Architektura rozwiązania analizy biznesowej w centrum doskonałości
Ten artykuł dotyczy specjalistów IT i menedżerów IT. Dowiesz się więcej na temat architektury rozwiązań analizy biznesowej w środowisku COE i różnych używanych technologiach. Technologie obejmują platformę Azure, usługę Power BI i program Excel. Razem można ich używać do dostarczania skalowalnej i opartej na danych platformy analizy biznesowej w chmurze.
Projektowanie niezawodnej platformy analizy biznesowej jest nieco podobne do tworzenia mostu; most, który łączy przekształcone i wzbogacone dane źródłowe z użytkownikami danych. Projekt takiej złożonej struktury wymaga myślenia inżynieryjnego, choć może to być jedna z najbardziej kreatywnych i satysfakcjonujących architektur IT, którą można zaprojektować. W dużej organizacji architektura rozwiązania analizy biznesowej może składać się z następujących elementów:
- Źródła danych
- Pozyskiwanie danych
- Przygotowywanie danych dużych zbiorów danych
- Magazyn danych
- Semantyczne modele analizy biznesowej
- Raporty
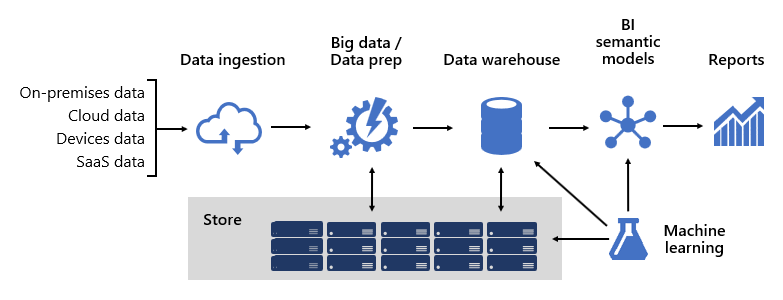
Platforma musi obsługiwać określone wymagania. W szczególności musi skalować się i działać, aby spełnić oczekiwania użytkowników usług biznesowych i konsumentów danych. Jednocześnie musi być zabezpieczony od podstaw. Ponadto musi być wystarczająco odporna, aby dostosować się do zmian, ponieważ jest pewne, że z czasem nowe dane i dziedziny tematyczne muszą być wprowadzane online.
Frameworki
W firmie Microsoft, od samego początku przyjęliśmy systemowe podejście, inwestując w rozwój frameworków. Struktury procesów technicznych i biznesowych zwiększają ponowne użycie projektu i logiki oraz zapewniają spójny wynik. Zapewniają one również elastyczność w architekturze wykorzystującej wiele technologii oraz usprawniają i zmniejszają nakłady pracy inżynieryjnej dzięki powtarzalnym procesom.
Dowiedzieliśmy się, że dobrze zaprojektowane struktury zwiększają wgląd w pochodzenie danych, analizę wpływu, konserwację logiki biznesowej, zarządzanie taksonomią i usprawnianie ładu. Ponadto programowanie stało się szybsze i współpraca w dużych zespołach stała się bardziej elastyczna i skuteczna.
W tym artykule opiszemy kilka naszych struktur.
Modele danych
Modele danych zapewniają kontrolę nad strukturą i dostępem do danych. W przypadku usług biznesowych i użytkowników danych modele danych są ich interfejsem z platformą analizy biznesowej.
Platforma analizy biznesowej może dostarczać trzy różne typy modeli:
- Modele przedsiębiorstwa
- Semantyczne modele analizy biznesowej
- Modele uczenia maszynowego (ML)
Modele przedsiębiorstwa
modele przedsiębiorstwa są tworzone i obsługiwane przez architektów IT. Są one czasami nazywane modelami wymiarowymi lub składnicami danych. Zazwyczaj dane są przechowywane w formacie relacyjnym jako tabele wymiarów i faktów. Te tabele przechowują oczyszczone i wzbogacone dane skonsolidowane z wielu systemów i reprezentują autorytatywne źródło raportowania i analizy.
