Akcje OCR
Power Automate umożliwia użytkownikom odczytywanie i wyodrębnianie danych z plików oraz zarządzanie nimi za pomocą rozpoznawania znaków (OCR).
Aby utworzyć aparat OCR i wyodrębnić tekst z obrazów i dokumentów za pomocą OCR, użyj akcji Wyodrębnij tekst za pomocą funkcji OCR. W poniższym przykładzie wyodrębniono tekst z całego wskazanego obrazu.
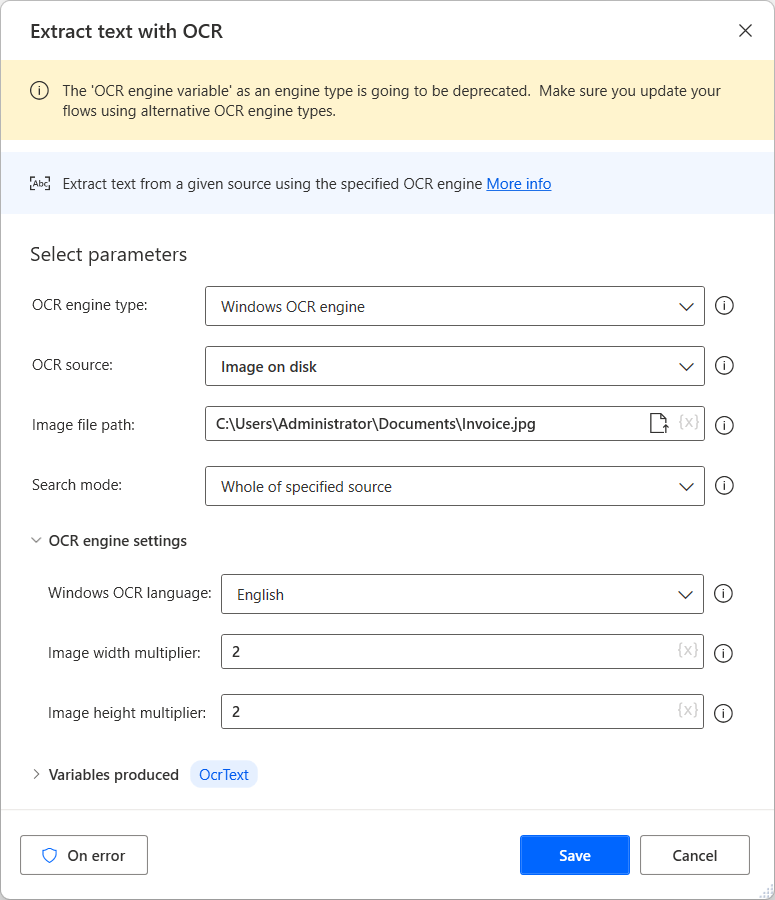
Wszystkie akcje OCR mogą tworzyć nowe zmienne silnika OCR lub używać istniejących. Możesz użyć istniejących zmiennych silnika OCR w każdej akcji, która oferuje możliwość OCR.
Power Automate obsługuje silnik OCR systemu Windows i Tesseract. Aby skonfigurować wybrany silnik OCR, przejdź do Ustawień silnika OCR odpowiedniej akcji. Dostępne opcje obejmują język oraz mnożniki szerokości i wysokości obrazu.
Uwaga
- Wszystkie dostępne silniki OCR są preinstalowane w Power Automate i działają lokalnie bez konieczności łączenia się z chmurą. Jednak aby wyodrębnić teksty w określonych językach, możesz potrzebować pobrać pakiety językowe lub pliki danych.
- Mnożniki obrazu zwiększają rozmiar obrazu, aby wyszukiwanie i wyodrębnianie tekstu było efektywniejsze. Ustawienie wartości większych niż trzy może powodować błędne wyniki.
Korzystanie z aparatu OCR systemu Windows
Domyślnym silnikiem OCR w Power Automate jest silnik OCR systemu Windows. Aby wyodrębnić dowolny tekst przy użyciu aparatu OCR systemu Windows, należy zainstalować odpowiedni pakiet językowy dla języka, który ma zostać wyodrębniony.
