Konfigurowanie usługi Azure Synapse Analytics w działaniu kopiowania
W tym artykule opisano sposób używania działania kopiowania w potoku danych do kopiowania danych z i do usługi Azure Synapse Analytics.
Obsługiwana konfiguracja
W przypadku konfiguracji każdej karty w działaniu kopiowania przejdź odpowiednio do poniższych sekcji.
Ogólne
Zapoznaj się ze wskazówkami dotyczącymi ustawień ogólnych, aby skonfigurować kartę Ustawienia ogólne.
Źródło
Następujące właściwości są obsługiwane w usłudze Azure Synapse Analytics na karcie Źródło działania kopiowania.

Wymagane są następujące właściwości:
Typ magazynu danych: wybierz pozycję Zewnętrzne.
Połączenie ion: wybierz połączenie usługi Azure Synapse Analytics z listy połączeń. Jeśli połączenie nie istnieje, utwórz nowe połączenie usługi Azure Synapse Analytics, wybierając pozycję Nowy.
Połączenie typionu: wybierz pozycję Azure Synapse Analytics.
Użyj zapytania: możesz wybrać tabelę, kwerendę lub procedurę składowaną, aby odczytać dane źródłowe. Poniższa lista zawiera opis konfiguracji każdego ustawienia:
Tabela: odczyt danych z tabeli określonej w tabeli w przypadku wybrania tego przycisku. Wybierz tabelę z listy rozwijanej lub wybierz pozycję Edytuj , aby ręcznie wprowadzić nazwę schematu i tabeli.

Zapytanie: określ niestandardowe zapytanie SQL do odczytu danych. Może to być na przykład
select * from MyTable. Możesz też wybrać ikonę ołówka, aby edytować w edytorze kodu.
Procedura składowana: użyj procedury składowanej, która odczytuje dane z tabeli źródłowej. Ostatnia instrukcja SQL musi być instrukcją SELECT w procedurze składowanej.
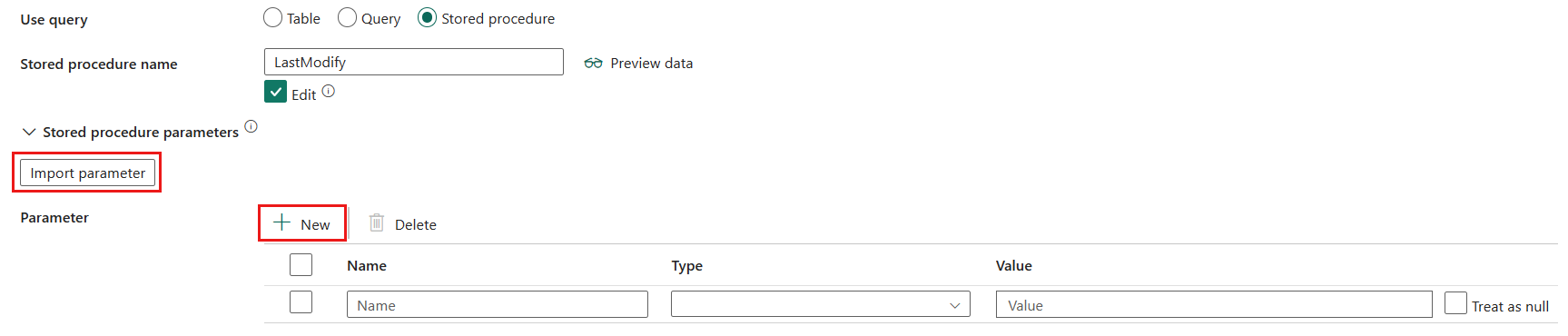
- Nazwa procedury składowanej: wybierz procedurę składowaną lub określ nazwę procedury składowanej ręcznie po wybraniu pozycji Edytuj.
- Parametry procedury składowanej: wybierz pozycję Importuj parametry , aby zaimportować parametr w określonej procedurze składowanej, lub dodaj parametry procedury składowanej, wybierając pozycję + Nowy. Dozwolone wartości to pary nazw lub wartości. Nazwy i wielkość liter parametrów muszą być zgodne z nazwami i wielkością parametrów procedury składowanej.

W obszarze Zaawansowane można określić następujące pola:
Limit czasu zapytania (minuty): określ limit czasu wykonywania polecenia zapytania, wartość domyślna to 120 minut. Jeśli parametr jest ustawiony dla tej właściwości, dozwolone wartości to przedział czasu, taki jak "02:00:00" (120 minut).
