie do następujących:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
Aby zwizualizować przewidywane pola ograniczenia i etykiety na obrazach otwarte FastRCNN_config.py z FastRCNN folderu i ustawić
__C.VISUALIZE_RESULTS = True
Jeśli uruchomisz polecenie python run_fast_rcnn.py, obrazy zostaną zapisane w folderze FastRCNN/Output/Grocery/ .
Trenowanie na VOC Pascal
Aby pobrać dane Pascal i utworzyć pliki adnotacji dla pascala w formacie CNTK, uruchom następujące skrypty:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
Zmień metodę dataset_cfg w metodzie run_fast_rcnn.pyget_configuration() na
from utils.configs.Pascal_config import cfg as dataset_cfg
Teraz ustawisz trenowanie danych Pascal VOC 2007 przy użyciu polecenia python run_fast_rcnn.py. Uważaj, że trenowanie może zająć trochę czasu.
Trenowanie na własnych danych
Przygotowywanie niestandardowego zestawu danych
Opcja #1: Narzędzie tagowania obiektów wizualnych (zalecane)
Narzędzie do tagowania obiektów wizualnych (VOTT) to wieloplatformowe narzędzie adnotacji do tagowania zasobów wideo i obrazów.

Usługa VOTT udostępnia następujące funkcje:
- Wspomagane komputerowo tagowanie i śledzenie obiektów w filmach wideo przy użyciu algorytmu śledzenia Camshift.
- Eksportowanie tagów i zasobów do formatu CNTK Fast-RCNN na potrzeby trenowania modelu wykrywania obiektów.
- Uruchamianie i weryfikowanie wytrenowanego modelu wykrywania obiektów CNTK na nowych filmach wideo w celu wygenerowania silniejszych modeli.
Jak dodawać adnotacje za pomocą usługi VOTT:
- Pobieranie najnowszej wersji
- Postępuj zgodnie z instrukcjami Readme , aby uruchomić zadanie tagowania
- Po tagowaniu eksportu tagów do katalogu zestawu danych
Opcja #2: Używanie skryptów adnotacji
Aby wytrenować model CNTK Fast R-CNN na własnym zestawie danych, udostępniamy dwa skrypty do dodawania adnotacji do regionów prostokątnych na obrazach i przypisywania etykiet do tych regionów.
Skrypty będą przechowywać adnotacje w poprawnym formacie zgodnie z wymaganiami pierwszego kroku uruchamiania szybkiej sieci R-CNN (A1_GenerateInputROIs.py).
Najpierw zapisz obrazy w następującej strukturze folderów
<your_image_folder>/negative— obrazy używane do trenowania, które nie zawierają żadnych obiektów<your_image_folder>/positive— obrazy używane do trenowania zawierającego obiekty<your_image_folder>/testImages— obrazy używane do testowania, które zawierają obiekty
W przypadku obrazów ujemnych nie trzeba tworzyć żadnych adnotacji. W przypadku pozostałych dwóch folderów użyj podanych skryptów:
- Uruchom polecenie ,
C1_DrawBboxesOnImages.pyaby narysować pola ograniczenia na obrazach.- Przed uruchomieniem zestawu
imgDir = <your_image_folder>skryptów (/positivelub/testImages). - Dodaj adnotacje przy użyciu kursora myszy. Gdy wszystkie obiekty na obrazie są oznaczone adnotacją, naciśnięcie klawisza "n" zapisuje plik .bboxes.txt, a następnie przechodzi do następnego obrazu, "u" cofa (tj. usuwa) ostatni prostokąt, a "q" kończy narzędzie adnotacji.