Jeśli odpowiedni pakiet językowy nie został zainstalowany, usługa Power Automate wyświetli błąd z monitem o zainstalowanie pakietu. Więcej informacji na temat pobierania i instalowania pakietów językowych można znaleźć w temacie Pakiety językowe dla systemu Windows.
Po zainstalowaniu odpowiedniego pakietu językowego należy rozszerzyć ustawienia aparatu OCR w akcji OCR i wybrać żądany język. Aparat Windows OCR obsługuje 25 języków, w tym: chiński (uproszczony i tradycyjny), czeski, duński, holenderski, angielski, fiński, francuski, niemiecki, grecki, węgierski, włoski, japoński, koreański, norweski, polski, portugalski, rumuński, rosyjski, serbski (cyrylica i łaciński), słowacki, hiszpański, szwedzki i turecki.
Korzystanie z aparatu OCR Tesseract
Uwaga
Aby korzystać z aparatu OCR Tesseract, upewnij się, że procesor komputera obsługuje zestaw instrukcji AVX2.
Oprócz aparatu OCR systemu Windows usługa Power Automate obsługuje również aparat Tesseract. Bez konieczności dalszego konfigurowania ten aparat może wyodrębnić tekst w pięciu językach: angielskim, niemieckim, hiszpańskim, francuskim i włoskim.
Aby wyodrębnić tekst w języku poza wymienioną listą, należy włączyć opcję Użyj innych języków w ustawieniach aparatu OCR akcji OCR. Po włączeniu tej opcji w akcji są wyświetlane dwa dodatkowe parametry: pola Skrót językowy i Ścieżka danych językowych.
Pole Skrót językowy wskazuje silnikowi, jakiego języka ma szukać podczas OCR. Pole Ścieżka danych językowych zawiera pliki danych językowych (.traineddata) używane do trenowania aparatu OCR. Pliki danych językowych można znaleźć dla wszystkich dostępnych języków można znaleźć w tym repozytorium GitHub.
Aparat Tesseract może być także używany do wyodrębniania tekstu z dokumentów wielojęzykowych. Aby uzyskać więcej informacji na temat wyodrębniania tekstów z dokumentów wielojęzykowych, zobacz temat Przeprowadzanie OCR w dokumentach wielojęzykowych.
Jeśli tekst znajduje się na ekranie (OCR)
Oznacza początek bloku warunkowego akcji w zależności od tego, czy dany tekst pojawia się na ekranie, czy nie, używając funkcji OCR.
Parametry wejściowe
| Argument | Opcjonalnie | Akceptuje | Wartość domyślna | opis |
|---|---|---|---|---|
| If text | Nie dotyczy | Istnieje, Nie istnieje | Istnieje | Określa, czy ma być sprawdzane istnienie tekstu w danym źródle przeznaczonym do analizy |
| Typ aparatu OCR | Nie | Aparat OCR systemu Windows, aparat Tesseract, zmienna aparatu OCR | Zmienna aparatu OCR | Typ aparatu OCR do użycia. Wybierz wstępnie skonfigurowany aparat OCR lub skonfiguruj nowy. |
| OCR engine variable | Nie | OCREngineObject | Aparat używany w celu wykonania operacji OCR | |
| Text to find | Nie | Wartość tekstowa | Tekst do wyszukania w określonym źródle | |
| Is regular expression | Nie dotyczy | Wartość logiczna | Fałsz | Określa, czy w celu wyszukiwania określonego tekstu ma być używane wyrażenie regularne |
| Search for text on | Nie dotyczy | Cały ekran, Okienko pierwszego planu | Cały ekran | Określa, czy podany tekst ma być wyszukiwany na całym widocznym ekranie, czy tylko w oknie na pierwszym planie |
| Search mode | Brak | Całe określone źródło, tylko określony podregion, podregion względem obrazu | Całe określone źródło | Określa, czy ma być skanowany cały ekran (lub okno), czy jego zawężony podregion |
| Image(s) | Nie. | Listaobrazów | Obrazy określające podregion (względem lewego górnego rogu obrazu) do skanowania w poszukiwaniu podanego tekstu | |
| X1 | Tak | Wartość liczbowa | Początkowa współrzędna X podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Tolerance | Tak | Wartość liczbowa | 10 | Określa, jak bardzo szukane obrazy mogą różnić się od pierwotnie wybranego obrazu |
