Problemy i rozwiązania dotyczące rozproszonego zarządzania danymi
Napiwek
Ta zawartość jest fragmentem książki eBook, architektury mikrousług platformy .NET dla konteneryzowanych aplikacji platformy .NET dostępnych na platformie .NET Docs lub jako bezpłatnego pliku PDF, który można odczytać w trybie offline.

Wyzwanie nr 1: Jak zdefiniować granice każdej mikrousługi
Definiowanie granic mikrousług jest prawdopodobnie pierwszym wyzwaniem, które napotyka każda osoba. Każda mikrousługa musi być elementem aplikacji, a każda mikrousługa powinna być autonomiczna ze wszystkimi korzyściami i wyzwaniami, które przekazuje. Jak jednak zidentyfikować te granice?
Najpierw należy skoncentrować się na modelach domeny logicznej aplikacji i powiązanych danych. Spróbuj zidentyfikować oddzielone wyspy danych i różne konteksty w tej samej aplikacji. Każdy kontekst może mieć inny język biznesowy (różne terminy biznesowe). Konteksty powinny być definiowane i zarządzane niezależnie. Terminy i jednostki, które są używane w tych różnych kontekstach, mogą wydawać się podobne, ale może się okazać, że w określonym kontekście pojęcie biznesowe z jednym jest używane do innego celu w innym kontekście, a nawet może mieć inną nazwę. Na przykład użytkownik może być określany jako użytkownik w kontekście tożsamości lub członkostwa, jako klient w kontekście CRM, jako nabywca w kontekście zamówienia itd.
Sposób identyfikowania granic między wieloma kontekstami aplikacji z inną domeną dla każdego kontekstu jest dokładnie taki, jak można zidentyfikować granice dla każdej mikrousługi biznesowej i powiązanego z nią modelu domeny i danych. Zawsze próbujesz zminimalizować sprzężenie między tymi mikrousługami. Ten przewodnik zawiera bardziej szczegółowe informacje na temat tego projektu identyfikacji i modelu domeny w sekcji Identyfikowanie granic modelu domeny dla każdej mikrousługi później.
Wyzwanie nr 2: Jak tworzyć zapytania pobierające dane z kilku mikrousług
Drugim wyzwaniem jest zaimplementowanie zapytań, które pobierają dane z kilku mikrousług, jednocześnie unikając czatty komunikacji z mikrousługami ze zdalnych aplikacji klienckich. Przykładem może być pojedynczy ekran z aplikacji mobilnej, która musi wyświetlać informacje o użytkowniku należące do koszyka, katalogu i mikrousług tożsamości użytkowników. Innym przykładem może być złożony raport obejmujący wiele tabel znajdujących się w wielu mikrousługach. Właściwe rozwiązanie zależy od złożoności zapytań. Jednak w każdym razie potrzebny jest sposób agregowania informacji, jeśli chcesz zwiększyć wydajność komunikacji systemu. Najbardziej popularne rozwiązania są następujące.
Brama interfejsu API. W przypadku prostej agregacji danych z wielu mikrousług, które są właścicielami różnych baz danych, zalecaną metodą jest mikrousługa agregacji nazywana bramą interfejsu API. Należy jednak zachować ostrożność podczas implementowania tego wzorca, ponieważ może to być punkt dławiący w systemie i może naruszać zasadę autonomii mikrousług. Aby temu zapobiec, możesz mieć wiele precyzyjnych bram interfejsów API, z których każda koncentruje się na pionowym "wycinku" lub obszarze biznesowym systemu. Wzorzec bramy interfejsu API jest bardziej szczegółowo opisany w sekcji Brama interfejsu API w dalszej części.
Program GraphQL Federation One może rozważyć, czy mikrousługi korzystają już z programu GraphQL to Federacja GraphQL. Federacja umożliwia zdefiniowanie "podgrafów" z innych usług i utworzenie ich w agregacji "supergraf", który działa jako autonomiczny schemat.
CQRS z tabelami zapytań/odczytów. Innym rozwiązaniem do agregowania danych z wielu mikrousług jest wzorzec zmaterializowanego widoku. W tym podejściu generujesz z wyprzedzeniem (przygotuj zdenormalizowane dane przed rzeczywistymi zapytaniami), tabelę tylko do odczytu z danymi należącymi do wielu mikrousług. Tabela ma format dostosowany do potrzeb aplikacji klienckiej.