- Przed uruchomieniem zestawu
- Uruchom polecenie ,
C2_AssignLabelsToBboxes.pyaby przypisać etykiety do pól ograniczenia.- W zestawie
imgDir = <your_image_folder>skryptów (/positivelub/testImages) przed uruchomieniem... - ... i dostosuj klasy w skryptze, aby odzwierciedlały kategorie obiektów, na przykład
classes = ("dog", "cat", "octopus"). - Skrypt ładuje te ręcznie oznaczone prostokąty dla każdego obrazu, wyświetla je jeden po jednym i prosi użytkownika o podanie klasy obiektu, klikając odpowiedni przycisk po lewej stronie okna. Adnotacje podstawowej prawdy oznaczone jako "niezdecydowane" lub "wykluczanie" są w pełni wykluczone z dalszego przetwarzania.
- W zestawie
Trenowanie na niestandardowym zestawie danych
Po zapisaniu obrazów w opisanej strukturze folderów i dodawaniu do nich adnotacji uruchom polecenie
python Examples/Image/Detection/utils/annotations/annotations_helper.py
po zmianie folderu w tym skrycie na folder danych. Na koniec utwórz element MyDataSet_config.py w folderze utils\configs poniżej istniejących przykładów:
__C.CNTK.DATASET == "YourDataSet":
__C.CNTK.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.CNTK.CLASS_MAP_FILE = "class_map.txt"
__C.CNTK.TRAIN_MAP_FILE = "train_img_file.txt"
__C.CNTK.TEST_MAP_FILE = "test_img_file.txt"
__C.CNTK.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.CNTK.TEST_ROI_FILE = "test_roi_file.txt"
__C.CNTK.NUM_TRAIN_IMAGES = 500
__C.CNTK.NUM_TEST_IMAGES = 200
__C.CNTK.PROPOSAL_LAYER_SCALES = [8, 16, 32]
Należy pamiętać, że __C.CNTK.PROPOSAL_LAYER_SCALES nie jest używany do szybkiego R-CNN, tylko dla szybszego R-CNN.
Aby wytrenować i ocenić szybką nazwę R-CNN na danych, zmień metodę dataset_cfgget_configuration() na run_fast_rcnn.py
from utils.configs.MyDataSet_config import cfg as dataset_cfg
i uruchom polecenie python run_fast_rcnn.py.
Szczegóły techniczne
Algorytm Fast R-CNN jest objaśniony w sekcji Szczegóły algorytmu wraz z ogólnym omówieniem sposobu implementacji w interfejsie API języka Python CNTK. Ta sekcja koncentruje się na konfigurowaniu szybkiej sieci R-CNN i sposobie używania różnych modeli bazowych.
Parametry
Parametry są pogrupowane w trzy części:
- Parametry narzędzia do wykrywania (zobacz
FastRCNN/FastRCNN_config.py) - Parametry zestawu danych (zobacz na przykład
utils/configs/Grocery_config.py) - Podstawowe parametry modelu (zobacz na przykład
utils/configs/AlexNet_config.py)
Trzy części są ładowane i scalane w metodzie get_configuration() w pliku run_fast_rcnn.py. W tej sekcji omówimy parametry detektora. Parametry zestawu danych są opisane tutaj, podstawowe parametry modelu tutaj. W poniższej sekcji przejdąśmy przez najważniejsze parametry w FastRCNN_config.pypliku . Wszystkie parametry są również komentowane w pliku. Konfiguracja używa EasyDict pakietu, który umożliwia łatwy dostęp do zagnieżdżonych słowników.
# Number of regions of interest [ROIs] proposals
__C.NUM_ROI_PROPOSALS = 200 # use 2000 or more for good results
# the minimum IoU (overlap) of a proposal to qualify for training regression targets
__C.BBOX_THRESH = 0.5
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
Propozycje zwrotu z inwestycji są obliczane na bieżąco w pierwszej epoce przy użyciu implementacji wyszukiwania selektywnego dlib z pakietu. Liczba generowanych propozycji jest kontrolowana przez __C.NUM_ROI_PROPOSALS parametr . Zalecamy użycie około 2000 propozycji. Głowica regresji jest trenowana tylko na tych zwrotach z inwestycji, które mają nakładające się (IoU) z prawem do ziemi pole co najmniej __C.BBOX_THRESH.
