Eksplorowanie danych w dublowanej bazie danych za pomocą notesów
Możesz eksplorować dane replikowane z dublowanej bazy danych za pomocą zapytań platformy Spark w notesach.
Notesy to zaawansowany element kodu umożliwiający opracowywanie zadań platformy Apache Spark i eksperymentów uczenia maszynowego na danych. Notesy w usłudze Fabric Lakehouse umożliwiają eksplorowanie tabel dublowanych.
Wymagania wstępne
- Ukończ samouczek, aby utworzyć dublowaną bazę danych na podstawie źródłowej bazy danych.
- Samouczek: konfigurowanie dublowanej bazy danych usługi Microsoft Fabric dla usługi Azure Cosmos DB (wersja zapoznawcza)
- Samouczek: konfigurowanie dublowanych baz danych usługi Microsoft Fabric z usługi Azure Databricks (wersja zapoznawcza)
- Samouczek: konfigurowanie dublowanych baz danych usługi Microsoft Fabric z usługi Azure SQL Database
- Samouczek: konfigurowanie dublowanych baz danych usługi Microsoft Fabric z usługi Azure SQL Managed Instance (wersja zapoznawcza)
- Samouczek: konfigurowanie dublowanych baz danych usługi Microsoft Fabric z usługi Snowflake
Tworzenie skrótu
Najpierw należy utworzyć skrót z dublowanych tabel do usługi Lakehouse, a następnie utworzyć notesy za pomocą zapytań platformy Spark w usłudze Lakehouse.
W portalu sieci szkieletowej otwórz inżynierowie danych ing.
Jeśli nie masz już utworzonego magazynu Lakehouse, wybierz pozycję Lakehouse i utwórz nową usługę Lakehouse, podając jej nazwę.
Wybierz pozycję Pobierz dane —> nowy skrót.
Wybierz pozycję Microsoft OneLake.
Wszystkie dublowane bazy danych są widoczne w obszarze roboczym Sieć szkieletowa.
Wybierz dublowaną bazę danych, którą chcesz dodać do usługi Lakehouse, jako skrót.
Wybierz żądane tabele z dublowanej bazy danych.
Wybierz pozycję Dalej, a następnie pozycję Utwórz.
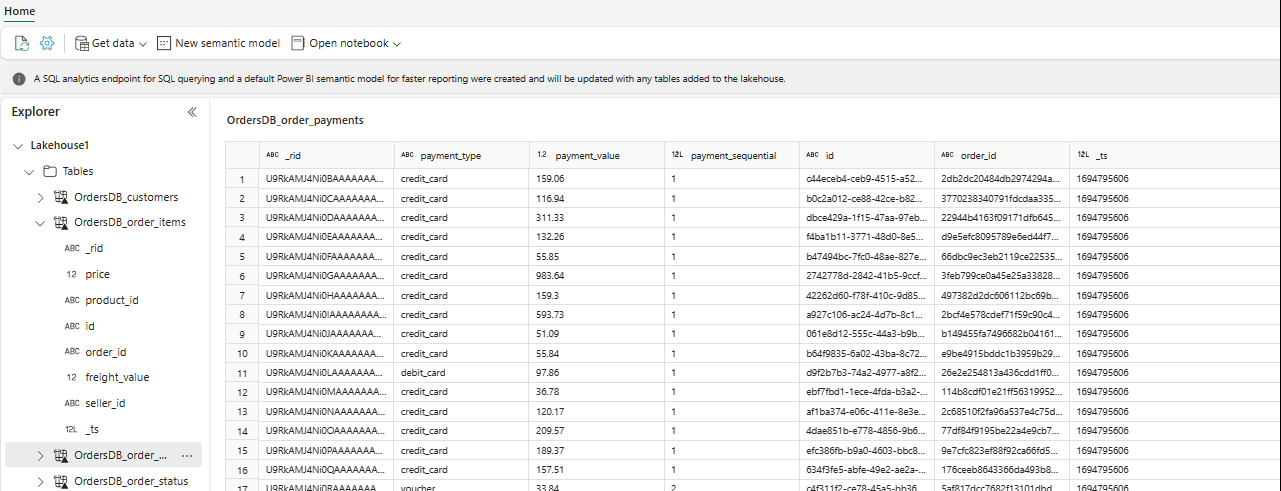
W Eksploratorze możesz teraz wyświetlić wybrane dane tabeli w usłudze Lakehouse.
Napiwek
Inne dane można dodać bezpośrednio w usłudze Lakehouse lub prowadzić skróty, takie jak S3, ADLS Gen2. Możesz przejść do punktu końcowego analizy SQL usługi Lakehouse i bezproblemowo połączyć dane we wszystkich tych źródłach z dublowanych danych.