Modele przedsiębiorstwa zapewniają spójne i pojedyncze źródło danych na potrzeby raportowania i analizy biznesowej. Są one tworzone raz i udostępniane jako standard firmowy. Zasady ładu zapewniają bezpieczeństwo danych, dlatego dostęp do poufnych zestawów danych , takich jak informacje o klientach lub finanse, jest ograniczony na podstawie potrzeb. Przyjmują one konwencje nazewnictwa zapewniające spójność, a tym samym dalsze ustanawianie wiarygodności danych i jakości.
Na platformie analizy biznesowej w chmurze, modele przedsiębiorstwa można wdrożyć w puli SQL Synapse w usłudze Azure Synapse. Pula SQL usługi Synapse staje się pojedynczą wersją prawdy, na która organizacja może liczyć na szybkie i niezawodne szczegółowe informacje.
Semantyczne modele analizy biznesowej
semantyczne modele analizy biznesowej reprezentują warstwę semantyczną nad modelami przedsiębiorstwa. Są one tworzone i obsługiwane przez deweloperów analizy biznesowej i użytkowników biznesowych. Deweloperzy analizy biznesowej tworzą podstawowe modele semantyczne, które pozyskują dane z modeli przedsiębiorstwa. Użytkownicy biznesowi mogą tworzyć modele o mniejszej skali, niezależne lub rozszerzać podstawowe modele semantyczne analizy biznesowej przy użyciu źródeł działów lub zewnętrznych. Semantyczne modele analizy biznesowej często koncentrują się na jednym obszarze tematu i są często szeroko udostępniane.
Możliwości biznesowe są włączone nie tylko przez dane, ale przez semantyczne modele analizy biznesowej, które opisują pojęcia, relacje, reguły i standardy. W ten sposób reprezentują intuicyjne i łatwe do zrozumienia struktury, które definiują relacje danych i hermetyzują reguły biznesowe jako obliczenia. Mogą również wymusić szczegółowe uprawnienia do danych, zapewniając odpowiednim osobom dostęp do odpowiednich danych. Co ważne, przyspieszają wydajność zapytań, zapewniając niezwykle elastyczną interaktywną analizę — nawet w przypadku terabajtów danych. Podobnie jak modele przedsiębiorstwa, semantyczne modele analizy biznesowej przyjmują konwencje nazewnictwa zapewniające spójność.
W ramach platformy analizy biznesowej w chmurze deweloperzy analizy biznesowej mogą wdrażać modele semantyczne analizy biznesowej w usłudze Azure Analysis Services, pojemności Power BI Premium oraz pojemności Microsoft Fabric.
Ważny
Czasami w tym artykule odnosi się do usługi Power BI Premium lub jej subskrypcji pojemnościowych (SKU P). Należy pamiętać, że firma Microsoft obecnie konsoliduje opcje zakupu i cofnie usługę Power BI Premium na jednostki SKU pojemności. Nowi i istniejący klienci powinni rozważyć zakup subskrypcji pojemności Fabric (SKU F).
Aby uzyskać więcej informacji, zobacz Ważna aktualizacja nadchodząca dotycząca licencjonowania usługi Power BI Premium i Power BI Premium — często zadawane pytania.
Zalecamy wdrożenie do Power BI, gdy jest używane jako warstwa do raportowania i analizy. Produkty te obsługują różne tryby przechowywania, umożliwiając tabelom modelu danych buforowanie danych lub używanie directquery, która jest technologią, która przekazuje zapytania do bazowego źródła danych. Tryb DirectQuery jest idealnym trybem przechowywania, gdy tabele modelu reprezentują duże woluminy danych lub trzeba dostarczać wyniki niemal w czasie rzeczywistym. Dwa tryby przechowywania można połączyć: Modele złożone łączą tabele, które używają różnych trybów przechowywania w jednym modelu.
W przypadku modeli o dużej liczbie zapytań można użyć usługi Azure Load Balancer do równomiernego rozłożenia obciążenia zapytań między replikami modelu. Umożliwia również skalowanie aplikacji i tworzenie modeli semantycznych analizy biznesowej o wysokiej dostępności.
