series_fit_poly()
Dotyczy: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Stosuje regresję wielomianową z zmiennej niezależnej (x_series) do zmiennej zależnej (y_series). Ta funkcja przyjmuje tabelę zawierającą wiele serii (dynamicznych tablic liczbowych) i generuje najlepsze dopasowanie wielomianu o wysokiej kolejności dla każdej serii przy użyciu regresji wielomianowej.
Napiwek
- W przypadku regresji liniowej serii równomiernie rozmieszczonej, utworzonej przez operator serii make, użyj prostszej funkcji series_fit_line(). Zobacz przykład 2.
- Jeśli x_series jest dostarczany, a regresja jest wykonywana dla wysokiego stopnia, rozważ normalizację zakresu [0–1]. Zobacz przykład 3.
- Jeśli x_series jest typu data/godzina, należy go przekonwertować na podwójne i znormalizowane. Zobacz przykład 3.
- Aby uzyskać informacje na temat implementacji regresji wielomianowej przy użyciu wbudowanego języka Python, zobacz series_fit_poly_fl().
Składnia
T | extend series_fit_poly( y_series [ , x_series, stopień ])
Dowiedz się więcej na temat konwencji składni.
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| y_series | dynamic |
✔️ | Tablica wartości liczbowych zawierająca zmienną zależną. |
| x_series | dynamic |
Tablica wartości liczbowych zawierająca zmienną niezależną. Wymagane tylko dla nierównomiernie rozmieszczonych serii. Jeśli nie zostanie określony, zostanie ustawiona wartość domyślna [1, 2, ..., length(y_series)]. | |
| stopień | Wymagana kolejność wielomianu do dopasowania. Na przykład 1 dla regresji liniowej, 2 dla regresji kwadratowej itd. Wartość domyślna to 1, która wskazuje regresję liniową. |
Zwraca
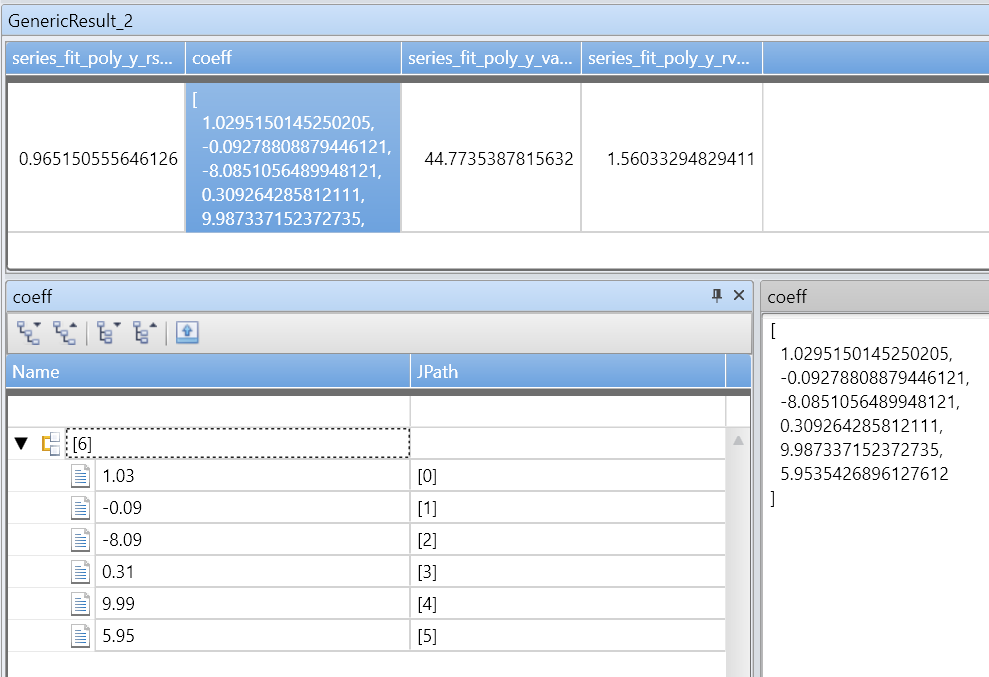
Funkcja series_fit_poly() zwraca następujące kolumny:
rsquare: r-square jest standardową miarą jakości dopasowania. Wartość jest liczbą w zakresie [0–1], gdzie 1 — jest najlepszym możliwym dopasowaniem, a 0 oznacza, że dane nie są uporządkowane i nie mieszczą się w żadnej linii.coefficients: Tablica liczbowa zawierająca współczynniki najlepiej dopasowanego wielomianu z danym stopniem, uporządkowane od najwyższego współczynnika mocy do najniższego.variance: wariancja zmiennej zależnej (y_series).rvariance: Wariancja reszt, która jest wariancją między wartościami danych wejściowych przybliżonymi.poly_fit: Tablica liczbowa zawierająca serię wartości najlepiej dopasowanego wielomianu. Długość serii jest równa długości zmiennej zależnej (y_series). Wartość używana do tworzenia wykresów.
