Tworzenie prostej mikrousługi CRUD na podstawie danych
Napiwek
Ta zawartość jest fragmentem książki eBook, architektury mikrousług platformy .NET dla konteneryzowanych aplikacji platformy .NET dostępnych na platformie .NET Docs lub jako bezpłatnego pliku PDF, który można odczytać w trybie offline.

W tej sekcji opisano sposób tworzenia prostej mikrousługi, która wykonuje operacje tworzenia, odczytu, aktualizowania i usuwania (CRUD) w źródle danych.
Projektowanie prostej mikrousługi CRUD
Z punktu widzenia projektu ten typ konteneryzowanej mikrousługi jest bardzo prosty. Być może problem do rozwiązania jest prosty, a może implementacja jest tylko weryfikacją koncepcji.
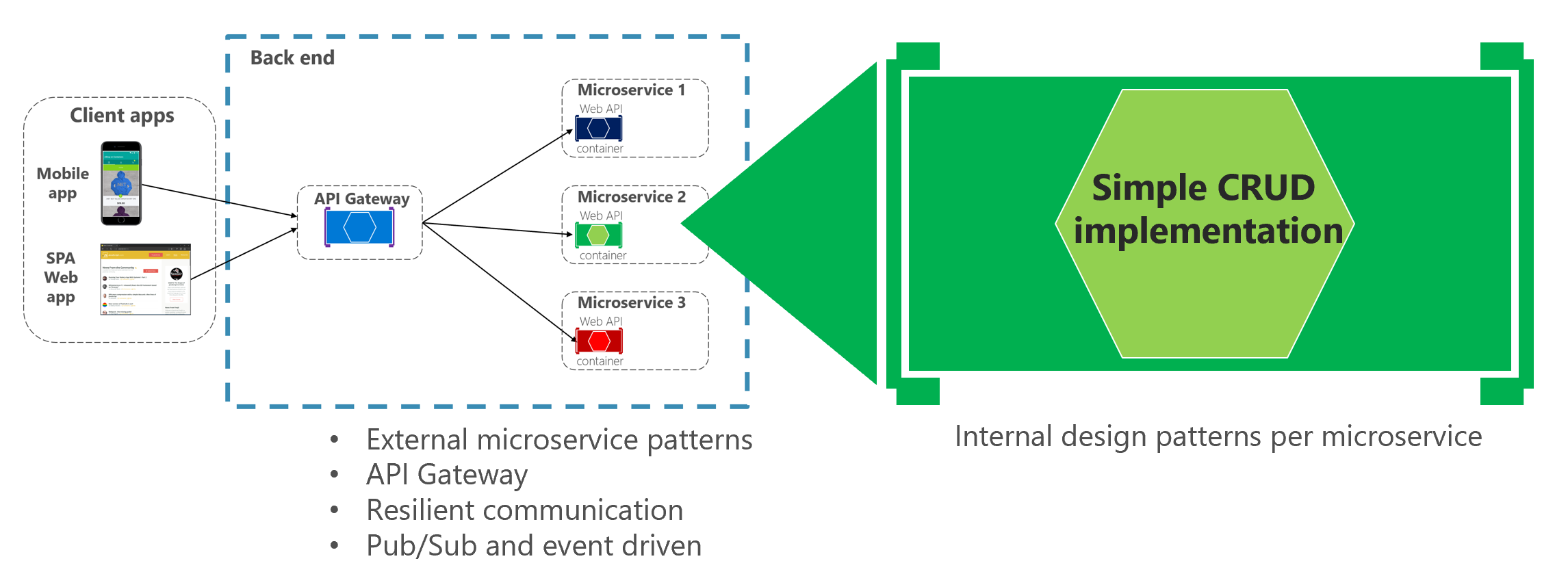
Rysunek 6–4. Wewnętrzny projekt prostych mikrousług CRUD
Przykładem tej prostej usługi dysku danych jest mikrousługa katalogu z przykładowej aplikacji eShopOnContainers. Ten typ usługi implementuje wszystkie jej funkcje w jednym projekcie interfejsu API sieci Web ASP.NET Core, który obejmuje klasy dla modelu danych, logikę biznesową i kod dostępu do danych. Przechowuje również powiązane dane w bazie danych uruchomionej w programie SQL Server (jako inny kontener na potrzeby tworzenia i testowania), ale może być również dowolnym zwykłym hostem programu SQL Server, jak pokazano na rysunku 6-5.
