Planowanie migracji z usługi Azure Data Factory
Microsoft Fabric to produkt SaaS do analizy danych firmy Microsoft, który łączy wszystkie wiodące na rynku produkty analityczne firmy Microsoft w jednym środowisku użytkownika. Usługa Fabric Data Factory zapewnia aranżację przepływu pracy, przenoszenie danych, replikację danych i przekształcanie danych na dużą skalę z podobnymi możliwościami znajdującymi się w usłudze Azure Data Factory (ADF). Jeśli masz istniejące inwestycje w usługę ADF, które chcesz zmodernizować w usłudze Fabric Data Factory, ten dokument jest przydatny, aby ułatwić zrozumienie zagadnień, strategii i metod migracji.
Migracja z usług Azure PaaS ETL/DI usługi ADF & potoków i przepływów danych usługi Synapse może zapewnić kilka ważnych korzyści:
- Nowe zintegrowane funkcje przepływu pracy, takie jak wiadomości e-mail i działania usługi Microsoft Teams, umożliwiają łatwe przekierowywanie wiadomości podczas wykonywania przepływu pracy.
- Wbudowane funkcje ciągłej integracji i ciągłego dostarczania (CI/CD) (potoki wdrażania) nie wymagają zewnętrznej integracji z repozytoriami Git.
- Integracja obszaru roboczego z usługą OneLake Data Lake umożliwia łatwe zarządzanie analizą w jednym okienku.
- Odświeżanie semantycznych modeli danych jest łatwe w Fabric dzięki w pełni zintegrowanej aktywności potokowej.
Microsoft Fabric to zintegrowana platforma zarówno dla danych przedsiębiorstwa samoobsługowego, jak i zarządzanego przez IT. Wraz ze wzrostem wykładniczym ilości danych i złożonością, klienci Fabric domagają się rozwiązań dla przedsiębiorstw, które się skalują, są bezpieczne, łatwe do zarządzania i dostępne dla wszystkich użytkowników w największych organizacjach.
W ostatnich latach firma Microsoft zainwestowała znaczne wysiłki w celu zapewnienia skalowalnych możliwości chmury w warstwie Premium. W tym celu usługa Data Factory w Fabric natychmiast zwiększa możliwości dużego ekosystemu deweloperów integracji danych oraz rozwiązań do integracji danych, które powstawały przez dziesięciolecia, aby zastosować pełny zestaw funkcji i możliwości, które znacząco wykraczają poza porównywalną funkcjonalność dostępną w poprzednich generacjach.
Oczywiście klienci pytają, czy istnieje możliwość konsolidacji przez hostowanie rozwiązań integracji danych w usłudze Fabric. Często zadawane pytania obejmują:
- Czy wszystkie funkcjonalności, na których polegamy, działają w potokach Fabric?
- Jakie możliwości są dostępne tylko w potokach Fabric?
- Jak migrujemy istniejące potoki do potoków Fabric?
- Co to jest plan firmy Microsoft dotyczący pozyskiwania danych przedsiębiorstwa?
Różnice między platformami
Podczas migracji całego wystąpienia usługi ADF istnieje wiele ważnych różnic, które należy wziąć pod uwagę między usługą ADF i usługą Data Factory w sieci szkieletowej, co staje się ważne podczas migracji do sieci szkieletowej. W tej sekcji zapoznamy się z kilkoma istotnymi różnicami.
Aby uzyskać bardziej szczegółowe informacje na temat funkcjonalnego mapowania różnic cech między usługami Azure Data Factory i Fabric Data Factory, zapoznaj się z tematem Porównanie Data Factory w Fabric i Azure Data Factory.
Środowiska uruchomieniowe integracji
W usłudze ADF środowiska Integration Runtime (IRs) to obiekty konfiguracji reprezentujące obliczenia używane przez usługę ADF do ukończenia przetwarzania danych. Te właściwości konfiguracji obejmują region platformy Azure dla obliczeń w chmurze oraz rozmiary obliczeń Spark dla przepływu danych. Inne typy środowisk IR obejmują środowiska IR hostowane lokalnie (SHIR) na potrzeby łączności danych lokalnych, środowiska IR SSIS do uruchamiania pakietów usług SQL Server Integration Services oraz środowiska IR w chmurze z obsługą sieci wirtualnej.
