Projektowanie aplikacji zorientowanej na mikrousługi
Napiwek
Ta zawartość jest fragmentem książki eBook, architektury mikrousług platformy .NET dla konteneryzowanych aplikacji platformy .NET dostępnych na platformie .NET Docs lub jako bezpłatnego pliku PDF, który można odczytać w trybie offline.

Ta sekcja koncentruje się na tworzeniu hipotetycznej aplikacji dla przedsiębiorstw po stronie serwera.
Specyfikacje aplikacji
Hipotetyczna aplikacja obsługuje żądania przez wykonywanie logiki biznesowej, uzyskiwanie dostępu do baz danych, a następnie zwracanie odpowiedzi HTML, JSON lub XML. Powiemy, że aplikacja musi obsługiwać różnych klientów, w tym przeglądarek klasycznych z aplikacjami jednostronicowymi (SPA), tradycyjnymi aplikacjami internetowymi, mobilnymi aplikacjami internetowymi i natywnymi aplikacjami mobilnymi. Aplikacja może również uwidaczniać interfejs API, który może być używany przez inne firmy. Powinna również mieć możliwość asynchronicznej integracji mikrousług lub aplikacji zewnętrznych, dzięki czemu takie podejście pomoże w odporności mikrousług w przypadku częściowych awarii.
Aplikacja będzie składać się z następujących typów składników:
Składniki prezentacji. Te składniki są odpowiedzialne za obsługę interfejsu użytkownika i korzystanie z usług zdalnych.
Domena lub logika biznesowa. Ten składnik jest logiką domeny aplikacji.
Logika dostępu do bazy danych. Ten składnik składa się ze składników dostępu do danych odpowiedzialnych za uzyskiwanie dostępu do baz danych (SQL lub NoSQL).
Logika integracji aplikacji. Ten składnik zawiera kanał obsługi komunikatów oparty na brokerach komunikatów.
Aplikacja będzie wymagała wysokiej skalowalności, pozwalając jednocześnie na autonomiczne skalowanie podsystemów pionowych, ponieważ niektóre podsystemy będą wymagały większej skalowalności niż inne.
Aplikacja musi być w stanie być wdrożona w wielu środowiskach infrastruktury (wiele chmur publicznych i lokalnych), a najlepiej mieć możliwość łatwego przejścia z systemu Linux do systemu Windows (lub odwrotnie).
Kontekst zespołu deweloperów
Przyjęto również następujące założenia dotyczące procesu programowania aplikacji:
Masz wiele zespołów deweloperskich koncentrujących się na różnych obszarach biznesowych aplikacji.
Nowi członkowie zespołu muszą szybko działać wydajnie, a aplikacja musi być łatwa do zrozumienia i zmodyfikowania.
Aplikacja będzie miała długoterminową ewolucję i stale zmieniające się reguły biznesowe.
Potrzebujesz dobrej długoterminowej konserwacji, co oznacza zwinność podczas implementowania nowych zmian w przyszłości przy jednoczesnym aktualizowaniu wielu podsystemów z minimalnym wpływem na inne podsystemy.
Chcesz ćwiczyć ciągłą integrację i ciągłe wdrażanie aplikacji.
Chcesz korzystać z nowych technologii (struktur, języków programowania itp.) podczas ewolucji aplikacji. Nie chcesz wykonywać pełnych migracji aplikacji podczas przechodzenia do nowych technologii, ponieważ spowodowałoby to wysokie koszty i wpływało na przewidywalność i stabilność aplikacji.
Wybieranie architektury
Jaka powinna być architektura wdrażania aplikacji? Specyfikacje aplikacji, wraz z kontekstem programowania, zdecydowanie sugerują, że należy zaprojektować aplikację, rozkładając ją na podsystemy autonomiczne w postaci współpracy mikrousług i kontenerów, gdzie mikrousługą jest kontener.
W tym podejściu każda usługa (kontener) implementuje zestaw spójnych i wąsko powiązanych funkcji. Na przykład aplikacja może składać się z usług, takich jak usługa katalogu, usługa zamawiania, usługa koszyka, usługa profilu użytkownika itp.
Mikrousługi komunikują się przy użyciu protokołów, takich jak HTTP (REST), ale także asynchronicznie (na przykład przy użyciu protokołu AMQP), jeśli to możliwe, zwłaszcza podczas propagacji aktualizacji ze zdarzeniami integracji.