Modele uczenia maszynowego
modele uczenia maszynowego (ML) są tworzone i obsługiwane przez analityków danych. Są one głównie opracowywane na podstawie pierwotnych źródeł w usłudze Data Lake.
Wytrenowane modele uczenia maszynowego mogą ujawniać wzorce w danych. W wielu okolicznościach te wzorce mogą służyć do przewidywania, które mogą służyć do wzbogacania danych. Na przykład zachowanie zakupowe może służyć do przewidywania odpływu klientów lub do segmentacji klientów. Wyniki przewidywania można dodać do modeli przedsiębiorstwa, aby umożliwić analizę według segmentu klienta.
Na platformie analizy biznesowej w chmurze można użyć azure Machine Learning do trenowania, wdrażania, automatyzowania i śledzenia modeli uczenia maszynowego oraz zarządzania nimi.
Magazyn danych
Sercem platformy analizy biznesowej jest magazyn danych, który hostuje modele przedsiębiorstwa. Jest to źródło zaakceptowanych danych — jako system rekordów i centrum — obsługujący modele przedsiębiorstwa do raportowania, analizy biznesowej i nauki o danych.
Wiele usług biznesowych, w tym aplikacji biznesowych (LOB), może polegać na magazynie danych jako autorytatywnym i zarządzanym źródle wiedzy przedsiębiorstwa.
W firmie Microsoft nasz magazyn danych jest hostowany w usłudze Azure Data Lake Storage Gen2 (ADLS Gen2) i Azure Synapse Analytics.
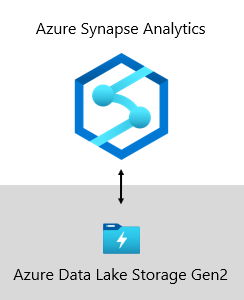
- ADLS Gen2 sprawia, że usługa Azure Storage stanowi podstawę do tworzenia jezior danych przedsiębiorstwa na platformie Azure. Jest ona przeznaczona do obsługi wielu petabajtów informacji przy jednoczesnym utrzymaniu setek gigabitów przepływności. Oferuje ona tanią pojemność pamięci masowej i tanie transakcje. Co więcej, obsługuje on dostęp zgodny z platformą Hadoop, który umożliwia zarządzanie danymi i uzyskiwanie do nich dostępu tak samo jak w przypadku rozproszonego systemu plików Hadoop (HDFS). W rzeczywistości usługi Azure HDInsight, Azure Databricks, i Azure Synapse Analytics mogą uzyskiwać dostęp do danych przechowywanych w usłudze ADLS Gen2. Dlatego w przypadku platformy analizy biznesowej dobrym wyborem jest przechowywanie nieprzetworzonych danych źródłowych, częściowo przetworzonych lub przygotowanych danych oraz danych gotowych do produkcji. Używamy go do przechowywania wszystkich naszych danych biznesowych.
- azure Synapse Analytics to usługa analityczna, która łączy magazynowanie danych przedsiębiorstwa i analizę danych big data. Zapewnia ona swobodę wykonywania zapytań dotyczących danych na Twoich warunkach przy użyciu bezserwerowych zasobów na żądanie lub aprowizowania — na dużą skalę. Usługa Synapse SQL, składnik usługi Azure Synapse Analytics, obsługuje kompletną analizę opartą na języku T-SQL, dlatego idealnie nadaje się do hostowania modeli przedsiębiorstwa obejmujących tabele wymiarów i faktów. Tabele można wydajnie ładować z usługi ADLS Gen2 przy użyciu prostych zapytań T-SQL Polybase . Następnie masz moc MPP do uruchamiania analiz o wysokiej wydajności.
Platforma silnika reguł biznesowych
Opracowaliśmy platformę Business Rules Engine (BRE), aby katalogować dowolną logikę biznesową, którą można zaimplementować w warstwie magazynu danych. BRE może oznaczać wiele rzeczy, ale w kontekście magazynu danych jest użyteczny do tworzenia kolumn obliczeniowych w tabelach relacyjnych. Te kolumny obliczeniowe są zwykle reprezentowane jako obliczenia matematyczne lub wyrażenia przy użyciu instrukcji warunkowych.
