Pobieranie danych z usługi Azure Event Hubs
Z tego artykułu dowiesz się, jak pobrać dane z usługi Event Hubs do bazy danych KQL w usłudze Microsoft Fabric. Azure Event Hubs to platforma przesyłania strumieniowego danych big data i usługa pozyskiwania zdarzeń, która może przetwarzać i kierować miliony zdarzeń na sekundę.
Aby przesyłać strumieniowo dane z usługi Event Hubs do analizy w czasie rzeczywistym, wykonaj dwa główne kroki. Pierwszy krok jest wykonywany w witrynie Azure Portal, gdzie definiujesz zasady dostępu współdzielonego w wystąpieniu centrum zdarzeń i przechwytujesz szczegóły potrzebne do późniejszego nawiązania połączenia za pośrednictwem tych zasad.
Drugi krok odbywa się w usłudze Analizy w czasie rzeczywistym w sieci szkieletowej, gdzie łączysz bazę danych KQL z centrum zdarzeń i konfigurujesz schemat dla danych przychodzących. Ten krok tworzy dwa połączenia. Pierwsze połączenie nazywane "połączeniem w chmurze" łączy usługę Microsoft Fabric z wystąpieniem centrum zdarzeń. Drugie połączenie łączy "połączenie w chmurze" z bazą danych KQL. Po zakończeniu konfigurowania danych zdarzeń i schematu przesyłane strumieniowo dane są dostępne do wykonywania zapytań przy użyciu zestawu zapytań KQL.
Aby uzyskać dane z usługi Event Hubs przy użyciu usługi EventStream, zobacz Dodawanie źródła usługi Azure Event Hubs do strumienia zdarzeń.
Wymagania wstępne
- Subskrypcja platformy Azure. Utwórz bezpłatne konto platformy Azure
- Centrum zdarzeń
- Obszar roboczy z pojemnością z włączoną usługą Microsoft Fabric
- Baza danych KQL z uprawnieniami do edycji
Ostrzeżenie
Centrum zdarzeń nie może znajdować się za zaporą.
Ustawianie zasad dostępu współdzielonego w centrum zdarzeń
Przed utworzeniem połączenia z danymi usługi Event Hubs należy ustawić zasady dostępu współdzielonego (SAS) w centrum zdarzeń i zebrać informacje, które mają być używane później podczas konfigurowania połączenia. Aby uzyskać więcej informacji na temat autoryzowania dostępu do zasobów usługi Event Hubs, zobacz Sygnatury dostępu współdzielonego.
W witrynie Azure Portal przejdź do wystąpienia centrum zdarzeń, z którym chcesz nawiązać połączenie.
W obszarze Ustawienia wybierz pozycję Zasady dostępu współdzielonego
Wybierz pozycję +Dodaj , aby dodać nowe zasady sygnatury dostępu współdzielonego lub wybierz istniejące zasady z uprawnieniami zarządzanie .
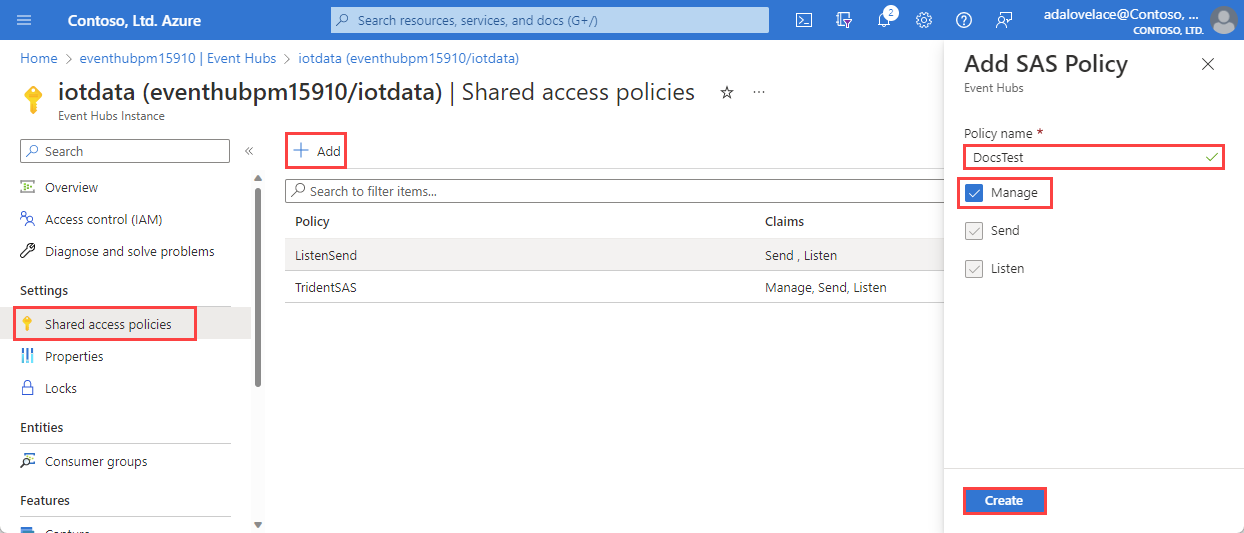
Wprowadź nazwę zasad.
