Zapisywanie komunikatów zdarzeń w usłudze Azure Data Lake Storage Gen2 przy użyciu interfejsu API Apache Flink® DataStream
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej dzięki temu ogłoszeniu.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania dla wersji zapoznawczych Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure w wersji beta, w wersji zapoznawczej lub w inny sposób nie są jeszcze ogólnodostępne. Aby uzyskać informacje na temat tej konkretnej wersji zapoznawczej, zobacz Azure HDInsight w usłudze AKS w wersji zapoznawczej informacji. W przypadku pytań lub sugestii dotyczących funkcji, prześlij żądanie na AskHDInsight ze szczegółami i śledź nas, aby otrzymywać więcej aktualizacji na społeczności Azure HDInsight.
Narzędzie Apache Flink używa systemów plików do korzystania z danych i ich trwałego przechowywania, zarówno w przypadku wyników aplikacji, jak i odporności na uszkodzenia i odzyskiwania. Z tego artykułu dowiesz się, jak zapisywać komunikaty o zdarzeniach w usłudze Azure Data Lake Storage Gen2 przy użyciu interfejsu API datastream.
Warunki wstępne
- klaster Apache Flink na HDInsight na AKS
-
klaster Apache Kafka w usłudze HDInsight
- Musisz upewnić się, że ustawienia sieci zostały odpowiednio skonfigurowane zgodnie z opisem w Korzystanie z platformy Apache Kafka w usłudze HDInsight. Upewnij się, że usługi HDInsight w klastrach AKS i HDInsight znajdują się w tej samej sieci wirtualnej.
- Użyj tożsamości zarządzanej, aby uzyskać dostęp do ADLS Gen2
- IntelliJ na potrzeby programowania na maszynie wirtualnej platformy Azure w HDInsight na AKS Virtual Network
Łącznik apache Flink FileSystem
Ten łącznik systemu plików zapewnia te same gwarancje zarówno dla usługi BATCH, jak i PRZESYŁANIA STRUMIENIOWEgo, i jest przeznaczony do zapewnienia dokładnie raz semantyki na potrzeby wykonywania przesyłania strumieniowego. Aby uzyskać więcej informacji, zobacz Flink DataStream Filesystem.
Łącznik Apache Kafka
Flink udostępnia łącznik platformy Apache Kafka do odczytywania danych z tematów platformy Kafka i zapisywania ich w tematach platformy Kafka z dokładnie jednokrotnymi gwarancjami. Aby uzyskać więcej informacji, zobacz łącznik Apache Kafka.
Kompilowanie projektu dla platformy Apache Flink
pom.xml w środowisku IntelliJ IDEA
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.17.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.12</scala.binary.version>
<kafka.version>3.2.0</kafka.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
program dla ujścia usługi ADLS Gen2
abfsGen2.java
Notatka
Zastąp Apache Kafka w klastrze HDInsight bootStrapServers własnymi brokerami dla Kafka 3.2
package contoso.example;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.configuration.MemorySize;
import org.apache.flink.connector.file.sink.FileSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import java.time.Duration;
public class KafkaSinkToGen2 {
public static void main(String[] args) throws Exception {
// 1. get stream execution env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Configuration flinkConfig = new Configuration();
flinkConfig.setString("classloader.resolve-order", "parent-first");
env.getConfig().setGlobalJobParameters(flinkConfig);
// 2. read kafka message as stream input, update your broker ip's
String brokers = "<update-broker-ip>:9092,<update-broker-ip>:9092,<update-broker-ip>:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("click_events")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
stream.print();
// 3. sink to gen2, update container name and storage path
String outputPath = "abfs://<container-name>@<storage-path>.dfs.core.windows.net/flink/data/click_events";
final FileSink<String> sink = FileSink
.forRowFormat(new Path(outputPath), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(2))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
.build();
stream.sinkTo(sink);
// 4. run stream
env.execute("Kafka Sink To Gen2");
}
}
Zapakuj plik jar pakietu i prześlij go do platformy Apache Flink.
