Wykonywanie optycznego rozpoznawania znaków (OCR) w dokumentach wielojęzycznych
Optyczne rozpoznawanie znaków (OCR) umożliwia lokalizowanie i wyodrębnianie tekstu z obrazów lub ekranu.
Chociaż większość scenariuszy wymaga obsługi tekstu w określonym języku, zdarzają się przypadki, gdy źródła są wielojęzyczne.
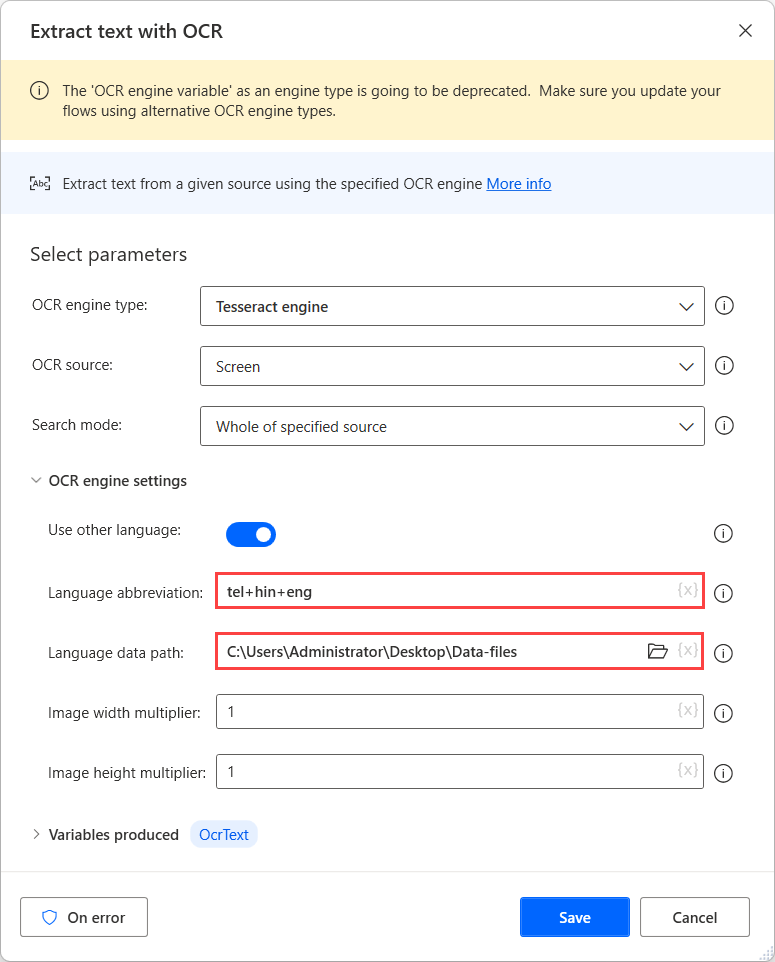
Aby wykonać OCR na tych źródłach, należy użyć silnika Tesseract w odpowiedniej akcji OCR i włączyć opcję Użyj innych języków w ustawieniach silnika.
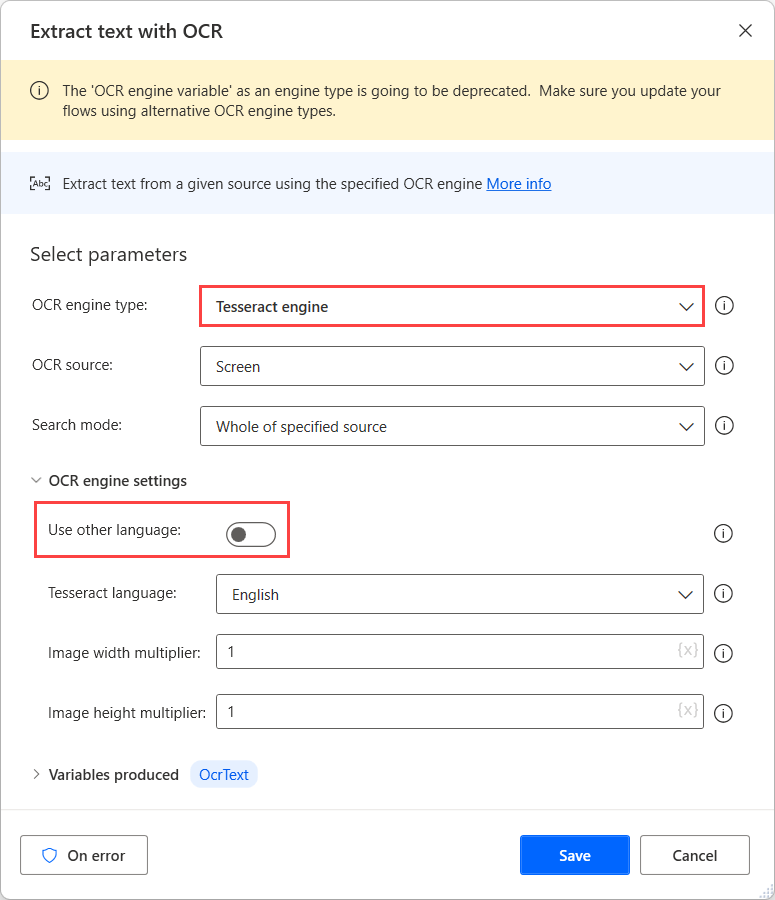
Po włączeniu opcji Użyj innych języków akcja wyświetla dwa dodatkowe ustawienia: pola Skrót języka i Ścieżka danych języka.