| Y1 | Tak | Wartość liczbowa | Początkowa współrzędna Y podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| X1 | Tak | Wartość liczbowa | Początkowa współrzędna X podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| X2 | Tak | Wartość liczbowa | Końcowa współrzędna X podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Y1 | Tak | Wartość liczbowa | Początkowa współrzędna Y podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Y2 | Tak | Wartość liczbowa | Końcowa współrzędna Y podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| X2 | Tak | Wartość liczbowa | Końcowa współrzędna X podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Y2 | Tak | Wartość liczbowa | Końcowa współrzędna Y podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Język aparatu Windows OCR | Brak | Chiński (uproszczony), chiński (tradycyjny), czeski, duński, holenderski, angielski, fiński, francuski, niemiecki, grecki, węgierski, włoski, japoński, koreański, norweski, polski, portugalski, rumuński, rosyjski, serbski (cyrylica), serbski (łaciński), słowacki, hiszpański, szwedzki, turecki | Angielski | Język tekstu wykrywany przez aparat Windows OCR |
| Użyj innego języka | Brak | Wartość logiczna | Fałsz | Określa, czy ma być używany język, który nie został określony w polu „Język aparatu Tesseract” |
| Język Tesseract | Brak | Angielski, niemiecki, hiszpański, francuski, włoski | Angielski | Język tekstu wykrywany przez aparat Tesseract |
| Skrót języka | Nie | Wartość tekstowa | Skrót aparatu Tesseract, który ma być używany. Jeśli na przykład dane to „eng.traineddata”, ustaw ten parametr na „eng” | |
| Ścieżka danych języka | Nie. | Wartość tekstowa | Ścieżka folderu, w którym są przechowywane dane aparatu Tesseract dotyczące określonego języka | |
| Mnożnik szerokości obrazu | Nie | Wartość liczbowa | 1 | Mnożnik szerokości obrazu |
| Mnożnik szerokości obrazu | Nie | Wartość liczbowa | 1 | Mnożnik wysokości obrazu |
| Algorytm dopasowywania obrazów | Brak | Podstawowe, zaawansowane | Podstawowe | Który algorytm obrazów ma być używany podczas wyszukiwania obrazu |
Uwaga
- Aparat wyrażenia regularnego usługi Power Automate to .NET. Więcej informacji na temat wyrażeń regularnych można znaleźć w temacie język wyrażenia regularnego — szybkie informacje.
- Opcja Zmienna aparatu OCR zostanie w przyszłości wycofana.
Utworzone zmienne
| Argument | Type | opis |
|---|---|---|
| LocationOfTextFoundX | Wartość liczbowa | Współrzędna X punktu, w którym tekst pojawia się na ekranie. Jeśli wyszukiwanie jest wykonywane w oknie pierwszego planu, zwrócona współrzędna jest względem lewego górnego rogu okna |
| LocationOfTextFoundY | Wartość liczbowa | Współrzędna X punktu, w którym tekst pojawia się na ekranie. Jeśli wyszukiwanie jest wykonywane w oknie pierwszego planu, zwrócona współrzędna jest względem lewego górnego rogu okna |
Wyjątki
| Wyjątek | opis |
|---|---|
| W trybie nieinterakcyjnym nie można sprawdzić, czy istnieje tekst | Wskazuje, że podczas działania w trybie nieinterakcyjnym nie można sprawdzić, czy na ekranie znajduje się tekst |
| Nieprawidłowe współrzędne podregionu | Wskazuje, że określone współrzędne podregionu są nieprawidłowe |
| Nie można przeanalizować tekstu za pomocą funkcji OCR | Wskazuje, że wystąpił błąd podczas próby przeanalizowania tekstu za pomocą funkcji OCR |
| Nie można utworzyć aparatu OCR | Wskazuje, że wystąpił błąd podczas próby utworzenia aparatu OCR |
| Folder ścieżki danych nie istnieje | Wskazuje, że określony na potrzeby przechowywania danych języka folder nie istnieje |
| Wybrany pakiet językowy systemu Windows nie jest zainstalowany na maszynie | Wskazuje, że wybrany pakiet językowy systemu Windows nie został zainstalowany na komputerze |
| Aparat OCR nie jest aktywny | Wskazuje, że aparat OCR nie jest aktywny |
Zaczekaj na tekst na ekranie (OCR)
Zaczekaj, aż określony tekst zostanie wyświetlony na ekranie lub w oknie na pierwszym planie (bądź na pozycji względnej w stosunku do obrazu na ekranie lub w oknie na pierwszym planie) albo z niego zniknie, używając funkcji OCR.