Przekaż plik jar do systemu ABFS.
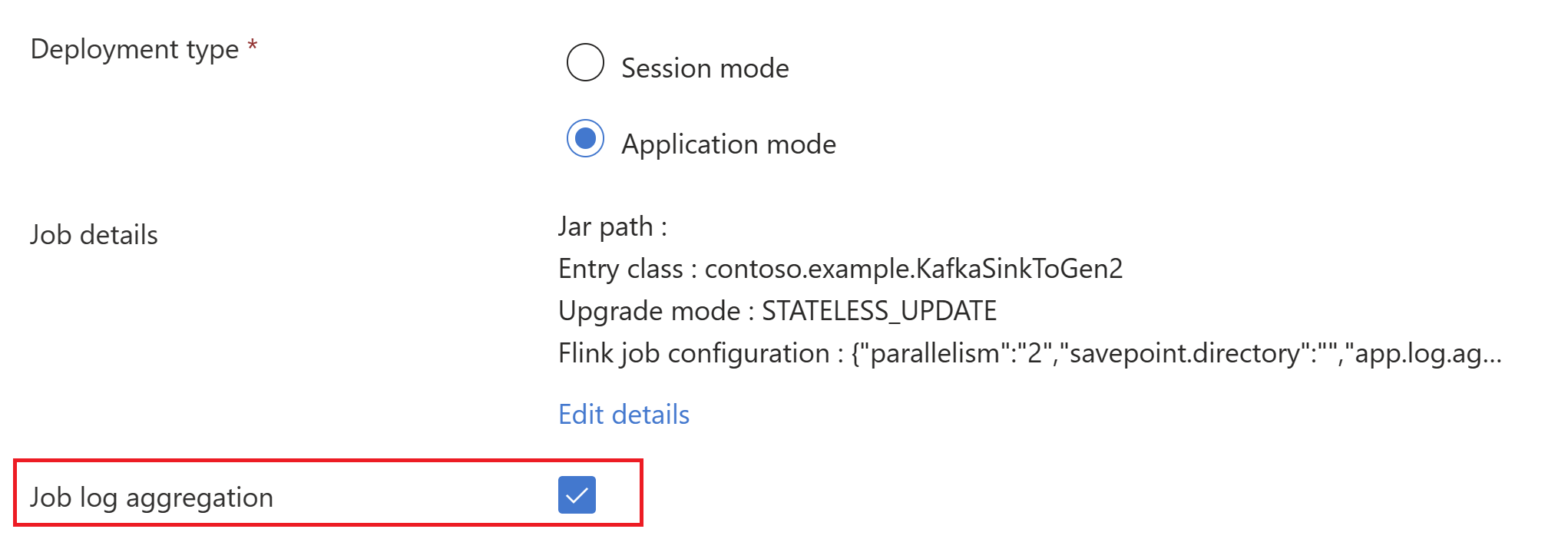
Przekaż informacje o pliku jar zadania podczas tworzenia klastra
AppMode.
Notatka
Upewnij się, że dodano classloader.resolve-order jako „parent-first” oraz hadoop.classpath.enable jako
trueWybierz pozycję Agregacja dziennika operacji, aby przesyłać dzienniki zadań do konta magazynowego.
Możesz zobaczyć, jak zadanie jest uruchomione.





Weryfikuj dane przesyłane strumieniowo w usłudze ADLS Gen2
Obserwujemy, jak strumień click_events dociera do ADLS Gen2.