Mikrousługi są opracowywane i wdrażane jako kontenery niezależnie od siebie. Takie podejście oznacza, że zespół programistyczny może opracowywać i wdrażać określoną mikrousługę bez wpływu na inne podsystemy.
Każda mikrousługa ma własną bazę danych, umożliwiając jej całkowite oddzielenie od innych mikrousług. W razie potrzeby spójność między bazami danych z różnych mikrousług jest osiągana przy użyciu zdarzeń integracji na poziomie aplikacji (za pośrednictwem magistrali zdarzeń logicznych) zgodnie z procedurą segregacji poleceń i odpowiedzialności zapytań (CQRS). Z tego powodu ograniczenia biznesowe muszą obejmować spójność ostateczną między wieloma mikrousługami i powiązanymi bazami danych.
eShopOnContainers: aplikacja referencyjna dla platformy .NET i mikrousług wdrożonych przy użyciu kontenerów
Aby można było skupić się na architekturze i technologiach zamiast myśleć o hipotetycznej domenie biznesowej, której możesz nie wiedzieć, wybraliśmy dobrze znaną domenę biznesową — czyli uproszczoną aplikację do handlu elektronicznego (e-shop), która prezentuje katalog produktów, pobiera zamówienia od klientów, weryfikuje spis i wykonuje inne funkcje biznesowe. Ten kod źródłowy aplikacji opartej na kontenerze jest dostępny w repozytorium GitHub eShopOnContainers .
Aplikacja składa się z wielu podsystemów, w tym kilku frontonów interfejsu użytkownika sklepu (aplikacja internetowa i natywna aplikacja mobilna) wraz z mikrousługami zaplecza i kontenerami dla wszystkich wymaganych operacji po stronie serwera z kilkoma bramami interfejsu API jako skonsolidowanymi punktami wejścia do wewnętrznych mikrousług. Rysunek 6–1 przedstawia architekturę aplikacji referencyjnej.
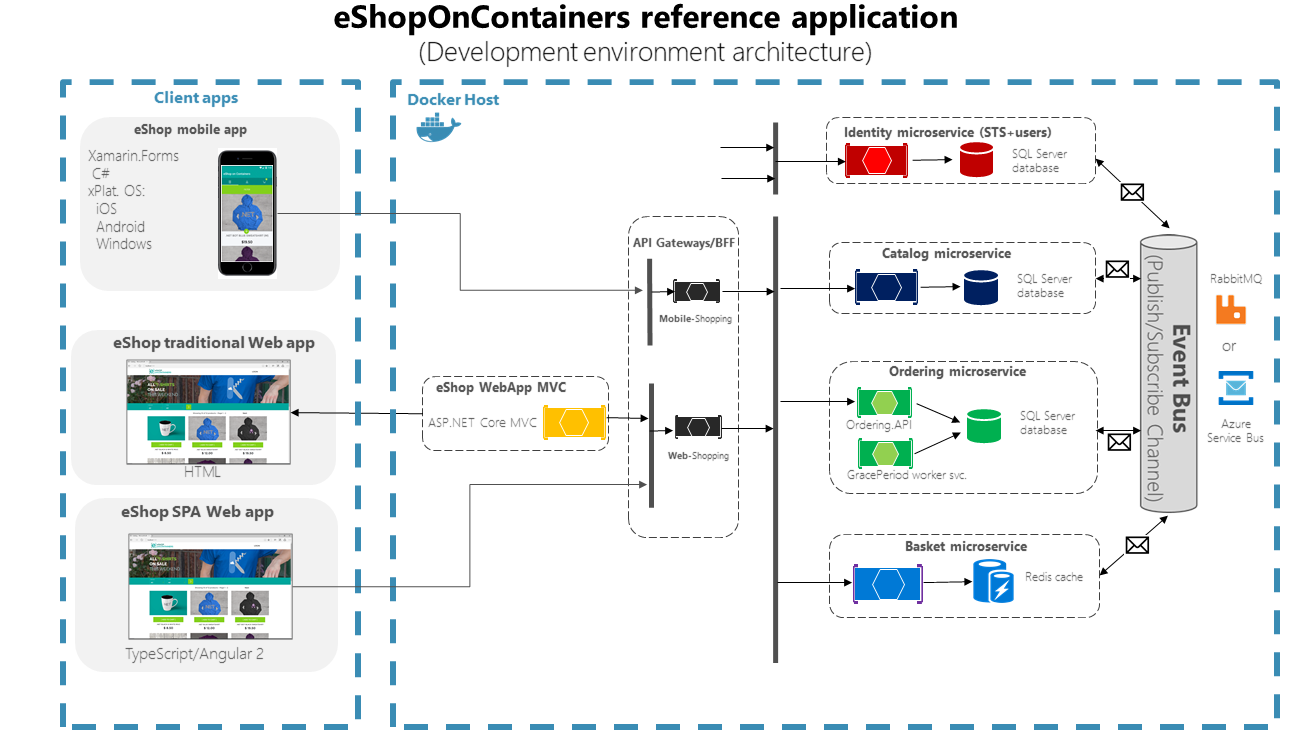
Rysunek 6–1. Architektura aplikacji referencyjnej eShopOnContainers dla środowiska deweloperskiego
Na powyższym diagramie pokazano, że klienci mobilni i SPA komunikują się z punktami końcowymi bramy pojedynczego interfejsu API, które następnie komunikują się z mikrousługami. Tradycyjni klienci sieci Web komunikują się z mikrousługą MVC, która komunikuje się z mikrousługami za pośrednictwem bramy interfejsu API.