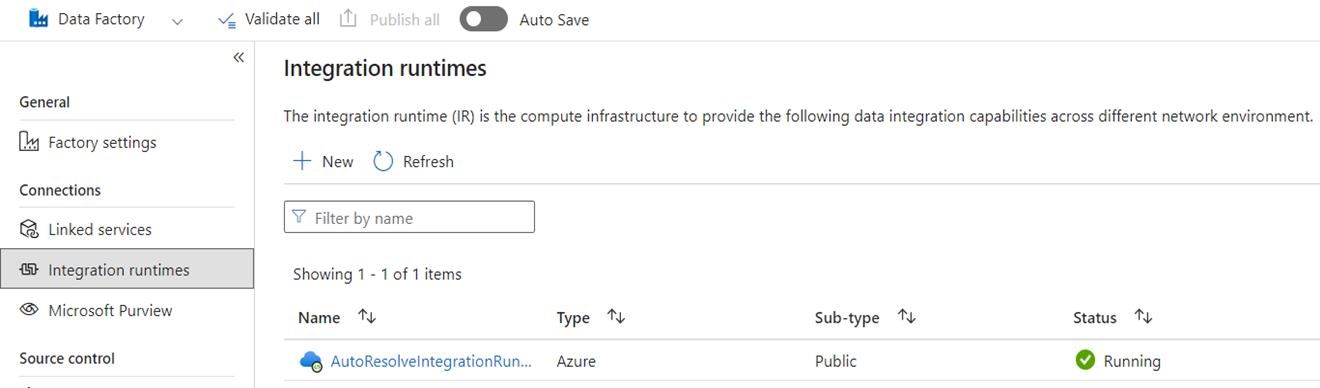
Microsoft Fabric to produkt typu oprogramowanie jako usługa (SaaS), natomiast usługa ADF to produkt typu "platforma jako usługa" (PaaS). To rozróżnienie oznacza, że jeśli chodzi o Integration Runtime, nie trzeba konfigurować żadnych elementów do używania potoków lub przepływów danych w Fabric, ponieważ domyślne jest używanie przetwarzania w chmurze w regionie, w którym znajdują się Twoje zasoby Fabric. SSIS IR nie istnieje w Fabric, a do łączności z danymi lokalnymi używasz komponentu specyficznego dla Fabric znanego jako lokalna brama danych (OPDG). W przypadku łączności opartej na sieci wirtualnej z zabezpieczonymi sieciami, należy użyć Bramki danych sieci wirtualnej w Fabric.
Podczas migracji z usługi ADF do Fabric nie trzeba migrować publicznych IR-ów sieci platformy Azure (chmury). Należy odtworzyć swoje obiekty SHIR jako OPDG i włączyć swoje Azure IR w ramach sieci wirtualnej jako bramy danych w sieci wirtualnej .
Rurociągi
Potoki danych są fundamentalnym elementem ADF, który jest używany do koordynacji przepływu pracy i orkiestracji procesów ADF w celu przenoszenia danych, przekształcania danych i koordynacji procesów. Potoki w usłudze Fabric Data Factory są prawie identyczne jak w usłudze Azure Data Factory, ale z dodatkowymi składnikami, które dobrze pasują do modelu SaaS opartego na usłudze Power BI. To podobieństwo obejmuje działania natywne dla wiadomości e-mail, aplikacji Teams i odświeżania modelu semantycznego.
Definicja JSON potoków w usłudze Fabric Data Factory różni się nieco od usługi ADF ze względu na różnice w modelu aplikacji między dwoma produktami. Ze względu na tę różnicę nie można skopiować/wkleić ciągu operacji JSON, zaimportować/wyeksportować ciągów operacji ani wskazać repozytorium Git dla ADF.
Podczas odbudowy potoków ADF jako potoków Fabric należy używać zasadniczo tych samych modeli przepływu pracy i umiejętności, co w przypadku potoków ADF. Podstawowa kwestia dotyczy Połączonych Usług i Zbiorów Danych, które są pojęciami w usłudze ADF, ale nie istnieją w Fabric.