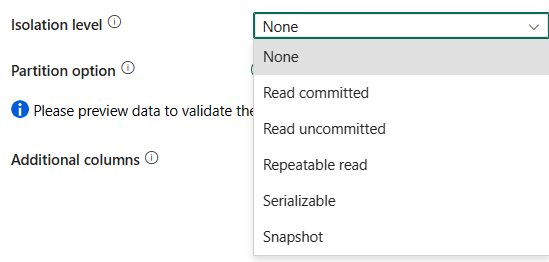
Poziom izolacji: określa zachowanie blokowania transakcji dla źródła SQL. Dozwolone wartości to: Brak, Zatwierdzone odczyty, Odczyt niezatwierdzony, Powtarzalny odczyt, Serializacja lub Migawka. Jeśli nie zostanie określony, zostanie użyty poziom izolacji Brak . Aby uzyskać więcej informacji, zapoznaj się z wyliczeniem IsolationLevel.
Opcja partycji: określ opcje partycjonowania danych używane do ładowania danych z usługi Azure Synapse Analytics. Dozwolone wartości to: Brak (wartość domyślna), Partycje fizyczne tabeli i Zakres dynamiczny. Jeśli opcja partycji jest włączona (czyli nie brak), stopień równoległości równoczesnego ładowania danych z usługi Azure Synapse Analytics jest kontrolowany przez ustawienie kopiowania równoległego w działaniu kopiowania .
Brak: wybierz to ustawienie, aby nie używać partycji.
Partycje fizyczne tabeli: wybierz to ustawienie, jeśli chcesz użyć partycji fizycznej. Kolumna partycji i mechanizm są automatycznie określane na podstawie definicji tabeli fizycznej.
Zakres dynamiczny: wybierz to ustawienie, jeśli chcesz użyć partycji zakresu dynamicznego. W przypadku korzystania z zapytania z włączonym równoległym parametrem partycji zakresu (
?DfDynamicRangePartitionCondition) jest wymagany. Przykładowe zapytanie:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.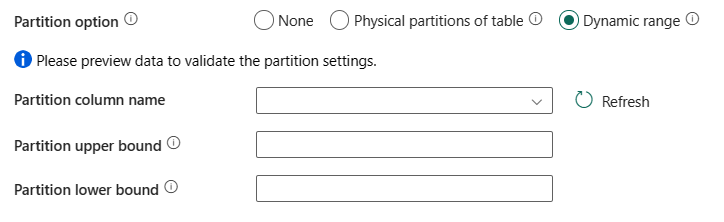
- Nazwa kolumny partycji: określ nazwę kolumny źródłowej w liczbach całkowitych lub typ daty/daty/godziny (
int,smallint,smalldatetimebigintdatetimedate,datetime2lubdatetimeoffset) używany przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli jest automatycznie wykrywany i używany jako kolumna partycji. - Górna granica partycji: określ maksymalną wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania są partycjonowane i kopiowane.
- Dolna granica partycji: określ minimalną wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania są partycjonowane i kopiowane.
- Nazwa kolumny partycji: określ nazwę kolumny źródłowej w liczbach całkowitych lub typ daty/daty/godziny (
Dodatkowe kolumny: Dodaj dodatkowe kolumny danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Wyrażenie jest obsługiwane w przypadku tych ostatnich. Aby uzyskać więcej informacji, zobacz Dodawanie dodatkowych kolumn podczas kopiowania.
Element docelowy
Następujące właściwości są obsługiwane w usłudze Azure Synapse Analytics na karcie Miejsce docelowe działania kopiowania.
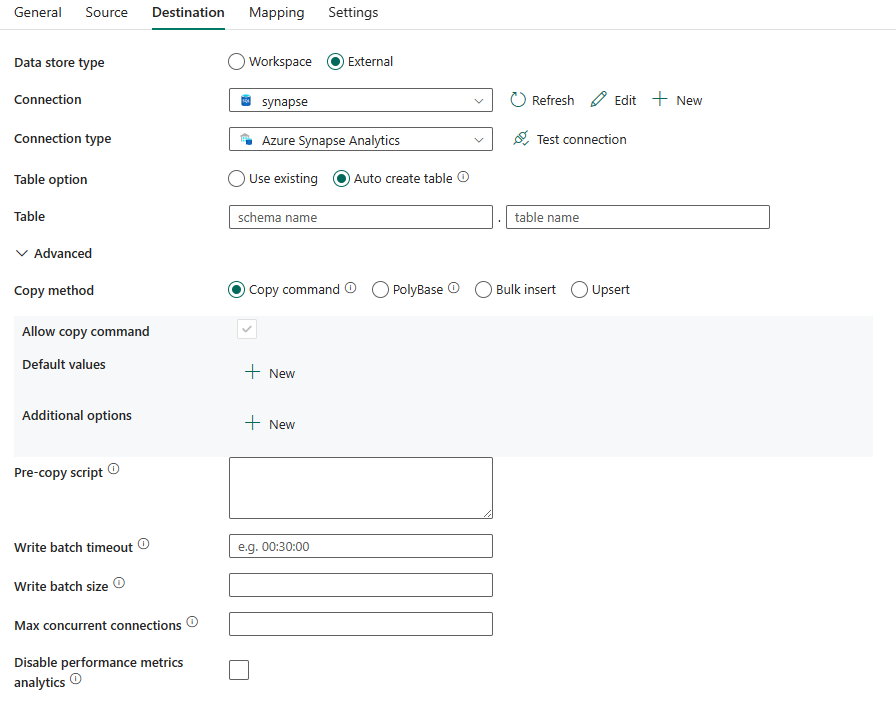
Wymagane są następujące właściwości:
- Typ magazynu danych: wybierz pozycję Zewnętrzne.