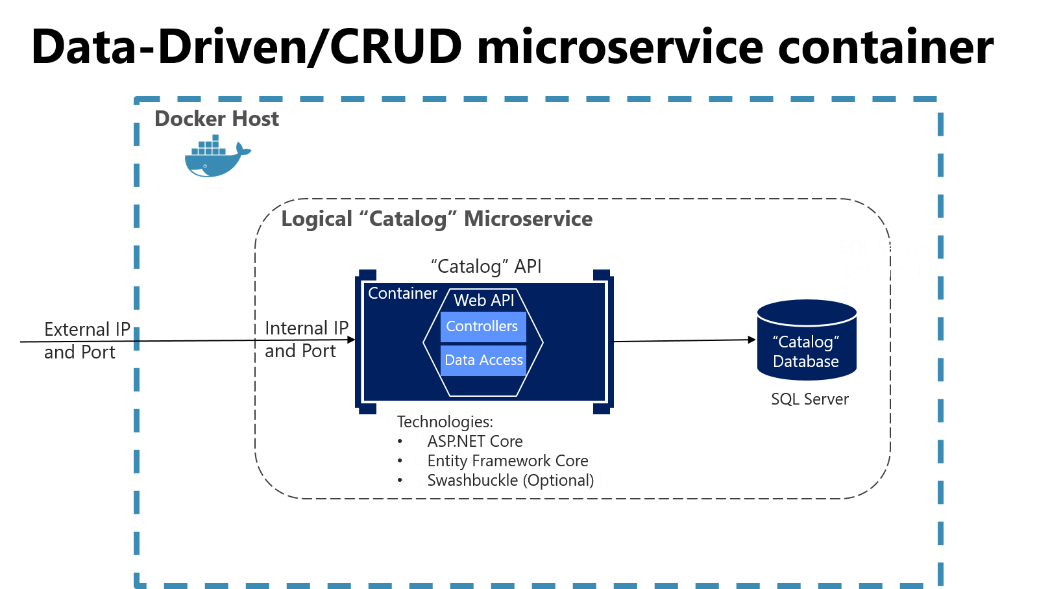
Rysunek 6–5. Prosty projekt mikrousługi opartej na danych/CRUD
Na poprzednim diagramie przedstawiono mikrousługę katalogu logicznego, która zawiera bazę danych wykazu, która może znajdować się na tym samym hoście platformy Docker. Posiadanie bazy danych na tym samym hoście platformy Docker może być dobre do programowania, ale nie w środowisku produkcyjnym. Podczas opracowywania tego rodzaju usługi potrzebujesz tylko ASP.NET Core i interfejsu API dostępu do danych lub ORM, takiego jak Entity Framework Core. Możesz również automatycznie wygenerować metadane struktury Swagger za pomocą pakietu Swashbuckle , aby podać opis ofert usług, jak wyjaśniono w następnej sekcji.
Należy pamiętać, że uruchamianie serwera bazy danych, takiego jak SQL Server w kontenerze platformy Docker, jest doskonałe dla środowisk programistycznych, ponieważ wszystkie zależności mogą być uruchomione bez konieczności aprowizowania bazy danych w chmurze lub lokalnie. Takie podejście jest wygodne podczas uruchamiania testów integracji. Jednak w przypadku środowisk produkcyjnych uruchomienie serwera bazy danych w kontenerze nie jest zalecane, ponieważ zwykle nie uzyskuje się wysokiej dostępności w tym podejściu. W przypadku środowiska produkcyjnego na platformie Azure zaleca się użycie usługi Azure SQL DB lub dowolnej innej technologii bazy danych, która może zapewnić wysoką dostępność i wysoką skalowalność. Na przykład w przypadku podejścia NoSQL możesz wybrać usługę CosmosDB.
Na koniec edytując plik Dockerfile i docker-compose.yml pliki metadanych, można skonfigurować sposób tworzenia obrazu tego kontenera — jaki obraz podstawowy będzie używany, oraz ustawienia projektu, takie jak nazwy wewnętrzne i zewnętrzne i porty TCP.
Implementowanie prostej mikrousługi CRUD przy użyciu platformy ASP.NET Core
Aby zaimplementować prostą mikrousługę CRUD przy użyciu platformy .NET i programu Visual Studio, zacznij od utworzenia prostego projektu internetowego interfejsu API platformy ASP.NET Core (uruchomionego na platformie .NET, aby można było go uruchomić na hoście platformy Docker systemu Linux), jak pokazano na rysunku 6–6.
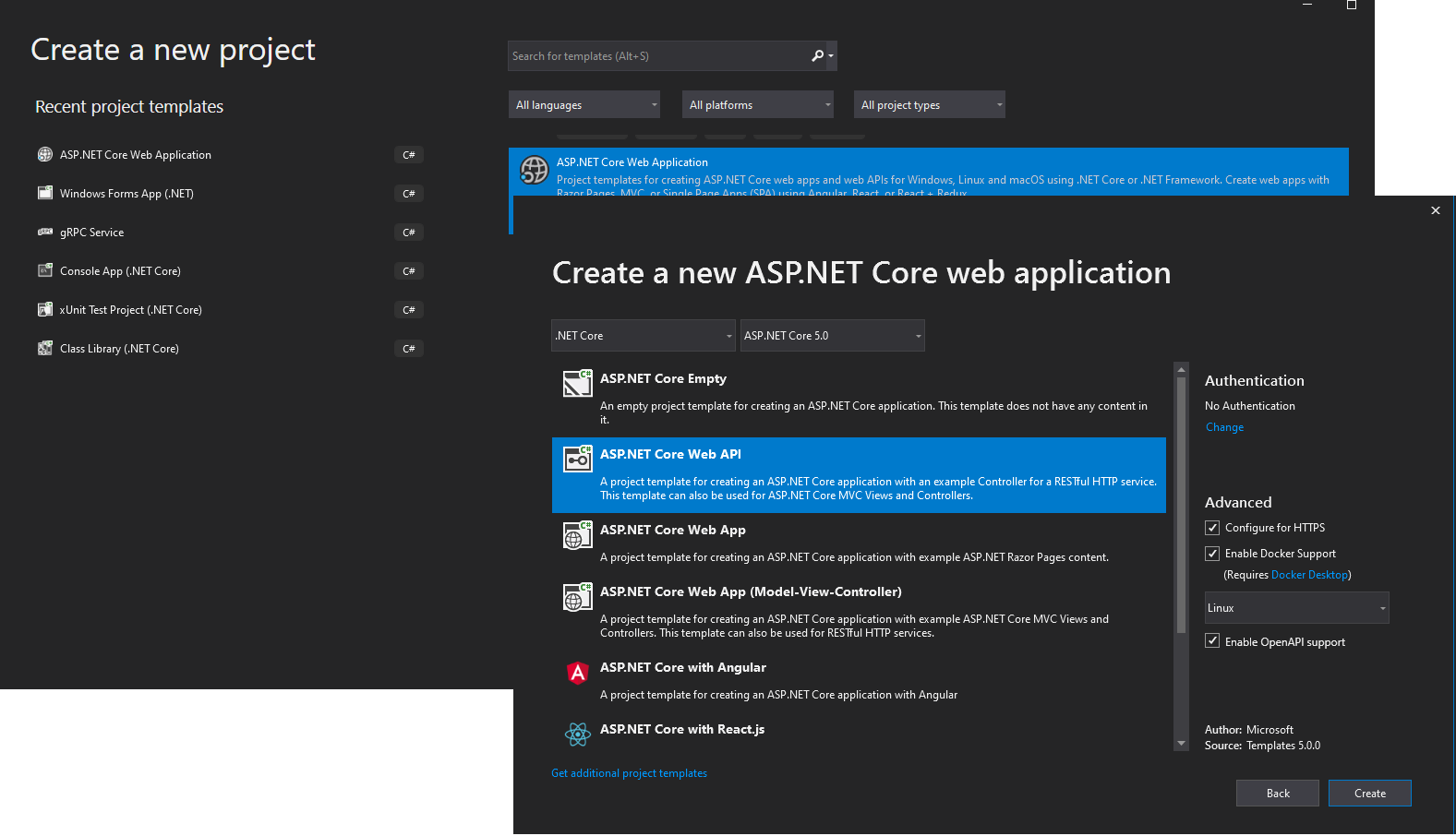
Rysunek 6–6. Tworzenie projektu internetowego interfejsu API platformy ASP.NET Core w programie Visual Studio 2019
Aby utworzyć ASP.NET Core Web API Project, najpierw wybierz ASP.NET Core Web Application, a następnie wybierz typ interfejsu API. Po utworzeniu projektu można zaimplementować kontrolery MVC, tak jak w innym projekcie internetowego interfejsu API, przy użyciu interfejsu API platformy Entity Framework lub innego interfejsu API. W nowym projekcie internetowego interfejsu API widać, że jedyną zależnością, która znajduje się w tej mikrousłudze, jest sama ASP.NET Core. Wewnętrznie w zależności Microsoft.AspNetCore.All odwołuje się ona do programu Entity Framework i wielu innych pakietów NuGet platformy .NET, jak pokazano na rysunku 6–7.
