Konfigurowanie buforowania
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej w tym ogłoszeniu.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania platformy Microsoft Azure zawierają więcej warunków prawnych, które dotyczą funkcji platformy Azure będących w wersji beta, w wersji zapoznawczej lub w inny sposób jeszcze niewprowadzone w wersji ogólnodostępnej. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz informacje o wersji zapoznawczej Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji, prosimy o przesłanie zgłoszenia na AskHDInsight wraz ze szczegółami oraz śledzenie nas, aby otrzymywać więcej aktualizacji na społeczności Azure HDInsight.
Wykonywanie zapytań dotyczących magazynu obiektów przy użyciu łącznika Hive jest typowym przypadkiem użycia Trino. Ten proces często obejmuje wysyłanie dużych ilości danych. Obiekty są pobierane z systemu plików HDFS lub innego obsługiwanego magazynu obiektów przez wielu pracowników i przetwarzane przez tych pracowników. Powtarzające się zapytania z różnymi parametrami, a nawet różne zapytania od różnych użytkowników, często uzyskują dostęp do tych samych obiektów i przesyłają je.
Usługa HDInsight w usłudze AKS dodała końcowego buforowania wyników możliwości trino, co zapewnia następujące korzyści:
- Zmniejsz obciążenie magazynu obiektów.
- Zwiększ wydajność zapytań.
- Zmniejsz koszt zapytania.
Opcje buforowania
Różne opcje buforowania:
- Końcowe buforowanie wyników: Po włączeniu (w sekcji konfiguracji komponentu koordynatora), wynik dowolnego zapytania dla dowolnego katalogu jest buforowany na maszynie wirtualnej koordynatora.