Parametry wejściowe
| Argument | Opcjonalnie | Akceptuje | Wartość domyślna | opis |
|---|---|---|---|---|
| Wait for text to | Nie dotyczy | Pojawi się, Zniknie | Pojawi się | Określa, czy należy czekać na wyświetlenie lub zniknięcie tekstu |
| Typ aparatu OCR | Nie | Aparat OCR systemu Windows, aparat Tesseract, zmienna aparatu OCR | Zmienna aparatu OCR | Typ aparatu OCR do użycia. Wybierz wstępnie skonfigurowany aparat OCR lub skonfiguruj nowy. |
| OCR engine variable | Nie | OCREngineObject | Aparat używany w celu wykonania operacji OCR | |
| Text to find | Nie | Wartość tekstowa | Tekst do wyszukania w określonym źródle | |
| Is regular expression | Nie dotyczy | Wartość logiczna | Fałsz | Określa, czy w celu wyszukiwania określonego tekstu ma być używane wyrażenie regularne |
| Search for text on | Nie dotyczy | Cały ekran, Okienko pierwszego planu | Cały ekran | Określa, czy podany tekst ma być wyszukiwany na całym widocznym ekranie, czy tylko w oknie na pierwszym planie |
| Search mode | Brak | Całe określone źródło, tylko określony podregion, podregion względem obrazu | Całe określone źródło | Określa, czy ma być skanowany cały ekran (lub okno), czy jego zawężony podregion |
| Image(s) | Nie. | Listaobrazów | Obrazy określające podregion (względem lewego górnego rogu obrazu) do skanowania w poszukiwaniu podanego tekstu | |
| X1 | Tak | Wartość liczbowa | Początkowa współrzędna X podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Tolerance | Tak | Wartość liczbowa | 10 | Określa, jak bardzo szukane obrazy mogą różnić się od pierwotnie wybranego obrazu |
| Y1 | Tak | Wartość liczbowa | Początkowa współrzędna Y podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| X1 | Tak | Wartość liczbowa | Początkowa współrzędna X podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| X2 | Tak | Wartość liczbowa | Końcowa współrzędna X podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Y1 | Tak | Wartość liczbowa | Początkowa współrzędna Y podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Y2 | Tak | Wartość liczbowa | Końcowa współrzędna Y podregionu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| X2 | Tak | Wartość liczbowa | Końcowa współrzędna X podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Y2 | Tak | Wartość liczbowa | Końcowa współrzędna Y podregionu względnego w stosunku do określonego obrazu, który ma być skanowany w poszukiwaniu podanego tekstu | |
| Język aparatu Windows OCR | Brak | Chiński (uproszczony), chiński (tradycyjny), czeski, duński, holenderski, angielski, fiński, francuski, niemiecki, grecki, węgierski, włoski, japoński, koreański, norweski, polski, portugalski, rumuński, rosyjski, serbski (cyrylica), serbski (łaciński), słowacki, hiszpański, szwedzki, turecki | Angielski | Język tekstu wykrywany przez aparat Windows OCR |
| Użyj innego języka | Brak | Wartość logiczna | Fałsz | Określa, czy ma być używany język, który nie został określony w polu „Język aparatu Tesseract” |
| Język Tesseract | Brak | Angielski, niemiecki, hiszpański, francuski, włoski | Angielski | Język tekstu wykrywany przez aparat Tesseract |
| Skrót języka | Nie | Wartość tekstowa | Skrót aparatu Tesseract, który ma być używany. Jeśli na przykład dane to „eng.traineddata”, ustaw ten parametr na „eng” | |
| Ścieżka danych języka | Nie. | Wartość tekstowa | Ścieżka folderu, w którym są przechowywane dane aparatu Tesseract dotyczące określonego języka | |
| Mnożnik szerokości obrazu | Nie | Wartość liczbowa | 1 | Mnożnik szerokości obrazu |
| Mnożnik szerokości obrazu | Nie | Wartość liczbowa | 1 | Mnożnik wysokości obrazu |
| Algorytm dopasowywania obrazów | Brak | Podstawowe, zaawansowane | Podstawowe | Który algorytm obrazów ma być używany podczas wyszukiwania obrazu |
| Niepowodzenie z powodu błędu przekroczenia limitu czasu | Brak | Wartość logiczna | Fałsz | Określ, czy chcesz, aby akcja oczekiwała bez końca, czy aby była określana jako zakończona niepowodzeniem po upływie ustawionego okresu |
Uwaga
- Aparat wyrażenia regularnego usługi Power Automate to .NET. Więcej informacji na temat wyrażeń regularnych można znaleźć w temacie język wyrażenia regularnego — szybkie informacje.