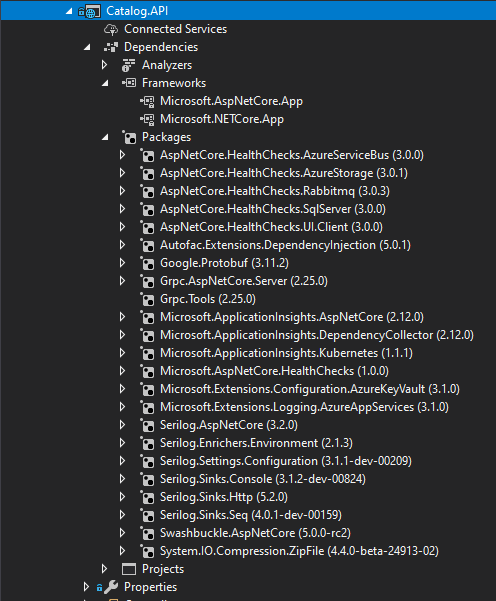
Rysunek 6–7. Zależności w prostej mikrousłudze interfejsu API sieci Web CRUD
Projekt interfejsu API zawiera odwołania do Microsoft.AspNetCore.App pakietu NuGet, który zawiera odwołania do wszystkich podstawowych pakietów. Może również zawierać kilka innych pakietów.
Implementowanie usług internetowego interfejsu API CRUD za pomocą platformy Entity Framework Core
Platforma Entity Framework (EF) Core to uproszczona, rozszerzalna i międzyplatformowa wersja popularnej technologii dostępu do danych programu Entity Framework. EF Core to maper obiektowo-relacyjny (ORM), który umożliwia deweloperom platformy .NET pracę z bazą danych przy użyciu obiektów platformy .NET.
Mikrousługa wykazu używa programu EF i dostawcy programu SQL Server, ponieważ jego baza danych jest uruchomiona w kontenerze z obrazem platformy Docker programu SQL Server dla systemu Linux. Bazę danych można jednak wdrożyć w dowolnym programie SQL Server, takim jak lokalny system Windows lub baza danych Azure SQL DB. Jedyną rzeczą, którą należy zmienić, jest parametry połączenia w mikrousłudze interfejsu API sieci Web ASP.NET.
Model danych
W przypadku platformy EF Core dostęp do danych jest wykonywany przy użyciu modelu. Model składa się z klas jednostek (modelu domeny) i kontekstu pochodnego (DbContext), który reprezentuje sesję z bazą danych, umożliwiając wykonywanie zapytań i zapisywanie danych. Model można wygenerować na podstawie istniejącej bazy danych, ręcznie zastosować kod modelu w celu dopasowania do bazy danych lub użyć techniki migracji ef do utworzenia bazy danych na podstawie modelu przy użyciu podejścia opartego na kodzie (które ułatwia rozwijanie bazy danych wraz ze zmianami modelu w miarę upływu czasu). W przypadku mikrousługi wykazu użyto ostatniego podejścia. Przykład klasy jednostki CatalogItem można zobaczyć w poniższym przykładzie kodu, który jest prostą klasą jednostki Plain Old Class Object (POCO).
public class CatalogItem
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal Price { get; set; }
public string PictureFileName { get; set; }
public string PictureUri { get; set; }
public int CatalogTypeId { get; set; }
public CatalogType CatalogType { get; set; }
public int CatalogBrandId { get; set; }
public CatalogBrand CatalogBrand { get; set; }
public int AvailableStock { get; set; }
public int RestockThreshold { get; set; }
public int MaxStockThreshold { get; set; }
public bool OnReorder { get; set; }
public CatalogItem() { }
// Additional code ...
