Utwórz klaster Apache Flink® w HDInsight na AKS za pomocą portalu Azure
Ważny
Usługa Azure HDInsight w usłudze AKS została wycofana 31 stycznia 2025 r. Dowiedz się więcej w tym ogłoszeniu.
Aby uniknąć nagłego kończenia obciążeń, należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure.
Ważny
Ta funkcja jest obecnie dostępna w wersji zapoznawczej. Dodatkowe warunki użytkowania platformy Microsoft Azure zawierają więcej warunków prawnych, które dotyczą funkcji platformy Azure w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz informacje o wersji zapoznawczej Azure HDInsight na AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie na AskHDInsight z podaniem szczegółów, a także śledź nas, aby uzyskać więcej aktualizacji na temat społeczności Azure HDInsight.
Wykonaj poniższe kroki, aby utworzyć klaster Apache Flink w witrynie Azure Portal.
Warunki wstępne
Wypełnij wymagania wstępne w następujących sekcjach:
- wymagania wstępne dotyczące subskrypcji
- wymagania wstępne dotyczące zasobów
- Tworzenie puli klastrów
Ważny
- Aby utworzyć klaster w nowej puli klastrów, przypisz rolę "Operator tożsamości zarządzanej" usługi AKS agentpool dla tożsamości zarządzanej przypisanej przez użytkownika w ramach wymagań wstępnych dotyczących zasobów. Jeśli masz wymagane uprawnienia, ten krok jest zautomatyzowany podczas tworzenia.
- Tożsamość zarządzana puli agentów usługi AKS jest tworzona podczas tworzenia puli klastrów. Tożsamość zarządzanej puli agentów AKS można zidentyfikować za pomocą (nazwa puli klastra)-agentpool. Wykonaj następujące kroki, aby przypisać rolę.
Tworzenie klastra Apache Flink
Klastry Flink można utworzyć po zakończeniu wdrażania puli klastrów. Omówmy kroki, gdy rozpoczynasz pracę z istniejącą pulą klastrów.
W witrynie Azure Portal wpisz pule klastrów usługi HDInsight/HDInsight/HDInsight w usłudze AKS i wybierz pozycję Azure HDInsight w pulach klastrów usługi AKS, aby przejść do strony pul klastrów. Na stronie Pule klastrów usługi HDInsight w usłudze AKS wybierz pulę klastrów, w której chcesz utworzyć nowy klaster Flink.

Na określonej stronie puli klastrów kliknij pozycję + Nowy klaster i podaj następujące informacje:
Własność Opis Subskrypcja To pole jest wypełniane automatycznie przy użyciu subskrypcji platformy Azure zarejestrowanej dla puli klastrów. Grupa zasobów To pole jest wypełniane automatycznie i pokazuje grupę zasobów w puli klastrów. Region To pole jest wypełniane automatycznie i pokazuje region wybrany w puli klastrów. Pula klastrów To pole jest wypełniane automatycznie i pokazuje nazwę puli klastra, w której klaster jest teraz tworzony. Aby utworzyć klaster w innej puli, znajdź pulę klastrów w portalu i kliknij pozycję + Nowy klaster. Wersja puli usługi HDInsight w usłudze AKS To pole jest wypełniane automatycznie i pokazuje wersję puli klastrów, w której klaster jest teraz tworzony. Usługa HDInsight w wersji usługi AKS Wybierz wersję pomocniczą lub poprawkową usługi HDInsight w usłudze AKS nowego klastra. Typ klastra Z listy rozwijanej wybierz pozycję Flink. Nazwa klastra Wprowadź nazwę nowego klastra. Tożsamość zarządzana przypisana użytkownikowi Z listy rozwijanej wybierz tożsamość zarządzaną, która ma być używana z klastrem. Jeśli jesteś właścicielem tożsamości zarządzanej (MSI) i ta tożsamość nie ma roli Operatora Tożsamości Zarządzanej w klastrze, kliknij link poniżej pola, aby przypisać wymagane uprawnienia z tożsamości zarządzanej puli agentów AKS. Jeśli MSI ma już odpowiednie uprawnienia, nie jest wyświetlany link. Zobacz Wymagania wstępne dla innych przypisań ról wymaganych dla MSI (tożsamości usługi zarządzanej). Konto magazynu Z listy rozwijanej wybierz konto magazynowania, które ma być skojarzone z klastrem Flink i określ nazwę kontenera. Tożsamość zarządzana jest dodatkowo udzielany dostęp do określonego konta magazynu z rolą „Właściciel danych Storage Blob” podczas tworzenia klastra. Sieć wirtualna Sieć wirtualna klastra. Podsieć Podsieć wirtualna klastra. Włączanie katalogu Hive dla języka Flink SQL.