Celem jest podzielenie logiki biznesowej z podstawowego kodu analizy biznesowej. Tradycyjnie reguły biznesowe są trwale zakodowane w procedurach składowanych SQL, dlatego często skutkuje dużym wysiłkiem w celu ich utrzymania, gdy zmieniają się potrzeby biznesowe. W dokumencie BRE reguły biznesowe są definiowane raz i używane wielokrotnie w przypadku zastosowania do różnych jednostek magazynu danych. Jeśli logika obliczeń musi ulec zmianie, musi zostać zaktualizowana tylko w jednym miejscu, a nie w wielu procedurach składowanych. Istnieje również dodatkowa korzyść: platforma BRE napędza przejrzystość i wgląd w zaimplementowaną logikę biznesową, którą można uwidocznić za pomocą zestawu raportów, które tworzą samodzielnie aktualizującą się dokumentację.
Źródła danych
Magazyn danych może konsolidować dane z praktycznie dowolnego źródła danych. Jest ona głównie oparta na źródłach danych LOB, które są często relacyjnymi bazami danych przechowujące dane tematyczne związane ze sprzedażą, marketingiem, finansami itp. Te bazy danych mogą być hostowane w chmurze lub mogą znajdować się na miejscu. Inne źródła danych mogą być oparte na plikach, zwłaszcza dzienniki internetowe lub dane IOT pochodzące z urządzeń. Co więcej, dane mogą być pozyskiwane od dostawców oprogramowania jako usługi (SaaS).
W firmie Microsoft niektóre z naszych systemów wewnętrznych generują dane operacyjne bezpośrednio do usługi ADLS Gen2 przy użyciu nieprzetworzonych formatów plików. Oprócz usługi Data Lake inne systemy źródłowe składają się z aplikacji relacyjnych LOB, skoroszytów programu Excel, innych źródeł opartych na plikach oraz głównego zarządzania danymi (MDM) i niestandardowych repozytoriów danych. Repozytoria MDM umożliwiają zarządzanie naszymi danymi głównymi w celu zapewnienia autorytatywnych, ustandaryzowanych i zweryfikowanych wersji danych.
Pozyskiwanie danych
W zależności od rytmów firmy dane są pozyskiwane z systemów źródłowych i ładowane do magazynu danych. Może to być raz dziennie lub w częstszych odstępach czasu. Pozyskiwanie danych dotyczy wyodrębniania, przekształcania i ładowania danych. Ewentualnie odwrotnie: wyodrębnianie, ładowanie, a następnie przekształcanie danych. Różnica sprowadza się do tego, gdzie odbywa się transformacja. Przekształcenia są stosowane do czyszczenia, zgodności, integrowania i standaryzacji danych. Aby uzyskać więcej informacji, zobacz wyodrębnianie, przekształcanie i ładowanie (ETL).
Ostatecznie celem jest załadowanie odpowiednich danych do modelu przedsiębiorstwa tak szybko i wydajnie, jak to możliwe.
W firmie Microsoft używamy usługi Azure Data Factory (ADF). Usługi służą do planowania i organizowania walidacji danych, przekształceń i zbiorczych obciążeń z zewnętrznych systemów źródłowych do usługi Data Lake. Jest ona zarządzana przez niestandardowe struktury do przetwarzania danych równolegle i na dużą skalę. Ponadto kompleksowe rejestrowanie jest podejmowane w celu obsługi rozwiązywania problemów, monitorowania wydajności i wyzwalania powiadomień o alertach w przypadku spełnienia określonych warunków.
W międzyczasie Azure Databricks— platforma analityczna oparta na platformie Apache Spark, zoptymalizowana pod kątem platformy Azure w chmurze — wykonuje przekształcenia specjalnie na potrzeby nauki o danych. Kompiluje również i wykonuje modele uczenia maszynowego przy użyciu notesów języka Python. Wyniki z tych modeli uczenia maszynowego są ładowane do magazynu danych w celu zintegrowania przewidywań z aplikacjami i raportami dla przedsiębiorstw. Ponieważ usługa Azure Databricks uzyskuje bezpośredni dostęp do plików data lake, eliminuje lub minimalizuje konieczność kopiowania lub pozyskiwania danych.