Połączone usługi
W usłudze ADF połączone usługi definiują właściwości łączności potrzebne do łączenia się z magazynami danych na potrzeby przenoszenia danych, przekształcania danych i przetwarzania danych. W Fabricu musisz odtworzyć te definicje jako Połączenia, które są właściwościami dla twoich działań, takich jak Kopia i przepływy danych.
Zestawy danych
Zestawy danych definiują kształt, lokalizację i zawartość danych w usłudze ADF, ale nie istnieją jako jednostki w Fabric. Aby zdefiniować właściwości danych, takie jak typy danych, kolumny, foldery, tabele itp. w potokach usługi Fabric Data Factory, należy zdefiniować te właściwości bezpośrednio w działaniach potoku i we wspomnianym wcześniej obiekcie Połączenie w sekcji Połączona usługa.
Przepływy danych
W usłudze Data Factory for Fabric termin przepływy danych odnosi się do działań przekształcania danych bez kodu, natomiast w usłudze ADF ta sama funkcja jest nazywana przepływami danych . Przepływy danych usługi Fabric Data Factory mają interfejs użytkownika oparty na Power Query, który jest używany w aktywności Power Query w usłudze ADF. Obliczenia wykorzystywane do wykonywania przepływów danych w Fabric to natywny silnik wykonawczy, który pozwala na skalowanie poziome w celu przekształcania danych na dużą skalę przy użyciu nowego silnika obliczeniowego Fabric Data Warehouse.
W usłudze ADF przepływy danych są oparte na infrastrukturze usługi Synapse Spark i definiowane przy użyciu interfejsu użytkownika do tworzenia, który używa podstawowego języka specyficznego dla domeny (DSL), znanego jako skrypt przepływu danych . Ten język definicji różni się znacznie od przepływów danych opartych na Power Query w Fabric, które używają języka definicji znanego jako M do definiowania ich zachowania. Ze względu na te różnice w interfejsach użytkownika, językach i motorach wykonawczych, przepływy danych Fabric i przepływy danych usługi ADF nie są zgodne i należy ponownie utworzyć przepływy danych usługi ADF jako przepływy danych Fabric podczas uaktualniania rozwiązań do Fabric.
Wyzwalaczy
Wyzwalacze sygnalizują usługę ADF do uruchamiania potoku na podstawie harmonogramu czasu rzeczywistego, przedziałów czasowych, zdarzeń opartych na plikach lub zdarzeń niestandardowych. Te funkcje są podobne w usłudze Fabric, chociaż podstawowa implementacja jest inna.
W ramach platformy wyzwalacze i istnieją tylko jako koncepcja przetwarzania przepływu. Większa struktura, której używają wyzwalacze potoków w Fabric, jest znana jako Aktywizator Danych, co jest podsystemem zdarzeń i alertów funkcji analizy w czasie rzeczywistym w Fabric.