Własność Opis Korzystanie z wykazu programu Hive Włącz tę opcję, aby użyć zewnętrznego magazynu metadanych Hive. Baza danych SQL dla Hive Z listy rozwijanej wybierz bazę danych SQL Database, w której chcesz dodać tabele hive-metastore. Nazwa użytkownika administratora SQL Wprowadź nazwę użytkownika administratora programu SQL Server. To konto jest używane przez magazyn metadanych do komunikowania się z bazą danych SQL. Skarbiec kluczy Z listy rozwijanej wybierz usługę Key Vault zawierającą tajemnicę z hasłem dla użytkownika administratora serwera SQL. Wymagane jest skonfigurowanie polityki dostępu z wszystkimi niezbędnymi uprawnieniami, takimi jak uprawnienia do klucza, uprawnienia do sekretów i uprawnienia do certyfikatów do MSI (tożsamości usługi zarządzanej), które jest używane podczas tworzenia klastra. Tożsamość usługi zarządzanej wymaga roli Administrator Key Vault, dodaj wymagane uprawnienia przy użyciu IAM. Nazwa sekretu hasła SQL Wprowadź tajną nazwę z usługi Key Vault, w której jest przechowywane hasło bazy danych SQL. 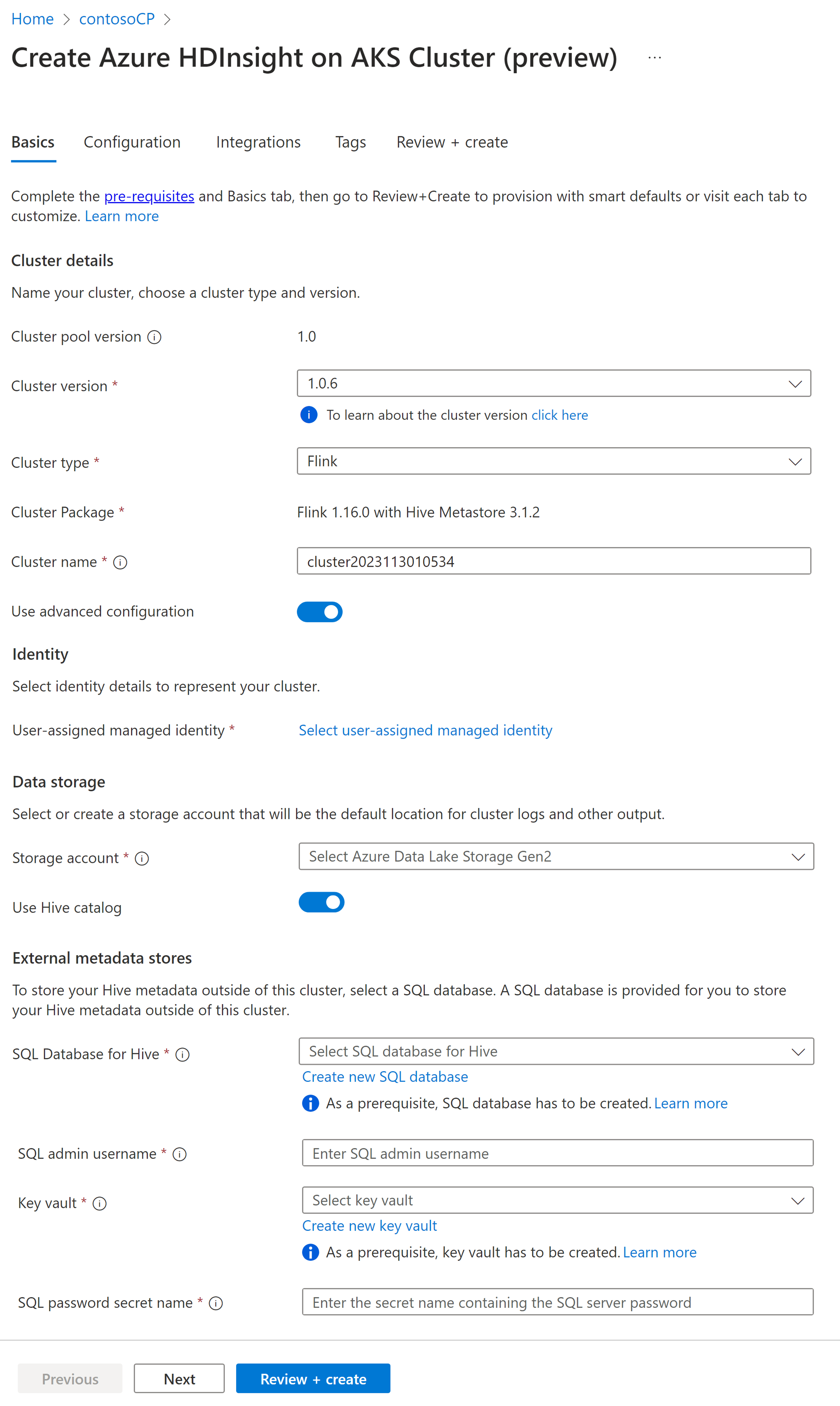
Notatka
Domyślnie używamy konta usługi Storage dla katalogu programu Hive tak samo jak konto magazynu i kontener używany podczas tworzenia klastra.