Wybierz pozycję Zarządzaj, a następnie pozycję Utwórz.

Zbieranie informacji dotyczących połączenia w chmurze
W okienku zasad sygnatury dostępu współdzielonego zanotuj następujące cztery pola. Możesz skopiować te pola i wkleić je gdzieś, jak notatnik, aby użyć ich w późniejszym kroku.

| Odwołanie do pola | Pole | opis | Przykład |
|---|---|---|---|
| a | Wystąpienie usługi Event Hubs | Nazwa wystąpienia centrum zdarzeń. | iotdata |
| b | Zasady sygnatury dostępu współdzielonego | Nazwa zasad sygnatury dostępu współdzielonego utworzona w poprzednim kroku | DocsTest |
| c | Klucz podstawowy | Klucz skojarzony z zasadami sygnatury dostępu współdzielonego | W tym przykładzie zaczyna się od PGGIISb009... |
| d | Parametry połączenia — klucz podstawowy | W tym polu chcesz skopiować tylko przestrzeń nazw centrum zdarzeń, którą można znaleźć w ramach parametry połączenia. | eventhubpm15910.servicebus.windows.net |
Źródło
Na dolnej wstążce bazy danych KQL wybierz pozycję Pobierz dane.
W oknie Pobieranie danych zostanie wybrana karta Źródło.
Wybierz źródło danych z listy dostępnych. W tym przykładzie pozyskiwane są dane z usługi Event Hubs.


Konfiguruj
Wybierz tabelę docelową. Jeśli chcesz pozyskać dane do nowej tabeli, wybierz pozycję + Nowa tabela i wprowadź nazwę tabeli.
Uwaga
Nazwy tabel mogą zawierać maksymalnie 1024 znaki, w tym spacje, alfanumeryczne, łączniki i podkreślenia. Znaki specjalne nie są obsługiwane.
Wybierz pozycję Utwórz nowe połączenie lub wybierz pozycję Istniejące połączenie i przejdź do następnego kroku.