__C.INPUT_ROIS_PER_IMAGE określa maksymalną liczbę adnotacji prawdy podstawowej na obraz. CnTK obecnie wymaga ustawienia maksymalnej liczby. Jeśli istnieje mniej adnotacji, zostaną one wypełnione wewnętrznie. __C.IMAGE_WIDTH i __C.IMAGE_HEIGHT są wymiarami używanymi do zmiany rozmiaru i wypełnienia obrazów wejściowych.
__C.TRAIN.USE_FLIPPED = True Rozszerzy dane treningowe przez przerzucanie wszystkich obrazów co drugą epokę, tj. pierwsza epoka ma wszystkie zwykłe obrazy, drugi ma przerzucane obrazy itd. __C.TRAIN_CONV_LAYERS określa, czy warstwy konwolucyjne, od danych wejściowych do mapy funkcji splotowych, zostaną wytrenowane lub naprawione. Naprawianie wagi warstw konwowych oznacza, że wagi z modelu podstawowego są pobierane i nie są modyfikowane podczas trenowania. (Możesz również określić liczbę warstw konwerowych, które chcesz wytrenować, zobacz sekcję Using a different base model (Korzystanie z innego modelu bazowego).
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# If set to True the following two parameters need to point to the corresponding files that contain the proposals:
# __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE
# __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE
__C.USE_PRECOMPUTED_PROPOSALS = False
__C.RESULTS_NMS_THRESHOLD to próg NMS używany do odrzucania nakładających się przewidywanych pól ograniczenia w ocenie. Niższy próg daje mniej usuwania, a tym samym bardziej przewidywane pola ograniczenia w końcowych danych wyjściowych. Jeśli ustawisz __C.USE_PRECOMPUTED_PROPOSALS = True czytnik, odczytuje wstępnie skompilowane zwroty z inwestycji z plików tekstowych. Jest to na przykład używane do trenowania danych Pascal VOC. Nazwy __C.DATA.TRAIN_PRECOMPUTED_PROPOSALS_FILE plików i __C.DATA.TEST_PRECOMPUTED_PROPOSALS_FILE są określone w pliku Examples/Image/Detection/utils/configs/Pascal_config.py.
# The basic segmentation is performed kvals.size() times. The k parameter is set (from, to, step_size)
__C.roi_ss_kvals = (10, 500, 5)
# When doing the basic segmentations prior to any box merging, all
# rectangles that have an area < min_size are discarded. Therefore, all outputs and
# subsequent merged rectangles are built out of rectangles that contain at
# least min_size pixels. Note that setting min_size to a smaller value than
# you might otherwise be interested in using can be useful since it allows a
# larger number of possible merged boxes to be created
__C.roi_ss_min_size = 9
# There are max_merging_iterations rounds of neighboring blob merging.
# Therefore, this parameter has some effect on the number of output rectangles
# you get, with larger values of the parameter giving more output rectangles.
# Hint: set __C.CNTK.DEBUG_OUTPUT=True to see the number of ROIs from selective search
__C.roi_ss_mm_iterations = 30
# image size used for ROI generation
__C.roi_ss_img_size = 200
Powyższe parametry konfigurują selektywne wyszukiwanie biblioteki dlib. Aby uzyskać szczegółowe informacje, zobacz stronę główną biblioteki dlib. Następujące dodatkowe parametry służą do filtrowania wygenerowanych zwrotów z inwestycji w.r.t. minimalnej i maksymalnej długości strony, obszaru i współczynnika proporcji.