Wybierz pozycję Następnie: Konfiguracja, aby kontynuować.
Na stronie konfiguracji podaj następujące informacje:
Własność Opis Rozmiar węzła Wybierz rozmiar węzła, który ma być używany dla węzłów połączenia Flink, zarówno węzłów głównych, jak i roboczych. Liczba węzłów Wybierz liczbę węzłów dla klastra Flink; domyślnie węzły główne to dwa. Ustalanie rozmiaru węzłów roboczych pomaga określić konfiguracje Task Managera dla Flinka. Menedżer zadań i serwer historii znajdują się w węzłach głównych. W sekcji Service Configuration podaj następujące informacje:
Własność Opis Procesor menedżera zadań CPU Liczba całkowita. Wprowadź rozmiar procesorów menedżera zadań (w rdzeniach). Menedżer zadań - pamięć (MB) Wprowadź rozmiar pamięci menedżera zadań w MB. Minimalna wartość 1800 MB. CPU menedżera zadań Liczba całkowita. Wprowadź liczbę procesorów DLA menedżera zadań (w rdzeniach). Pamięć menedżera zadań w MB Wprowadź rozmiar pamięci w MB. Minimum of 1800 MB. CPU serwera historii Liczba całkowita. Wprowadź liczbę procesorów DLA menedżera zadań (w rdzeniach). Pamięć serwera historii w MB Wprowadź rozmiar pamięci w MB. Minimum of 1800 MB. 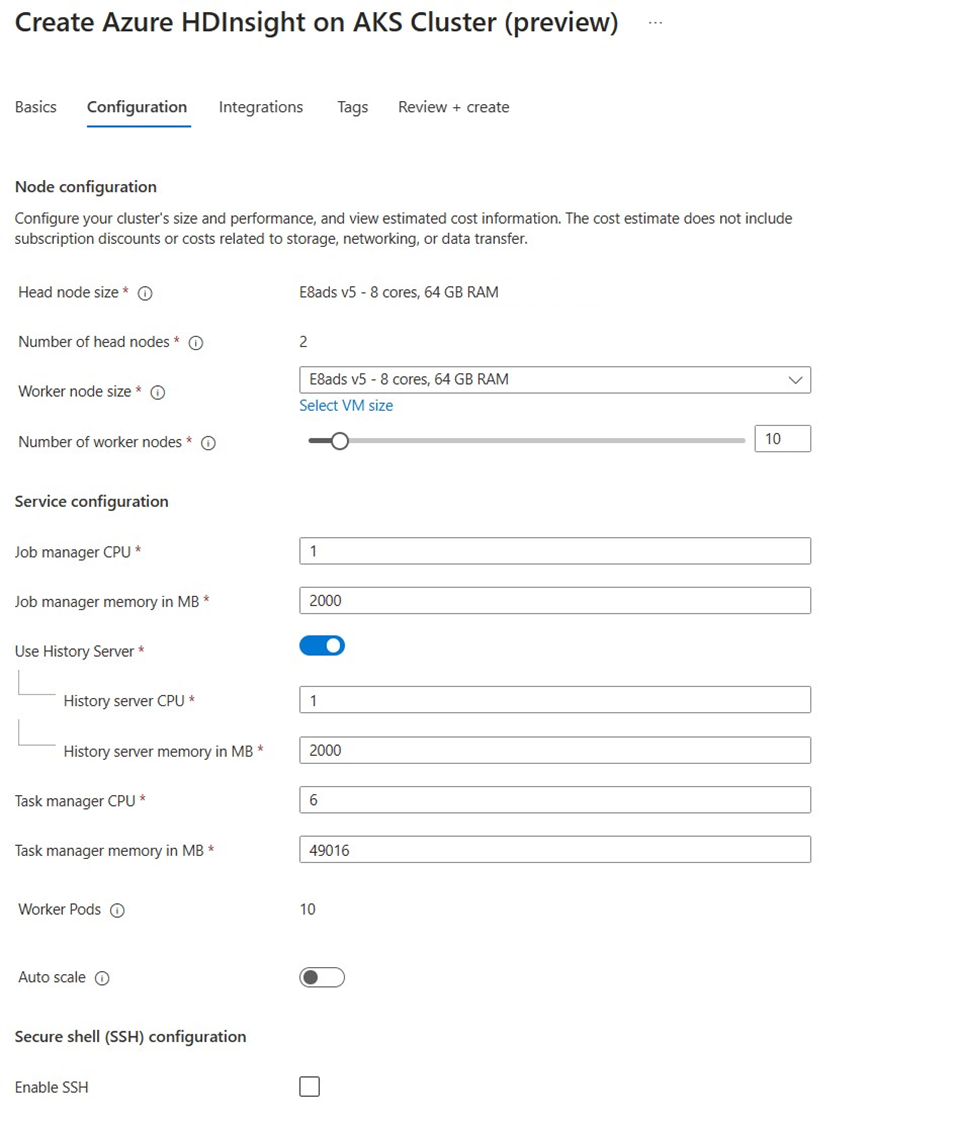
