Samouczek, część 2. Eksplorowanie i wizualizowanie danych przy użyciu notesów usługi Microsoft Fabric
W tym samouczku dowiesz się, jak przeprowadzić eksploracyjną analizę danych (EDA), aby zanalizować i zbadać dane oraz podsumować ich kluczowe cechy za pomocą technik wizualizacji danych.
Użyjesz seaborn, biblioteki wizualizacji danych języka Python, która udostępnia interfejs wysokiego poziomu do tworzenia wizualizacji na ramkach danych i tablicach. Aby uzyskać więcej informacji na temat seaborn, zobacz Seaborn: Statistical Data Visualization.
Użyjesz również Data Wrangler, narzędzia opartego na notesach, które zapewnia immersyjne środowisko do przeprowadzania eksploracyjnej analizy i czyszczenia danych.
Główne kroki opisane w tym samouczku to:
- Odczytaj dane przechowywane w tabeli delty w lakehouse.
- Przekonwertuj ramkę danych platformy Spark na ramkę danych biblioteki pandas, która obsługuje biblioteki wizualizacji języka Python.
- Użyj narzędzia Data Wrangler, aby wykonać początkowe czyszczenie i przekształcanie danych.
- Wykonaj eksploracyjne analizy danych przy użyciu
seaborn.
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska w lewej dolnej części Twojej strony głównej, aby przełączyć się na Fabric.

Jest to część 2 z 5 w serii samouczków. Aby ukończyć ten samouczek, najpierw wykonaj następujące czynności:
- część 1. Pozyskiwanie danych do usługi Microsoft Fabric lakehouse przy użyciu platformy Apache Spark.
Podążaj za notatkami w notesie
2-explore-cleanse-data.ipynb to notatnik, który towarzyszy temu samouczkowi.
Aby otworzyć towarzyszący notatnik na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w Przygotuj swój system do samouczków z nauki o danych, aby zaimportować notatnik do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby dołączyć lakehouse do notesu.
Ważny
Dołącz lakehouse, którego użyto w części 1.
Odczytywanie surowych danych z lakehouse'u
Odczytaj dane pierwotne z sekcji Pliki lakehouse. Te dane zostały załadowane w poprzednim notatniku. Przed uruchomieniem tego kodu upewnij się, że załączyłeś do tego notesu ten sam lakehouse, którego użyłeś w części 1.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Tworzenie ramki danych pandas na podstawie zestawu danych
Przekonwertuj ramkę danych platformy Spark na ramkę danych biblioteki pandas, aby ułatwić przetwarzanie i wizualizację.
df = df.toPandas()
Wyświetlanie danych pierwotnych
Zapoznaj się z danymi nieprzetworzonymi za pomocą display, wykonaj kilka podstawowych statystyk i wyświetl widoki wykresów. Należy najpierw zaimportować wymagane biblioteki, takie jak Numpy, Pnadas, Seaborni Matplotlib na potrzeby analizy danych i wizualizacji.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Wykonywanie początkowego czyszczenia danych przy użyciu narzędzia Data Wrangler
Aby eksplorować i przekształcać dowolne ramki danych pandas w notatniku, uruchom narzędzie Data Wrangler bezpośrednio z notatnika.
Notatka
Nie można otworzyć Data Wrangler, gdy jądro notatnika jest zajęte. Wykonanie komórki musi zostać ukończone przed uruchomieniem narzędzia Data Wrangler.
- Na karcie danych na wstążce notesu wybierz pozycję Launch Data Wrangler. Zobaczysz listę aktywowanych ramek danych w pandas dostępnych do edycji.
- Wybierz ramkę danych, którą chcesz otworzyć w narzędziu Data Wrangler. Ponieważ ten notatnik zawiera tylko jeden DataFrame,
dfwybierzdf.