# minimum relative width/height of an ROI
__C.roi_min_side_rel = 0.01
# maximum relative width/height of an ROI
__C.roi_max_side_rel = 1.0
# minimum relative area of an ROI
__C.roi_min_area_rel = 0.0001
# maximum relative area of an ROI
__C.roi_max_area_rel = 0.9
# maximum aspect ratio of an ROI vertically and horizontally
__C.roi_max_aspect_ratio = 4.0
# aspect ratios of ROIs for uniform grid ROIs
__C.roi_grid_aspect_ratios = [1.0, 2.0, 0.5]
Jeśli wyszukiwanie selektywne zwraca więcej zwrotów z inwestycji niż zażądano, są próbkowane losowo. Jeśli mniejsza liczba zwrotów z inwestycji zwraca dodatkowe zwroty z inwestycji jest generowana w zwykłej siatce przy użyciu określonego __C.roi_grid_aspect_ratioselementu .
Korzystanie z innego modelu podstawowego
Aby użyć innego modelu podstawowego, należy wybrać inną konfigurację modelu w get_configuration() metodzie run_fast_rcnn.py. Dwa modele są obsługiwane od razu:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
Aby pobrać model VGG16, użyj skryptu pobierania w pliku <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
Jeśli chcesz użyć innego modelu podstawowego, musisz skopiować na przykład plik utils/configs/VGG16_config.py konfiguracji i zmodyfikować go zgodnie z modelem bazowym:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
Aby zbadać nazwy węzłów modelu podstawowego, możesz użyć plot() metody z cntk.logging.graphklasy . Należy pamiętać, że modele ResNet nie są obecnie obsługiwane, ponieważ buforowanie roi w cnTK nie obsługuje jeszcze średniej puli roi.
Szczegóły algorytmu
Szybka nazwa sieci R-CNN
R-CNN do wykrywania obiektów zostały po raz pierwszy przedstawione w 2014 roku przez RossA Girshick et al., i zostały pokazane, aby przewyższać poprzednie najnowocześniejsze podejścia do jednego z głównych wyzwań związanych z rozpoznawaniem obiektów w tej dziedzinie: Pascal VOC. Od tego czasu opublikowano dwa kolejne dokumenty, które zawierają znaczne ulepszenia szybkości: Fast R-CNN i Faster R-CNN.
Podstawową ideą sieci R-CNN jest utworzenie głębokiej sieci neuronowej, która została pierwotnie wytrenowana do klasyfikacji obrazów przy użyciu milionów obrazów z adnotacjami i zmodyfikowania jej na potrzeby wykrywania obiektów. Podstawowy pomysł z pierwszego dokumentu R-CNN przedstawiono na rysunku poniżej (pobranym z papieru): (1) Biorąc pod uwagę obraz wejściowy, (2) w pierwszym kroku, generowanych jest wiele propozycji regionów. (3) Te propozycje regionów lub regiony interesów (ROI) są następnie wysyłane niezależnie za pośrednictwem sieci, która generuje wektor wartości zmiennoprzecinkowych 4096 dla każdego zwrotu z inwestycji. Na koniec (4) klasyfikator jest nauczony, który przyjmuje reprezentację 4096 zmiennoprzecinkowego zwrotu z inwestycji jako dane wejściowe i wyprowadza etykietę i pewność dla każdego zwrotu z inwestycji.

Chociaż to podejście działa dobrze pod względem dokładności, obliczenia są bardzo kosztowne, ponieważ sieć neuronowa musi być oceniana dla każdego zwrotu z inwestycji. Szybka sieć R-CNN rozwiązuje tę wadę, oceniając tylko większość sieci (aby być specyficzna: warstwy konwolucyjne) pojedynczo na obraz. Według autorów, prowadzi to do 213 razy przyspieszenie podczas testowania i 9x przyspieszenie podczas trenowania bez utraty dokładności. Jest to osiągane przy użyciu warstwy puli roI, która projektuje zwrot z inwestycji na mapie funkcji splotowych i wykonuje maksymalną pulę w celu wygenerowania żądanego rozmiaru danych wyjściowych oczekiwanego przez następującą warstwę.