Notatka
- Serwer historii można włączyć/wyłączyć zgodnie z wymaganiami.
- Automatyczne skalowanie oparte na harmonogramie jest obsługiwane w języku Flink. Możesz zaplanować liczbę węzłów roboczych zgodnie z potrzebami. Na przykład włączono automatyczne skalowanie oparte na harmonogramie z domyślną liczbą węzłów roboczych: 3. A w dni powszednie od 9:00 UTC do 20:00 UTC zaplanowano, że będzie 10 węzłów roboczych. Później w ciągu dnia należy domyślnie ustawić 3 węzły (od 20:00 UTC do następnego dnia 09:00 UTC). W weekendy w godzinach od 9:00 UTC do 20:00 UTC liczba węzłów roboczych wynosi 4.
W sekcji Automatyczne skalowanie & SSH zaktualizuj następujące:
Własność Opis Automatyczne skalowanie Po wybraniu opcji można wybrać automatyczne skalowanie oparte na harmonogramie, aby skonfigurować harmonogram operacji skalowania. Włączanie protokołu SSH Po wybraniu opcji możesz wybrać łączną wymaganą liczbę węzłów SSH, które są punktami dostępu dla interfejsu wiersza polecenia Flink przy użyciu protokołu Secure Shell. Maksymalna dozwolona liczba węzłów SSH wynosi 5. 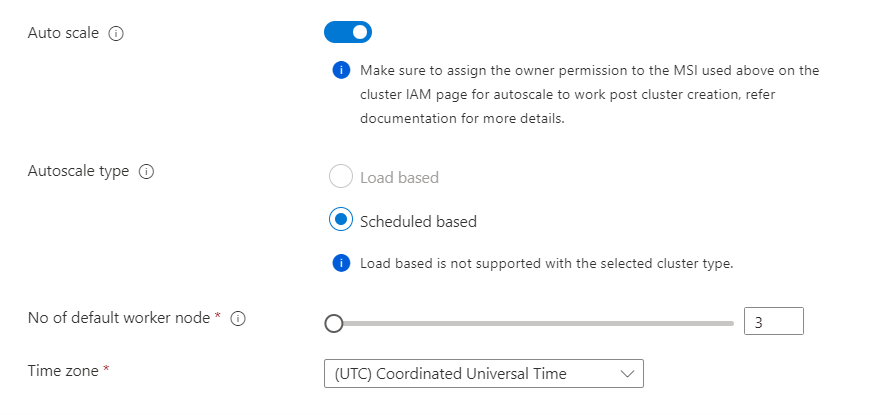

Kliknij przycisk Dalej: integracja, aby przejść do następnej strony.
