Pobierz dane ze strumienia zdarzeń
Z tego artykułu dowiesz się, jak pobrać dane z istniejącego strumienia zdarzeń do nowej lub istniejącej tabeli.
Aby pobrać dane z nowego strumienia zdarzeń, zobacz Pobieranie danych z nowego strumienia zdarzeń.
Warunki wstępne
- Obszar roboczy z włączoną pojemnością usługi Microsoft Fabric
- baza KQL z uprawnieniami do edycji
- strumienia zdarzeń ze źródłem danych
Źródło
Aby pobrać dane z strumienia zdarzeń, musisz wybrać strumień zdarzeń jako źródło danych. Możesz wybrać istniejący strumień zdarzeń w następujący sposób:
Na dolnej wstążce bazy danych KQL wybierz jedną z opcji:
Z menu rozwijanego Pobierz dane, następnie w sekcji Continuous, wybierz pozycję Eventstream>Existing Eventstream.
Wybierz pozycję Pobierz dane, a następnie w oknie Pobierz dane wybierz pozycję Eventstream.
Z menu rozwijanego Pobierz dane w obszarze Continuouswybierz pozycję Real-Time data hub>Existing Eventstream.


Skonfiguruj
Wybierz tabelę docelową. Jeśli chcesz pozyskać dane do nowej tabeli, wybierz pozycję + Nowa tabela i wprowadź nazwę tabeli.
Notatka
Nazwy tabel mogą zawierać maksymalnie 1024 znaki, w tym spacje, alfanumeryczne, łączniki i podkreślenia. Znaki specjalne nie są obsługiwane.
W obszarze Skonfiguruj źródło danych, wypełnij ustawienia, korzystając z informacji w poniższej tabeli:
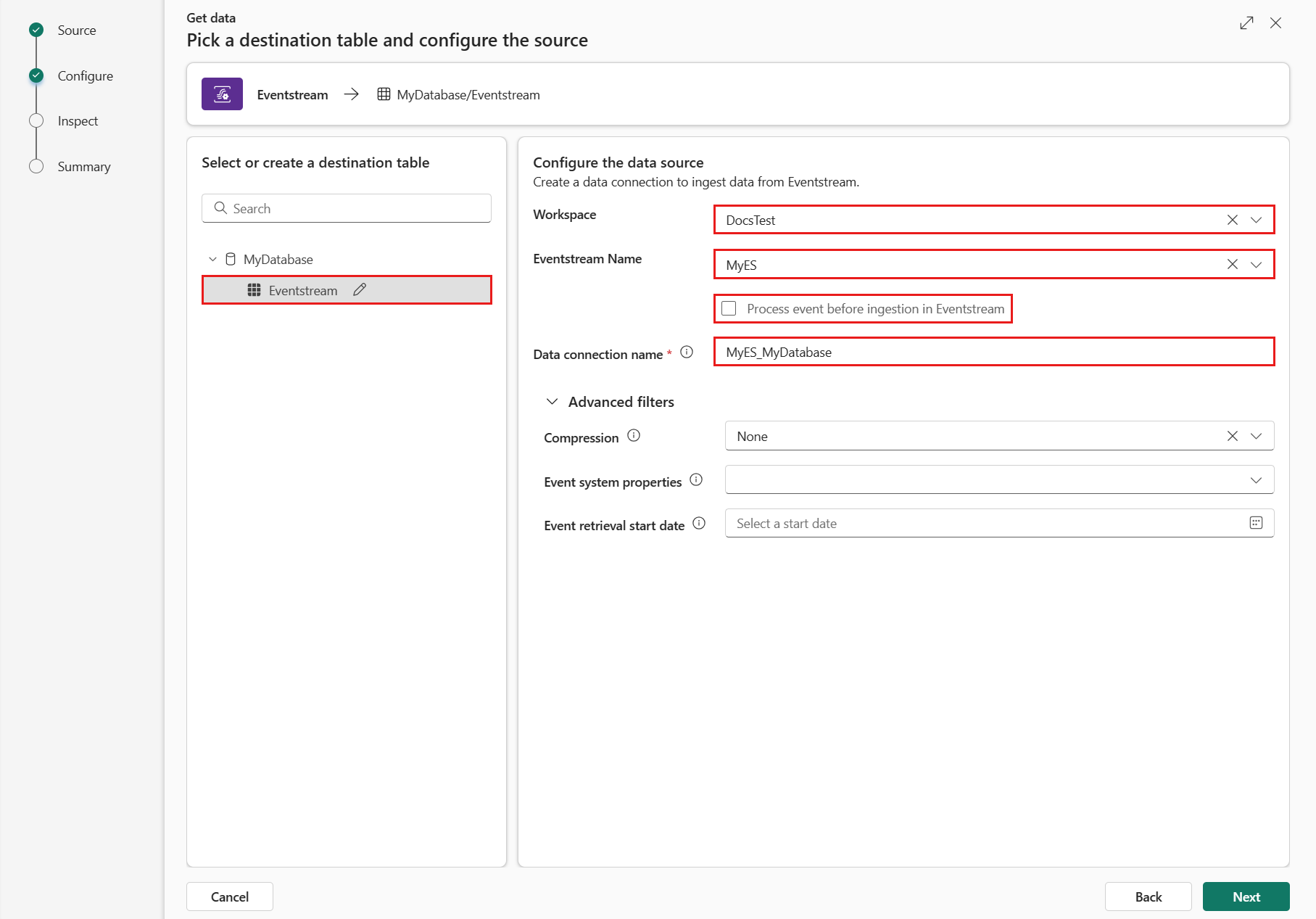