}
Potrzebujesz również elementu DbContext reprezentującego sesję z bazą danych. W przypadku mikrousługi wykazu klasa CatalogContext pochodzi z klasy bazowej DbContext, jak pokazano w poniższym przykładzie:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{ }
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
// Additional code ...
}
Możesz mieć dodatkowe DbContext implementacje. Na przykład w przykładowej mikrousłudze Catalog.API jest druga DbContext nazwana CatalogContextSeed , w której automatycznie wypełnia przykładowe dane przy pierwszej próbie uzyskania dostępu do bazy danych. Ta metoda jest przydatna w przypadku danych demonstracyjnych i scenariuszy zautomatyzowanego testowania.
W programie DbContextużyjesz OnModelCreating metody , aby dostosować mapowania jednostek obiektów/bazy danych i inne punkty rozszerzalności ef.
Wykonywanie zapytań dotyczących danych z kontrolerów internetowego interfejsu API
Wystąpienia klas jednostek są zwykle pobierane z bazy danych przy użyciu zapytania zintegrowanego z językiem (LINQ), jak pokazano w poniższym przykładzie:
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
private readonly CatalogContext _catalogContext;
private readonly CatalogSettings _settings;
private readonly ICatalogIntegrationEventService _catalogIntegrationEventService;
public CatalogController(
CatalogContext context,
IOptionsSnapshot<CatalogSettings> settings,
ICatalogIntegrationEventService catalogIntegrationEventService)
{
_catalogContext = context ?? throw new ArgumentNullException(nameof(context));
_catalogIntegrationEventService = catalogIntegrationEventService
?? throw new ArgumentNullException(nameof(catalogIntegrationEventService));
_settings = settings.Value;
context.ChangeTracker.QueryTrackingBehavior = QueryTrackingBehavior.NoTracking;
}
// GET api/v1/[controller]/items[?pageSize=3&pageIndex=10]
[HttpGet]
[Route("items")]
[ProducesResponseType(typeof(PaginatedItemsViewModel<CatalogItem>), (int)HttpStatusCode.OK)]
[ProducesResponseType(typeof(IEnumerable<CatalogItem>), (int)HttpStatusCode.OK)]
[ProducesResponseType((int)HttpStatusCode.BadRequest)]
public async Task<IActionResult> ItemsAsync(
[FromQuery]int pageSize = 10,
[FromQuery]int pageIndex = 0,
string ids = null)
{
if (!string.IsNullOrEmpty(ids))
{
var items = await GetItemsByIdsAsync(ids);
if (!items.Any())
{
return BadRequest("ids value invalid. Must be comma-separated list of numbers");
}
return Ok(items);
}
var totalItems = await _catalogContext.CatalogItems
.LongCountAsync();
var itemsOnPage = await _catalogContext.CatalogItems
.OrderBy(c => c.Name)
.Skip(pageSize * pageIndex)
.Take(pageSize)
.ToListAsync();
itemsOnPage = ChangeUriPlaceholder(itemsOnPage);
var model = new PaginatedItemsViewModel<CatalogItem>(
pageIndex, pageSize, totalItems, itemsOnPage);
return Ok(model);
}
//...
}
Zapisywanie danych
Dane są tworzone, usuwane i modyfikowane w bazie danych przy użyciu wystąpień klas jednostek. Do kontrolerów internetowego interfejsu API można dodać kod podobny do poniższego przykładu zakodowanego na twardo (w tym przypadku pozorować dane).
var catalogItem = new CatalogItem() {CatalogTypeId=2, CatalogBrandId=2,
Name="Roslyn T-Shirt", Price = 12};
_context.Catalog.Add(catalogItem);
_context.SaveChanges();
Wstrzykiwanie zależności w kontrolerach ASP.NET Core i web API
W ASP.NET Core możesz użyć iniekcji zależności (DI) z pudełka. Nie trzeba konfigurować kontenera Inversion of Control (IoC) innej firmy, chociaż w razie potrzeby możesz podłączyć preferowany kontener IoC do infrastruktury ASP.NET Core. W takim przypadku oznacza to, że można bezpośrednio wstrzyknąć wymagane repozytoria EF DBContext lub dodatkowe repozytoria za pomocą konstruktora kontrolera.
We wspomnianej CatalogController wcześniej CatalogContext klasie (która dziedziczy z DbContext) typ jest wstrzykiwany wraz z innymi wymaganymi obiektami w konstruktorze CatalogController() .
Ważną konfiguracją do skonfigurowania w projekcie internetowego interfejsu API jest rejestracja klasy DbContext w kontenerze IoC usługi. Zazwyczaj w pliku Program.cs można to zrobić, wywołując metodę builder.Services.AddDbContext<CatalogContext>() , jak pokazano w poniższym uproszczonym przykładzie:
// Additional code...
builder.Services.AddDbContext<CatalogContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.MigrationsAssembly(
typeof(Program).GetTypeInfo().Assembly.GetName().Name);
//Configuring Connection Resiliency:
sqlOptions.