W przykładzie usługi AlexNet używanym w tym samouczku warstwa buforowania zwrotu z inwestycji jest umieszczana między ostatnią warstwą splotową a pierwszą w pełni połączoną warstwą. W kodzie interfejsu API języka Python CNTK pokazanym poniżej jest to realizowane przez sklonowanie dwóch części sieci : i conv_layersfc_layers. Obraz wejściowy jest następnie najpierw znormalizowany, wypychany przez conv_layerswarstwę , roipooling i fc_layers na koniec głowy przewidywania i regresji są dodawane, aby przewidzieć etykietę klasy i współczynniki regresji odpowiednio na kandydata zwrotu z inwestycji.
def create_fast_rcnn_model(features, roi_proposals, label_targets, bbox_targets, bbox_inside_weights, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, roi_proposals, fc_layers, cfg)
detection_losses = create_detection_losses(...)
pred_error = classification_error(cls_score, label_targets, axis=1)
return detection_losses, pred_error
def create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg):
# RCNN
roi_out = roipooling(conv_out, rois, cntk.MAX_POOLING, (6, 6), spatial_scale=1/16.0)
fc_out = fc_layers(roi_out)
# prediction head
cls_score = plus(times(fc_out, W_pred), b_pred, name='cls_score')
# regression head
bbox_pred = plus(times(fc_out, W_regr), b_regr, name='bbox_regr')
return cls_score, bbox_pred
Oryginalna implementacja Caffe używana w dokumentach R-CNN można znaleźć w witrynie GitHub: RCNN, Fast R-CNN i Faster R-CNN.
Trenowanie maszyn wektorów nośnych a NN
Patrick Buehler udostępnia instrukcje dotyczące trenowania maszyny wektorów nośnych na danych wyjściowych CNN CNN CNTK (przy użyciu funkcji 4096 z ostatniej w pełni połączonej warstwy), a także dyskusji na temat zalet i wad tutaj.
Wyszukiwanie selektywne
Wyszukiwanie selektywne to metoda znajdowania dużego zestawu możliwych lokalizacji obiektów na obrazie, niezależnie od klasy rzeczywistego obiektu. Działa on przez klastrowanie pikseli obrazu w segmenty, a następnie wykonywanie klastrowania hierarchicznego w celu łączenia segmentów z tego samego obiektu w propozycje obiektów.



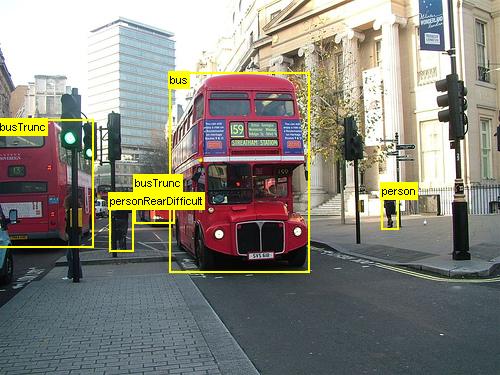
Aby uzupełnić wykryte zwroty z inwestycji z wyszukiwania selektywnego, dodamy zwroty z inwestycji, które jednolite obejmują obraz w różnych skalach i współczynnikach proporcji. Obraz po lewej stronie przedstawia przykładowe dane wyjściowe wyszukiwania selektywnego, gdzie każda możliwa lokalizacja obiektu jest wizualizowana przez zielony prostokąt. Zwroty z inwestycji, które są zbyt małe, zbyt duże itp., są odrzucane (środkowe) i wreszcie zwroty z inwestycji, które równomiernie pokrywają obraz są dodawane (po prawej). Te prostokąty są następnie używane jako regiony zainteresowań (ROI) w potoku R-CNN.
Celem generowania zwrotu z inwestycji jest znalezienie małego zestawu zwrotów z inwestycji, które jednak ściśle obejmują jak najwięcej obiektów na obrazie. To obliczenie musi być wystarczająco szybkie, podczas gdy jednocześnie znajdowanie lokalizacji obiektów w różnych skalach i współczynnikach proporcji. Wyszukiwanie selektywne zostało pokazane, aby dobrze wykonać to zadanie, z dobrą dokładnością do przyspieszenia kompromisów.