Rozważ coś takiego jak ekran aplikacji mobilnej. Jeśli masz pojedynczą bazę danych, możesz zebrać dane dla tego ekranu przy użyciu zapytania SQL, które wykonuje złożone sprzężenia obejmujące wiele tabel. Jeśli jednak masz wiele baz danych, a każda baza danych jest własnością innej mikrousługi, nie można wykonać zapytań dotyczących tych baz danych i utworzyć sprzężenia SQL. Złożone zapytanie staje się wyzwaniem. Możesz rozwiązać wymaganie przy użyciu podejścia CQRS — tworzysz tabelę zdenormalizowaną w innej bazie danych, która jest używana tylko w przypadku zapytań. Tabelę można zaprojektować specjalnie dla danych potrzebnych dla złożonego zapytania z relacją jeden do jednego między polami wymaganymi przez ekran aplikacji i kolumnami w tabeli zapytań. Może również służyć do celów raportowania.
Takie podejście nie tylko rozwiązuje oryginalny problem (sposób wykonywania zapytań i łączenia między mikrousługami), ale również znacznie poprawia wydajność w porównaniu ze złożonym sprzężeniami, ponieważ masz już dane potrzebne przez aplikację w tabeli zapytań. Oczywiście użycie podziału odpowiedzialności poleceń i zapytań (CQRS) z tabelami zapytań/odczytów oznacza dodatkową pracę programistyjną i konieczne będzie przyjęcie spójności ostatecznej. Niemniej jednak wymagania dotyczące wydajności i wysokiej skalowalności w scenariuszach współpracy (lub scenariuszach konkurencyjnych , w zależności od punktu widzenia) są miejscem, w którym należy zastosować usługę CQRS z wieloma bazami danych.
"Zimne dane" w centralnych bazach danych. W przypadku złożonych raportów i zapytań, które mogą nie wymagać danych w czasie rzeczywistym, typowym podejściem jest wyeksportowanie "gorących danych" (danych transakcyjnych z mikrousług) jako "zimnych danych" do dużych baz danych, które są używane tylko do raportowania. Ten centralny system baz danych może być systemem opartym na danych big data, takim jak Hadoop; magazyn danych, taki jak jeden oparty na usłudze Azure SQL Data Warehouse; a nawet pojedyncza baza danych SQL, która jest używana tylko w przypadku raportów (jeśli rozmiar nie będzie problemem).
Należy pamiętać, że ta scentralizowana baza danych będzie używana tylko w przypadku zapytań i raportów, które nie potrzebują danych w czasie rzeczywistym. Oryginalne aktualizacje i transakcje, jako źródło prawdy, muszą znajdować się w danych mikrousług. Sposób synchronizowania danych odbywa się za pomocą komunikacji sterowanej zdarzeniami (opisanej w następnych sekcjach) lub innych narzędzi importu/eksportowania infrastruktury bazy danych. Jeśli używasz komunikacji opartej na zdarzeniach, proces integracji będzie podobny do sposobu propagacji danych zgodnie z wcześniejszym opisem w przypadku tabel zapytań CQRS.
Jeśli jednak projekt aplikacji obejmuje ciągłe agregowanie informacji z wielu mikrousług w przypadku złożonych zapytań, może to być objaw złego projektu — mikrousługi powinny być tak odizolowane, jak to możliwe od innych mikrousług. (Wyklucza to raporty/analizy, które zawsze powinny używać centralnych baz danych zimnych danych). Często może to być przyczyną scalania mikrousług. Musisz zrównoważyć autonomię ewolucji i wdrażania każdej mikrousługi z silnymi zależnościami, spójnością i agregacją danych.
Wyzwanie nr 3: Jak osiągnąć spójność w wielu mikrousługach
Jak wspomniano wcześniej, dane należące do każdej mikrousługi są prywatne dla tej mikrousługi i mogą być dostępne tylko przy użyciu interfejsu API mikrousług. W związku z tym przedstawione wyzwanie polega na tym, jak zaimplementować kompleksowe procesy biznesowe przy zachowaniu spójności w wielu mikrousługach.
Aby przeanalizować ten problem, przyjrzyjmy się przykładowi aplikacji referencyjnej eShopOnContainers. Mikrousługa Wykazu przechowuje informacje o wszystkich produktach, w tym o cenie produktu. Mikrousługa Koszyk zarządza danymi czasowymi dotyczącymi produktów dodawanych przez użytkowników do koszyków zakupów, które obejmują cenę przedmiotów w momencie dodania ich do koszyka. Gdy cena produktu zostanie zaktualizowana w wykazie, ta cena powinna być również zaktualizowana w aktywnych koszykach, które przechowują ten sam produkt, a system powinien prawdopodobnie ostrzec użytkownika, że cena określonego elementu uległa zmianie od czasu dodania go do koszyka.
W hipotetycznej monolitycznej wersji tej aplikacji, gdy cena zmienia się w tabeli products, podsystem wykazu może po prostu użyć transakcji ACID do zaktualizowania bieżącej ceny w tabeli Koszyk.