Aby eksplorować te dane na platformie Spark, wybierz kropki
...obok dowolnej tabeli. Wybierz pozycję Nowy notes lub Istniejący notes , aby rozpocząć analizę.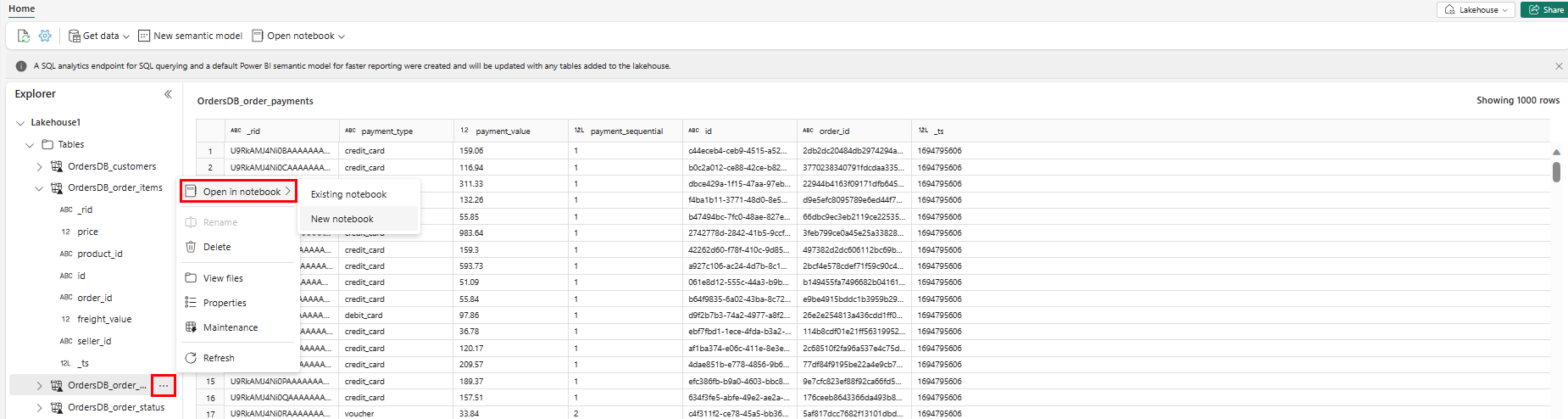
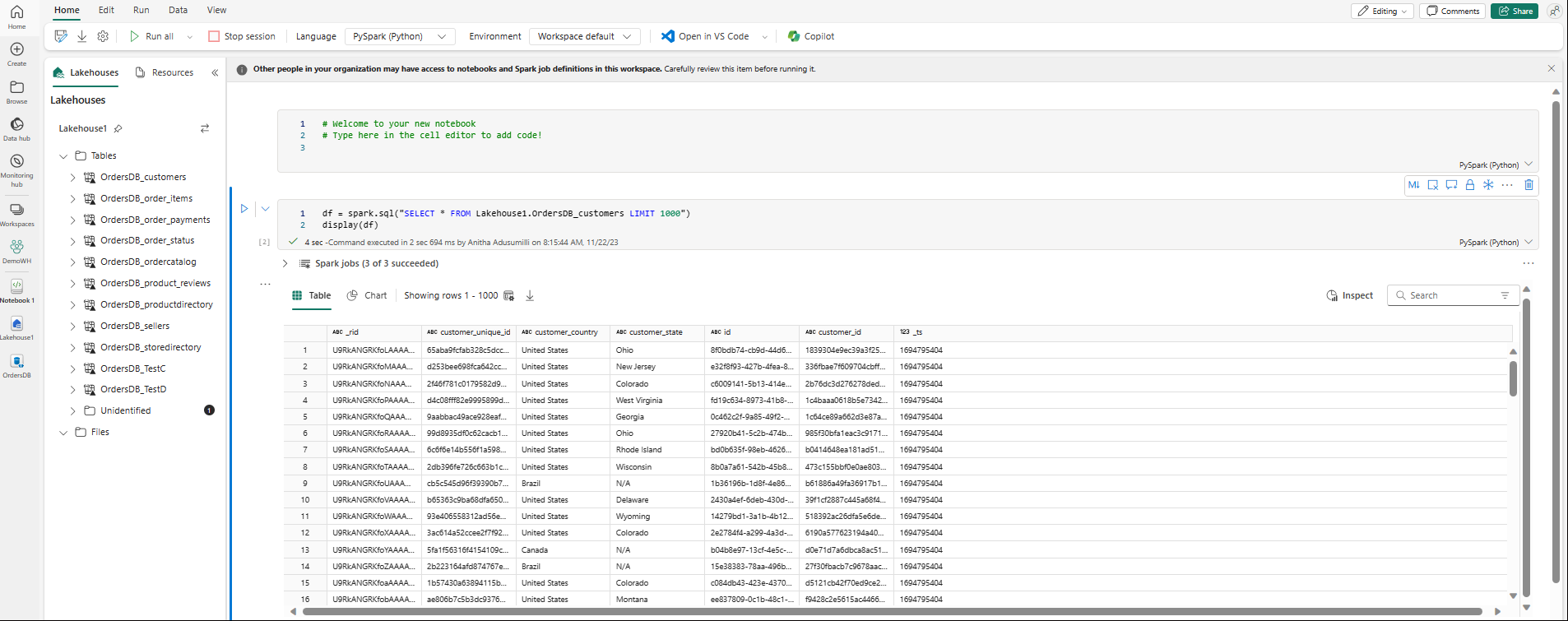
Notes zostanie otwarty automatycznie i załaduje ramkę danych za pomocą
SELECT ... LIMIT 1000zapytania Spark SQL.- Ładowanie nowych notesów może potrwać do dwóch minut. To opóźnienie można uniknąć, używając istniejącego notesu z aktywną sesją.
- Ładowanie nowych notesów może potrwać do dwóch minut. To opóźnienie można uniknąć, używając istniejącego notesu z aktywną sesją.