Narzędzie Data Wrangler uruchamia i generuje opisowe omówienie danych. Tabela w środku zawiera każdą kolumnę danych. Panel Podsumowanie obok tabeli zawiera informacje o ramce danych. Po wybraniu kolumny w tabeli podsumowanie zostanie zaktualizowane o informacje o wybranej kolumnie. W niektórych przypadkach wyświetlane i podsumowane dane będą skróconym widokiem ramki danych. W takim przypadku w okienku podsumowania zostanie wyświetlony obraz ostrzegawczy. Umieść kursor na tym ostrzeżeniu, aby wyświetlić tekst wyjaśniający sytuację.

Każda operacja, którą można wykonać, można zastosować w kilku kliknięciach, aktualizując wyświetlanie danych w czasie rzeczywistym i generując kod, który można zapisać z powrotem do notesu jako funkcję wielokrotnego użytku.
W pozostałej części tej sekcji przedstawiono procedurę czyszczenia danych za pomocą narzędzia Data Wrangler.
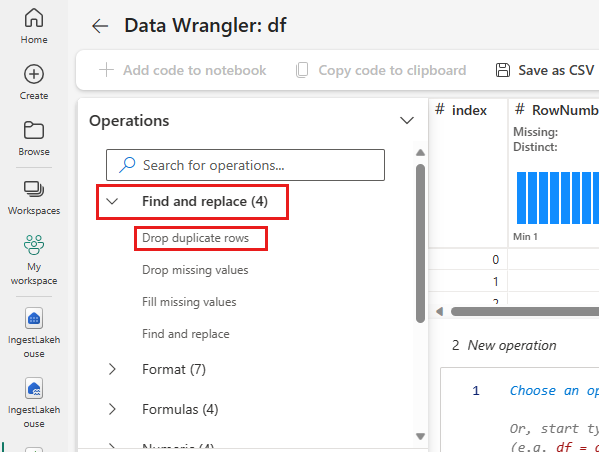
Usuwanie zduplikowanych wierszy
Na panelu po lewej stronie znajduje się lista operacji (takich jak Znajdź i zamień, Formatowanie, Formuły, Numeryczne), które można wykonać na zestawie danych.
Rozwiń Znajdź i zastąp i wybierz Usuń zduplikowane wiersze.
Zostanie wyświetlony panel umożliwiający wybranie listy kolumn, które chcesz porównać, aby zdefiniować zduplikowany wiersz. Wybierz RowNumber i CustomerId.
W środkowym panelu jest podgląd wyników tej operacji. W wersji zapoznawczej jest kod do wykonania operacji. W tym przypadku dane wydają się być niezmienione. Ale ponieważ patrzysz na ograniczony widok, warto wciąż zastosować operację.
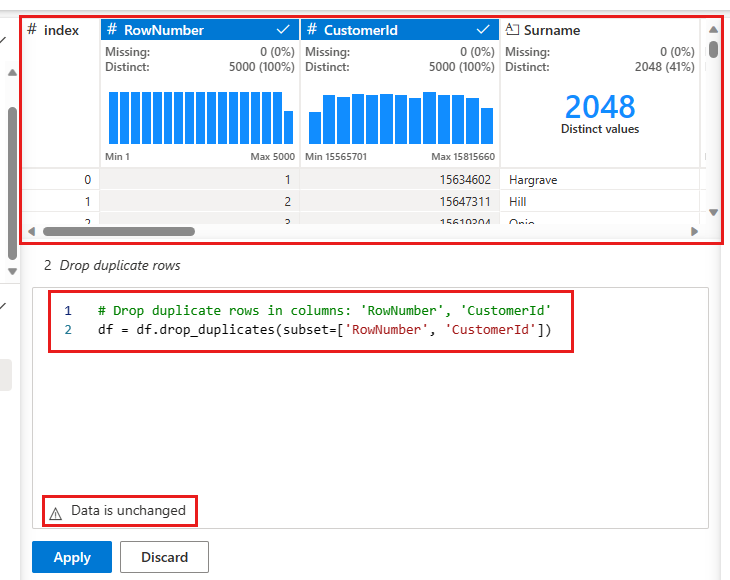
Wybierz pozycję Zastosuj (z boku lub na dole), aby przejść do następnego kroku.