EnableRetryOnFailure(maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
});
// Changing default behavior when client evaluation occurs to throw.
// Default in EFCore would be to log warning when client evaluation is done.
options.ConfigureWarnings(warnings => warnings.Throw(
RelationalEventId.QueryClientEvaluationWarning));
});
Ważne
Firma Microsoft zaleca korzystanie z najbezpieczniejszego dostępnego przepływu uwierzytelniania. Jeśli łączysz się z usługą Azure SQL, tożsamości zarządzane dla zasobów platformy Azure to zalecana metoda uwierzytelniania.
Dodatkowe zasoby
Wykonanie zapytania o dane
https://learn.microsoft.com/ef/core/querying/indexZapisywanie danych
https://learn.microsoft.com/ef/core/saving/index
Zmienne środowiskowe i parametry połączenia db używane przez kontenery platformy Docker
Możesz użyć ustawień ASP.NET Core i dodać właściwość ConnectionString do pliku settings.json, jak pokazano w poniższym przykładzie:
{
"ConnectionString": "Server=tcp:127.0.0.1,5433;Initial Catalog=Microsoft.eShopOnContainers.Services.CatalogDb;User Id=sa;Password=[PLACEHOLDER]",
"ExternalCatalogBaseUrl": "http://host.docker.internal:5101",
"Logging": {
"IncludeScopes": false,
"LogLevel": {
"Default": "Debug",
"System": "Information",
"Microsoft": "Information"
}
}
}
Plik settings.json może mieć wartości domyślne właściwości ConnectionString lub dowolnej innej właściwości. Jednak te właściwości zostaną zastąpione przez wartości zmiennych środowiskowych określonych w pliku docker-compose.override.yml podczas korzystania z platformy Docker.
W plikach docker-compose.yml lub docker-compose.override.yml można zainicjować te zmienne środowiskowe, tak aby platforma Docker skonfigurowała je jako zmienne środowiskowe systemu operacyjnego, jak pokazano w poniższym pliku docker-compose.override.yml (parametry połączenia i innych wierszach zawijanych w tym przykładzie, ale nie będzie opakowować ich we własnym pliku).
# docker-compose.override.yml
#
catalog-api:
environment:
- ConnectionString=Server=sqldata;Database=Microsoft.eShopOnContainers.Services.CatalogDb;User Id=sa;Password=[PLACEHOLDER]
# Additional environment variables for this service
ports:
- "5101:80"
Ważne
Firma Microsoft zaleca korzystanie z najbezpieczniejszego dostępnego przepływu uwierzytelniania. Jeśli łączysz się z usługą Azure SQL, tożsamości zarządzane dla zasobów platformy Azure to zalecana metoda uwierzytelniania.
Pliki docker-compose.yml na poziomie rozwiązania są nie tylko bardziej elastyczne niż pliki konfiguracji na poziomie projektu lub mikrousługi, ale także bezpieczniejsze, jeśli zastąpisz zmienne środowiskowe zadeklarowane w plikach docker-compose z wartościami ustawionymi na podstawie narzędzi wdrażania, takich jak zadania wdrażania usługi Azure DevOps Services docker.
Na koniec możesz pobrać te wartości z kodu przy użyciu metody builder.Configuration["ConnectionString"], jak pokazano we wcześniejszym przykładzie kodu.
Jednak w środowiskach produkcyjnych warto zapoznać się z dodatkowymi sposobami przechowywania wpisów tajnych, takich jak parametry połączenia. Doskonałym sposobem zarządzania wpisami tajnymi aplikacji jest użycie usługi Azure Key Vault.
Usługa Azure Key Vault ułatwia przechowywanie i zabezpieczanie kluczy kryptograficznych i wpisów tajnych używanych przez aplikacje i usługi w chmurze. Wpis tajny to wszystko, co chcesz zachować ścisłą kontrolę, na przykład klucze interfejsu API, parametry połączenia, hasła itp., a ścisła kontrola obejmuje rejestrowanie użycia, ustawianie wygasania, zarządzanie dostępem, między innymi.
Usługa Azure Key Vault umożliwia szczegółowy poziom kontroli użycia wpisów tajnych aplikacji bez konieczności informowania nikogo o nich. Wpisy tajne można nawet obracać w celu zwiększenia bezpieczeństwa bez zakłócania programowania lub operacji.
Aplikacje muszą być zarejestrowane w usłudze Active Directory organizacji, aby mogły korzystać z usługi Key Vault.
Aby uzyskać więcej informacji, zapoznaj się z dokumentacją Pojęcia dotyczące usługi Key Vault.
Implementowanie przechowywania wersji w interfejsach API sieci Web ASP.NET
W miarę zmiany wymagań biznesowych mogą zostać dodane nowe kolekcje zasobów, relacje między zasobami mogą ulec zmianie, a struktura danych w zasobach może zostać zmieniona. Aktualizowanie internetowego interfejsu API w celu obsługi nowych wymagań jest stosunkowo prostym procesem, ale należy wziąć pod uwagę skutki, które takie zmiany będą miały na aplikacjach klienckich korzystających z internetowego interfejsu API. Mimo że deweloper projektujący i implementujący internetowy interfejs API ma pełną kontrolę nad tym interfejsem API, deweloper nie ma takiej samej kontroli nad aplikacjami klienckimi, które mogą być tworzone przez organizacje innych firm działające zdalnie.