ustawienie opis Obszar roboczy Lokalizacja przestrzeni roboczej strumienia zdarzeń. Wybierz obszar roboczy z listy rozwijanej. Nazwa strumienia zdarzeń Nazwa strumienia zdarzeń. Wybierz strumień zdarzeń z listy rozwijanej. Nazwa połączenia danych Nazwa używana do odniesienia się do łącza danych i zarządzania nim w obszarze roboczym. Nazwa połączenia danych jest wypełniana automatycznie. Opcjonalnie możesz wprowadzić nową nazwę. Nazwa może zawierać tylko znaki alfanumeryczne, kreskowe i kropkowe oraz maksymalnie 40 znaków. Przetwarzanie zdarzenia przed przyjmowaniem w strumieniu zdarzeń Ta opcja umożliwia skonfigurowanie przetwarzania danych przed ich załadowaniem do tabeli docelowej. W przypadku wybrania opcji kontynuuj proces pozyskiwania danych w usłudze Eventstream. Aby uzyskać więcej informacji, zobacz "Procesowanie zdarzenia przed przetworzeniem w Eventstream". filtry zaawansowane Kompresja Kompresja danych zdarzeń pochodzących z centrum zdarzeń. Opcje to Brak (wartość domyślna) lub Kompresja Gzip. Właściwości systemu zdarzeń Jeśli jest wiele rekordów w komunikacie zdarzenia, właściwości systemu są dodawane do pierwszego. Aby uzyskać więcej informacji, przejrzyj właściwości systemu zdarzeń. Data rozpoczęcia pobierania zdarzeń Połączenie danych pobiera istniejące zdarzenia utworzone od daty rozpoczęcia pobierania zdarzeń. Może pobierać tylko te zdarzenia, które są przechowywane w centrum zdarzeń zgodnie z jego okresem przechowywania. Strefa czasowa to UTC. Jeśli nie określono czasu, domyślny czas to czas, w którym jest tworzone połączenie danych. Wybierz Dalej