- buforowanie katalogu Hive/Iceberg/Delta Lake: po włączeniu (dla określonego katalogu odpowiedniego typu) dane podziału dla każdego zapytania pamięciowane są w klastrze na maszynach wirtualnych pracowników.
Buforowanie wyników końcowych
Buforowanie wyników końcowych można skonfigurować na dwa sposoby:
Dostępne parametry konfiguracji to:
| Własność | Domyślny | Opis |
|---|---|---|
query.cache.enabled |
fałszywy | Umożliwia buforowanie wyników końcowych, jeśli ustawione na 'true'. |
query.cache.ttl |
- | Definiuje czas, aż dane pamięci podręcznej będą przechowywane przed eksmisją. Na przykład: "10m","1h" |
query.cache.disk-usage-percentage |
80 | Procent miejsca na dysku używanego do buforowanych danych. |
query.cache.max-result-data-size |
0 | Maksymalny rozmiar danych dla wyniku. Jeśli ta wartość zostanie przekroczona, wynik nie będzie buforowany. |
Notatka
Buforowanie wyników końcowych używa planu zapytania i czasu wygaśnięcia jako klucza pamięci podręcznej.
Buforowanie wyników końcowych można również kontrolować za pomocą następujących parametrów sesji:
| Parametr sesji | Domyślny | Opis |
|---|---|---|
query_cache_enabled |
Oryginalna wartość konfiguracji | Włącza/wyłącza końcowe buforowanie wyników dla zapytania/sesji. |
query_cache_ttl |
Oryginalna wartość konfiguracji | Definiuje czas, aż dane pamięci podręcznej będą przechowywane przed eksmisją. |
query_cache_max_result_data_size |