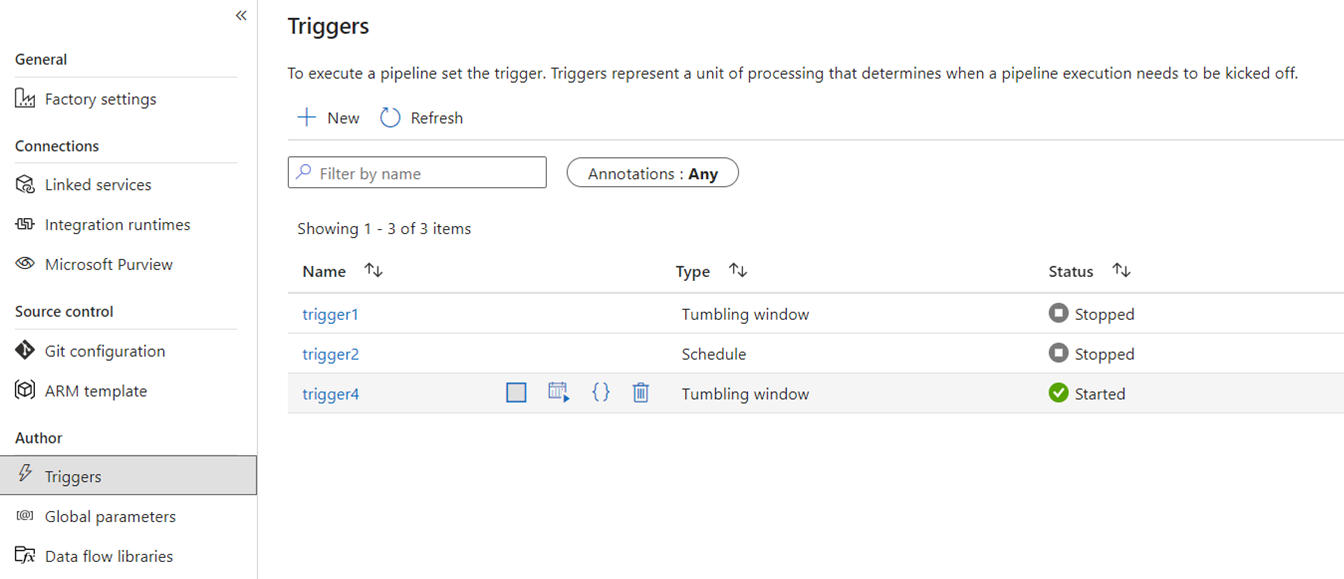
Aktywator danych Fabric ma alerty, których można użyć do tworzenia zdarzeń pliku i wyzwalaczy zdarzeń niestandardowych. Chociaż wyzwalacze harmonogramu są oddzielną jednostką w systemie Fabric, znaną jako harmonogramy . Te harmonogramy są ustalone na poziomie platformy w Fabric i nie są specyficzne dla potoków. Nie są one również nazywane wyzwalaczami w Fabric.
Aby przeprowadzić migrację wyzwalaczy z usługi ADF do sieci szkieletowej, pomyśl o odbudowaniu wyzwalaczy harmonogramu po prostu jako harmonogramach, które są właściwościami potoków sieci szkieletowej. W przypadku wszystkich innych typów wyzwalaczy użyj przycisku Wyzwalacze w ramach potoku Fabric lub użyj natywnie funkcji Aktywator danych w Fabric.
Debugowanie
Debugowanie potoków jest prostsze w Fabric niż w usłudze ADF. Ta prostota jest taka, ponieważ potoki usługi Fabric Data Factory nie mają oddzielnej koncepcji trybu debugowania , które można znaleźć w potokach i przepływach danych usługi ADF. Zamiast tego podczas tworzenia potoku zawsze jesteś w trybie interaktywnym. Aby przetestować i debugować potoki, wystarczy wybrać przycisk odtwarzania na pasku narzędzi w Edytorze potoku, gdy wszystko będzie gotowe do cyklu rozwoju. Potoki w Fabric nie zawierają debugowania dopóki nie zostanie osiągnięty interaktywny krokowy wzorzec debugowania. Zamiast tego w sieci szkieletowej używasz stanu działania i ustawiasz tylko działania, które chcesz przetestować jako aktywne, ustawiając jednocześnie wszystkie inne działania na nieaktywne, aby osiągnąć te same wzorce testowania i debugowania. Obejrzyj poniższy film wideo, w którym przedstawiono sposób osiągnięcia tego doświadczenia debugowania w Fabric.
Przechwytywanie zmian danych
Funkcja przechwytywania zmian danych (CDC) w usłudze ADF to funkcja w wersji zapoznawczej, która ułatwia szybkie przenoszenie danych w sposób przyrostowy dzięki zastosowaniu funkcji CDC po stronie źródłowej magazynów danych. Aby przeprowadzić migrację artefaktów CDC do usługi Fabric Data Factory, należy ponownie utworzyć te artefakty jako elementy zlecenia kopiowania w obszarze roboczym Fabric. Ta funkcja oferuje podobne możliwości przenoszenia danych przyrostowych przy użyciu intuicyjnego interfejsu użytkownika i nie wymaga stosowania potoku, podobnie jak ma to miejsce w usłudze ADF CDC. Aby uzyskać więcej informacji, zobacz zadanie kopiowania dla usługi Data Factory w Fabric.