Środowisko hostingu. Na rysunku 6–1 widać kilka kontenerów wdrożonych na jednym hoście platformy Docker. Tak byłoby w przypadku wdrażania na jednym hoście platformy Docker za pomocą polecenia docker-compose up. Jeśli jednak używasz orkiestratora lub klastra kontenerów, każdy kontener może być uruchomiony na innym hoście (węźle), a dowolny węzeł może mieć dowolną liczbę kontenerów, jak wyjaśniono wcześniej w sekcji architektury.
Architektura komunikacji. Aplikacja eShopOnContainers używa dwóch typów komunikacji, w zależności od rodzaju akcji funkcjonalnej (zapytania a aktualizacje i transakcje):
Komunikacja między klientem i mikrousługą http za pośrednictwem bram interfejsu API. To podejście jest używane w przypadku zapytań i akceptowania poleceń aktualizacji lub transakcyjnych z aplikacji klienckich. Podejście korzystające z bram interfejsu API zostało szczegółowo wyjaśnione w kolejnych sekcjach.
Asynchroniczna komunikacja oparta na zdarzeniach. Ta komunikacja odbywa się za pośrednictwem magistrali zdarzeń w celu propagowania aktualizacji między mikrousługami lub integracji z aplikacjami zewnętrznymi. Magistralę zdarzeń można zaimplementować przy użyciu dowolnej technologii infrastruktury brokera komunikatów, takiej jak RabbitMQ, lub korzystając z magistrali usług wyższego poziomu (abstrakcji), takich jak Azure Service Bus, NServiceBus, MassTransit lub Brighter.
Aplikacja jest wdrażana jako zestaw mikrousług w postaci kontenerów. Aplikacje klienckie mogą komunikować się z tymi mikrousługami działającymi jako kontenery za pośrednictwem publicznych adresów URL opublikowanych przez bramy interfejsu API.
Suwerenność danych przypadająca na mikrousługę
W przykładowej aplikacji każda mikrousługa jest właścicielem własnej bazy danych lub źródła danych, chociaż wszystkie bazy danych programu SQL Server są wdrażane jako pojedynczy kontener. Ta decyzja projektowa została podjęta tylko w celu ułatwienia deweloperowi pobrania kodu z usługi GitHub, sklonowania go i otwarcia go w programie Visual Studio lub Visual Studio Code. Alternatywnie ułatwia kompilowanie niestandardowych obrazów platformy Docker przy użyciu interfejsu wiersza polecenia platformy .NET i interfejsu wiersza polecenia platformy Docker, a następnie wdrażania i uruchamiania ich w środowisku projektowym platformy Docker. Użycie kontenerów dla źródeł danych umożliwia deweloperom tworzenie i wdrażanie w ciągu kilku minut bez konieczności aprowizacji zewnętrznej bazy danych lub dowolnego innego źródła danych z twardymi zależnościami infrastruktury (chmury lub środowiska lokalnego).
W rzeczywistym środowisku produkcyjnym w celu zapewnienia wysokiej dostępności i skalowalności bazy danych powinny być oparte na serwerach baz danych w chmurze lub lokalnie, ale nie w kontenerach.