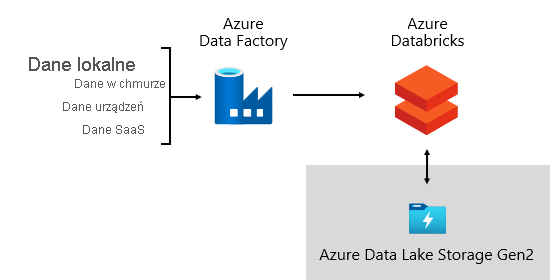
Struktura pozyskiwania
Opracowaliśmy framework do pobierania danych jako zestaw tabel konfiguracji i procedur. Obsługuje ona oparte na danych podejście do uzyskiwania dużych ilości danych z dużą szybkością i przy minimalnym kodzie. Krótko mówiąc, ta struktura upraszcza proces pozyskiwania danych w celu załadowania magazynu danych.
Struktura zależy od tabel konfiguracji, które przechowują informacje dotyczące źródła danych i miejsca docelowego danych, takie jak typ źródła, serwer, baza danych, schemat i szczegóły dotyczące tabeli. Takie podejście projektowe oznacza, że nie musimy opracowywać określonych potoków usługi ADF ani pakietów usług SQL Server Integration Services (SSIS). Zamiast tego procedury są pisane w wybranym języku, aby tworzyć potoki ADF, które są dynamicznie generowane i wykonywane w czasie rzeczywistym. W związku z tym pozyskiwanie danych staje się ćwiczeniem konfiguracyjnym, które można łatwo zoperacjonalizować. Tradycyjnie wymagałoby to rozbudowanych zasobów programistycznych w celu utworzenia zakodowanych w kodzie pakietów usług ADF lub SSIS.
System pobierania danych został zaprojektowany w celu uproszczenia procesu obsługi zmian w schematach źródeł nadrzędnych. Łatwo jest aktualizować dane konfiguracji — ręcznie lub automatycznie po wykryciu zmian schematu w celu uzyskania nowo dodanych atrybutów w systemie źródłowym.
Struktura orkiestracji
Opracowaliśmy strukturę aranżacji w celu operacjonalizacji i organizowania naszych potoków danych. Struktura aranżacji korzysta z projektu opartego na danych, który zależy od zestawu tabel konfiguracji. Te tabele przechowują metadane opisujące zależności przepływu pracy i sposób mapowania danych źródłowych na docelowe struktury danych. Inwestycje w rozwój tych ram adaptacyjnych od tego czasu zapłaciły za siebie; Nie ma już wymogu kodowania każdego przenoszenia danych.
Magazyn danych
Usługa Data Lake może przechowywać duże ilości danych pierwotnych do późniejszego użycia wraz z przejściowymi przekształceniami danych.
W firmie Microsoft używamy usługi ADLS Gen2 jako naszego pojedynczego źródła prawdy. Przechowuje nieprzetworzone dane wraz ze przygotowanymi danymi i danymi gotowymi do produkcji. Zapewnia wysoce skalowalne i ekonomiczne rozwiązanie typu data lake do analizy danych big data. Łącząc moc systemu plików o wysokiej wydajności z ogromną skalą, jest zoptymalizowany pod kątem obciążeń związanych z analizą danych, przyspieszając uzyskiwanie wglądu w dane.
Usługa ADLS Gen2 łączy w sobie zalety dwóch światów: magazyn obiektów BLOB oraz przestrzeń nazw systemu plików o wysokiej wydajności, którą dostosowujemy przy użyciu precyzyjnych uprawnień dostępu.
Uściślone dane są następnie przechowywane w relacyjnej bazie danych, aby zapewnić wysokowydajnego, bardzo skalowalnego magazynu danych dla modeli korporacyjnych, zapewniającego bezpieczeństwo, ład korporacyjny i zarządzalność. Magazyny danych dostosowane do danego tematu są przechowywane w usłudze Azure Synapse Analytics i ładowane za pomocą zapytań T-SQL z Azure Databricks lub Polybase.