Utwórz nowe połączenie
Wypełnij ustawienia połączenia zgodnie z poniższą tabelą:
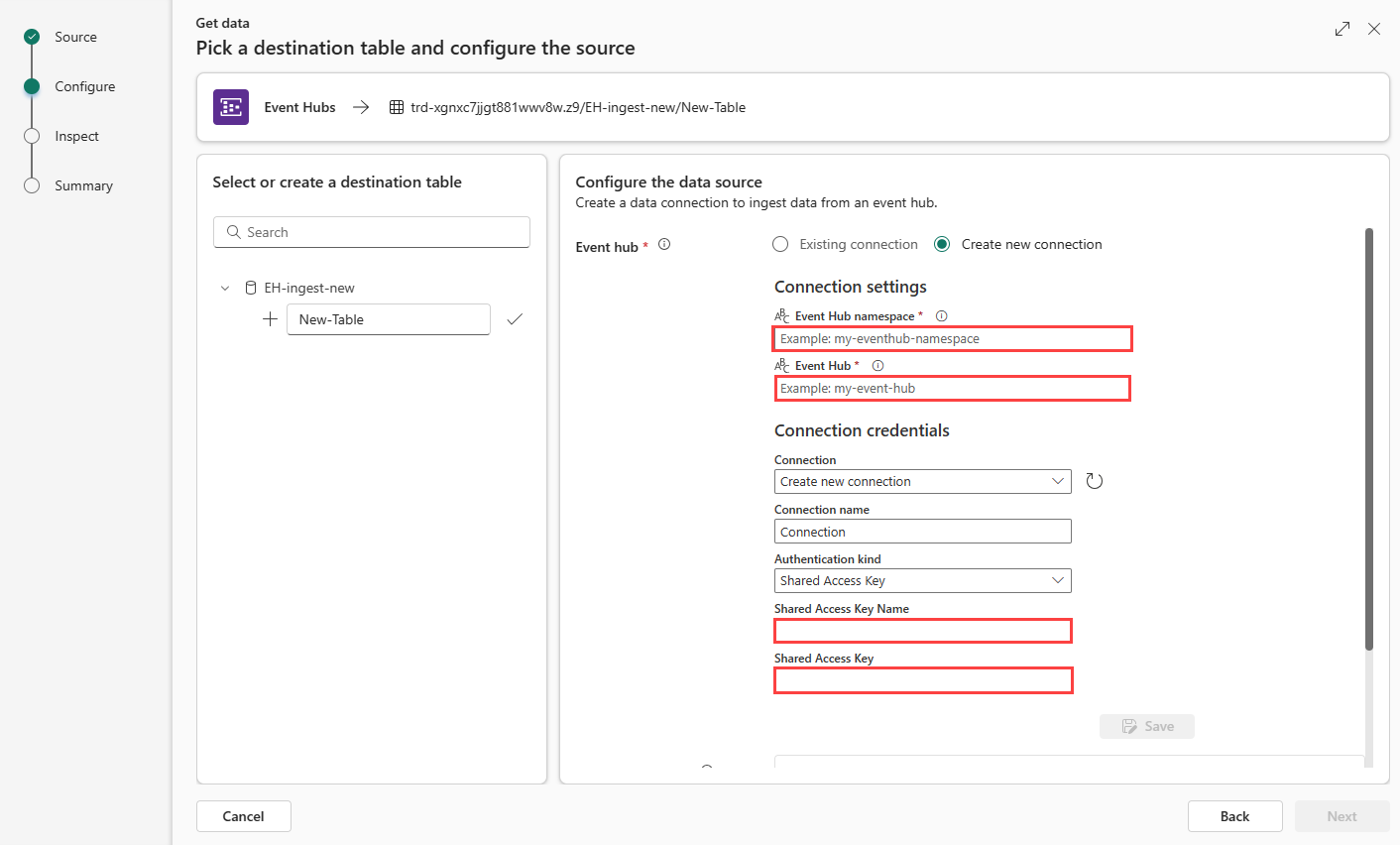
Wybierz pozycję Zapisz. Zostanie utworzone nowe połączenie danych w chmurze między usługą Fabric i usługą Event Hubs.

Łączenie połączenia w chmurze z bazą danych KQL
Niezależnie od tego, czy utworzono nowe połączenie w chmurze, czy używasz istniejącego, musisz zdefiniować grupę odbiorców. Opcjonalnie można ustawić parametry, które dodatkowo definiują aspekty połączenia między bazą danych KQL i połączeniem w chmurze.