Azure Synapse Link
Mimo że nie jest dostępna w usłudze ADF, użytkownicy potoków usługi Synapse często używają funkcji Azure Synapse Link do replikowania danych z baz danych SQL do swojego jeziora danych w kompleksowym podejściu. W usłudze Fabric odtwarzamy artefakty usługi Azure Synapse Link jako elementy odbicia w obszarze roboczym. Aby uzyskać więcej informacji, zobacz w temacie Fabric database mirroring.
SQL Server Integration Services (SSIS)
SSIS to lokalne narzędzie do integracji danych i etL dostarczane przez firmę Microsoft z programem SQL Server. W usłudze ADF możesz przenosić pakiety SSIS do chmury metodą "lift-and-shift" przy użyciu środowiska ADF SSIS IR. W usłudze Fabric nie mamy pojęcia dotyczące IRs, więc ta funkcja nie jest obecnie możliwa. Pracujemy jednak nad umożliwieniem natywnego wykonywania pakietów SSIS z rozwiązania Fabric, co mamy nadzieję wkrótce wprowadzić do produktu. W międzyczasie najlepszym sposobem na wykonywanie pakietów SSIS w chmurze za pomocą Fabric Data Factory jest uruchomienie środowiska SSIS IR w fabryce ADF, a następnie wywołanie potoku ADF do uruchomienia pakietów SSIS. Potok ADF można wywołać zdalnie z pipeline'ów Fabric przy użyciu aktywności 'Invoked pipeline' opisanej w poniższej sekcji.
Uruchom działanie potoku
Typowym działaniem używanym w potokach usługi ADF jest wykonywanie działania potoku, które umożliwia wywołanie innego potoku w fabryce. W usłudze Fabric ulepszyliśmy to działanie jako działanie Wywołaj potok. Zapoznaj się z dokumentacją Wywołaj działanie potoku.
To działanie jest przydatne w przypadku scenariuszy migracji, w których istnieje wiele potoków usługi ADF korzystających z funkcji specyficznych dla usługi ADF, takich jak mapowanie przepływów danych lub SSIS. Możesz zarządzać tymi potokami as-is w potokach ADF lub nawet Synapse, a następnie wywołać ten potok bezpośrednio z nowego potoku usługi Fabric Data Factory, używając działania Wywołaj potok i wskazując na potok zdalnej fabryki danych.
Przykładowe scenariusze migracji
Poniższe scenariusze to typowe scenariusze migracji, które można napotkać podczas migracji z usługi ADF do usługi Fabric Data Factory.
Scenariusz nr 1: potoki i przepływy danych w usłudze Azure Data Factory
Podstawowe przypadki użycia migracji fabryk opierają się na modernizacji środowiska ETL z modelu PaaS ADF do nowego modelu SaaS Fabric. Podstawowe elementy zakładu produkcyjnego do migracji to przepływy danych i potoki. Istnieje kilka podstawowych elementów zakładu, które należy zaplanować w kontekście migracji poza dwoma głównymi elementami: połączonymi usługami, środowiskami Integration Runtime, zestawami danych i wyzwalaczami.
- Połączone usługi muszą być ponownie tworzone w Fabric jako połączenia w działaniach przepływu pracy.
- Zestawy danych nie istnieją w usłudze Factory. Właściwości zestawów danych są przedstawiane jako właściwości wewnątrz działań potoku, takich jak Kopiowanie lub Wyszukiwanie, podczas gdy Połączenia zawierają inne właściwości zestawów danych.
- Środowiska Integration Runtime nie istnieją w Fabric. Jednak własne hostowane środowiska uruchomieniowe można odtworzyć przy użyciu lokalnych bram danych (OPDG) w Fabric oraz środowisk uruchomieniowych sieci wirtualnej platformy Azure jako zarządzanych bram sieci wirtualnej w Fabric.
- Te działania w ramach potoku ADF nie są uwzględniane w usłudze Fabric Data Factory.
- Data Lake Analytics (U-SQL) — ta funkcja jest przestarzałą usługą platformy Azure.
- Działanie walidacji — działanie weryfikacji w usłudze ADF to działanie pomocnicze, które można łatwo skompilować w potokach sieci szkieletowej przy użyciu działania Pobierz metadane, pętli potoku i działania If.
