Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Synapse Analytics to usługa analityczna, która łączy magazynowanie danych przedsiębiorstwa i analizę danych big data. Zapewnia ona swobodę wykonywania zapytań dotyczących danych na Twoich warunkach.
Uwaga
Aby uzyskać więcej informacji na temat usługi Azure Synapse Analytics, obejrzyj ten film wideo wyjaśniający ulepszenia przenoszenia danych.
Składniki architektury usługi Synapse SQL
Dedykowana pula SQL (dawniej SQL DW) wykorzystuje architekturę rozproszoną do dystrybucji obliczeniowego przetwarzania danych między wieloma węzłami. Jednostka skalowania to abstrakcja mocy obliczeniowej, która jest nazywana jednostką magazynu danych. Zasoby obliczeniowe są niezależne od magazynu, co umożliwia ich skalowanie niezależnie od danych w systemie.
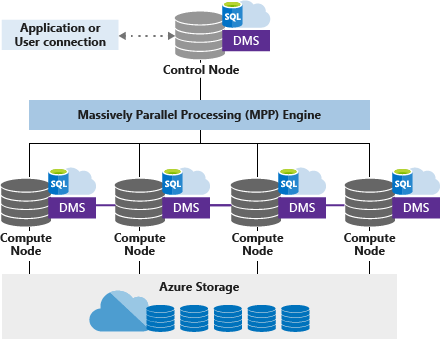
Dedykowana pula SQL (dawniej SQL DW) używa architektury opartej na węzłach. Aplikacje łączą się i wydają polecenia języka T-SQL do węzła sterującego. Węzeł kontrolny hostuje rozproszony aparat zapytań, który optymalizuje zapytania pod kątem przetwarzania równoległego, a następnie przekazuje operacje do węzłów obliczeniowych w celu równoległego wykonywania pracy.
Węzły obliczeniowe przechowują wszystkie dane użytkowników w usłudze Azure Storage i wykonują zapytania równoległe. Usługa przenoszenia danych (ang. Data Movement Service, DMS) to wewnętrzna usługa działająca na poziomie systemu, która przenosi dane pomiędzy węzłami w sposób wymagany do równoległego wykonywania zapytań i zwracania prawidłowych wyników.
W przypadku rozdzielenia przechowywania i obliczeń przy użyciu dedykowanej puli SQL (dawniej SQL DW) można:
- Dostosuj rozmiar mocy obliczeniowej niezależnie od swoich potrzeb w zakresie magazynowania.
- Zwiększanie lub zmniejszanie mocy obliczeniowej w dedykowanej puli SQL (dawniej SQL DW) bez przenoszenia danych.
- Wstrzymaj zasoby obliczeniowe bez wpływu na dane, płacąc tylko za przechowywanie.
- Wznawianie zasobów obliczeniowych w godzinach pracy.
Azure Storage
Dedykowana pula SQL SQL (dawniej SQL DW) korzysta z usługi Azure Storage, aby zapewnić bezpieczeństwo danych użytkownika. Ponieważ dane są przechowywane i zarządzane przez usługę Azure Storage, są naliczane oddzielne opłaty za użycie magazynu. Dane są podzielone na dystrybucje w celu zoptymalizowania wydajności systemu. Podczas definiowania tabeli możesz wybrać wzorzec dzielenia na fragmenty używany do dystrybucji danych. Te wzorce fragmentowania są obsługiwane:
- Hash
- System kołowy
- Replikuj
Węzeł kontrolny
Węzeł kontrolny to mózg całej architektury. Jest to fronton współdziałający ze wszystkimi aplikacjami i połączeniami. Aparat zapytań rozproszonych działa w węźle Kontrolnym, aby zoptymalizować i koordynować zapytania równoległe. Po przesłaniu zapytania T-SQL węzeł kontrolny przekształca je w zapytania uruchamiane równolegle z każdą dystrybucją.
Węzły obliczeniowe
Węzły obliczeniowe zapewniają moc obliczeniową. System mapuje dystrybucje na węzły obliczeniowe do przetwarzania. W miarę płacenia za więcej zasobów obliczeniowych dystrybucje są ponownie mapowane na dostępne węzły obliczeniowe. Liczba węzłów obliczeniowych waha się od 1 do 60 i jest określana przez poziom usługi Synapse SQL.
Każdy węzeł obliczeniowy ma identyfikator węzła widoczny w widokach systemowych. Identyfikator węzła obliczeniowego można wyświetlić, wyszukując kolumnę node_id w widokach systemowych, których nazwy zaczynają się od sys.pdw_nodes. Aby uzyskać listę tych widoków systemowych, zobacz Widoki systemowe usługi Synapse SQL.