W związku z tym jednostki wdrażania dla mikrousług (a nawet baz danych w tej aplikacji) to kontenery platformy Docker, a aplikacja referencyjna jest aplikacją wielokontenerową obejmującą zasady mikrousług.
Dodatkowe zasoby
- repozytorium GitHub eShopOnContainers. Kod źródłowy aplikacji referencyjnej
https://aka.ms/eShopOnContainers/
Zalety rozwiązania opartego na mikrousługach
Rozwiązanie oparte na mikrousługach ma wiele korzyści:
Każda mikrousługa jest stosunkowo mała — łatwa do zarządzania i rozwoju. Szczególnie:
Deweloper może łatwo zrozumieć i szybko rozpocząć pracę z dobrą produktywnością.
Kontenery zaczynają się szybko, co sprawia, że deweloperzy są bardziej wydajni.
Środowisko IDE, takie jak Program Visual Studio, może szybko ładować mniejsze projekty, dzięki czemu deweloperzy są wydajni.
Każdą mikrousługę można projektować, opracowywać i wdrażać niezależnie od innych mikrousług, które zapewniają elastyczność, ponieważ łatwiej jest często wdrażać nowe wersje mikrousług.
Istnieje możliwość skalowania poszczególnych obszarów aplikacji w poziomie. Na przykład usługa wykazu lub usługa koszyka może wymagać skalowania w poziomie, ale nie procesu zamawiania. Infrastruktura mikrousług będzie znacznie bardziej wydajna w odniesieniu do zasobów używanych podczas skalowania w górę niż architektura monolityczna.
Możesz podzielić prace programistyczne między wieloma zespołami. Każda usługa może należeć do jednego zespołu deweloperów. Każdy zespół może zarządzać, opracowywać, wdrażać i skalować swoją usługę niezależnie od pozostałych zespołów.
Problemy są bardziej odizolowane. Jeśli występuje problem w jednej usłudze, tylko na tę usługę początkowo ma to wpływ (z wyjątkiem sytuacji, gdy jest używany niewłaściwy projekt, z bezpośrednimi zależnościami między mikrousługami), a inne usługi mogą nadal obsługiwać żądania. Z kolei jeden składnik, który działa nieprawidłowo w architekturze wdrożenia monolitycznego, może obniżyć cały system, zwłaszcza gdy obejmuje zasoby, takie jak wyciek pamięci. Ponadto po rozwiązaniu problemu w mikrousłudze można wdrożyć tylko tę mikrousługę bez wpływu na pozostałą część aplikacji.
Możesz użyć najnowszych technologii. Ponieważ możesz niezależnie rozpocząć tworzenie usług i uruchamiać je obok siebie (dzięki kontenerom i platformie .NET), możesz zacząć korzystać z najnowszych technologii i struktur, aby przyspieszyć pracę, zamiast blokować się na starszym stosie lub strukturze dla całej aplikacji.
Wady rozwiązania opartego na mikrousługach
Rozwiązanie oparte na mikrousługach ma również pewne wady:
Aplikacja rozproszona. Dystrybucja aplikacji zwiększa złożoność deweloperów podczas projektowania i tworzenia usług. Deweloperzy muszą na przykład zaimplementować komunikację między usługami przy użyciu protokołów, takich jak HTTP lub AMQP, co zwiększa złożoność testowania i obsługi wyjątków. Dodaje również opóźnienie do systemu.
Złożoność wdrożenia. Aplikacja, która ma dziesiątki typów mikrousług i wymaga wysokiej skalowalności (musi być w stanie utworzyć wiele wystąpień na usługę i zrównoważyć te usługi na wielu hostach) oznacza wysoki stopień złożoności wdrażania dla operacji IT i zarządzania. Jeśli nie używasz infrastruktury zorientowanej na mikrousługę (na przykład orkiestratora i harmonogramu), dodatkowa złożoność może wymagać znacznie więcej wysiłków programistycznych niż sama aplikacja biznesowa.
Transakcje niepodzielne. Transakcje niepodzielne między wieloma mikrousługami zwykle nie są możliwe. Wymagania biznesowe muszą obejmować spójność ostateczną między wieloma mikrousługami. Aby uzyskać więcej informacji, zobacz wyzwania związane z przetwarzaniem komunikatów idempotentnych.