NMS (brak maksymalnego pomijania)
Metody wykrywania obiektów często generują wiele wykryć, które w pełni lub częściowo obejmują ten sam obiekt na obrazie.
Te zwroty z inwestycji należy scalić, aby móc zliczyć obiekty i uzyskać ich dokładne lokalizacje na obrazie.
Jest to tradycyjnie wykonywane przy użyciu techniki o nazwie Non Maximum Suppression (NMS). Używana wersja NMS (i używana również w publikacjach R-CNN) nie scala zwrotów z inwestycji, ale zamiast tego próbuje zidentyfikować, które zwroty z inwestycji najlepiej obejmują rzeczywiste lokalizacje obiektu i odrzuca wszystkie inne zwroty z inwestycji. Jest to implementowane przez iteracyjne wybieranie zwrotu z inwestycji z najwyższą ufnością i usuwanie wszystkich innych zwrotów z inwestycji, które znacząco nakładają się na ten zwrot z inwestycji i są klasyfikowane jako z tej samej klasy. Próg nakładania się można ustawić w PARAMETERS.py pliku (szczegóły).
Wyniki wykrywania przed (po lewej) i po (po prawej) nienależące do maksymalnej pomijania:


mAP (średnia precyzja)
Po wytrenowanym jakość modelu można zmierzyć przy użyciu różnych kryteriów, takich jak precyzja, kompletność, dokładność, krzywa pod powierzchnią itp. Typową metryką, która jest używana w zadaniu rozpoznawania obiektów Pascal VOC, jest pomiar średniej precyzji (AP) dla każdej klasy. Poniższy opis średniej precyzji jest pobierany z Everingham i in. Średnia precyzja (mAP) jest obliczana przez pobranie średniej dla APs wszystkich klas.
Dla danego zadania i klasy krzywa precyzji/kompletności jest obliczana na podstawie sklasyfikowanych danych wyjściowych metody. Kompletność jest definiowana jako proporcja wszystkich pozytywnych przykładów sklasyfikowanych powyżej danej rangi. Precyzja jest proporcją wszystkich przykładów powyżej tej rangi, które pochodzą z klasy dodatniej. Ap podsumowuje kształt krzywej precyzji/kompletności i jest definiowany jako średnia precyzja w zestawie poziomów kompletności równych jedenastu równych odstępów [0,0,1, . . . ,1]:
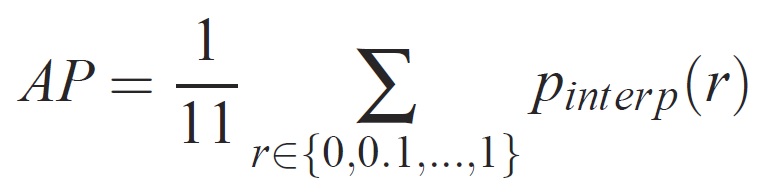
Precyzja na każdym poziomie kompletności r jest interpolowana przez pobranie maksymalnej precyzji mierzonej dla metody, dla której odpowiadające odwołanie przekracza r:
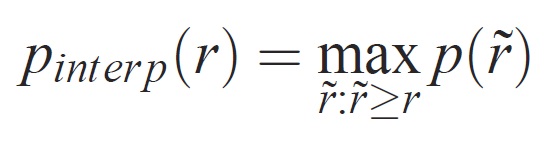
gdzie p( ̃r) to mierzona precyzja przy odwołaniu ̃r. Celem interpolacji krzywej precyzji/kompletności w ten sposób jest zmniejszenie wpływu "wiggles" w krzywej precyzji/kompletności, spowodowane przez niewielkie różnice w klasyfikacji przykładów. Należy zauważyć, że aby uzyskać wysoką ocenę, metoda musi mieć precyzję na wszystkich poziomach kompletności — to karanie metod, które pobierają tylko podzbiór przykładów o wysokiej precyzji (np. widoki boczne samochodów).