Przechowywanie wersji umożliwia interfejsowi API sieci Web wskazanie funkcji i zasobów, które uwidacznia. Aplikacja kliencka może następnie przesyłać żądania do określonej wersji funkcji lub zasobu. Istnieje kilka podejść do implementowania przechowywania wersji:
- Obsługa wersji za pomocą identyfikatora URI
- Obsługa wersji za pomocą ciągu zapytania
- Obsługa wersji za pomocą nagłówka
Przechowywanie wersji ciągu zapytania i identyfikatora URI jest najprostsze do zaimplementowania. Przechowywanie wersji nagłówka jest dobrym rozwiązaniem. Przechowywanie wersji nagłówka nie jest jednak tak jawne i proste, jak przechowywanie wersji identyfikatora URI. Ponieważ przechowywanie wersji adresu URL jest najprostsze i najbardziej jawne, przykładowa aplikacja eShopOnContainers używa obsługi wersji identyfikatora URI.
W przypadku przechowywania wersji identyfikatora URI, podobnie jak w przykładowej aplikacji eShopOnContainers, za każdym razem, gdy modyfikujesz internetowy interfejs API lub zmieniasz schemat zasobów, dodajesz numer wersji do identyfikatora URI dla każdego zasobu. Istniejące identyfikatory URI powinny nadal działać tak jak wcześniej, zwracając zasoby zgodne ze schematem zgodnym z żądaną wersją.
Jak pokazano w poniższym przykładzie kodu, wersję można ustawić przy użyciu atrybutu Route w kontrolerze internetowego interfejsu API, co powoduje, że wersja jest jawna w identyfikatorze URI (wersja 1 w tym przypadku).
[Route("api/v1/[controller]")]
public class CatalogController : ControllerBase
{
// Implementation ...
Ten mechanizm przechowywania wersji jest prosty i zależy od serwera routingu żądania do odpowiedniego punktu końcowego. Jednak w przypadku bardziej zaawansowanego przechowywania wersji i najlepszej metody podczas korzystania z architektury REST należy użyć hipermedia i zaimplementować funkcję HATEOAS (hipertekst jako aparat stanu aplikacji).
Dodatkowe zasoby
Przechowywanie wersji interfejsu API ASP.NET \ https://github.com/dotnet/aspnet-api-versioning
Scott Hanselman. ASP.NET Core INTERFEJS API sieci Web RESTful jest łatwy w obsłudze
https://www.hanselman.com/blog/ASPNETCoreRESTfulWebAPIVersioningMadeEasy.aspxPrzechowywanie wersji internetowego interfejsu API RESTful
https://learn.microsoft.com/azure/architecture/best-practices/api-design#versioning-a-restful-web-apiRoy Fielding. Przechowywanie wersji, hipermedia i REST
https://www.infoq.com/articles/roy-fielding-on-versioning
Generowanie metadanych opisu struktury Swagger na podstawie internetowego interfejsu API platformy ASP.NET Core
Swagger to powszechnie używana platforma typu open source wspierana przez duży ekosystem narzędzi, które ułatwiają projektowanie, kompilowanie, dokumentowanie i korzystanie z interfejsów API RESTful. Staje się to standardem dla domeny metadanych opisu interfejsów API. Należy uwzględnić metadane opisu struktury Swagger z dowolną mikrousługą opartą na danych lub bardziej zaawansowanymi mikrousługami opartymi na domenie (zgodnie z opisem w poniższej sekcji).
Sercem struktury Swagger jest specyfikacja struktury Swagger, która to metadane opisu interfejsu API w pliku JSON lub YAML. Specyfikacja tworzy kontrakt RESTful dla interfejsu API, szczegółowo opisując wszystkie jego zasoby i operacje zarówno w formacie czytelnym dla człowieka, jak i maszynowym w celu łatwego programowania, odnajdywania i integracji.
Specyfikacja jest podstawą specyfikacji OpenAPI (OAS) i jest opracowywana w otwartej, przezroczystej i współpracy społeczności w celu standaryzacji sposobu definiowania interfejsów RESTful.
Specyfikacja definiuje strukturę sposobu odnajdowania usługi i sposobu zrozumienia jej możliwości. Aby uzyskać więcej informacji, w tym edytora internetowego i przykłady specyfikacji struktury Swagger od firm takich jak Spotify, Uber, Slack i Microsoft, zobacz witrynę Swagger (https://swagger.io).
Dlaczego warto używać struktury Swagger?
Główne przyczyny generowania metadanych struktury Swagger dla interfejsów API są następujące.
Możliwość automatycznego korzystania z innych produktów i integrowania interfejsów API. Dziesiątki produktów i narzędzi komercyjnych oraz wiele bibliotek i struktur obsługuje strukturę Swagger. Firma Microsoft ma produkty i narzędzia wysokiego poziomu, które mogą automatycznie korzystać z interfejsów API opartych na strukturze Swagger, takich jak następujące:
AutoRest. Możesz automatycznie generować klasy klientów platformy .NET do wywoływania programu Swagger. Tego narzędzia można używać z poziomu interfejsu wiersza polecenia, a także integruje się z programem Visual Studio w celu łatwego użycia za pośrednictwem graficznego interfejsu użytkownika.
Usługa Microsoft Flow. Możesz automatycznie używać interfejsu API i integrować go z ogólnym przepływem pracy usługi Microsoft Flow bez wymaganych umiejętności programistycznych.
Microsoft PowerApps. Możesz automatycznie korzystać z interfejsu API z poziomu aplikacji mobilnych usługi PowerApps utworzonych za pomocą programu PowerApps Studio bez wymaganych umiejętności programistycznych.
aplikacja systemu Azure Service Logic Apps. Możesz automatycznie używać interfejsu API i integrować go z aplikacją logiki usługi aplikacja systemu Azure bez wymaganych umiejętności programistycznych.