Wypełnij następujące pola zgodnie z tabelą:
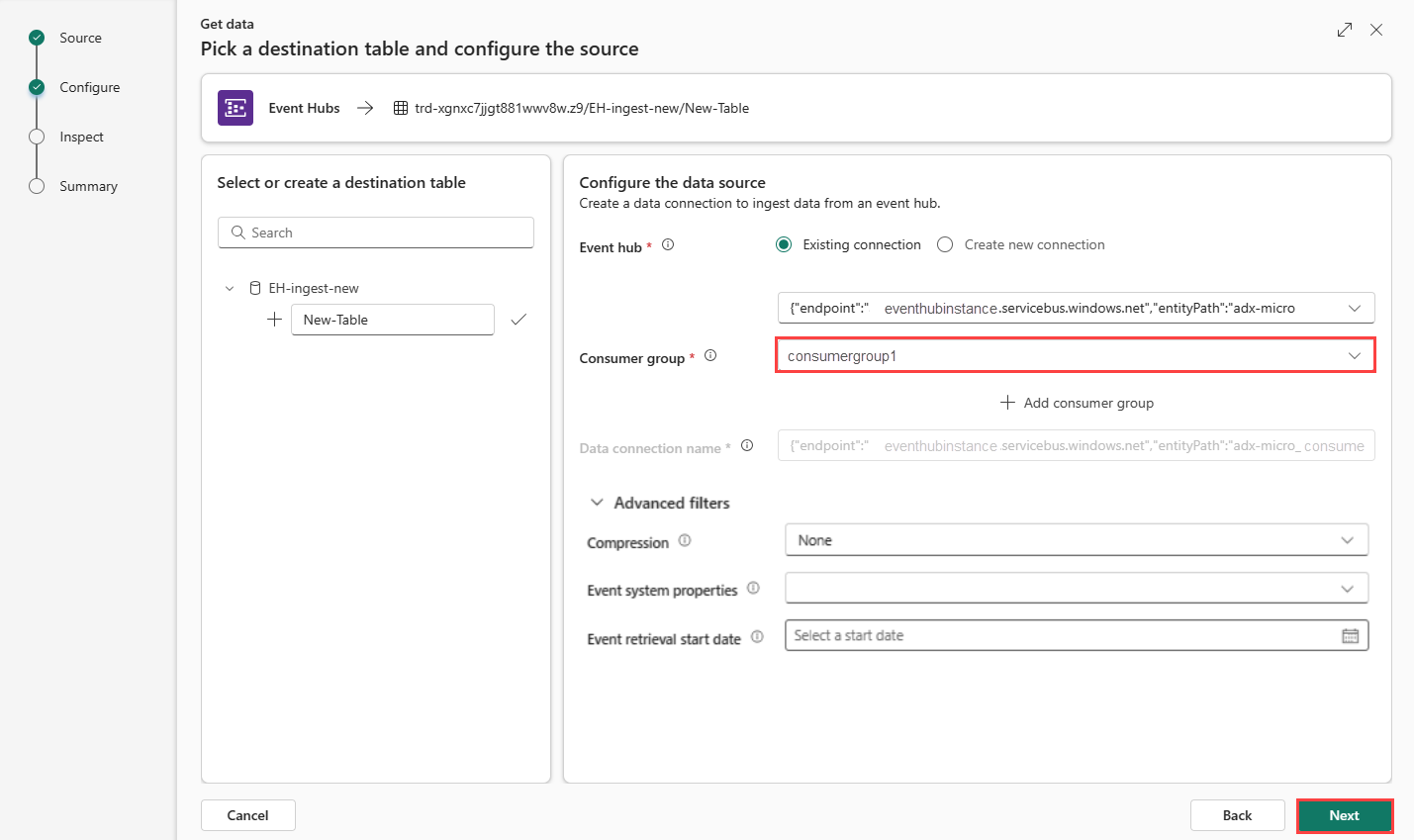
Ustawienie Opis Przykładowa wartość Grupa konsumentów Odpowiednia grupa odbiorców zdefiniowana w centrum zdarzeń. Aby uzyskać więcej informacji, zobacz grupy odbiorców. Po dodaniu nowej grupy odbiorców musisz wybrać tę grupę z listy rozwijanej. NewConsumer Więcej parametrów Kompresja Kompresja danych zdarzeń pochodzących z centrum zdarzeń. Opcje to Brak (wartość domyślna) lub Kompresja Gzip. Brak Właściwości systemu zdarzeń Aby uzyskać więcej informacji, zobacz Właściwości systemu centrum zdarzeń. Jeśli istnieje wiele rekordów na komunikat zdarzenia, właściwości systemu są dodawane do pierwszego. Zobacz właściwości systemu zdarzeń. Data rozpoczęcia pobierania zdarzeń Połączenie danych pobiera istniejące zdarzenia centrum zdarzeń utworzone od daty rozpoczęcia pobierania zdarzeń. Może pobierać tylko zdarzenia przechowywane przez centrum zdarzeń na podstawie okresu przechowywania. Strefa czasowa to UTC. Jeśli nie określono czasu, domyślny czas to czas, w którym jest tworzone połączenie danych. Wybierz przycisk Dalej, aby przejść do karty Inspekcja.