Usługa przenoszenia danych
Usługa przenoszenia danych (DMS) to technologia transportu danych, która koordynuje przenoszenie danych między węzłami obliczeniowymi. Niektóre zapytania wymagają przenoszenia danych, aby zapewnić, że zapytania równoległe zwracają dokładne wyniki. Gdy wymagane jest przenoszenie danych, usługa DMS zapewnia, że odpowiednie dane są przesyłane do właściwej lokalizacji.
Dystrybucje
Dystrybucja to podstawowa jednostka magazynowania i przetwarzania zapytań równoległych wykonywanych na danych rozproszonych. Gdy usługa Synapse SQL uruchamia zapytanie, praca jest podzielona na 60 mniejszych zapytań uruchamianych równolegle.
Każde z 60 mniejszych zapytań jest uruchamianych w jednej z dystrybucji danych. Każdy węzeł obliczeniowy zarządza co najmniej jedną z 60 dystrybucji. Dedykowana pula SQL (wcześniej SQL DW) posiada maksymalne zasoby obliczeniowe i ma jedną dystrybucję na każdy węzeł obliczeniowy. Dedykowana pula SQL (dawniej SQL DW) z minimalnymi zasobami obliczeniowymi ma wszystkie dystrybucje w jednym węźle obliczeniowym.
Uwaga
Aby uzyskać zalecenia dotyczące najlepszej strategii dystrybucji tabel do użycia na podstawie obciążeń, zobacz Azure Synapse SQL Distribution Advisor.
Tabele rozdzielone skrótem
Tabela rozpraszana za pomocą skrótu może zapewnić najwyższą wydajność zapytań SQL dla łączeń i agregacji w dużych tabelach.
Aby podzielić dane na tabelę rozproszoną przy użyciu skrótu, funkcja skrótu służy do deterministycznego przypisywania każdego wiersza do jednej dystrybucji. W definicji tabeli jedna kolumna zostaje wyznaczona jako kolumna dystrybucji. Funkcja haszująca używa wartości z kolumny dystrybucji, aby przypisać każdy wiersz do dystrybucji.
Na poniższym diagramie pokazano, jak pełna (niedystrybuowana) tabela jest przechowywana jako tabela z dystrybucją haszową.

- Każdy wiersz należy do jednego rozkładu.
- Deterministyczny algorytm wyznaczania wartości skrótu przypisuje każdy wiersz do jednej dystrybucji.
- Liczba wierszy tabeli dla każdego rozkładu różni się, co pokazują różne rozmiary tabel.
Istnieją zagadnienia dotyczące wydajności wyboru kolumny dystrybucji, takie jak odrębność, niesymetryczność danych i typy zapytań uruchamianych w systemie.
Tabele dystrybuowane metodą okrężną
Tabela okrężna to najprostsza tabela do utworzenia i zapewnia szybką wydajność w przypadku użycia jako tabeli przejściowej na potrzeby obciążeń.
W tabeli dystrybuowanej metodą okrężną dane są rozmieszczane równomiernie w całej tabeli, bez dodatkowej optymalizacji. Rozkład jest najpierw wybierany losowo, a następnie bufory wierszy są przypisywane do rozkładów sekwencyjnie. Ładowanie danych do tabeli z równomiernym przydzielaniem jest szybkie, ale wydajność zapytań często bywa lepsza w przypadku tabel haszowanych. Łączenia w tabelach typu round-robin wymagają przetasowania danych, co zajmuje dodatkowy czas.
Tabele replikowane
Tabela replikowana zapewnia najszybsze wykonywanie zapytań w przypadku niewielkich tabel.
Tabela replikowana buforuje pełną kopię tabeli w każdym węźle obliczeniowym. Dlatego replikowanie tabeli eliminuje konieczność przesyłania danych między węzłami obliczeniowymi przed operacją sprzężenia lub agregacji. Replikowane tabele są najlepiej wykorzystywane w przypadku małych tabel. Wymagana jest dodatkowa ilość miejsca do magazynowania, co wiąże się z dodatkowym obciążeniem podczas zapisywania danych, co sprawia, że duże tabele są niepraktyczne.
Na poniższym diagramie przedstawiono zreplikowana tabelę, która jest buforowana w pierwszej dystrybucji w każdym węźle obliczeniowym.

Powiązana zawartość
Teraz, gdy znasz już nieco usługę Azure Synapse, dowiedz się, jak szybko utworzyć dedykowaną pulę SQL (dawniej SQL DW) i załadować przykładowe dane. Jeśli jesteś nowicjuszem w korzystaniu z platformy Azure, podstawowe pojęcia dotyczące Azure mogą być pomocne, gdy napotkasz nową terminologię. Możesz też przyjrzeć się niektórym z tych innych zasobów usługi Azure Synapse.