Możliwość automatycznego generowania dokumentacji interfejsu API. Podczas tworzenia dużych interfejsów API RESTful, takich jak złożone aplikacje oparte na mikrousługach, należy obsługiwać wiele punktów końcowych z różnymi modelami danych używanymi w ładunkach żądania i odpowiedzi. Posiadanie odpowiedniej dokumentacji i posiadanie solidnego eksploratora interfejsu API, jak można uzyskać z programu Swagger, jest kluczem do sukcesu interfejsu API i wdrożenia przez deweloperów.
Metadane programu Swagger są używane przez usługi Microsoft Flow, PowerApps i Azure Logic Apps, aby zrozumieć, jak używać interfejsów API i łączyć się z nimi.
Istnieje kilka opcji automatyzowania generowania metadanych struktury Swagger dla aplikacji interfejsu API REST platformy ASP.NET Core w postaci funkcjonalnych stron pomocy interfejsu API na podstawie struktury Swagger-ui.
Prawdopodobnie najlepszą wiedzą jest swashbuckle, który jest obecnie używany w eShopOnContainers i omówimy szczegółowo w tym przewodniku, ale istnieje również opcja używania NSwag, który może generować klientów interfejsu API Typescript i C#, a także kontrolerów języka C#, ze specyfikacji Swagger lub OpenAPI, a nawet przez skanowanie .dll, które zawiera kontrolery, przy użyciu aplikacji NSwagStudio.
Jak zautomatyzować generowanie metadanych struktury Swagger interfejsu API za pomocą pakietu NuGet swashbuckle
Ręczne generowanie metadanych struktury Swagger (w pliku JSON lub YAML) może być żmudne. Można jednak zautomatyzować odnajdywanie interfejsu API ASP.NET internetowych usług interfejsu API przy użyciu pakietu NuGet swashbuckle w celu dynamicznego generowania metadanych interfejsu API programu Swagger.
Pakiet Swashbuckle automatycznie generuje metadane struktury Swagger dla projektów internetowego interfejsu API ASP.NET. Obsługuje on projekty internetowego interfejsu API platformy ASP.NET Core oraz tradycyjny internetowy interfejs API ASP.NET oraz dowolny inny smak, taki jak aplikacja interfejsu API platformy Azure, aplikacja mobilna platformy Azure, mikrousługi usługi Azure Service Fabric oparte na ASP.NET. Obsługuje również zwykły internetowy interfejs API wdrożony w kontenerach, podobnie jak w przypadku aplikacji referencyjnej.
Pakiet Swashbuckle łączy narzędzia API Explorer i Swagger lub swagger-ui , aby zapewnić zaawansowane środowisko odnajdywania i dokumentacji dla użytkowników interfejsu API. Oprócz aparatu generatora metadanych struktury Swagger pakiet Swashbuckle zawiera również osadzoną wersję struktury Swagger-ui, która automatycznie będzie obsługiwać po zainstalowaniu pakietu Swashbuckle.
Oznacza to, że możesz uzupełnić interfejs API miłym interfejsem użytkownika odnajdywania, aby ułatwić deweloperom korzystanie z interfejsu API. Wymaga ona niewielkiej ilości kodu i konserwacji, ponieważ jest ona generowana automatycznie, co pozwala skupić się na tworzeniu interfejsu API. Wynik eksploratora interfejsu API wygląda następująco: Rysunek 6–8.
Rysunek 6–8. Eksplorator interfejsu API programu Swashbuckle oparty na metadanych struktury Swagger — mikrousług katalogu eShopOnContainers
Dokumentacja interfejsu API programu Swashbuckle wygenerowana przez pakiet Swashbuckle zawiera wszystkie opublikowane akcje. Eksplorator interfejsu API nie jest tutaj najważniejszą rzeczą. Po utworzeniu internetowego interfejsu API, który może opisać się w metadanych struktury Swagger, interfejs API można bezproblemowo używać z narzędzi opartych na strukturze Swagger, w tym generatorów kodu klasy serwera proxy klienta, które mogą być przeznaczone dla wielu platform. Na przykład, jak wspomniano, funkcja AutoRest automatycznie generuje klasy klientów platformy .NET. Dostępne są również dodatkowe narzędzia, takie jak swagger-codegen , które umożliwiają automatyczne generowanie kodu bibliotek klienckich interfejsu API, wycinków serwera i dokumentacji.
Obecnie pakiet Swashbuckle składa się z pięciu wewnętrznych pakietów NuGet w ramach metapakietów wysokiego poziomu swashbuckle.AspNetCore dla aplikacji ASP.NET Core.
Po zainstalowaniu tych pakietów NuGet w projekcie internetowego interfejsu API należy skonfigurować program Swagger w klasie Program.cs , jak w poniższym uproszczonym kodzie:
// Add framework services.
builder.Services.AddSwaggerGen(options =>
{
options.DescribeAllEnumsAsStrings();
options.SwaggerDoc("v1", new OpenApiInfo
{
Title = "eShopOnContainers - Catalog HTTP API",
Version = "v1",
Description = "The Catalog Microservice HTTP API. This is a Data-Driven/CRUD microservice sample"
});
});
// Other startup code...
app.UseSwagger();
if (app.Environment.IsDevelopment())
{
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("/swagger/v1/swagger.json", "My API V1");
});
}
Po wykonaniu tej czynności możesz uruchomić aplikację i przeglądać następujące punkty końcowe programu Swagger JSON i UI przy użyciu adresów URL, takich jak:
http://<your-root-url>/swagger/v1/swagger.json
http://<your-root-url>/swagger/
Wcześniej wygenerowany interfejs użytkownika utworzony przez pakiet Swashbuckle dla adresu URL, taki jak http://<your-root-url>/swagger. Na rysunku 6–9 można również zobaczyć, jak można przetestować dowolną metodę interfejsu API.