Przykłady
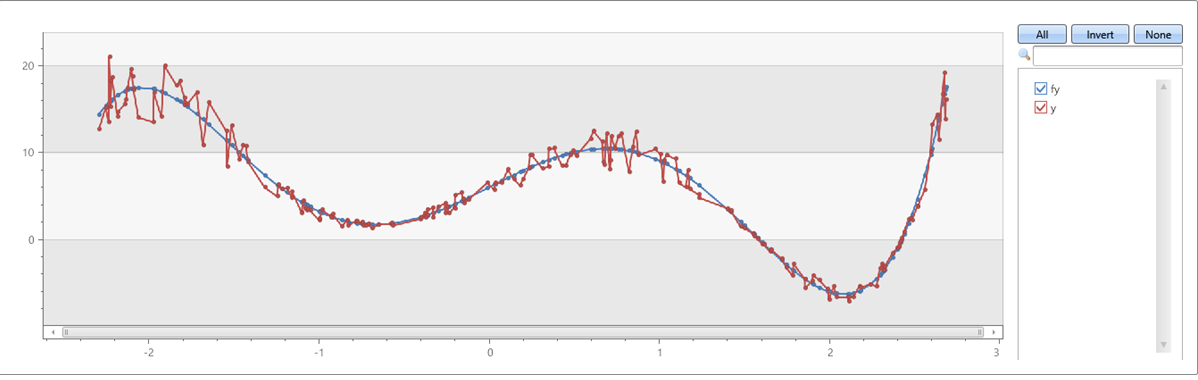
Przykład 1
Piąty wielomian z szumem na osiach x i y:
range x from 1 to 200 step 1
| project x = rand()*5 - 2.3
| extend y = pow(x, 5)-8*pow(x, 3)+10*x+6
| extend y = y + (rand() - 0.5)*0.5*y
| summarize x=make_list(x), y=make_list(y)
| extend series_fit_poly(y, x, 5)
| project-rename fy=series_fit_poly_y_poly_fit, coeff=series_fit_poly_y_coefficients
|fork (project x, y, fy) (project-away x, y, fy)
| render linechart
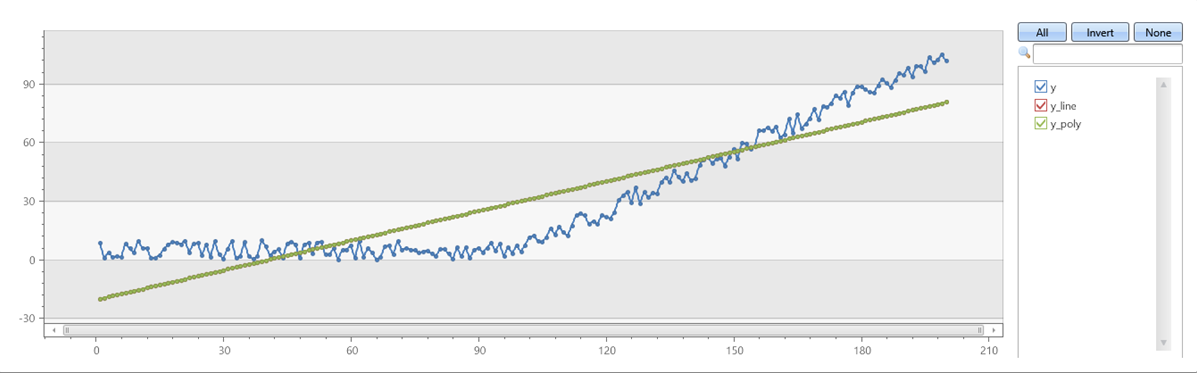
Przykład 2
Sprawdź, czy series_fit_poly z stopniem=1 pasuje series_fit_linedo elementu :
demo_series1
| extend series_fit_line(y)
| extend series_fit_poly(y)
| project-rename y_line = series_fit_line_y_line_fit, y_poly = series_fit_poly_y_poly_fit
| fork (project x, y, y_line, y_poly) (project-away id, x, y, y_line, y_poly)