- Power Query — w sieci szkieletowej wszystkie przepływy danych są kompilowane przy użyciu interfejsu użytkownika dodatku Power Query, dzięki czemu możesz po prostu skopiować i wkleić kod M z działań usługi ADF Power Query i skompilować je jako przepływy danych w sieci szkieletowej.
- Jeśli używasz dowolnego z funkcji potoku usługi ADF, które nie znajdują się w usłudze Fabric Data Factory, użyj działania Wywołaj potok w sieci szkieletowej, aby wywołać istniejące potoki w usłudze ADF.
- Następujące działania potoku usługi ADF zostały połączone w działanie o jednym celu:
- Działania usługi Azure Databricks (Notatnik, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
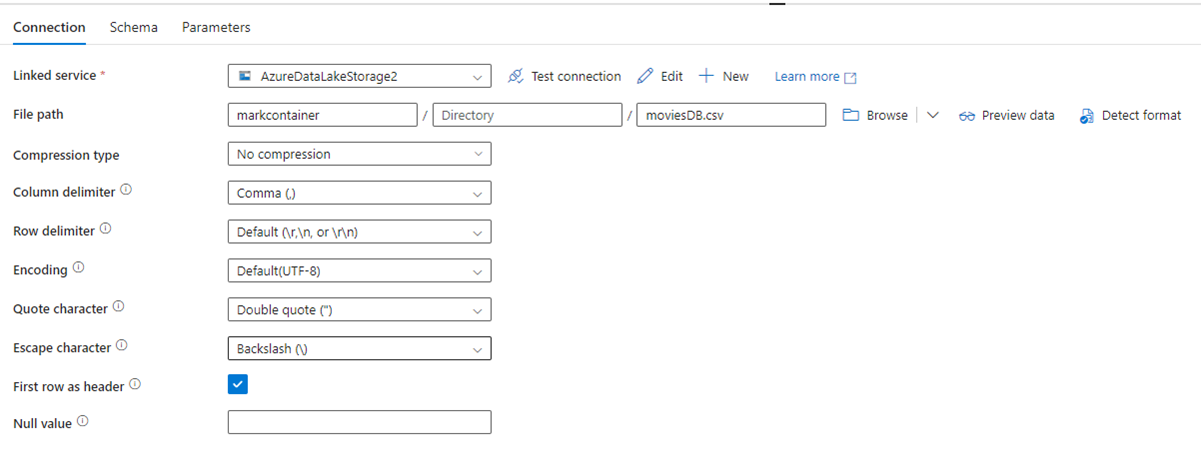
Na poniższej ilustracji przedstawiono stronę konfiguracji zestawu danych usługi ADF z ustawieniami ścieżki pliku i kompresji:
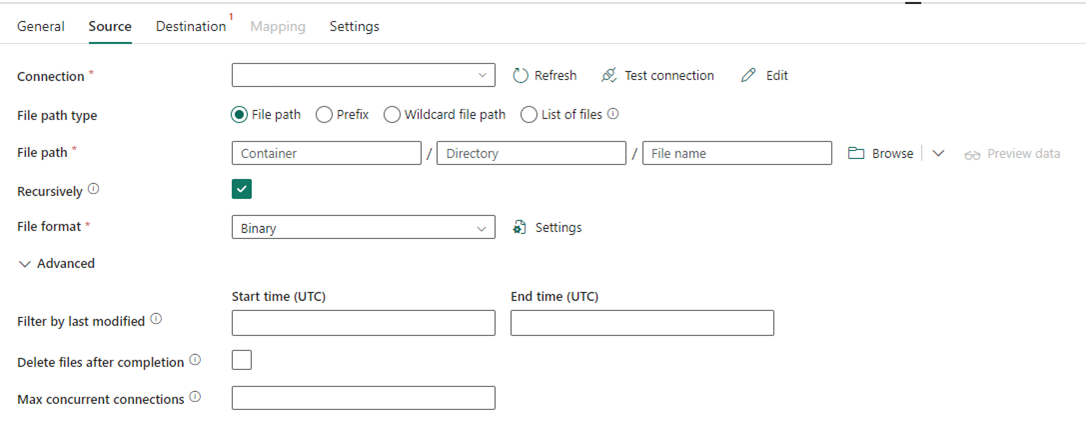
Na poniższej ilustracji przedstawiono konfigurację działania Kopiowania dla usługi Data Factory w sieci szkieletowej, gdzie kompresja i ścieżka pliku są wbudowane w działaniu:
Scenariusz nr 2: ADF z CDC, SSIS i Airflow
Funkcje CDC & Airflow w ADF są funkcjami podglądowymi, podczas gdy SSIS w ADF jest funkcją ogólnie dostępną od wielu lat. Każda z tych funkcji obsługuje różne potrzeby integracji danych, ale wymaga szczególnej uwagi podczas migracji z usługi ADF do sieci szkieletowej. Funkcja przechwytywania zmian danych (CDC) to koncepcja usługi ADF najwyższego poziomu, ale w usłudze Fabric ta funkcja jest widoczna jako zadanie kopiowania .