Jednak w aplikacji opartej na mikrousług tabele Product i Basket należą do odpowiednich mikrousług. Żadna mikrousługa nigdy nie powinna zawierać tabel/magazynu należących do innej mikrousługi we własnych transakcjach, nawet w zapytaniach bezpośrednich, jak pokazano na rysunku 4–9.
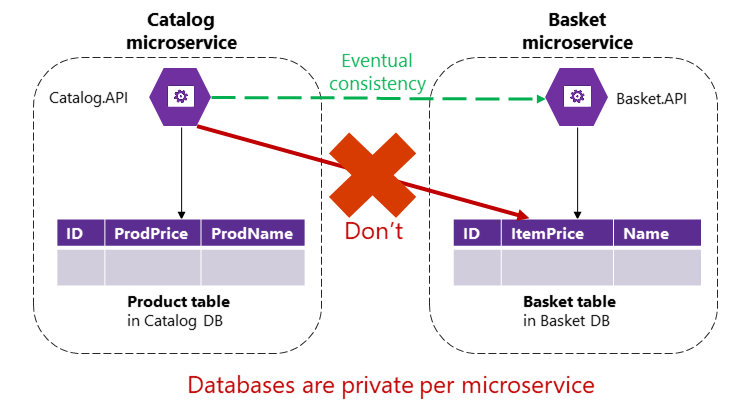
Rysunek 4–9. Mikrousługa nie może bezpośrednio uzyskać dostępu do tabeli w innej mikrousłudze
Mikrousługa wykazu nie powinna aktualizować tabeli Koszyk bezpośrednio, ponieważ tabela Koszyk jest własnością mikrousługi Koszyk. Aby zaktualizować mikrousługę koszyka, mikrousługa wykazu powinna używać spójności ostatecznej prawdopodobnie na podstawie komunikacji asynchronicznej, takiej jak zdarzenia integracji (komunikat i komunikacja oparta na zdarzeniach). W ten sposób aplikacja referencyjna eShopOnContainers wykonuje ten typ spójności między mikrousługami.
Zgodnie z twierdzeniem CAP należy wybrać między dostępnością a silną spójnością ACID. Większość scenariuszy opartych na mikrousługach wymaga dostępności i wysokiej skalowalności, w przeciwieństwie do silnej spójności. Aplikacje o krytycznym znaczeniu muszą pozostać uruchomione, a deweloperzy mogą pracować nad silną spójnością przy użyciu technik pracy ze słabą lub ostateczną spójnością. Jest to podejście podejmowane przez większość architektur opartych na mikrousługach.
Ponadto transakcje zatwierdzania dwufazowego lub dwufazowego nie są tylko sprzeczne z zasadami mikrousług; Większość baz danych NoSQL (takich jak Azure Cosmos DB, MongoDB itp.) nie obsługuje transakcji zatwierdzania dwufazowego, typowych w scenariuszach rozproszonych baz danych. Jednak utrzymanie spójności danych między usługami i bazami danych jest niezbędne. To wyzwanie jest również związane z pytaniem, jak propagować zmiany w wielu mikrousługach, gdy niektóre dane muszą być nadmiarowe — na przykład gdy musisz mieć nazwę lub opis produktu w mikrousłudze Katalogu i mikrousługę Koszyk.
Dobrym rozwiązaniem dla tego problemu jest użycie spójności ostatecznej między mikrousługami przegubskrywowanym za pośrednictwem komunikacji sterowanej zdarzeniami i systemem publikowania i subskrybowania. Te tematy zostały omówione w sekcji Asynchroniczna komunikacja sterowana zdarzeniami w dalszej części tego przewodnika.
Wyzwanie nr 4: Jak zaprojektować komunikację między granicami mikrousług
Komunikacja między granicami mikrousług jest prawdziwym wyzwaniem. W tym kontekście komunikacja nie odnosi się do używanego protokołu (HTTP i REST, AMQP, obsługi komunikatów itd.). Zamiast tego zajmuje się tym, jakiego stylu komunikacji należy używać, a zwłaszcza w jaki sposób powinny być powiązane mikrousługi. W zależności od poziomu sprzężenia, gdy wystąpi awaria, wpływ tej awarii na system będzie się znacznie różnić.
W systemie rozproszonym, takiej jak aplikacja oparta na mikrousługach, z tak wieloma artefaktami przenoszonymi i rozproszonymi usługami na wielu serwerach lub hostach, składniki ostatecznie zakończy się niepowodzeniem. Wystąpią częściowe awarie i jeszcze większe awarie, dlatego należy zaprojektować mikrousługi i komunikację między nimi, biorąc pod uwagę typowe zagrożenia w tym typie systemu rozproszonego.