- Połączenie ion: wybierz połączenie usługi Azure Synapse Analytics z listy połączeń. Jeśli połączenie nie istnieje, utwórz nowe połączenie usługi Azure Synapse Analytics, wybierając pozycję Nowy.
- Połączenie typionu: wybierz pozycję Azure Synapse Analytics.
- Opcja tabela: możesz wybrać opcję Użyj istniejącej, Automatyczne tworzenie tabeli. Poniższa lista zawiera opis konfiguracji każdego ustawienia:
- Użyj istniejącej: wybierz tabelę w bazie danych z listy rozwijanej. Możesz też ręcznie zaznaczyć opcję Edytuj , aby ręcznie wprowadzić nazwę schematu i tabeli.
- Automatyczne tworzenie tabeli: automatycznie tworzy tabelę (jeśli nie istnieje) w schemacie źródłowym.
W obszarze Zaawansowane można określić następujące pola:
Kopiuj metodę Wybierz metodę, której chcesz użyć do kopiowania danych. Możesz wybrać polecenie Kopiuj, program PolyBase, wstawianie zbiorcze lub upsert. Poniższa lista zawiera opis konfiguracji każdego ustawienia:
Kopiuj polecenie: użyj instrukcji COPY, aby załadować dane z usługi Azure Storage do usługi Azure Synapse Analytics lub puli SQL.
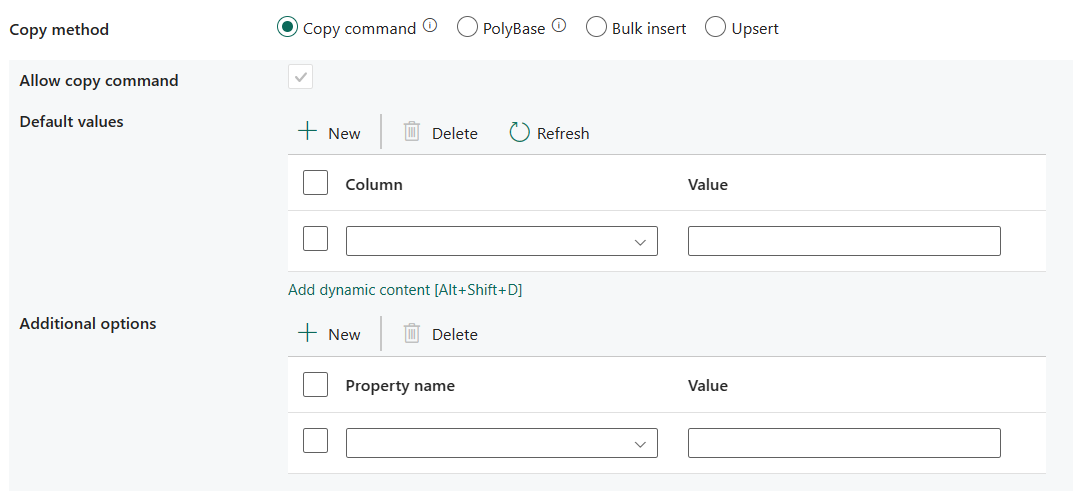
- Zezwalaj na kopiowanie polecenia: podczas wybierania polecenia Kopiuj należy wybrać polecenie .
- Wartości domyślne: określ wartości domyślne dla każdej kolumny docelowej w usłudze Azure Synapse Analytics. Wartości domyślne we właściwości zastępują ograniczenie DOMYŚLNE ustawione w magazynie danych, a kolumna tożsamości nie może mieć wartości domyślnej.