Usuwanie wierszy z brakującymi danymi
Użyj narzędzia Data Wrangler, aby usunąć wiersze z brakującymi danymi we wszystkich kolumnach.
Wybierz Usuń brakujące wartości z Znajdź i zastąp.
Wybierz pozycję Wybierz wszystkie z kolumn Target.
Wybierz pozycję Zastosuj, aby przejść do następnego kroku.

Usuwanie kolumn
Użyj narzędzia Data Wrangler, aby usunąć kolumny, których nie potrzebujesz.
Rozwiń schemat i wybierz opcję Usuń kolumny.
Wybierz RowNumber, CustomerId, Nazwisko. Te kolumny są wyświetlane na czerwono w wersji zapoznawczej, aby pokazać, że zostały zmienione przez kod (w tym przypadku porzucony).
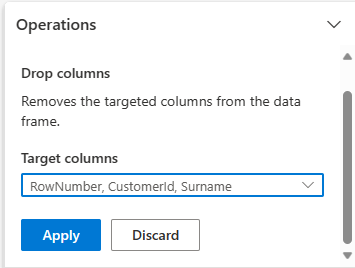
Wybierz pozycję Zastosuj, aby przejść do następnego kroku.

Dodawanie kodu do notesu
Za każdym razem, gdy wybierzesz Zastosuj, w panelu Kroki czyszczenia w lewym dolnym rogu zostanie utworzony nowy krok. W dolnej części panelu wybierz pozycję Kod podglądu dla wszystkich kroków, aby wyświetlić kombinację wszystkich oddzielnych kroków.
Wybierz pozycję Dodaj kod do notesu w lewym górnym rogu, aby zamknąć narzędzie Data Wrangler i dodać kod automatycznie. Dodawanie kodu do notesu umieszcza kod w funkcji, a następnie ją wywołuje.
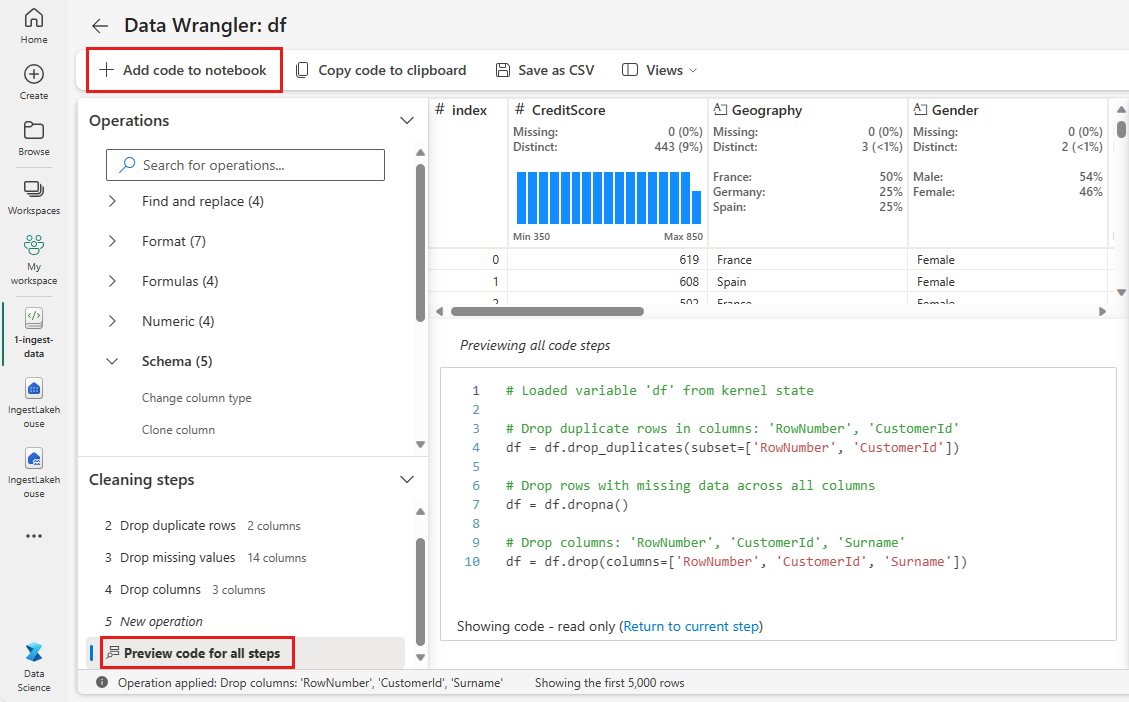
Napiwek
Kod wygenerowany przez usługę Data Wrangler nie zostanie zastosowany do momentu ręcznego uruchomienia nowej komórki.