Popularnym podejściem jest zaimplementowanie mikrousług opartych na protokole HTTP (REST) ze względu na ich prostotę. Podejście oparte na protokole HTTP jest całkowicie akceptowalne; problem jest tutaj związany z tym, jak go używasz. Jeśli używasz żądań HTTP i odpowiedzi tylko do interakcji z mikrousługami z aplikacji klienckich lub z bram interfejsu API, jest to w porządku. Jeśli jednak utworzysz długie łańcuchy synchronicznych wywołań HTTP w mikrousługach, komunikując się przez granice tak, jakby mikrousługi były obiektami w aplikacji monolitycznej, aplikacja ostatecznie napotka problemy.
Załóżmy na przykład, że aplikacja kliencka wykonuje wywołanie interfejsu API HTTP do pojedynczej mikrousługi, takiej jak mikrousługa Zamawianie. Jeśli mikrousługa Zamawianie z kolei wywołuje dodatkowe mikrousługi przy użyciu protokołu HTTP w ramach tego samego cyklu żądania/odpowiedzi, tworzysz łańcuch wywołań HTTP. Początkowo może to brzmieć rozsądnie. Jednak podczas przechodzenia w dół tej ścieżki należy wziąć pod uwagę ważne kwestie:
Blokowanie i niska wydajność. Ze względu na synchroniczną naturę protokołu HTTP oryginalne żądanie nie otrzymuje odpowiedzi do momentu zakończenia wszystkich wewnętrznych wywołań HTTP. Wyobraź sobie, że liczba tych wywołań znacznie się zwiększa i jednocześnie jedno z pośrednich wywołań HTTP do mikrousługi jest blokowane. Wynika to z tego, że ma to wpływ na wydajność, a ogólna skalowalność będzie miała wpływ wykładniczo w miarę wzrostu dodatkowych żądań HTTP.
Sprzęganie mikrousług za pomocą protokołu HTTP. Mikrousługi biznesowe nie powinny być powiązane z innymi mikrousługami biznesowymi. W idealnym przypadku nie powinni "wiedzieć" o istnieniu innych mikrousług. Jeśli aplikacja opiera się na sprzężeniu mikrousług, jak w przykładzie, osiągnięcie autonomii na mikrousługę będzie prawie niemożliwe.
Niepowodzenie w dowolnej mikrousłudze. Jeśli zaimplementowano łańcuch mikrousług połączonych przez wywołania HTTP, gdy którakolwiek z mikrousług zakończy się niepowodzeniem (i ostatecznie zakończy się niepowodzeniem), cały łańcuch mikrousług zakończy się niepowodzeniem. System oparty na mikrousługach powinien być zaprojektowany tak, aby działał tak dobrze, jak to możliwe podczas częściowych awarii. Nawet jeśli implementujesz logikę klienta, która używa ponownych prób z mechanizmami wycofywania wykładniczego lub wyłącznika, tym bardziej złożone są łańcuchy wywołań HTTP, tym bardziej złożone jest zaimplementowanie strategii awarii na podstawie protokołu HTTP.
W rzeczywistości, jeśli wewnętrzne mikrousługi komunikują się przez tworzenie łańcuchów żądań HTTP zgodnie z opisem, można argumentować, że masz aplikację monolityczną, ale jedną opartą na protokole HTTP między procesami zamiast mechanizmów komunikacji wewnątrzprocesowej.
W związku z tym, aby wymusić autonomię mikrousług i mieć lepszą odporność, należy zminimalizować użycie łańcuchów komunikacji żądań/odpowiedzi między mikrousługami. Zaleca się używanie tylko asynchronicznej interakcji dla komunikacji między mikrousługami przy użyciu asynchronicznej komunikacji opartej na komunikatach i zdarzeniach albo przy użyciu sondowania HTTP (asynchronicznego) niezależnie od oryginalnego cyklu żądania HTTP/odpowiedzi.
Użycie komunikacji asynchronicznej zostało wyjaśnione dodatkowymi szczegółami w dalszej części tego przewodnika w sekcjach Integracja mikrousługi asynchronicznej wymusza autonomię mikrousługi i asynchroniczną komunikację opartą na komunikatach.
Dodatkowe zasoby
Twierdzenie CAP
https://en.wikipedia.org/wiki/CAP_theoremSpójność ostateczna
https://en.wikipedia.org/wiki/Eventual_consistencyPodstawy spójności danych
https://learn.microsoft.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS (podział odpowiedzialności poleceń i zapytań)
https://martinfowler.com/bliki/CQRS.htmlZmaterializowany widok
https://learn.microsoft.com/azure/architecture/patterns/materialized-viewCharles Row. ACID a BASE: Przesunięcie pH przetwarzania transakcji bazy danych
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Transakcja wyrównująca
https://learn.microsoft.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Kompozycja zorientowana na usługi
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/