Zwiększone globalne potrzeby zasobów (łączna ilość pamięci, dysków i zasobów sieciowych dla wszystkich serwerów lub hostów). W wielu przypadkach, gdy zastąpisz aplikację monolityczną metodą mikrousług, ilość początkowych zasobów globalnych potrzebnych przez nową aplikację opartą na mikrousługach będzie większa niż potrzeby infrastruktury oryginalnej aplikacji monolitycznej. Takie podejście jest spowodowane tym, że wyższy stopień szczegółowości i usług rozproszonych wymaga większej liczby zasobów globalnych. Jednak biorąc pod uwagę ogólne niskie koszty zasobów i korzyści wynikające z możliwości skalowania w poziomie niektórych obszarów aplikacji w porównaniu z kosztami długoterminowymi podczas ewolucji aplikacji monolitycznych, zwiększone wykorzystanie zasobów jest zwykle dobrym kompromisem w przypadku dużych, długoterminowych aplikacji.
Problemy z bezpośrednią komunikacją między klientem a mikrousługą. Gdy aplikacja jest duża, z dziesiątkami mikrousług, istnieją wyzwania i ograniczenia, jeśli aplikacja wymaga bezpośredniej komunikacji między klientem a mikrousługą. Jednym z problemów jest potencjalna niezgodność między potrzebami klienta a interfejsami API udostępnianymi przez poszczególne mikrousługi. W niektórych przypadkach aplikacja kliencka może wymagać wykonania wielu oddzielnych żądań utworzenia interfejsu użytkownika, co może być nieefektywne przez Internet i byłoby niepraktyczne za pośrednictwem sieci komórkowej. W związku z tym żądania z aplikacji klienckiej do systemu zaplecza powinny być zminimalizowane.
Innym problemem z bezpośrednią komunikacją między klientami i mikrousługami jest to, że niektóre mikrousługi mogą używać protokołów, które nie są przyjazne dla sieci Web. Jedna usługa może używać protokołu binarnego, podczas gdy inna usługa może używać komunikatów PROTOKOŁU AMQP. Te protokoły nie są przyjazne dla zapory i najlepiej są używane wewnętrznie. Zazwyczaj aplikacja powinna używać protokołów, takich jak HTTP i WebSocket do komunikacji poza zaporą.
Kolejną wadą tego bezpośredniego podejścia typu klient-usługa jest to, że trudno jest refaktoryzować kontrakty dla tych mikrousług. Z czasem deweloperzy mogą chcieć zmienić sposób partycjonowania systemu na usługi. Mogą na przykład scalić dwie usługi lub podzielić usługę na co najmniej dwie usługi. Jeśli jednak klienci komunikują się bezpośrednio z usługami, wykonanie tego rodzaju refaktoryzacji może przerwać zgodność z aplikacjami klienckimi.
Jak wspomniano w sekcji architektura, podczas projektowania i tworzenia złożonej aplikacji opartej na mikrousługach można rozważyć użycie wielu precyzyjnych bram interfejsu API zamiast prostszego podejścia bezpośredniego komunikacji między klientami i mikrousługami.
Partycjonowanie mikrousług. Na koniec niezależnie od tego, które podejście należy wziąć pod uwagę w przypadku architektury mikrousług, kolejnym wyzwaniem jest podjęcie decyzji o tym, jak podzielić kompleksową aplikację na wiele mikrousług. Jak wspomniano w sekcji dotyczącej architektury przewodnika, istnieje kilka technik i podejść, które można podjąć. Zasadniczo należy zidentyfikować obszary aplikacji, które są oddzielone od innych obszarów i które mają niewielką liczbę twardych zależności. W wielu przypadkach takie podejście jest dostosowane do usług partycjonowania według przypadku użycia. Na przykład w naszej aplikacji sklepu elektronicznego mamy usługę zamawiania, która jest odpowiedzialna za całą logikę biznesową związaną z procesem zamówienia. Mamy również usługę wykazu i usługę koszyka, która implementuje inne możliwości. Najlepiej, aby każda usługa miała tylko niewielki zestaw obowiązków. Takie podejście jest podobne do pojedynczej zasady odpowiedzialności (SRP) stosowanej do klas, które stwierdza, że klasa powinna mieć tylko jeden powód do zmiany. Jednak w tym przypadku chodzi o mikrousługi, więc zakres będzie większy niż jedna klasa. Przede wszystkim mikrousługa musi być autonomiczna, kończyć się również odpowiedzialnością za własne źródła danych.