Jeśli nie użyto narzędzia Data Wrangler, możesz zamiast tego użyć następnej komórki kodu.
Ten kod jest podobny do kodu wygenerowanego przez usługę Data Wrangler, ale dodaje argument inplace=True do każdego z wygenerowanych kroków. Ustawiając inplace=True, biblioteka pandas zastąpi oryginalną ramkę danych zamiast tworzyć nową ramkę danych jako dane wyjściowe.
# Modified version of code generated by Data Wrangler
# Modification is to add in-place=True to each step
# Define a new function that include all above Data Wrangler operations
def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
df_clean.head()
Eksplorowanie danych
Wyświetl niektóre podsumowania i wizualizacje oczyszczonych danych.
Określanie atrybutów kategorii, liczbowych i docelowych
Ten kod służy do określania atrybutów kategorii, liczbowych i docelowych.
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Podsumowanie z pięcioma liczbami
Pokaż podsumowanie pięciu liczb (minimalny wynik, pierwszy kwartyl, mediana, trzeci kwartyl, maksymalny wynik) dla atrybutów liczbowych przy użyciu wykresów pól.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
fig.delaxes(axes[1,2])
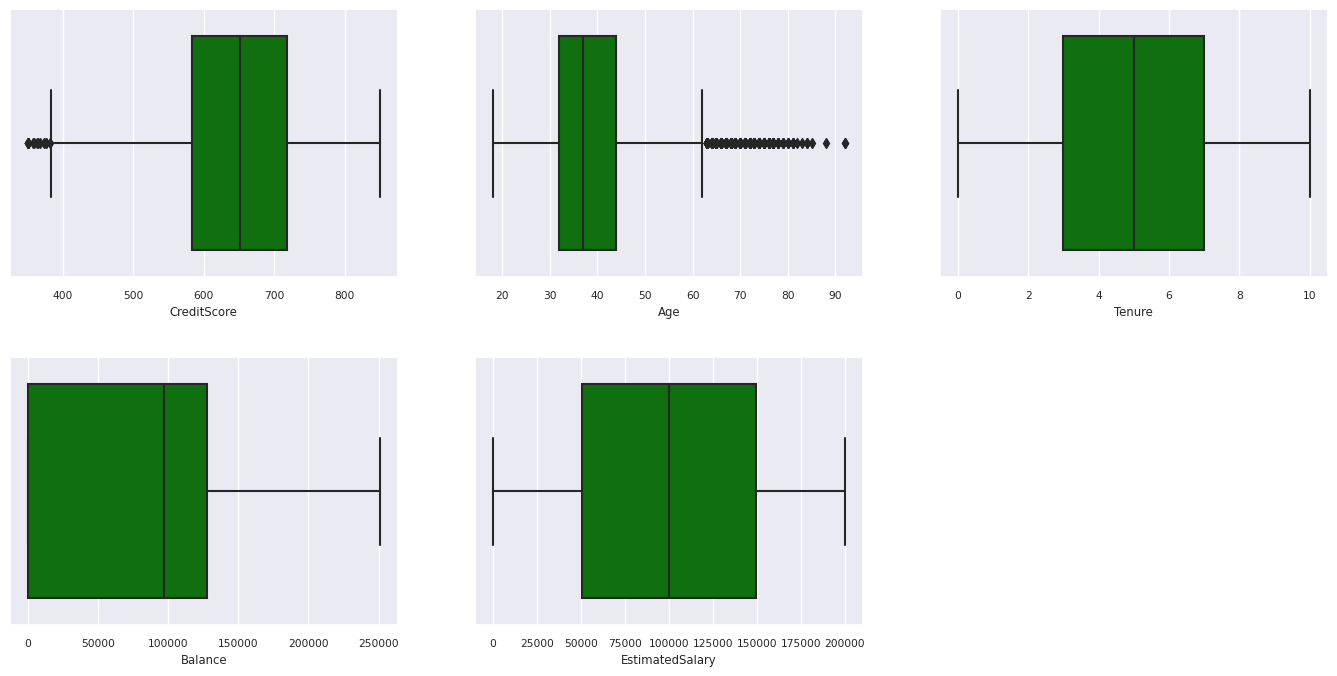
Dystrybucja odchodzących i nieistniejących klientów
Pokaż rozkład wycofanych i niewycofanych klientów według atrybutów kategorycznych.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)

Rozkład atrybutów liczbowych
Pokaż rozkład częstotliwości atrybutów liczbowych przy użyciu histogramu.
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
plt.show()

Wykonywanie inżynierii cech
Wykonaj inżynierię cech, aby wygenerować nowe atrybuty na podstawie bieżących atrybutów:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Używanie narzędzia Data Wrangler do wykonywania kodowania jednorazowego
Wrangler danych może również służyć do wykonywania kodowania jednorazowego. W tym celu otwórz ponownie narzędzie Data Wrangler. Tym razem wybierz dane df_clean.