- Dodatkowe opcje: dodatkowe opcje, które zostaną przekazane do instrukcji COPY usługi Azure Synapse Analytics bezpośrednio w klauzuli "With" w instrukcji COPY. Podaj wartość zgodnie z potrzebami, aby dopasować się do wymagań instrukcji COPY.
PolyBase: Technologia PolyBase to mechanizm o wysokiej przepływności. Służy do ładowania dużych ilości danych do usługi Azure Synapse Analytics lub puli SQL.
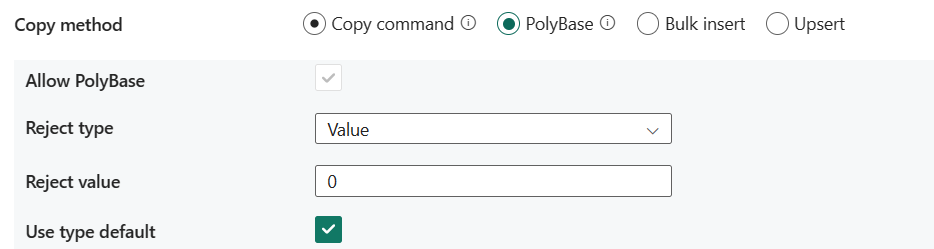
- Zezwalaj na program PolyBase: wybranie opcji PolyBase jest obowiązkowe.
- Typ odrzucenia: określ, czy opcja rejectValue jest wartością literału, czy wartością procentową. Dozwolone wartości to Wartość (wartość domyślna) i Wartość procentowa.
- Odrzuć wartość: określ liczbę lub procent wierszy, które można odrzucić przed niepowodzeniem zapytania. Dowiedz się więcej o opcjach odrzucania technologii PolyBase w sekcji Argumenty w temacie CREATE EXTERNAL TABLE (Transact-SQL). Dozwolone wartości to 0 (wartość domyślna), 1, 2 itd.
- Odrzuć przykładową wartość: określa liczbę wierszy do pobrania przed ponownym obliczeniu wartości procentowej odrzuconych wierszy przez program PolyBase. Dozwolone wartości to 1, 2 itd. Jeśli wybierzesz wartość Procent jako typ odrzucenia, ta właściwość jest wymagana.
- Użyj domyślnego typu: określ sposób obsługi brakujących wartości w rozdzielanych plikach tekstowych, gdy program PolyBase pobiera dane z pliku tekstowego. Dowiedz się więcej o tej właściwości w sekcji Argumenty w temacie CREATE EXTERNAL FILE FORMAT (Transact-SQL). Dozwolone wartości są zaznaczone (domyślne) lub niezaznaczone.
Wstawianie zbiorcze: zbiorcze wstawianie służy do wstawiania zbiorczego danych do miejsca docelowego.

- Blokada wstawiania zbiorczego tabeli: umożliwia zwiększenie wydajności kopiowania podczas operacji wstawiania zbiorczego w tabeli bez indeksu z wielu klientów. Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL).Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL).
Upsert: określ grupę ustawień zachowania zapisu, gdy chcesz upsert danych do miejsca docelowego.
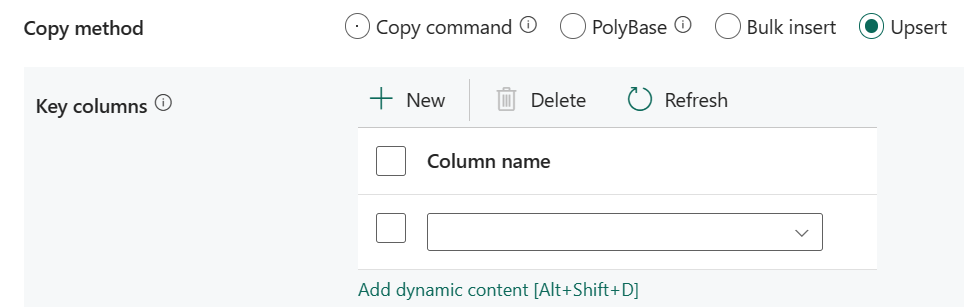
Kolumny klucza: wybierz kolumnę używaną do określenia, czy wiersz ze źródła pasuje do wiersza z miejsca docelowego.
Blokada wstawiania zbiorczego tabeli: umożliwia zwiększenie wydajności kopiowania podczas operacji wstawiania zbiorczego w tabeli bez indeksu z wielu klientów. Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL).Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL).
Skrypt wstępny: określ skrypt działania kopiowania do wykonania przed zapisaniem danych w tabeli docelowej w każdym przebiegu. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane.