Właściwości systemu zdarzeń
Właściwości systemu przechowują właściwości, które są ustawiane przez usługę Event Hubs w momencie kolejkowania zdarzenia. Połączenie danych z centrum zdarzeń może osadzić wybrany zestaw właściwości systemowych w danych pozyskanych do tabeli na podstawie danego mapowania.
| Właściwości | Typ danych | opis |
|---|---|---|
| x-opt-enqueued-time | datetime | Czas UTC, kiedy zdarzenie zostało w kolejce. |
| x-opt-sequence-number | długi | Numer sekwencji logicznej zdarzenia w strumieniu partycji centrum zdarzeń. |
| przesunięcie x-opt-offset | string | Przesunięcie zdarzenia ze strumienia partycji centrum zdarzeń. Identyfikator przesunięcia jest unikatowy w ramach partycji strumienia centrum zdarzeń. |
| x-opt-publisher | string | Nazwa wydawcy, jeśli wiadomość została wysłana do punktu końcowego wydawcy. |
| x-opt-partition-key | string | Klucz partycji odpowiadającej partycji, która przechowywała zdarzenie. |
Kontrola
Aby ukończyć proces pozyskiwania, wybierz pozycję Zakończ.

Opcjonalnie:
Wybierz pozycję Przeglądarka poleceń, aby wyświetlić i skopiować polecenia automatyczne wygenerowane na podstawie danych wejściowych.
Zmień automatycznie wnioskowany format danych, wybierając żądany format z listy rozwijanej. Dane są odczytywane z centrum zdarzeń w postaci obiektów EventData . Obsługiwane formaty to CSV, JSON, PSV, SCsv, SOHsv TSV, TXT i TSVE.
Zapoznaj się z opcjami zaawansowanymi na podstawie typu danych.
Jeśli dane widoczne w oknie podglądu nie są kompletne, może być konieczne utworzenie tabeli ze wszystkimi niezbędnymi polami danych. Użyj następujących poleceń, aby pobrać nowe dane z centrum zdarzeń:
- Odrzuć i pobierz nowe dane: odrzuca prezentowane dane i wyszukuje nowe zdarzenia.
- Pobierz więcej danych: wyszukuje więcej zdarzeń oprócz znalezionych już zdarzeń.
Edytuj kolumny
Uwaga
- W przypadku formatów tabelarycznych (CSV, TSV, PSV) nie można dwukrotnie mapować kolumny. Aby zamapować na istniejącą kolumnę, najpierw usuń nową kolumnę.
- Nie można zmienić istniejącego typu kolumny. Jeśli spróbujesz mapować kolumnę na inny format, może się okazać, że kolumny będą puste.
Zmiany, które można wprowadzić w tabeli, zależą od następujących parametrów:
- Typ tabeli jest nowy lub istniejący
- Typ mapowania to nowy lub istniejący
| Typ tabeli | Typ mapowania | Dostępne korekty |
|---|---|---|
| Nowa tabela | Nowe mapowanie | Zmienianie nazwy kolumny, zmienianie typu danych, zmienianie źródła danych, przekształcanie mapowania, dodawanie kolumny, usuwanie kolumny |
| Istniejąca tabela | Nowe mapowanie | Dodaj kolumnę (na której można następnie zmienić typ danych, zmienić nazwę i zaktualizować) |
| Istniejąca tabela | Istniejące mapowanie | Brak |

Przekształcenia mapowania
Niektóre mapowania formatów danych (Parquet, JSON i Avro) obsługują proste przekształcenia czasu pozyskiwania. Aby zastosować przekształcenia mapowania, utwórz lub zaktualizuj kolumnę w oknie Edytowanie kolumn .