Przetwarzanie zdarzenia przed wprowadzeniem w strumień zdarzeń
Opcja Process przed wprowadzeniem danych w usłudze Eventstream umożliwia przetwarzanie danych przed ich wprowadzeniem do tabeli docelowej. Dzięki tej opcji proces pobierania danych jest bezproblemowo kontynuowany w usłudze Eventstream, a szczegóły tabeli docelowej i źródła danych są wypełniane automatycznie.
Aby przetworzyć zdarzenie przed wczytywaniem w strumieniu zdarzeń:
Na karcie Skonfiguruj wybierz Zdarzenie procesu przed pobraniem w strumieniu zdarzeń.
W oknie dialogowym Przetwarzanie zdarzeń w Eventstream wybierz Kontynuuj w Eventstream.
Ważny
Wybranie Kontynuuj w Eventstream kończy proces pobierania danych w Real-Time Intelligence i automatycznie przechodzi dalej w Eventstream z wypełnioną tabelą docelową oraz szczegółami źródła danych.
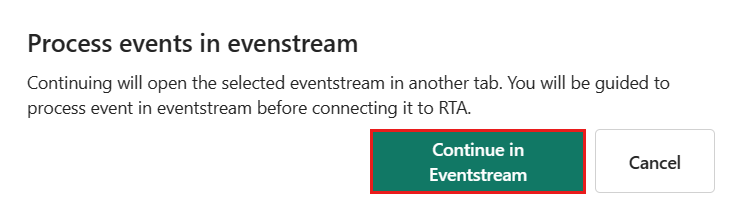
W Eventstream wybierz węzeł docelowy KQL Database, a w okienku KQL Database sprawdź, czy przetwarzanie zdarzeń przed pozyskiwaniem jest zaznaczone i czy szczegóły miejsca docelowego są poprawne.
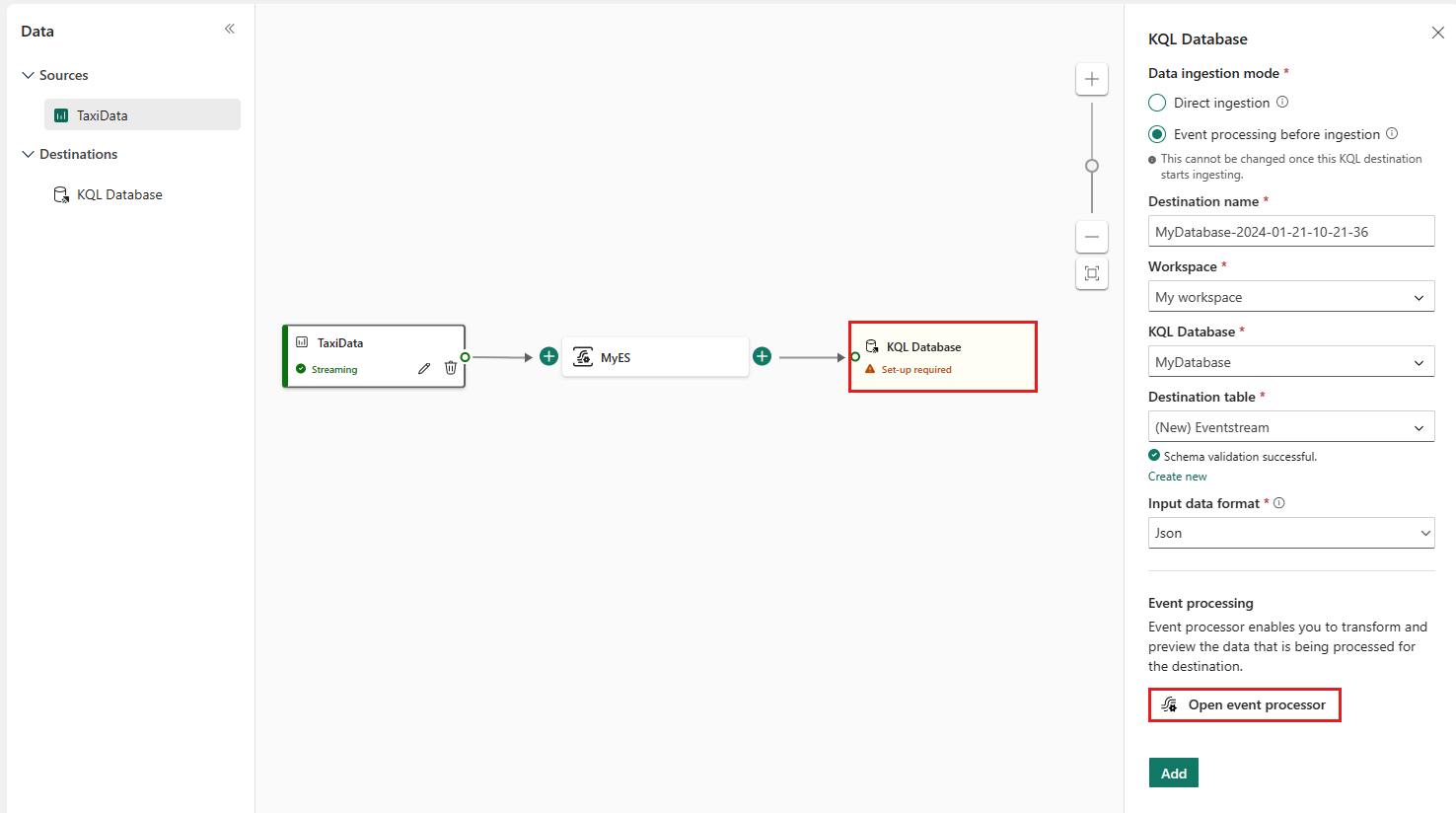
Wybierz pozycję Otwórz procesor zdarzeń, aby skonfigurować przetwarzanie danych, a następnie wybierz pozycję Zapisz. Aby uzyskać więcej informacji, zobacz Przetwarzanie danych zdarzeń za pomocą edytora procesora zdarzeń.
W okienku bazy danych KQL wybierz Dodaj, aby ukończyć konfigurację węzła docelowego bazy danych KQL.
Sprawdź, czy dane są wczytywane do tabeli docelowej.