Limit czasu zapisu wsadowego: określ czas oczekiwania na zakończenie operacji wstawiania wsadowego przed przekroczeniem limitu czasu. Dozwolona wartość to przedział czasu. Wartość domyślna to "00:30:00" (30 minut).
Rozmiar partii zapisu: określ liczbę wierszy do wstawienia do tabeli SQL na partię. Dozwolona wartość to liczba całkowita (liczba wierszy). Domyślnie usługa dynamicznie określa odpowiedni rozmiar partii na podstawie rozmiaru wiersza.
Maksymalna liczba połączeń współbieżnych: określ górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne.
Wyłącz analizę metryk wydajności: to ustawienie służy do zbierania metryk, takich jak DTU, DWU, RU itd., na potrzeby optymalizacji wydajności i zaleceń dotyczących kopiowania. Jeśli interesuje Cię to zachowanie, zaznacz to pole wyboru. Jest on domyślnie niezaznaczony.
Kopiowanie bezpośrednie przy użyciu polecenia COPY
Polecenie kopiowania usługi Azure Synapse Analytics bezpośrednio obsługuje usługi Azure Blob Storage i Azure Data Lake Storage Gen2 jako źródłowe magazyny danych. Jeśli dane źródłowe spełniają kryteria opisane w tej sekcji, użyj polecenia COPY, aby skopiować bezpośrednio ze źródłowego magazynu danych do usługi Azure Synapse Analytics.
Dane źródłowe i format zawierają następujące typy i metody uwierzytelniania:
Obsługiwany typ magazynu danych źródłowych Obsługiwany format Obsługiwany typ uwierzytelniania źródłowego Azure Blob Storage Rozdzielany tekst
ParquetUwierzytelnianie anonimowe
Uwierzytelnianie klucza konta
Uwierzytelnianie sygnatury dostępu współdzielonegoAzure Data Lake Storage Gen2 Rozdzielany tekst
ParquetUwierzytelnianie klucza konta
Uwierzytelnianie sygnatury dostępu współdzielonegoMożna ustawić następujące ustawienia formatu:
- W przypadku parquet: typ kompresji może mieć wartość None, snappy lub gzip.
- Dla tekstu rozdzielanego:
- Ogranicznik wierszy: podczas kopiowania tekstu rozdzielanego do usługi Azure Synapse Analytics za pomocą bezpośredniego polecenia COPY określ ogranicznik wierszy jawnie (\r; \n; lub \r\n\n). Tylko wtedy, gdy ogranicznik wiersza pliku źródłowego to \r\n, wartość domyślna (\r, \n lub \r\n). W przeciwnym razie włącz przemieszczanie dla danego scenariusza.
- Wartość null jest pozostawiona jako domyślna lub ustawiona na pusty ciąg ("").
- Kodowanie jest pozostawione jako domyślne lub ustawione na UTF-8 lub UTF-16.
- Pomiń liczbę wierszy jest pozostawiona jako domyślna lub ustawiona na 0.
- Typ kompresji może mieć wartość Brak lub gzip.
Jeśli źródło jest folderem, należy zaznaczyć pole wyboru Rekursywnie .
Czas rozpoczęcia (UTC) i godzina zakończenia (UTC) w obszarze Filtruj według ostatniej modyfikacji, Prefiksu, Włącz odnajdywanie partycji i Dodatkowe kolumny nie są określone.
Aby dowiedzieć się, jak pozyskiwać dane do usługi Azure Synapse Analytics przy użyciu polecenia COPY, zobacz ten artykuł.
Jeśli źródłowy magazyn danych i format nie są pierwotnie obsługiwane przez polecenie COPY, użyj funkcji kopiowania etapowego za pomocą funkcji polecenia COPY. Automatycznie konwertuje dane na format zgodny z poleceniem COPY, a następnie wywołuje polecenie COPY w celu załadowania danych do usługi Azure Synapse Analytics.