Przekształcenia mapowania można wykonać na kolumnie typu ciąg lub data/godzina, a źródło ma typ danych int lub long. Obsługiwane przekształcenia mapowania to:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Mapowanie schematu dla plików Avro przechwytywania usługi Event Hubs
Jednym ze sposobów korzystania z danych usługi Event Hubs jest przechwytywanie zdarzeń za pośrednictwem usługi Azure Event Hubs w usłudze Azure Blob Storage lub Azure Data Lake Storage. Następnie można pozyskiwać pliki przechwytywania podczas ich zapisywania przy użyciu połączenia danych usługi Event Grid.
Schemat plików przechwytywania różni się od schematu oryginalnego zdarzenia wysyłanego do usługi Event Hubs. Należy zaprojektować schemat tabeli docelowej z tą różnicą. W szczególności ładunek zdarzenia jest reprezentowany w pliku przechwytywania jako tablica bajtów, a ta tablica nie jest automatycznie dekodowana przez połączenie danych usługi Azure Data Explorer usługi Event Grid. Aby uzyskać bardziej szczegółowe informacje na temat schematu plików dla danych przechwytywania usługi Event Hubs Avro, zobacz Eksplorowanie przechwyconych plików Avro w usłudze Azure Event Hubs.
Aby poprawnie zdekodować ładunek zdarzenia:
- Zamapuj
Bodypole przechwyconego zdarzenia na kolumnę typudynamicw tabeli docelowej. - Zastosuj zasady aktualizacji, które konwertują tablicę bajtów na ciąg czytelny przy użyciu funkcji unicode_codepoints_to_string().
Opcje zaawansowane oparte na typie danych
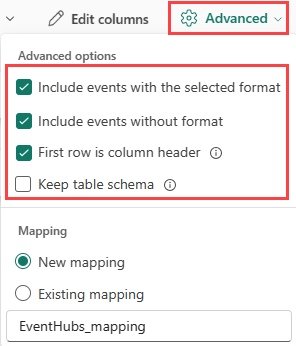
Tabelaryczny (CSV, TSV, PSV):
Jeśli pozyskujesz formaty tabelaryczne w istniejącej tabeli, możesz wybrać pozycję Zaawansowane>zachowaj schemat tabeli. Dane tabelaryczne nie muszą zawierać nazw kolumn używanych do mapowania danych źródłowych na istniejące kolumny. Po zaznaczeniu tej opcji mapowanie odbywa się według kolejności, a schemat tabeli pozostaje taki sam. Jeśli ta opcja nie jest zaznaczona, nowe kolumny są tworzone dla danych przychodzących, niezależnie od struktury danych.
Aby użyć pierwszego wiersza jako nazw kolumn, wybierz pozycję Zaawansowane>pierwszy wiersz to nagłówek kolumny.
JSON:
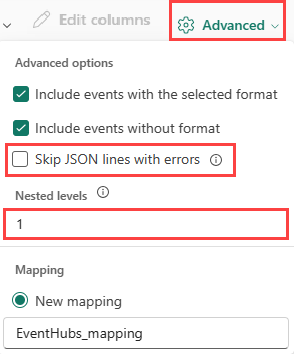
Aby określić podział kolumn danych JSON, wybierz pozycję Zaawansowane>poziomy zagnieżdżone z zakresu od 1 do 100.
W przypadku wybrania opcji Zaawansowane>pomiń wiersze JSON z błędami dane są pozyskiwane w formacie JSON. Jeśli to pole wyboru nie zostanie zaznaczone, dane są pozyskiwane w formacie wielossonowym.
Podsumowanie
W oknie Przygotowywanie danych wszystkie trzy kroki są oznaczone zielonymi znacznikami wyboru po pomyślnym zakończeniu pozyskiwania danych. Możesz wybrać kartę, aby wykonać zapytanie, usunąć pozyskane dane lub wyświetlić pulpit nawigacyjny podsumowania pozyskiwania.