Architektura zewnętrzna a wewnętrzna i wzorce projektowe
Architektura zewnętrzna to architektura mikrousług składająca się z wielu usług, zgodnie z zasadami opisanymi w sekcji architektury tego przewodnika. Jednak w zależności od charakteru każdej mikrousługi i niezależnie od wybranej architektury mikrousług wysokiego poziomu często zaleca się posiadanie różnych architektur wewnętrznych, z których każda opiera się na różnych wzorcach dla różnych mikrousług. Mikrousługi mogą nawet używać różnych technologii i języków programowania. Rysunek 6–2 ilustruje tę różnorodność.
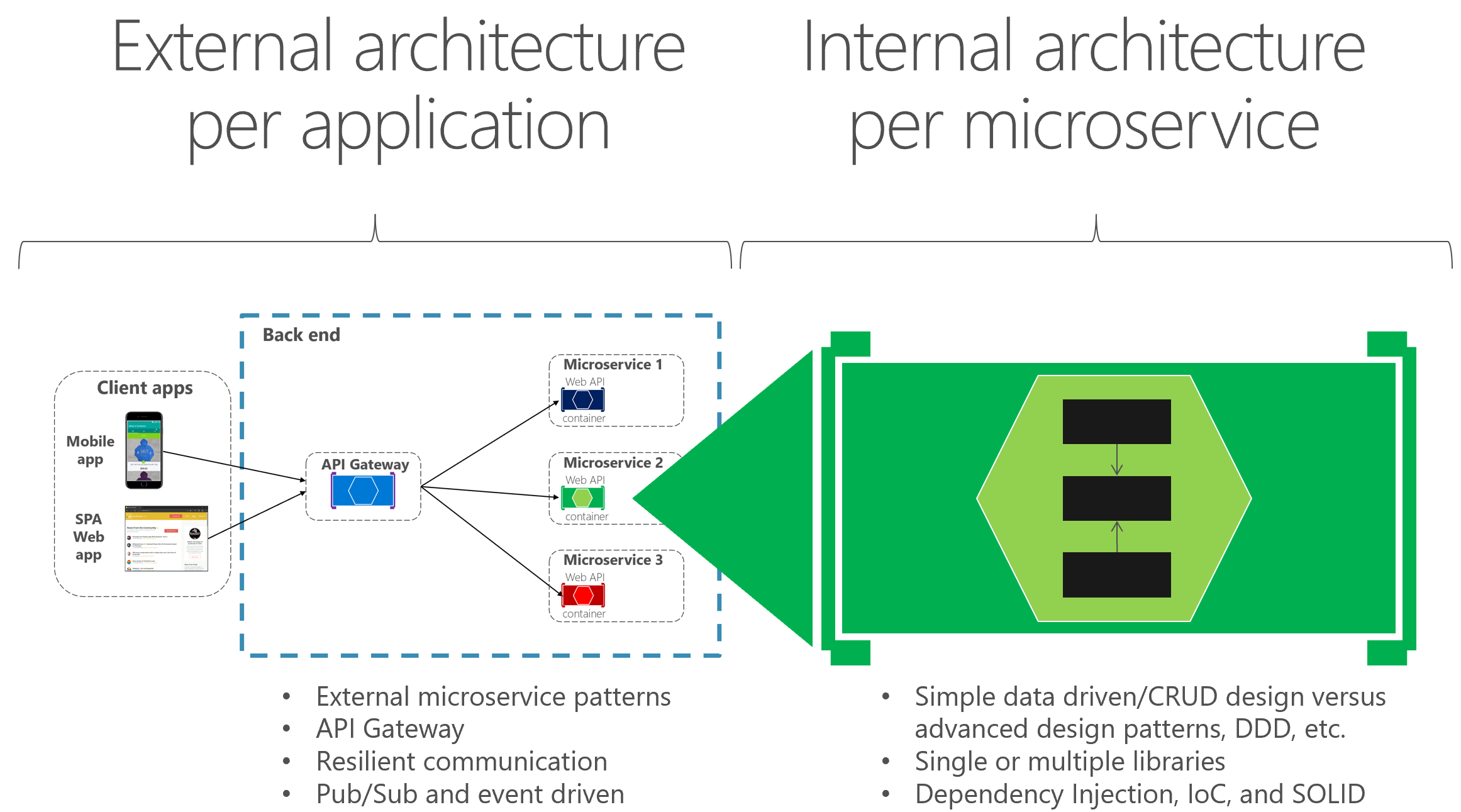
Rysunek 6–2. Architektura zewnętrzna a wewnętrzna i projekt
Na przykład w naszym przykładzie eShopOnContainers mikrousługi katalogu, koszyka i profilu użytkownika są proste (w zasadzie podsystemy CRUD). W związku z tym ich wewnętrzna architektura i projekt są proste. Jednak mogą istnieć inne mikrousługi, takie jak mikrousługa zamawiania, która jest bardziej złożona i reprezentuje stale zmieniające się reguły biznesowe o wysokim stopniu złożoności domeny. W takich przypadkach warto zaimplementować bardziej zaawansowane wzorce w ramach konkretnej mikrousługi, takich jak te zdefiniowane za pomocą metod projektowania opartego na domenie (DDD), jak robimy w eShopOnContainers zamawiania mikrousługi. (Omówimy te wzorce DDD w dalszej części sekcji, w których wyjaśniono implementację modułu eShopOnContainers zamawiania mikrousługi).