Mapowanie
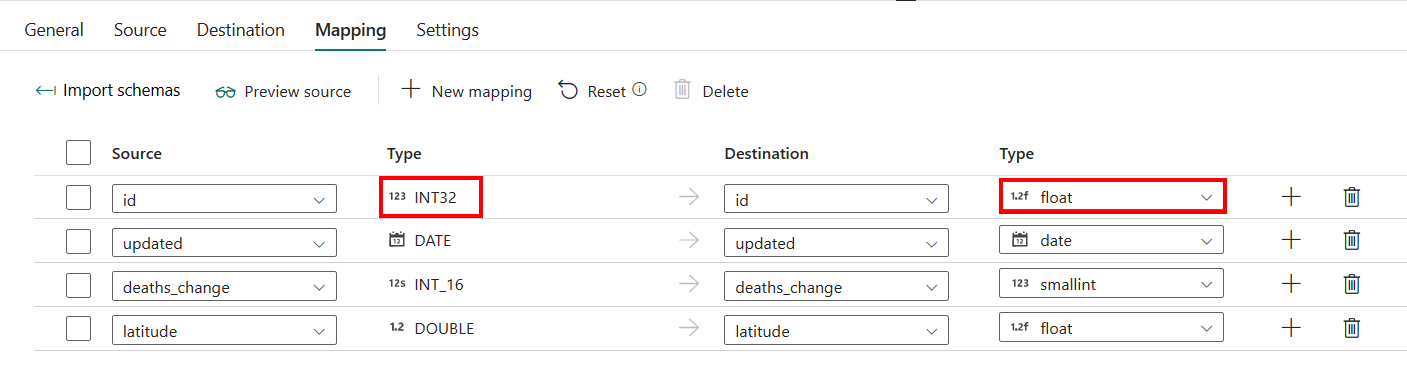
W przypadku konfiguracji karty Mapowanie , jeśli nie zastosujesz usługi Azure Synapse Analytics z tabelą automatycznego tworzenia jako miejsca docelowego, przejdź do pozycji Mapowanie.
Jeśli zastosujesz usługę Azure Synapse Analytics z tabelą automatycznego tworzenia jako lokalizacją docelową, z wyjątkiem konfiguracji w obszarze Mapowanie, możesz edytować typ kolumn docelowych. Po wybraniu pozycji Importuj schematy można określić typ kolumny w miejscu docelowym.
Na przykład typ kolumny ID w źródle jest int i można zmienić go na typ zmiennoprzecinkowy podczas mapowania na kolumnę docelową.
Ustawienia
Aby uzyskać Ustawienia konfiguracji karty, przejdź do sekcji Konfigurowanie innych ustawień na karcie ustawienia.
Kopiowanie równoległe z usługi Azure Synapse Analytics
Łącznik usługi Azure Synapse Analytics w działaniu kopiowania zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych. Opcje partycjonowania danych można znaleźć na karcie Źródło działania kopiowania.
Po włączeniu kopii partycjonowanej działanie kopiowania uruchamia zapytania równoległe względem źródła usługi Azure Synapse Analytics w celu załadowania danych według partycji. Stopień równoległy jest kontrolowany przez stopień równoległości kopiowania na karcie ustawień działania kopiowania. Jeśli na przykład ustawisz opcję Stopień równoległości kopiowania na cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z usługi Azure Synapse Analytics.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z usługi Azure Synapse Analytics. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli z partycjami fizycznymi. | Opcja partycji: fizyczne partycje tabeli. Podczas wykonywania usługa automatycznie wykrywa partycje fizyczne i kopiuje dane według partycji. Aby sprawdzić, czy tabela ma partycję fizyczną, czy nie, możesz odwołać się do tego zapytania. |
| Pełne ładowanie z dużej tabeli, bez partycji fizycznych, podczas gdy z liczbą całkowitą lub kolumną datetime na potrzeby partycjonowania danych. | Opcje partycji: partycja zakresu dynamicznego. Kolumna partycji (opcjonalnie): określ kolumnę używaną do partycjonowania danych. Jeśli nie zostanie określony, zostanie użyta kolumna indeksu lub klucza podstawowego. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie dotyczy to filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykryje wartości. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona na wartość 20, a górna granica to 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, bez partycji fizycznych, natomiast z liczbą całkowitą lub kolumną date/datetime na potrzeby partycjonowania danych. | Opcje partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie jest to przeznaczone do filtrowania wierszy w tabeli, wszystkie wiersze w wyniku zapytania zostaną partycjonowane i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona jako 20 i górna granica jako 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. Poniżej przedstawiono więcej przykładowych zapytań dla różnych scenariuszy: • Wykonaj zapytanie dotyczące całej tabeli: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Kwerenda z tabeli z zaznaczeniem kolumny i dodatkowymi filtrami klauzuli where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Kwerenda z podzapytaniami: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Zapytanie z partycją w podzapytaniu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Najlepsze rozwiązania dotyczące ładowania danych z opcją partycji:
- Wybierz charakterystyczną kolumnę jako kolumnę partycji (np. klucz podstawowy lub unikatowy klucz), aby uniknąć niesymetryczności danych.
- Jeśli tabela ma wbudowaną partycję, użyj opcji partycji Partycja Partycje fizyczne tabeli , aby uzyskać lepszą wydajność.