Pole Skrót językowy wskazuje silnikowi, jakiego języka ma szukać podczas OCR. Pole Ścieżka danych językowych zawiera pliki danych językowych (.traineddata) używane do trenowania silnika OCR.
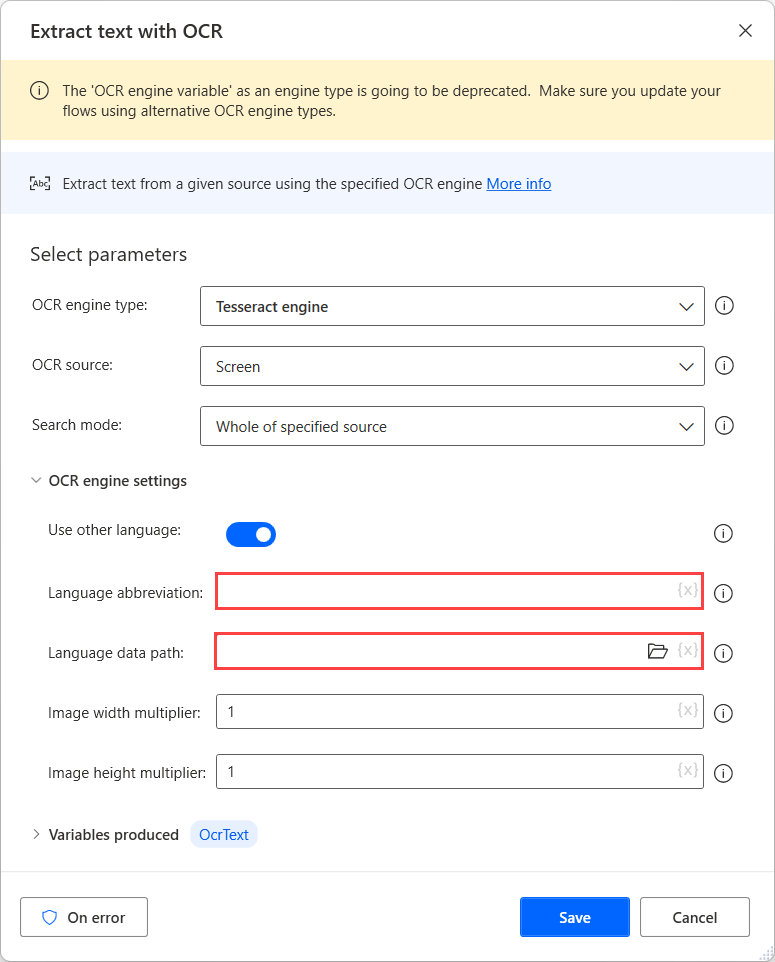
Po pobraniu plików danych dla potrzebnych języków, przenieś je do wspólnego folderu, aby były dostępne pod tą samą ścieżką.
Następnie w polu Scieżka dostępu do danych językowych wybieramy utworzony folder, a w polu Skrót języka wpisujemy odpowiednie kody języków. Aby oddzielić kody języków, należy użyć znaku plus (+).
Uwaga
Wszystkie dostępne kody języków można znaleźć w źródle plików danych językowych. W poniższym przykładzie użyte kody reprezentują języki: telugu, hindi i angielski.