Na stronie Integration podaj następujące informacje:
Własność Opis Analiza dzienników Ta funkcja jest dostępna tylko wtedy, gdy pula klastrów ma skojarzony obszar roboczy analizy dzienników. Po włączeniu tej funkcji można wybrać dzienniki do zbierania. Azure Prometheus Ta funkcja polega na wyświetlaniu szczegółowych informacji i dzienników bezpośrednio w klastrze przez wysyłanie metryk i dzienników do obszaru roboczego usługi Azure Monitor. 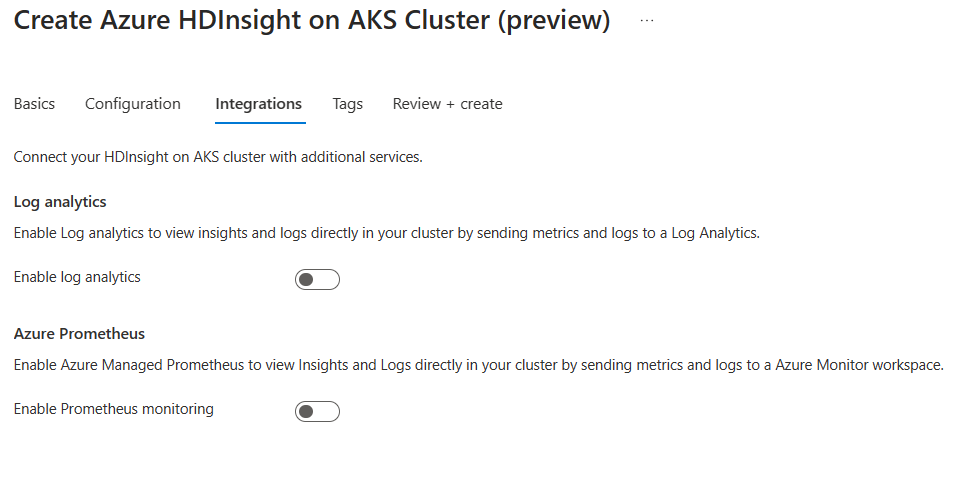
Kliknij przycisk Dalej: Tagi, aby przejść do następnej strony.
Na stronie tagów podaj następujące informacje:
Własność Opis Nazwa Fakultatywny. Wprowadź nazwę, taką jak usługa HDInsight w usłudze AKS, aby łatwo zidentyfikować wszystkie zasoby skojarzone z zasobami klastra. Wartość Możesz pozostawić to pole puste. Zasób Wybierz wszystkie zasoby wybrane. Wybierz pozycję Dalej: Przejrzyj i utwórz, aby kontynuować.
Na stronie Przegląd i utwórz wyszukaj komunikat Walidacja zakończona pomyślnie w górnej części strony, a następnie kliknij Utwórz.
Wyświetlana jest strona wdrożenia w trakcie tworzenia klastra. Utworzenie klastra trwa od 5 do 10 minut. Po utworzeniu klastra zostanie wyświetlony komunikat "Wdrożenie zostało ukończone". Jeśli odejdziesz od strony, możesz sprawdzić powiadomienia pod kątem bieżącego stanu.
Notatka
Nazwy projektów typu open source Apache, Apache Flink, Flink i nazwy im skojarzone są znakami towarowymiApache Software Foundation (ASF).