Oryginalna wartość konfiguracji | Maksymalny rozmiar danych dla wyniku. Jeśli ta wartość zostanie przekroczona, wynik nie będzie buforowany. |
query_cache_forced_refresh |
fałszywy | Po ustawieniu wartości true wymusza buforowanie wyniku wykonywania zapytania, który oznacza, że wynik zastępuje istniejące buforowane dane, jeśli istnieje). |
Notatka
Parametry sesji można ustawić dla sesji (na przykład jeśli jest używany interfejs wiersza polecenia Trino) lub można ustawić w wielu instrukcjach przed tekstem zapytania. Na przykład
set session query_cache_enabled=true;
select cust.name, *
from tpch.tiny.orders
join tpch.tiny.customer as cust on cust.custkey = orders.custkey
order by cust.name
limit 10;
Buforowanie wyników końcowych generuje metryki JMX, które można wyświetlić przy użyciu Zarządzany Prometheus i Grafana. Dostępne są następujące metryki:
| Metryka | Opis |
|---|---|
trino_cache_cachestats_requestcount |
Łączna liczba zapytań przechodzących przez warstwę pamięci podręcznej. Ta liczba nie obejmuje zapytań wykonywanych z wyłączoną pamięcią podręczną. |
trino_cache_cachestats_hitcount |
Liczba trafień pamięci podręcznej, tj. liczba zapytań, gdy dane były dostępne i zwracane z pamięci podręcznej. |
trino_cache_cachestats_misscount |
Liczba chybień pamięci podręcznej, tj. liczba zapytań, gdy dane nie były dostępne i musiały być buforowane. |
trino_cache_cachestats_hitrate |
Procentowa reprezentacja trafień pamięci podręcznej względem łącznej liczby zapytań. |
trino_cache_cachestats_totalevictedcount |
Liczba buforowanych zapytań usuniętych z pamięci podręcznej. |