Airflow to funkcja systemu Apache Airflow zarządzana przez chmurę usługi ADF, która jest również dostępna w usłudze Fabric Data Factory. Powinno być możliwe użycie tego samego repozytorium źródłowego airflow lub użycie grup DAG i skopiowanie/wklejenie kodu do oferty Fabric Airflow z niewielkimi zmianami.
Scenariusz nr 3: migracja z usługi Data Factory z obsługą usługi Git do sieci szkieletowej
Często, choć niekoniecznie, fabryki ADF lub Synapse oraz ich obszary robocze są podłączone do własnego zewnętrznego dostawcy Git w ADO lub GitHub. W tym scenariuszu należy przeprowadzić migrację elementów fabryki i obszaru roboczego do obszaru roboczego Fabric, a następnie skonfigurować integrację Git w obszarze roboczym Fabric.
pl-PL: Fabric oferuje dwa podstawowe sposoby włączania ciągłej integracji/ciągłego wdrażania na poziomie obszaru roboczego: integrację z usługą Git, gdzie można korzystać z własnego repozytorium Git w środowisku ADO i połączyć je z Fabric, oraz wbudowane potoki wdrażania, które pozwalają promować kod do wyższych środowisk bez potrzeby dostarczania własnego repozytorium Git.
W obu przypadkach istniejące repozytorium Git z usługi ADF nie działa z usługą Fabric. Zamiast tego należy wskazać nowe repozytorium lub uruchomić nowy potok wdrażania w sieci szkieletowej i ponownie skompilować artefakty potoku w sieci szkieletowej.
Podłączanie istniejących wystąpień usługi ADF bezpośrednio do obszaru roboczego Fabrykacji
Wcześniej rozmawialiśmy o korzystaniu z aktywności Invoke Pipeline w ramach Fabric Data Factory jako mechanizmu do utrzymania istniejących inwestycji w potoki ADF i wywoływania ich bezpośrednio z Fabric. W ramach Fabric możesz pójść o krok dalej i zamontować całą fabrykę w obszarze roboczym Fabric jako natywny element Fabric.
Aby uzyskać więcej informacji na temat scenariuszy użytkowania, zobacz Scenariusze współpracy i dostarczania zawartości.
Instalowanie usługi Azure Data Factory w obszarze roboczym usługi Fabric przynosi wiele korzyści. Jeśli dopiero zaczynasz korzystać z platformy Fabric i chcesz zachować swoje fabryki obok siebie w jednym interfejsie, możesz je zamontować w Fabric, aby zarządzać nimi razem z wykorzystaniem Fabric. Pełny interfejs użytkownika usługi ADF jest teraz dostępny w twojej zamontowanej fabryce, gdzie można w pełni monitorować, zarządzać i edytować elementy fabryki usługi ADF z poziomu platformy Fabric. Ta funkcja znacznie ułatwia rozpoczęcie migracji tych elementów do Fabric jako natywnych artefaktów Fabric. Ta funkcja służy głównie dla łatwości użytkowania i ułatwia wyświetlanie fabryk ADF w twoim obszarze roboczym Fabric. Jednak rzeczywiste wykonywanie potoków, działań, środowisk Integration Runtime itp. nadal odbywa się wewnątrz zasobów usług Azure.
Powiązana zawartość
Zagadnienia dotyczące migracji z ADF do Data Factory w Fabric