- Opcja Zmienna aparatu OCR zostanie w przyszłości wycofana.
Utworzone zmienne
| Argument | Type | opis |
|---|---|---|
| LocationOfTextFoundX | Wartość liczbowa | Współrzędna X punktu, w którym tekst pojawia się na ekranie. Jeśli wyszukiwanie jest wykonywane w oknie pierwszego planu, zwrócona współrzędna jest względem lewego górnego rogu okna |
| LocationOfTextFoundY | Wartość liczbowa | Współrzędna X punktu, w którym tekst pojawia się na ekranie. Jeśli wyszukiwanie jest wykonywane w oknie pierwszego planu, zwrócona współrzędna jest względem lewego górnego rogu okna |
Wyjątki
| Wyjątek | opis |
|---|---|
| W trybie nieinterakcyjnym nie można sprawdzić, czy istnieje tekst | Wskazuje, że podczas działania w trybie nieinterakcyjnym nie można sprawdzić, czy na ekranie znajduje się tekst |
| Nieprawidłowe współrzędne podregionu | Wskazuje, że określone współrzędne podregionu są nieprawidłowe |
| Nie można przeanalizować tekstu za pomocą funkcji OCR | Wskazuje, że wystąpił błąd podczas próby przeanalizowania tekstu za pomocą funkcji OCR |
| Nie można utworzyć aparatu OCR | Wskazuje, że wystąpił błąd podczas próby utworzenia aparatu OCR |
| Folder ścieżki danych nie istnieje | Wskazuje, że określony na potrzeby przechowywania danych języka folder nie istnieje |
| Wybrany pakiet językowy systemu Windows nie jest zainstalowany na maszynie | Wskazuje, że wybrany pakiet językowy systemu Windows nie został zainstalowany na komputerze |
| Aparat OCR nie jest aktywny | Wskazuje, że aparat OCR nie jest aktywny |
| Błąd limitu czasu | Wskazuje, że akcja zakończyła się niepowodzeniem po upływie ustawionego okresu |
Wyodrębnij tekst za pomocą funkcji OCR
Wyodrębnij tekst z danego źródła za pomocą danego aparatu OCR.