- Usługa Azure Synapse Analytics może wykonywać maksymalnie 32 zapytania w danym momencie, ustawiając zbyt duży stopień równoległości kopiowania, może spowodować problem z ograniczaniem przepustowości usługi Synapse.
Przykładowe zapytanie do sprawdzania partycji fizycznej
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Jeśli tabela ma partycję fizyczną, zostanie wyświetlona wartość "HasPartition" jako "tak".
Podsumowanie tabeli
Poniższe tabele zawierają więcej informacji na temat działania kopiowania w usłudze Azure Synapse Analytics.
Źródło
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Typ magazynu danych | Typ magazynu danych. | Zewnętrzne | Tak | / |
| Połączenie | Połączenie ze źródłowym magazynem danych. | < połączenie > | Tak | połączenie |
| Connection type (Typ połączenia) | Typ połączenia źródłowego. | Azure Synapse Analytics | Tak | / |
| Korzystanie z zapytania | Sposób odczytywania danych. | •Tabeli •Kwerendy • Procedura składowana |
Tak | • typeProperties (poniżej typeProperties ->source)-Schematu -Tabeli • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters -Nazwa -Wartość |
| Limit czasu zapytania | Limit czasu wykonywania polecenia zapytania, wartość domyślna to 120 minut. | zakres czasu | Nie. | Querytimeout |
| Poziom izolacji | Zachowanie blokowania transakcji dla źródła SQL. | •Brak • Odczyt zatwierdzony • Odczytywanie niezatwierdzonych • Powtarzalny odczyt •Serializacji •Migawka |
Nie. | Isolationlevel: •Readcommitted •Readuncommitted •Repeatableread •Serializacji •Migawka |
| Opcja partycji | Opcje partycjonowania danych używane do ładowania danych z usługi Azure SQL Database. | •Brak • Fizyczne partycje tabeli • Zakres dynamiczny - Nazwa kolumny partycji — Górna granica partycji - Partycja dolna granica |
Nie. | Partitionoption: • PhysicalPartitionsOfTable • DynamicRange partition Ustawienia: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| Dodatkowe kolumny | Dodaj dodatkowe kolumny danych, aby przechowywać ścieżkę względną plików źródłowych lub wartość statyczną. Wyrażenie jest obsługiwane w przypadku tych ostatnich. | • Nazwa •Wartość |
Nie. | additionalColumns: •Nazwa •Wartość |
Element docelowy
| Nazwa/nazwisko | Opis | Wartość | Wymagania | Właściwość skryptu JSON |
|---|---|---|---|---|
| Typ magazynu danych | Typ magazynu danych. | Zewnętrzne | Tak | / |
| Połączenie | Połączenie z docelowym magazynem danych. | < połączenie > | Tak | połączenie |
| Connection type (Typ połączenia) | Typ połączenia docelowego. | Azure Synapse Analytics | Tak | / |
| Opcja tabeli | Opcja docelowej tabeli danych. | • Użyj istniejącej • Automatyczne tworzenie tabeli |
Tak | • typeProperties (poniżej typeProperties ->sink)-Schematu -Tabeli • tableOption: - AutoTworzenie typeProperties (w obszarze typeProperties ->sink)-Schematu -Tabeli |
| Copy, metoda | Metoda używana do kopiowania danych. | • Kopiuj polecenie • PolyBase • Wstawianie zbiorcze • Upsert |
Nie. | / |
| Podczas wybierania polecenia Kopiuj | Użyj instrukcji COPY, aby załadować dane z usługi Azure Storage do usługi Azure Synapse Analytics lub puli SQL. | / | L.p. Zastosuj w przypadku korzystania z funkcji COPY. |
allowCopyCommand: true copyCommand Ustawienia |
| Wartości domyślne | Określ wartości domyślne dla każdej kolumny docelowej w usłudze Azure Synapse Analytics. Wartości domyślne we właściwości zastępują ograniczenie DOMYŚLNE ustawione w magazynie danych, a kolumna tożsamości nie może mieć wartości domyślnej. | < wartości domyślne > | Nie. | Defaultvalues: -Columnname -Defaultvalue |
| Dodatkowe opcje | Dodatkowe opcje, które zostaną przekazane do instrukcji COPY usługi Azure Synapse Analytics bezpośrednio w klauzuli "With" w instrukcji COPY. Podaj wartość zgodnie z potrzebami, aby dopasować się do wymagań instrukcji COPY. | < dodatkowe opcje > | Nie. | additionalOptions: - <nazwa> właściwości: <wartość> |