Notatka
Nie trzeba wykonywać pozostałych kroków opisanych w tym artykule, ponieważ zdarzenie procesu przed pobraniem danych w procesie strumienia zdarzeń zostało już ukończone.
Inspekcjonować
Zakładka Przegląd otwiera się z podglądem danych.
Aby ukończyć proces pozyskiwania, wybierz Zakończ.

Opcjonalnie:
- Wybierz Podgląd poleceń, aby wyświetlić i skopiować polecenia automatyczne wygenerowane na podstawie danych wejściowych.
- Zmień automatycznie wnioskowany format danych, wybierając żądany format z listy rozwijanej. Dane są odczytywane z centrum zdarzeń w postaci obiektów EventData. Obsługiwane formaty to CSV, JSON, PSV, SCsv, SOHsv TSV, TXT i TSVE.
- Edytuj kolumny.
- Poznaj opcje zaawansowane oparte na typie danych.
Edytowanie kolumn
Notatka
- W przypadku formatów tabelarycznych (CSV, TSV, PSV) nie można dwukrotnie mapować kolumny. Aby dopasować do istniejącej kolumny, najpierw usuń nową kolumnę.
- Nie można zmienić istniejącego typu kolumny. Jeśli spróbujesz mapować kolumnę na inny format, może się okazać, że kolumny będą puste.
Zmiany, które można wprowadzić w tabeli, zależą od następujących parametrów:
- typ tabeli jest nowy lub istniejący
- Typ mapowania jest nowy lub istniejący
| Typ tabeli | Typ mapowania | Dostępne korekty |
|---|---|---|
| Nowa tabela | Nowe mapowanie | Zmienianie nazwy kolumny, zmienianie typu danych, zmienianie źródła danych, przekształcanie mapowania, dodawanie kolumny, usuwanie kolumny |
| Istniejąca tabela | Nowe mapowanie | Dodaj kolumnę (na której można następnie zmienić typ danych, zmienić nazwę i zaktualizować) |
| Istniejąca tabela | Istniejące mapowanie | żaden |

Przekształcenia mapowania
Niektóre mapowania formatów danych (Parquet, JSON i Avro) obsługują proste przekształcenia przy wprowadzaniu. Aby zastosować przekształcenia mapowania, utwórz lub zaktualizuj kolumnę w oknie Edytuj kolumny.
Przekształcenia mapowania można wykonać na kolumnie typu ciąg znaków lub data/godzina, przy czym źródło może mieć typ danych int lub long. Obsługiwane przekształcenia mapowania to:
- CzasDataZUnixowychSekund
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opcje zaawansowane oparte na typie danych
tabelaryczne (CSV, TSV, PSV):
Dane tabelaryczne nie muszą zawierać nazw kolumn używanych do mapowania danych źródłowych na istniejące kolumny. Aby użyć pierwszego wiersza jako nazw kolumn, włącz Pierwszy wiersz to nagłówek kolumny.

JSON:
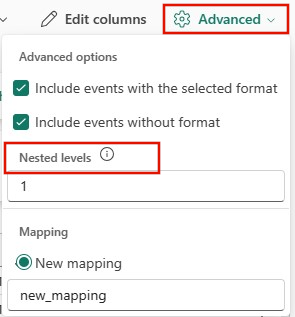
Aby określić podział kolumn danych JSON, wybierz Zaawansowane poziomy>zagnieżdżone, w zakresie od 1 do 100.
Streszczenie
W oknie przygotowywania danych , wszystkie trzy kroki są oznaczone zielonymi znacznikami wyboru po pomyślnym zakończeniu przetwarzania danych. Możesz wybrać kartę, aby wykonać zapytanie, usunąć pozyskane dane lub wyświetlić pulpit nawigacyjny podsumowania pozyskiwania. Wybierz pozycję Zamknij, aby zamknąć okno.

Powiązana zawartość
- Aby zarządzać bazą danych, zobacz Zarządzanie danymi
- Aby tworzyć, przechowywać i eksportować zapytania, zobacz Zapytanie danych w zestawie zapytań KQL