Parametry wejściowe
| Argument | Opcjonalnie | Akceptuje | Wartość domyślna | opis |
|---|---|---|---|---|
| Aparat OCR | Nie | Aparat OCR systemu Windows, aparat Tesseract, zmienna aparatu OCR | Zmienna aparatu OCR | Typ aparatu OCR do użycia. Wybierz wstępnie skonfigurowany aparat OCR lub skonfiguruj nowy |
| Zmienna aparatu OCR | Nie | OCREngineObject | Aparat używany w celu wykonania operacji OCR | |
| OCR source | Nie dotyczy | Ekran, Okno pierwszego planu, Obraz na dysku | Ekran | Źródło obrazu, na którym ma zostać wykonana operacja OCR |
| Image file path | Nie | Plik | Ścieżka obrazu, na którym ma zostać wykonana operacja OCR | |
| Search mode | Nie dotyczy | Całe określone źródło, tylko określony podregion, podregion względem obrazu | Całe określone źródło | Wybrany tryb dla operacji OCR |
| Image | Nie. | Listaobrazów | Obraz używany w celu zawężenia skanowania do podregionu, który jest względny w stosunku do określonego obrazu | |
| Tolerance | Tak | Wartość liczbowa | 10 | Określa, jak bardzo obraz może różnić się od pierwotnie wybranego obrazu |
| X1 | Tak | Wartość liczbowa | Początkowa współrzędna X podregionu używanego w celu zawężenia skanowania | |
| X2 | Tak | Wartość liczbowa | Końcowa współrzędna X podregionu używanego w celu zawężenia skanowania | |
| Y1 | Tak | Wartość liczbowa | Początkowa współrzędna Y podregionu używanego w celu zawężenia skanowania | |
| Y2 | Tak | Wartość liczbowa | Końcowa współrzędna Y podregionu używanego w celu zawężenia skanowania | |
| Język aparatu Windows OCR | Brak | Chiński (uproszczony), chiński (tradycyjny), czeski, duński, holenderski, angielski, fiński, francuski, niemiecki, grecki, węgierski, włoski, japoński, koreański, norweski, polski, portugalski, rumuński, rosyjski, serbski (cyrylica), serbski (łaciński), słowacki, hiszpański, szwedzki, turecki | Angielski | Język tekstu wykrywany przez aparat Windows OCR |
| Użyj innego języka | Brak | Wartość logiczna | Fałsz | Określa, czy ma być używany język, który nie został określony w polu „Język aparatu Tesseract” |
| Język Tesseract | Brak | Angielski, niemiecki, hiszpański, francuski, włoski | Angielski | Język tekstu wykrywany przez aparat Tesseract |
| Skrót języka | Nie | Wartość tekstowa | Skrót aparatu Tesseract, który ma być używany. Jeśli na przykład dane to „eng.traineddata”, ustaw ten parametr na „eng” | |
| Ścieżka danych języka | Nie. | Wartość tekstowa | Ścieżka folderu, w którym są przechowywane dane aparatu Tesseract dotyczące określonego języka | |
| Mnożnik szerokości obrazu | Nie | Wartość liczbowa | 1 | Mnożnik szerokości obrazu |
| Mnożnik szerokości obrazu | Nie | Wartość liczbowa | 1 | Mnożnik wysokości obrazu |
| Czekaj na pojawienie się obrazu | Brak | Wartość logiczna | Prawda | Określa, czy należy czekać na wyświetlenie obrazu na ekranie lub w oknie na pierwszym planie, czy nie |
| Limit czasu | Nie | Wartość liczbowa | 5 | Określa czas oczekiwania na zakończenie operacji, po upływie którego wykonywanie akcji zakończy się niepowodzeniem |
| Algorytm dopasowywania obrazów | Brak | Podstawowe, zaawansowane | Podstawowe | Który algorytm obrazów ma być używany podczas wyszukiwania obrazu |
Uwaga
Opcja Zmienna aparatu OCR zostanie w przyszłości wycofana.
Utworzone zmienne
| Argument | Type | opis |
|---|---|---|
| OcrText | Wartość tekstowa | Wynik po wyodrębnieniu tekstu |
Wyjątki
| Wyjątek | Opis |
|---|---|
| Nie można wyodrębnić tekstu za pomocą funkcji OCR | Wskazuje, że wystąpił błąd podczas próby wyodrębnienia tekstu za pomocą funkcji OCR z danego źródła |
| Nie znaleziono pliku obrazu | Wskazuje, że plik nie istnieje w danej ścieżce |
| Nie znaleziono obrazu punktu orientacyjnego | Wskazuje, że obraz punktu orientacyjnego nie istnieje |
| W trybie nieinterakcyjnym nie można pobrać tekstu z ekranu | Wskazuje, że podczas działania w trybie nieinterakcyjnym nie można pobrać tekstu z ekranu |
| Nie można utworzyć aparatu OCR | Wskazuje, że wystąpił błąd podczas próby utworzenia aparatu OCR |
| Folder ścieżki danych nie istnieje | Wskazuje, że określony na potrzeby przechowywania danych języka folder nie istnieje |
| Wybrany pakiet językowy systemu Windows nie jest zainstalowany na maszynie | Wskazuje, że wybrany pakiet językowy systemu Windows nie został zainstalowany na komputerze |
| Aparat OCR nie jest aktywny | Wskazuje, że aparat OCR nie jest aktywny |