Użycie danych
W warstwie raportowania usługi biznesowe wykorzystują dane przedsiębiorstwa pochodzące z magazynu danych. Uzyskują również dostęp do danych bezpośrednio w usłudze Data Lake na potrzeby zadań analizy ad hoc lub nauki o danych.
Szczegółowe uprawnienia są wymuszane we wszystkich warstwach: w usłudze Data Lake, modelach przedsiębiorstwa i semantycznych modelach analizy biznesowej. Uprawnienia zapewniają użytkownikom danych wyświetlanie tylko danych, do których mają prawa dostępu.
W firmie Microsoft używamy raportów i pulpitów nawigacyjnych usługi Power BI oraz raportów stronicowanych usługi Power BI. Niektóre raporty i analizy ad hoc są wykonywane w programie Excel — szczególnie w przypadku raportowania finansowego.
Publikujemy słowniki danych, które zawierają informacje referencyjne dotyczące naszych modeli danych. Są one udostępniane naszym użytkownikom, aby mogli odnajdywać informacje o naszej platformie analizy biznesowej. Słowniki dokumentują projekty modeli, zapewniając opisy jednostek, formatów, struktury, pochodzenia danych, relacji i obliczeń. Używamy usługi Azure Data Catalog, aby nasze źródła danych można było łatwo odnaleźć i zrozumieć.
Zazwyczaj wzorce użycia danych różnią się w zależności od roli:
- Analitycy danych łączą się bezpośrednio z podstawowymi modelami semantycznymi analizy biznesowej. Gdy podstawowe modele semantyczne analizy biznesowej zawierają wszystkie potrzebne dane i logikę, używają połączeń na żywo do tworzenia raportów i pulpitów nawigacyjnych usługi Power BI. Gdy trzeba rozszerzyć modele przy użyciu danych działów, tworzą one modele złożone usługi Power BI . Jeśli potrzebujesz raportów w stylu arkusza kalkulacyjnego, używają one programu Excel do tworzenia raportów na podstawie podstawowych modeli semantycznych analizy biznesowej lub semantycznych modeli analizy biznesowej dla działów.
- deweloperzy analizy biznesowej i autorzy raportów operacyjnych łączą się bezpośrednio z modelami przedsiębiorstwa. Używają programu Power BI Desktop do tworzenia raportów analitycznych połączeń na żywo. Mogą również tworzyć raporty analizy biznesowej typu operacyjnego jako raporty usługi Power BI podzielone na strony, pisząc natywne zapytania SQL w celu uzyskania dostępu do danych z modeli przedsiębiorstwa usługi Azure Synapse Analytics przy użyciu języka T-SQL lub modeli semantycznych usługi Power BI przy użyciu języka DAX lub MDX.
- Analitycy danych łączą się bezpośrednio z danymi w jeziorze danych. Używają one notesów Azure Databricks i Python do tworzenia modeli uczenia maszynowego, które są często eksperymentalne i wymagają specjalnych umiejętności do zastosowania produkcyjnego.

Powiązana zawartość
Aby uzyskać więcej informacji na temat tego artykułu, zapoznaj się z następującymi zasobami:
- plan wdrażania usługi Fabric: Centrum doskonałości
- Enterprise BI na platformie Azure przy użyciu usługi Azure Synapse Analytics
- Pytania? spróbuj zapytać społeczność Fabric
- Sugestie? Wnosić pomysły na ulepszenie usługi Fabric
Profesjonalne usługi
Certyfikowani partnerzy usługi Power BI są dostępni, aby pomóc organizacji w pomyślnym skonfigurowaniu środowiska COE. Mogą one zapewnić ekonomiczne szkolenie lub inspekcję danych. Aby znaleźć partnera usługi Power BI, odwiedź portal partnerów usługi Microsoft Power BI .
Możesz również współpracować z doświadczonymi partnerami konsultingowymi. Mogą one pomóc ocenić, ocenićlub zaimplementować usługę Power BI.