trino_cache_cachestats_totalbytesfromsource |
Liczba bajtów odczytanych ze źródła. |
trino_cache_cachestats_totalbytesfromcache |
Liczba bajtów odczytanych z pamięci podręcznej. |
trino_cache_cachestats_totalcachedbytes |
Łączna liczba buforowanych bajtów. |
trino_cache_cachestats_totalevictedbytes |
Łączna liczba eksmitowanych bajtów. |
trino_cache_cachestats_spaceused |
Bieżący rozmiar pamięci podręcznej. |
trino_cache_cachestats_cachereadfailures |
Liczba przypadków, gdy nie można odczytać danych z pamięci podręcznej z powodu błędu. |
trino_cache_cachestats_cachewritefailures |
Liczba przypadków, gdy nie można zapisać danych w pamięci podręcznej z powodu błędu. |
Korzystanie z witryny Azure Portal
Zaloguj się do Portalu Azure.
Na pasku wyszukiwania na platformie Azure wpisz "HDInsight na klastrze AKS" i wybierz "Azure HDInsight on AKS clusters" z listy rozwijanej.

Wybierz nazwę klastra na stronie listy.
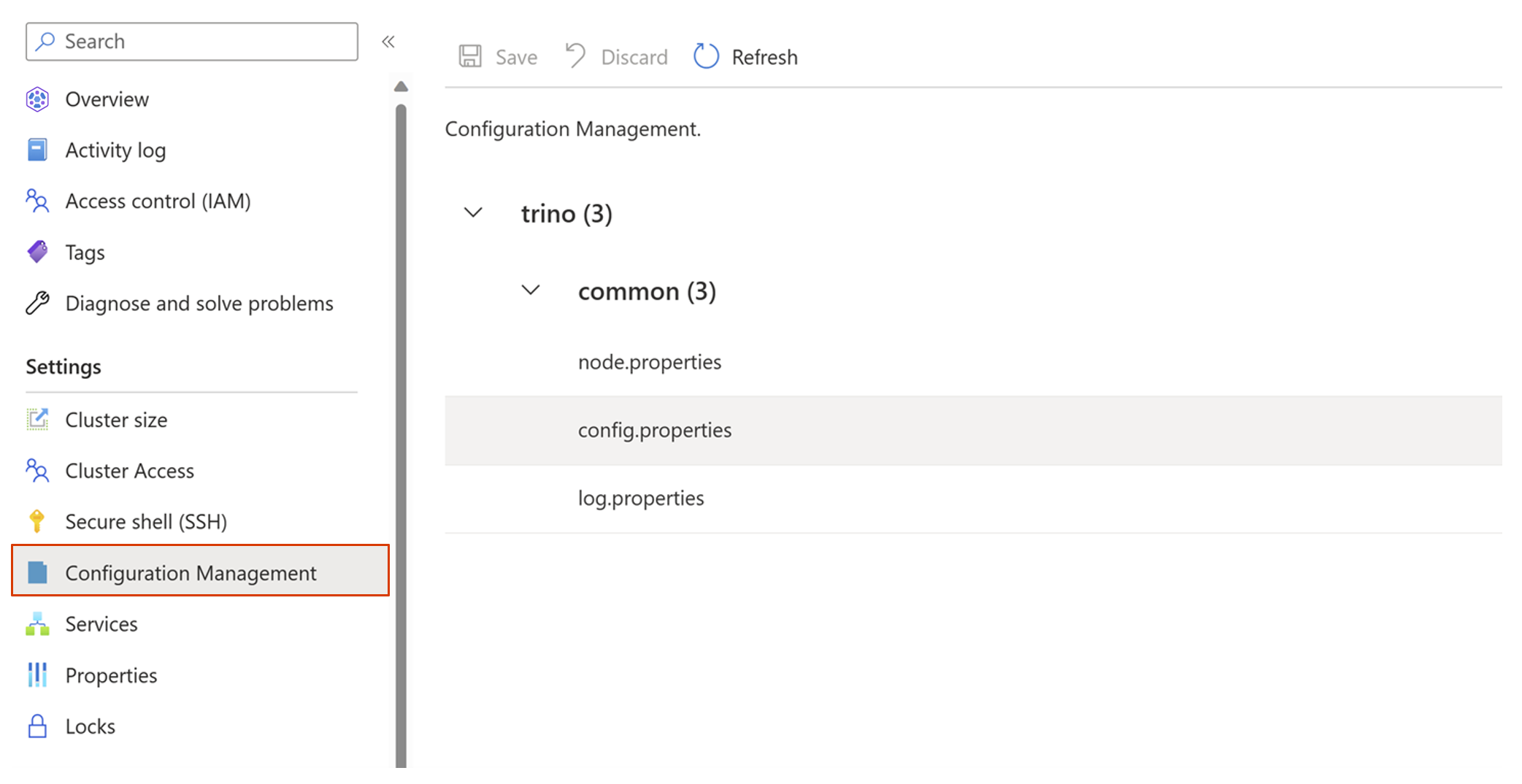
Przejdź do panelu Configuration Management.
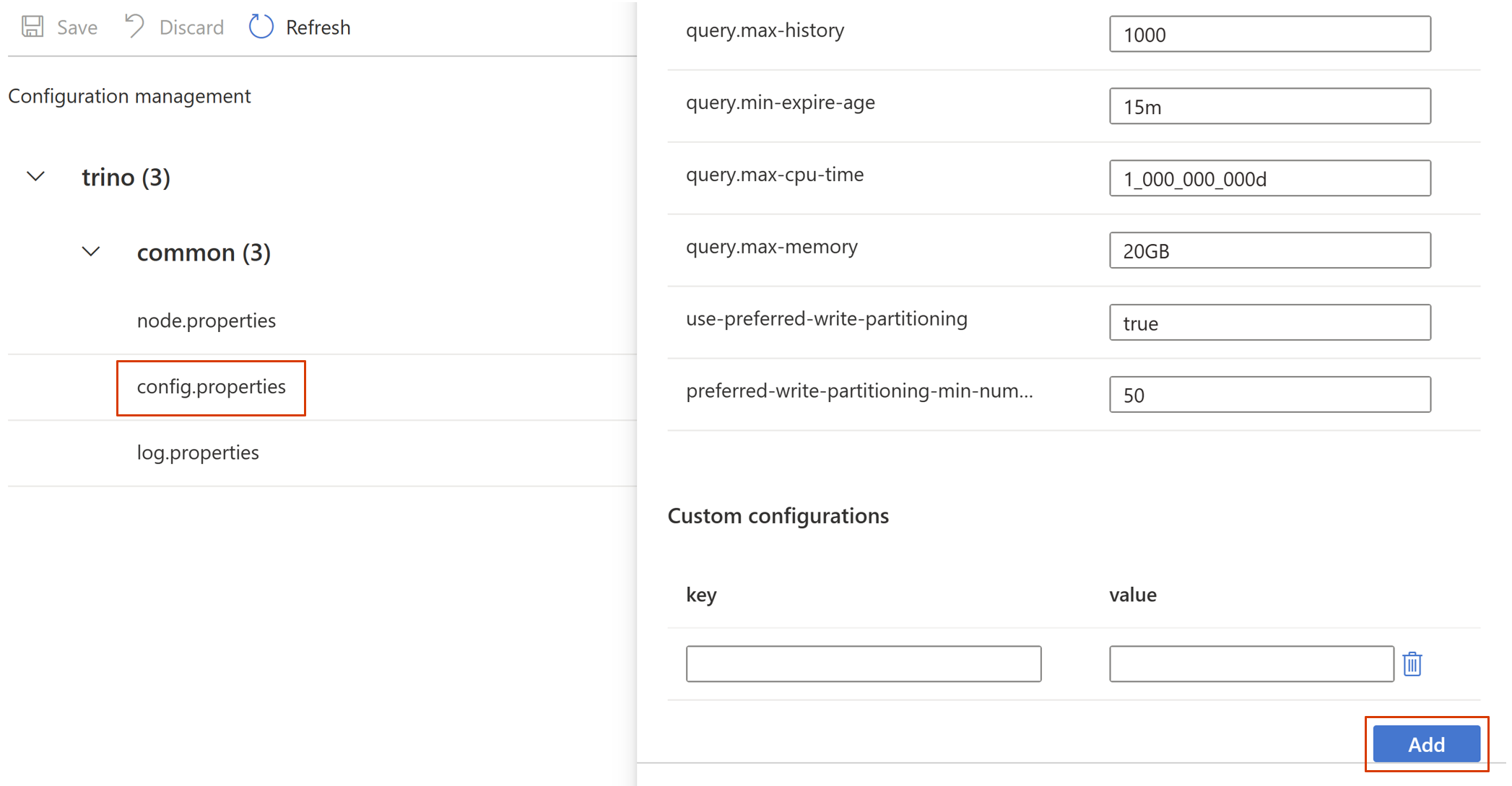
Przejdź do pliku config.properties -> konfiguracje niestandardowe, a następnie kliknij Dodaj.
Ustaw wymagane właściwości, a następnie kliknij przycisk OK.
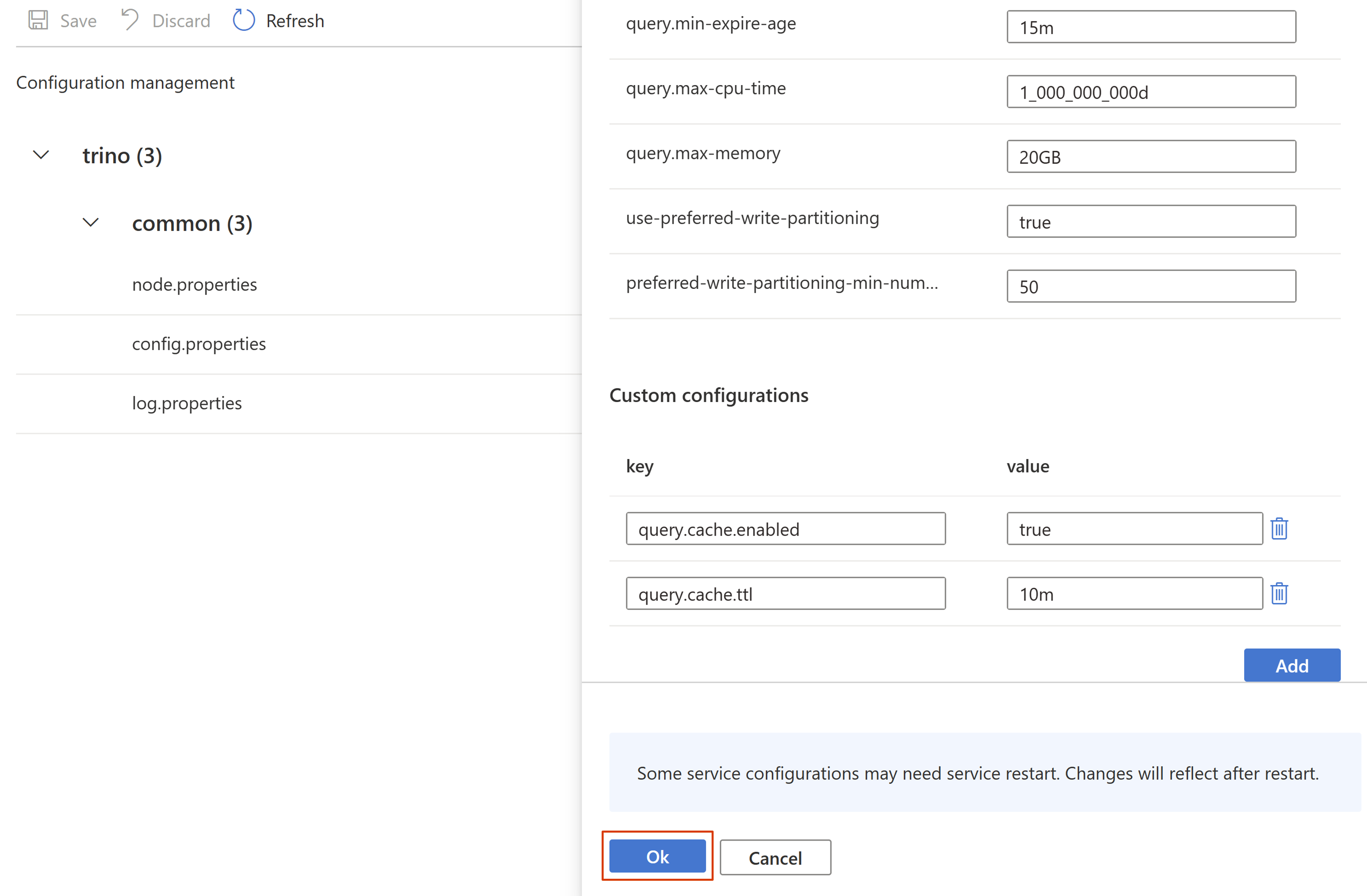
Zapisz konfigurację.
Korzystanie z szablonu ARM
Warunki wstępne
- Operacyjny klaster Trino z usługą HDInsight w usłudze AKS.
- Utwórz szablon ARM dla klastra.
- Przejrzyj kompletny szablon klastra usługi ARM .
- Znajomość tworzenia i wdrażania szablonu usługi ARM.