| render linechart with(xcolumn=x, ycolumns=y, y_line, y_poly)

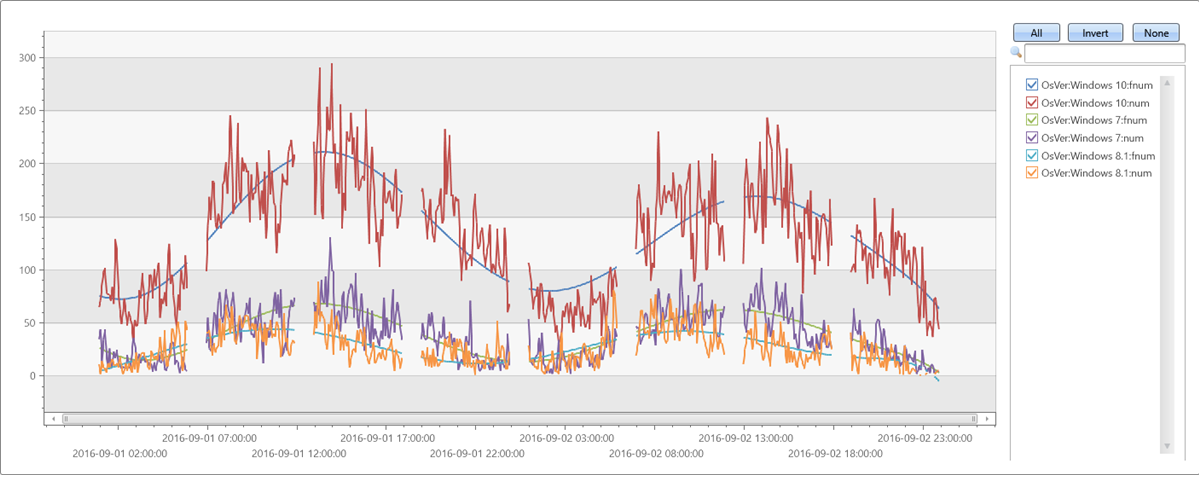
Przykład 3
Nieregularne (nierówno rozmieszczone) szeregi czasowe:
//
// x-axis must be normalized to the range [0-1] if either degree is relatively big (>= 5) or original x range is big.
// so if x is a time axis it must be normalized as conversion of timestamp to long generate huge numbers (number of 100 nano-sec ticks from 1/1/1970)
//
// Normalization: x_norm = (x - min(x))/(max(x) - min(x))
//
irregular_ts
| extend series_stats(series_add(TimeStamp, 0)) // extract min/max of time axis as doubles
| extend x = series_divide(series_subtract(TimeStamp, series_stats__min), series_stats__max-series_stats__min) // normalize time axis to [0-1] range
| extend series_fit_poly(num, x, 8)
| project-rename fnum=series_fit_poly_num_poly_fit
| render timechart with(ycolumns=num, fnum)