Innym powodem innej technologii na mikrousługę może być charakter każdej mikrousługi. Na przykład lepszym rozwiązaniem może być użycie funkcjonalnego języka programowania, takiego jak F#, a nawet języka, takiego jak R, jeśli jest przeznaczona dla domen sztucznej inteligencji i uczenia maszynowego, zamiast bardziej obiektowo zorientowanego języka programowania, takiego jak C#.
Najważniejsze jest to, że każda mikrousługa może mieć inną architekturę wewnętrzną na podstawie różnych wzorców projektowych. Nie wszystkie mikrousługi powinny być implementowane przy użyciu zaawansowanych wzorców DDD, ponieważ byłoby to nadmiernie inżynieryjne. Podobnie złożone mikrousługi ze stale zmieniającą się logiką biznesową nie powinny być implementowane jako składniki CRUD lub kod o niskiej jakości.
Nowy świat: wiele wzorców architektonicznych i mikrousług wielolotowych
Istnieje wiele wzorców architektury używanych przez architektów oprogramowania i deweloperów. Poniżej przedstawiono kilka (mieszanie stylów architektury i wzorców architektury):
Simple CRUD, jednowarstwowa, jednowarstwowa.
Czysta architektura (używana z eShopOnWeb)
Podział odpowiedzialności poleceń i zapytań (CQRS).
Architektura sterowana zdarzeniami (EDA).
Możesz również tworzyć mikrousługi z wieloma technologiami i językami, takimi jak ASP.NET Core Web API, NancyFx, ASP.NET Core SignalR (dostępne w środowisku .NET Core 2 lub nowszym), F#, Node.js, Python, Java, C++, GoLang i nie tylko.
Ważnym punktem jest to, że żaden konkretny wzorzec architektury ani styl, ani żadna konkretna technologia, nie jest odpowiedni dla wszystkich sytuacji. Rysunek 6–3 przedstawia niektóre podejścia i technologie (chociaż nie w żadnej określonej kolejności), które mogą być używane w różnych mikrousługach.
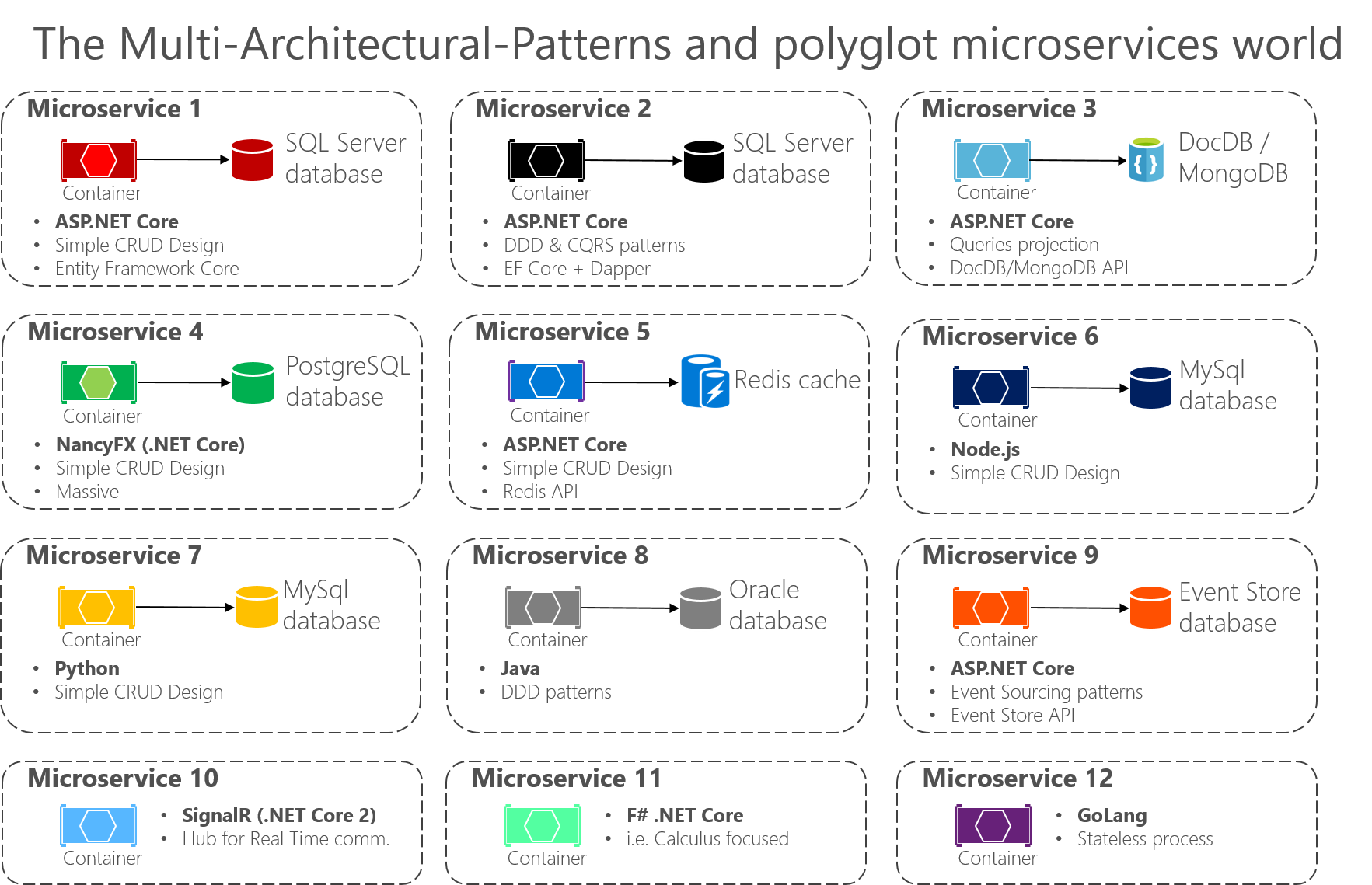