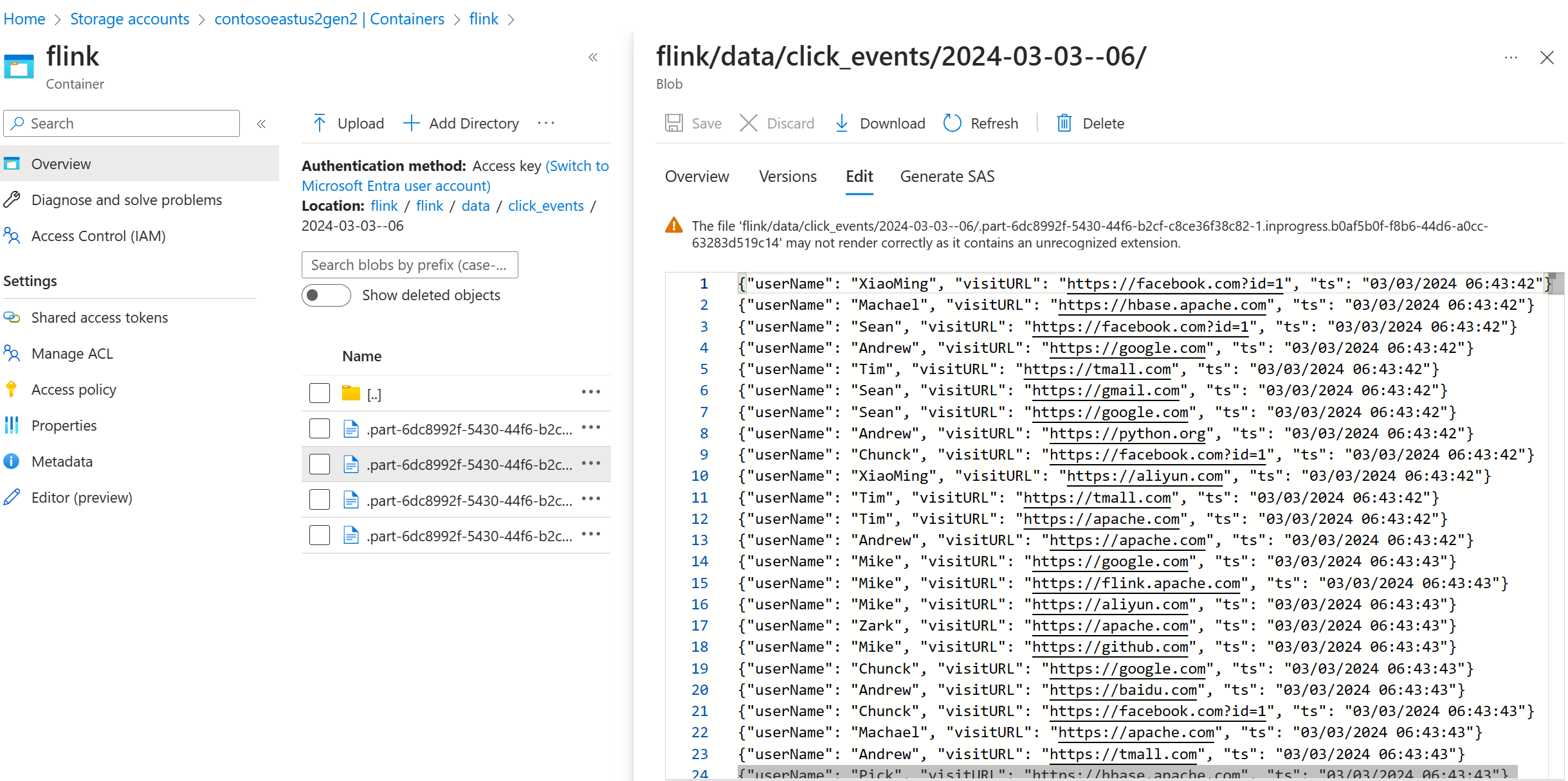
Możesz określić zasady rotacyjną, która przekształca plik częściowy będący w toku przy spełnieniu jednego z następujących trzech warunków:
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(Duration.ofMinutes(5))
.withInactivityInterval(Duration.ofMinutes(3))
.withMaxPartSize(MemorySize.ofMebiBytes(5))
.build())
Odniesienie
- Konektor Apache Kafka
- System plików Flink DataStream
- Apache Flink witryna internetowa
- Nazwy projektów open source Apache, Apache Kafka, Kafka, Apache Flink, Flink i powiązane są znakami towarowymiApache Software Foundation (ASF).