Należy zdefiniować właściwości w składniku koordynatora w sekcji properties.clusterProfile.serviceConfigsProfiles szablonu ARM.
W poniższym przykładzie pokazano, gdzie dodać właściwości.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "coordinator",
"files": [
{
"fileName": "config.properties",
"values": {
"query.cache.enabled": "true",
"query.cache.ttl": "10m"
}
}
]
}
]
}
]
}
}
}
]
}
Buforowanie Hive/Iceberg/Delta Lake
Wszystkie trzy łączniki mają taki sam zestaw parametrów, jak opisano w buforowaniu Hive .
Notatka
Niektóre parametry nie są konfigurowalne i zawsze ustawiane na ich wartości domyślne:
hive.cache.data-transfer-port=8898,
hive.cache.bookkeeper-port=8899,
hive.cache.location=/etc/trino/cache,
hive.cache.disk-usage-percentage=80
W poniższym przykładzie pokazano, gdzie dodać właściwości umożliwiające buforowanie Hive przy użyciu szablonu ARM.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {},
"resources": [
{
"type": "microsoft.hdinsight/clusterpools/clusters",
"apiVersion": "<api-version>",
"name": "<cluster-pool-name>/<cluster-name>",
"location": "<region, e.g. westeurope>",
"tags": {},
"properties": {
"clusterType": "Trino",
"clusterProfile": {
"serviceConfigsProfiles": [
{
"serviceName": "trino",
"configs": [
{
"component": "catalogs",
"files": [
{
"fileName": "hive1.properties",
"values": {
"connector.name": "hive"
"hive.cache.enabled": "true",
"hive.cache.ttl": "5d"
}
}
]
}
]
}
]
}
}
}
]
}
Wdróż zaktualizowany szablon ARM, aby odzwierciedlić zmiany w klastrze. Dowiedz się, jak wdrożyć szablon ARM.