Rysunek 6–3. Wzorce wielowymiarowe i mikrousługi wielopłatowe
Wzorzec wielowymiarowy i mikrousługi wielolotowe oznaczają, że można łączyć i dopasowywać języki i technologie do potrzeb każdej mikrousługi i nadal mieć ze sobą rozmowy. Jak pokazano na rysunku 6–3, w aplikacjach składających się z wielu mikrousług (konteksty ograniczone w terminologii projektowej opartej na domenie lub po prostu "podsystemy" jako autonomiczne mikrousługi) można zaimplementować każdą mikrousługę w inny sposób. Każdy z nich może mieć inny wzorzec architektury i używać różnych języków i baz danych w zależności od charakteru aplikacji, wymagań biznesowych i priorytetów. W niektórych przypadkach mikrousługi mogą być podobne. Jednak zwykle nie jest tak, ponieważ granica kontekstu każdego podsystemu i wymagania są zwykle różne.
Na przykład w przypadku prostej aplikacji konserwacji CRUD warto zaprojektować i zaimplementować wzorce DDD. Jednak w przypadku podstawowej domeny lub podstawowej firmy może być konieczne zastosowanie bardziej zaawansowanych wzorców w celu rozwiązania problemów ze złożonością biznesową z ciągle zmieniającymi się regułami biznesowymi.
Szczególnie w przypadku obsługi dużych aplikacji składających się z wielu podsystemów nie należy stosować jednej architektury najwyższego poziomu na podstawie pojedynczego wzorca architektury. Na przykład usługa CQRS nie powinna być stosowana jako architektura najwyższego poziomu dla całej aplikacji, ale może być przydatna dla określonego zestawu usług.
Nie ma srebrnego punktora ani odpowiedniego wzorca architektury dla każdego przypadku. Nie można mieć "jednego wzorca architektury do reguł wszystkich". W zależności od priorytetów każdej mikrousługi należy wybrać inne podejście, jak wyjaśniono w poniższych sekcjach.