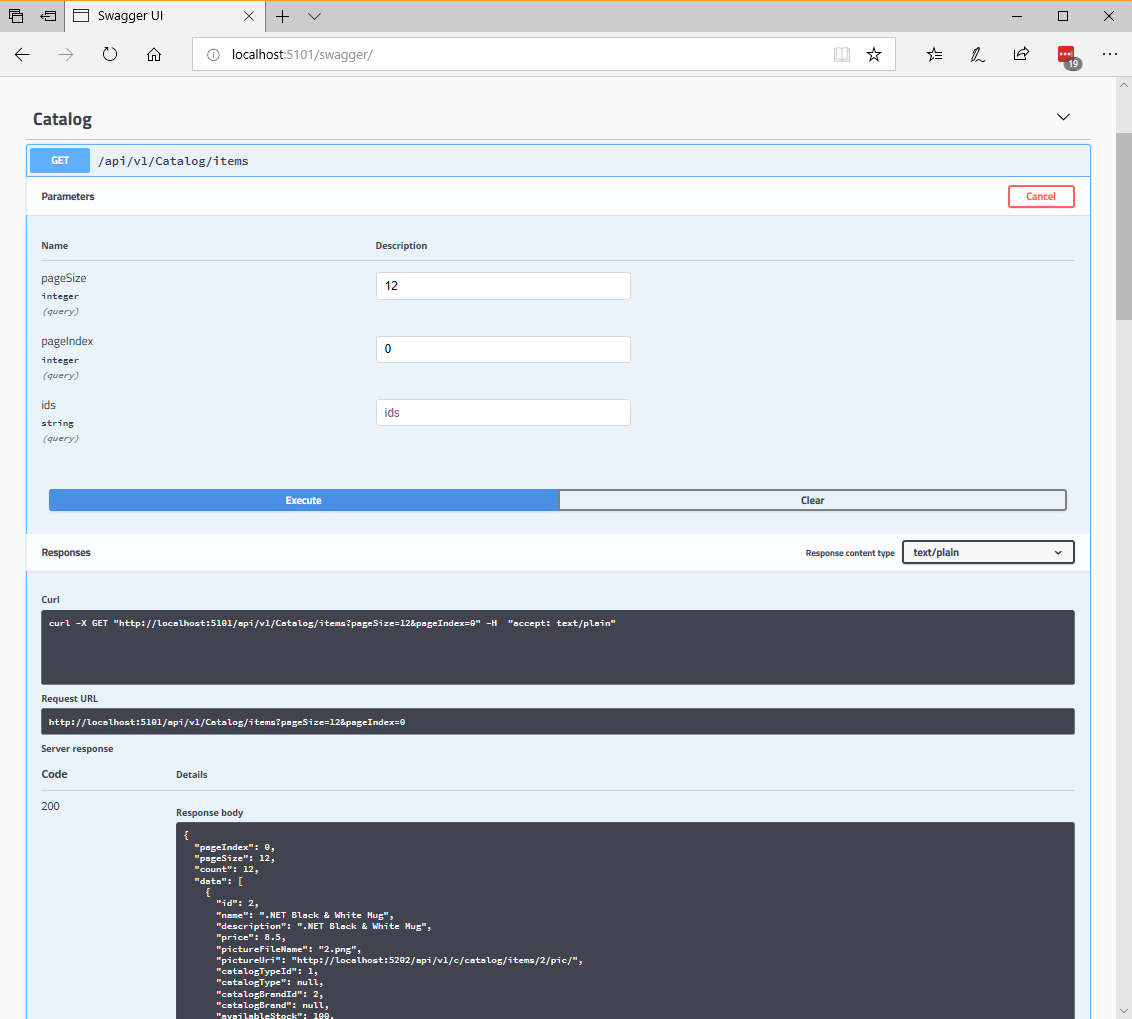
Rysunek 6–9. Narzędzie Swashbuckle UI testujące metodę interfejsu API katalogu/elementów
Szczegóły interfejsu API interfejsu użytkownika struktury Swagger pokazują przykładową odpowiedź i mogą służyć do wykonywania rzeczywistego interfejsu API, który doskonale nadaje się do odnajdywania deweloperów. Aby wyświetlić metadane JSON struktury Swagger wygenerowane na podstawie mikrousługi eShopOnContainers (która jest używana przez narzędzia poniżej), utwórz żądanie http://<your-root-url>/swagger/v1/swagger.json przy użyciu rozszerzenia klienta REST programu Visual Studio Code.
Dodatkowe zasoby
ASP.NET stron pomocy internetowego interfejsu API przy użyciu programu Swagger
https://learn.microsoft.com/aspnet/core/tutorials/web-api-help-pages-using-swaggerWprowadzenie do pakietu Swashbuckle i platformy ASP.NET Core
https://learn.microsoft.com/aspnet/core/tutorials/getting-started-with-swashbuckleWprowadzenie do sieciowych grup zabezpieczeń i platformy ASP.NET Core
https://learn.microsoft.com/aspnet/core/tutorials/getting-started-with-nswag