- Rozwiń Formuły i wybierz pozycję Kodowanie jednokrotne.
- Zostanie wyświetlony panel umożliwiający wybranie listy kolumn, na których chcesz wykonać kodowanie jednorazowe. Wybierz Geography i Gender.
Możesz skopiować wygenerowany kod, zamknąć narzędzie Data Wrangler, aby powrócić do notesu, a następnie wkleić go do nowej komórki. Możesz też wybrać pozycję Dodaj kod do notesu w lewym górnym rogu, aby zamknąć narzędzie Data Wrangler i dodać kod automatycznie.
Jeśli nie użyto narzędzia Data Wrangler, możesz zamiast tego użyć następnej komórki kodu:
# This is the same code that Data Wrangler will generate
import pandas as pd
def clean_data(df_clean):
# One-hot encode columns: 'Geography', 'Gender'
df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
return df_clean
df_clean_1 = clean_data(df_clean.copy())
df_clean_1.head()
Podsumowanie obserwacji z eksploracyjnej analizy danych
- Większość klientów pochodzi z Francji w porównaniu z Hiszpanią i Niemcami, podczas gdy Hiszpania ma najniższy współczynnik zmian w porównaniu z Francją i Niemcami.
- Większość klientów ma karty kredytowe.
- Istnieją klienci, których wiek i ocena kredytowa są powyżej 60 i poniżej 400, ale nie można ich traktować jako wartości odstających.
- Bardzo niewielu klientów ma więcej niż dwa produkty banku.
- Klienci, którzy nie są aktywni, mają wyższy współczynnik zmian.
- Płeć i lata kadencji nie wydają się mieć wpływu na decyzję klienta o zamknięciu konta bankowego.
Tworzenie tabeli różnicowej dla oczyszczonych danych
Te dane będą używane w następnym notatniku tej serii.
table_name = "df_clean"
# Create Spark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean_1)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark dataframe saved to delta table: {table_name}")
Następny krok
Trenowanie i rejestrowanie modeli uczenia maszynowego przy użyciu tych danych: