Pozyskiwanie danych Dataverse za pomocą usługi Azure Data Factory
Po wyeksportowaniu danych z Microsoft Dataverse do Azure Data Lake Storage Gen2 za pomocą Azure Synapse Link for Dataverse, można użyć Azure Data Factory do tworzenia przepływów danych, transformacji danych i przeprowadzania analiz.
Uwaga
Azure Synapse Link for Dataverse, wcześniej znane jako Eksportowanie do data lake. Nazwa usługi została zmieniona w maja 2021 r. i nadal będzie eksportować dane do Azure Data Lake oraz Azure Synapse Analytics.
W tym artykule opisano, jak wykonać następujące zadania:
Ustaw konto magazynu Gen2 Data Lake Storage z danymi Dataverse jako źródło w przepływie danych Data Factory.
Przekształcanie danych Dataverse w Azure Data Factory przy użyciu przepływu danych.
Ustaw konto magazynu Gen2 Data Lake Storage z danymi Dataverse jako ujście w przepływie danych Data Factory.
Uruchom przepływ danych, tworząc potok.
Wymagania wstępne
W tej sekcji opisano wymagania wstępne niezbędne do wyeksportowania danych Dataverse przy użyciu Data Factory.
Role platformy Azure. Konto użytkownika, które zostało użyte do zalogowania się na platformie Azure, musi należeć do roli współautor lub właściciel albo administrator subskrypcji platformy Azure. Aby wyświetlić uprawnienia użytkownika w subskrypcji, przejdź do portalu Azure, wybierz swoją nazwę użytkownika w prawym górnym rogu, wybierz opcję ..., a następnie wybierz pozycję Moje uprawnienia. Jeśli masz dostęp do wielu subskrypcji, wybierz odpowiednią z nich. Aby tworzyć i zarządzać zasobami podrzędnymi dla fabryki danych w programie Azure portal — w tym zestawy danych, usługi połączone, potoki, wyzwalacze i środowiska uruchomieniowe integracji — użytkownik musi należeć do roli Współautor Factory Contributor na poziomie grupy zasobów lub wyższym.
Azure Synapse Link for Dataverse. W tym podręczniku przyjęto, że dane Dataverse zostały już wyeksportowane przy użyciu programu Azure Synapse Link for Dataverse. W tym przykładzie dane z tabeli kont są eksportowane do jeziora danych.
Azure Data Factory. W tym podręczniku przyjęto założenie, że fabryka danych została już utworzona w ramach tej samej subskrypcji i grupy zasobów, co konto magazynu zawierające wyeksportowane dane Dataverse.
Ustawianie konta magazynu programu Data Lake Storage Gen2 jako źródła
Otwórz Azure Data Factory i wybierz fabrykę danych w tej samej subskrypcji i grupie zasobów, co konto magazynu zawierające wyeksportowane dane Dataverse. Następnie na stronie głównej wybierz opcję Utwórz przepływ danych.
Włącz tryb debugowania przepływu danych i wybierz preferowany czas do wprowadzenia. Może to potrwać do 10 minut, ale można wykonać następujące kroki.

Wybierz Dodaj źródło danych.

W obszarze Ustawienia źródła wykonaj następujące operacje:
- Nazwa strumienia wyjściowego: wprowadź żądaną nazwę.
- Typ źródła: Wybierz śródwierszowy.
- Typ zestaw danych śródwierszowych: Wybierz wspólny model danych.
- Połączone usługi: wybierz konto magazynu z menu rozwijanego, a następnie połącz nową usługę, podając szczegóły subskrypcji i pozostawiając wszystkie domyślne ustawienia.
- Pobieranie próbek: Aby użyć wszystkich danych, należy wybrać opcję Wyłącz.
W obszarze Opcje źródła wykonaj następujące operacje:
Format metadanych: wybierz Model.json.
Lokalizacja główna: wprowadź nazwę kontenera w pierwszym polu (Kontener) lub wyszukaj nazwę kontenera i wybierz przycisk OK.
Encja: wprowadź nazwę tabeli lub Wyszukaj tabelę.

Sprawdź kartę Projekcja, aby upewnić się, że schemat został poprawnie zaimportowany. Jeśli nie ma żadnych kolumn, wybierz Opcje schematu i sprawdź opcję Typy kolumn inferowanych. Skonfiguruj opcje formatowania zgodne z zestawem danych, a następnie wybierz opcję Zastosuj.
Dane na karcie Podgląd danych można wyświetlić, aby upewnić się, że tworzenie źródła było pełne i dokładne.
Przekształcanie danych Dataverse
Po ustawieniu wyeksportowanych danych Dataverse na koncie Azure Data Lake Storage Gen2 jako źródła w przepływie danych Data Factory, istnieje wiele możliwości przekształcania danych. Więcej informacji: Azure Data Factory
Wykonaj te instrukcje, aby utworzyć klasyfikację dla każdego wiersza według przychodu tabeli klienta.
Wybierz + w prawym dolnym rogu poprzedniego przekształcenia, a następnie wyszukaj i wybierz opcję Klasyfikacja.
Na karcie Ustawienia klasyfikacji wprowadź poniższe informacje:
Nazwa strumienia wyjściowego: wprowadź nazwę, na przykład Ranga1.
Strumień przychodzący: wybierz żądaną nazwę źródła. W tym przypadku jest to nazwa źródłowa z poprzedniego kroku.
Opcje: pozostaw niezaznaczone opcje.
Kolumna klasyfikacji: Wprowadź nazwę wygenerowanej kolumny klasyfikacji.
Warunki sortowania: wybierz kolumnę przychodu i posortuj ją według porządku malejącego.
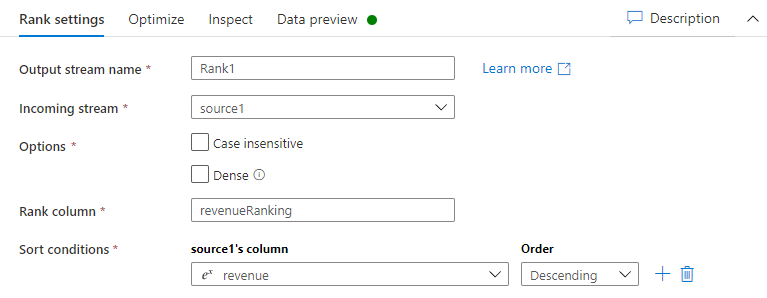
Dane można wyświetlić na karcie Podgląd danych, gdzie można znaleźć nową kolumnę revenueRank w prawym górnym rogu.
Ustawianie konta magazynu Data Lake Storage Gen2 jako magazynu danych
Ostatecznie należy ustawić ujście dla przepływu danych. Postępuj zgodnie z tymi instrukcjami, aby umieścić przekształcone dane jako rozdzielany plik tekstowy w data lake.
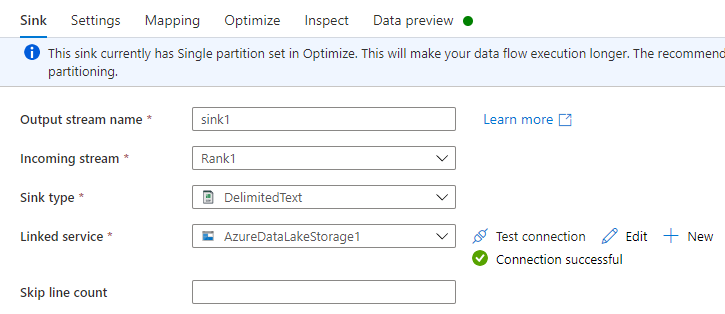
Wybierz + w prawym dolnym rogu poprzedniego przekształcenia, a następnie wyszukaj i wybierz opcję Magazyn.
Na karcie Ujście wykonaj jedną z następujących czynności:
Nazwa strumienia wyjściowego: wprowadź żądaną nazwę, taką jak Ujście1.
Strumień przychodzący: wybierz żądaną nazwę źródła. W tym przypadku jest to nazwa źródłowa z poprzedniego kroku.
Typ magazynu Wybierz DelimitedText.
Powiązana usługa: wybierz swój kontener Data Lake Storage Gen2, w którym znajdują się dane wyeksportowane za pomocą usługi Azure Synapse Link for Dataverse.
Na karcie Ustawienia można wykonać następujące czynności:
Ścieżka do folderu: wprowadź nazwę kontenera w pierwszym polu (System pliku) lub wyszukaj nazwę kontenera i wybierz przycisk OK.
Opcja nazwy pliku: wybierz plik wyjściowy do pojedynczego pliku.
Plik wyjściowy do pojedynczego pliku: wprowadź nazwę pliku, na przykład ADFOutbut
Pozostaw wszystkie inne ustawienia domyślne.
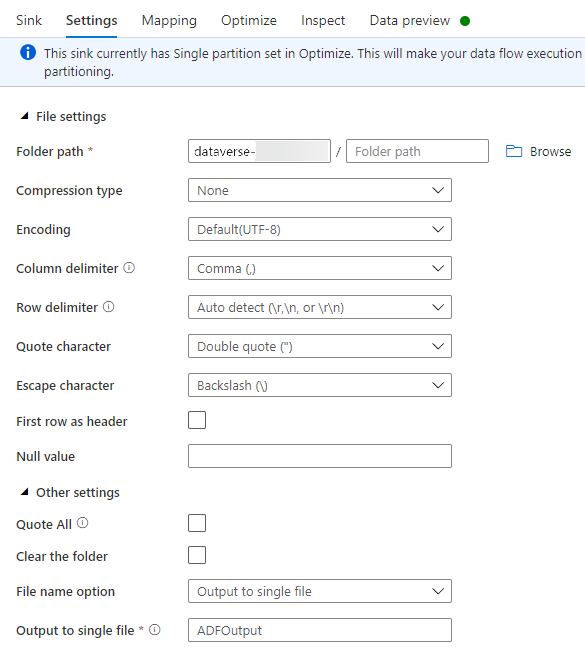
Na karcie Optymalizowanie ustaw opcję Partycja na wartość Pojedyncza partycja.
Dane można wyświetlać na karcie Podgląd danych.
Uruchom przepływ danych
W lewym okienku w obszarze Zasoby fabryki wybierz opcję +, a następnie wybierz opcję Potok.

W obszarze Działania wybierz opcję Przenieś i przekształć, a następnie przeciągnij Przepływ danych do obszaru roboczego.
Wybierz opcję Użyj istniejącego przepływu danych, a następnie wybierz przepływ danych utworzony w poprzednich krokach.
Na pasku poleceń wybierz Debuguj.
Niech przepływ danych będzie uruchamiany, dopóki nie zostanie wyświetlony widok najniższego poziomu. Może to potrwać kilka minut.
Przejdź do ostatniego docelowego kontenera magazynu i znajdź plik z przekształconymi danymi tabeli.
Zobacz także
Konfigurowanie usługi Azure Synapse Link for Dataverse do działania z usługą Azure Data Lake
Analizowanie danych Dataverse w Azure Data Lake Storage Gen2 za pomocą usługi Power BI
Uwaga
Czy możesz poinformować nas o preferencjach dotyczących języka dokumentacji? Wypełnij krótką ankietę. (zauważ, że ta ankieta jest po angielsku)
Ankieta zajmie około siedmiu minut. Nie są zbierane żadne dane osobowe (oświadczenie o ochronie prywatności).