| Podczas wybierania programu PolyBase | Technologia PolyBase to mechanizm o wysokiej przepływności. Służy do ładowania dużych ilości danych do usługi Azure Synapse Analytics lub puli SQL. | / | L.p. Zastosuj w przypadku korzystania z technologii PolyBase. |
allowPolyBase: true polyBase Ustawienia |
| Typ odrzucania | Typ wartości odrzucania. | •Wartość •Procent |
Nie. | rejectType: -Wartość -Procent |
| Odrzuć wartość | Liczba lub procent wierszy, które można odrzucić przed niepowodzeniem zapytania. | 0 (wartość domyślna), 1, 2 itd. | Nie. | rejectValue |
| Odrzuć przykładową wartość | Określa liczbę wierszy do pobrania przed ponownym obliczeniu wartości procentowej odrzuconych wierszy przez program PolyBase. | 1, 2 itd. | Tak po określeniu wartości Procentowej jako typu odrzucenia | rejectSampleValue |
| Użyj domyślnego typu | Określ sposób obsługi brakujących wartości w rozdzielanych plikach tekstowych, gdy program PolyBase pobiera dane z pliku tekstowego. Dowiedz się więcej o tej właściwości w sekcji Argumenty w temacie CREATE EXTERNAL FILE FORMAT (Transact-SQL) | wybrane (domyślne) lub niezaznaczone. | Nie. | useTypeDefault: true (wartość domyślna) lub fałsz |
| Podczas wybierania operacji wstawiania zbiorczego | Zbiorcze wstawianie danych do miejsca docelowego. | / | Nie. | writeBehavior: Wstaw |
| Zbiorcze wstawianie blokady tabeli | Umożliwia to zwiększenie wydajności kopiowania podczas operacji wstawiania zbiorczego w tabeli bez indeksu z wielu klientów. Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL).Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL). | wybrane lub niezaznaczone (ustawienie domyślne) | Nie. | sqlWriterUseTableLock: true lub false (wartość domyślna) |
| Podczas wybierania opcji Upsert | Określ grupę ustawień zachowania zapisu, jeśli chcesz zmienić dane na miejsce docelowe. | / | Nie. | writeBehavior: Upsert |
| Kolumny kluczy | Wskazuje, która kolumna jest używana do określenia, czy wiersz ze źródła pasuje do wiersza z miejsca docelowego. | < nazwa kolumny> | Nie. | upsert Ustawienia: - klucze: < nazwa kolumny > - interimSchemaName |
| Zbiorcze wstawianie blokady tabeli | Umożliwia to zwiększenie wydajności kopiowania podczas operacji wstawiania zbiorczego w tabeli bez indeksu z wielu klientów. Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL).Dowiedz się więcej na temat instrukcji BULK INSERT (Transact-SQL). | wybrane lub niezaznaczone (ustawienie domyślne) | Nie. | sqlWriterUseTableLock: true lub false (wartość domyślna) |
| Skrypt wstępny | Skrypt działania kopiowania do wykonania przed zapisaniem danych w tabeli docelowej w każdym przebiegu. Za pomocą tej właściwości można wyczyścić wstępnie załadowane dane. | < skrypt wstępny > (ciąg) |
Nie. | preCopyScript |
| Limit czasu zapisu wsadowego | Czas oczekiwania na zakończenie operacji wstawiania wsadowego przed upływem limitu czasu. Dozwolona wartość to przedział czasu. Wartość domyślna to "00:30:00" (30 minut). | zakres czasu | Nie. | writeBatchTimeout |
| Rozmiar partii zapisu | Liczba wierszy do wstawiania do tabeli SQL na partię. Domyślnie usługa dynamicznie określa odpowiedni rozmiar partii na podstawie rozmiaru wiersza. | < liczba wierszy > (liczba całkowita) |
Nie. | writeBatchSize |
| Maksymalna liczba połączeń współbieżnych | Górny limit połączeń współbieżnych ustanowionych z magazynem danych podczas uruchamiania działania. Określ wartość tylko wtedy, gdy chcesz ograniczyć połączenia współbieżne. | < górny limit połączeń współbieżnych > (liczba całkowita) |
Nie. | maxConcurrent Połączenie ions |
| Wyłączanie analizy metryk wydajności | To ustawienie służy do zbierania metryk, takich jak DTU, DWU, RU itd., na potrzeby optymalizacji wydajności kopiowania i zaleceń. Jeśli interesuje Cię to zachowanie, zaznacz to pole wyboru. | zaznacz lub usuń zaznaczenie (ustawienie domyślne) | Nie. | disableMetricsCollection: true lub false (wartość domyślna) |