Co to jest chmura natywna?
Napiwek
Ta zawartość jest fragmentem książki eBook, Architekting Cloud Native .NET Applications for Azure, dostępnej na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

Zatrzymaj to, co robisz, i poproś współpracowników o zdefiniowanie terminu "Cloud Native". Istnieje duża szansa, że otrzymasz kilka różnych odpowiedzi.
Zacznijmy od prostej definicji:
Architektura i technologie natywne dla chmury to podejście do projektowania, konstruowania i obsługi obciążeń, które są wbudowane w chmurze i w pełni korzystają z modelu przetwarzania w chmurze.
Fundacja Cloud Native Computing Foundation zawiera oficjalną definicję:
Technologie natywne dla chmury umożliwiają organizacjom tworzenie i uruchamianie skalowalnych aplikacji w nowoczesnych środowiskach dynamicznych, takich jak chmury publiczne, prywatne i hybrydowe. Kontenery, siatki usług, mikrousługi, niezmienna infrastruktura i deklaratywne interfejsy API są przykładem tego podejścia.
Te techniki umożliwiają luźno powiązane systemy, które są odporne, możliwe do zarządzania i zauważalne. W połączeniu z niezawodną automatyzacją umożliwiają inżynierom częste i przewidywanie częste wprowadzanie zmian o dużym wpływie i przewidywanie przy minimalnym trudze.
Natywna dla chmury jest o szybkości i elastyczności. Systemy biznesowe ewoluują od umożliwienia możliwości biznesowych do broni strategicznej transformacji, która przyspiesza szybkość działalności biznesowej i rozwój. Konieczne jest natychmiastowe uzyskanie nowych pomysłów na rynek.
Jednocześnie systemy biznesowe stają się coraz bardziej złożone, a użytkownicy domagają się więcej. Oczekują szybkiego reagowania, innowacyjnych funkcji i zerowego przestoju. Problemy z wydajnością, błędy cykliczne i brak możliwości szybkiego przenoszenia nie są już akceptowalne. Twoi użytkownicy odwiedzą konkurenta. Systemy natywne dla chmury zaprojektowano tak, aby obejmowały szybkie zmiany, dużą skalę i odporność.
Oto niektóre firmy, które wdrożyły techniki natywne dla chmury. Zastanów się nad szybkością, elastycznością i skalowalnością, jaką osiągnęli.
| Firma | Środowisko |
|---|---|
| Netflix | Ma 600+ usług w środowisku produkcyjnym. Wdraża 100 razy dziennie. |
| Uber | Ma 1000 usług w środowisku produkcyjnym. Wdraża kilka tysięcy razy w tygodniu. |
| Ma 3000 usług w środowisku produkcyjnym. Wdraża 1000 razy dziennie. |
Jak widać, Netflix, Uber i WeChat udostępniają systemy natywne dla chmury, które składają się z wielu niezależnych usług. Ten styl architektoniczny pozwala im szybko reagować na warunki rynkowe. Natychmiast aktualizują małe obszary aktywnej, złożonej aplikacji bez pełnego ponownego wdrożenia. Indywidualnie skalują usługi zgodnie z potrzebami.
Filary chmury natywnej
Szybkość i elastyczność natywnej chmury wynikają z wielu czynników. Przede wszystkim jest infrastruktura chmury. Ale jest więcej: Pięć innych podstawowych filarów pokazanych na rysunku 1-3 zapewnia również podstawy dla systemów natywnych dla chmury.
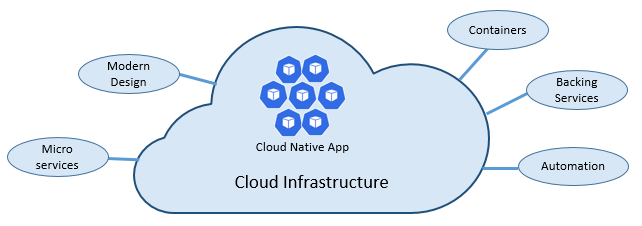
Rysunek 1–3. Podstawowe filary chmury
Pośmińmy trochę czasu, aby lepiej zrozumieć znaczenie każdego filaru.
Chmura
Systemy natywne dla chmury korzystają w pełni z modelu usług w chmurze.
Zaprojektowane tak, aby rozwijać się w dynamicznym, zwirtualizowanym środowisku chmury, systemy te intensywnie korzystają z infrastruktury obliczeniowej platformy jako usługi (PaaS) i usług zarządzanych. Traktują podstawową infrastrukturę jako jednorazową — aprowizowaną w minutach i zmienianą, skalowaną lub zniszczona na żądanie — za pośrednictwem automatyzacji.
Rozważ różnicę między tym, jak traktujemy zwierzęta domowe i towary. W tradycyjnym centrum danych serwery są traktowane jako zwierzęta domowe: maszyna fizyczna, mająca znaczącą nazwę i dbana o nie. Skalowanie można przeprowadzić, dodając więcej zasobów do tej samej maszyny (skalowanie w górę). Jeśli serwer staje się chory, pielęgniarka go z powrotem do zdrowia. Jeśli serwer stanie się niedostępny, wszyscy zauważą.
Model usług towarowych jest inny. Każde wystąpienie można aprowizować jako maszynę wirtualną lub kontener. Są one identyczne i przypisane identyfikator systemu, taki jak Service-01, Service-02 itd. Skalowanie odbywa się przez utworzenie większej liczby wystąpień (skalowanie w poziomie). Nikt nie zauważa, gdy wystąpienie stanie się niedostępne.
Model towarów obejmuje niezmienną infrastrukturę. Serwery nie są naprawiane ani modyfikowane. Jeśli jedna z nich zakończy się niepowodzeniem lub wymaga aktualizacji, zostanie ona zniszczona, a nowa zostanie aprowizowana — wszystko odbywa się za pośrednictwem automatyzacji.
Systemy natywne dla chmury obejmują model usług towarów. Nadal działają one w miarę skalowania infrastruktury w poziomie lub w poziomie bez względu na maszyny, na których są uruchomione.
Platforma w chmurze platformy Azure obsługuje tego typu wysoce elastyczną infrastrukturę z automatycznym skalowaniem, samonaprawieniem i możliwościami monitorowania.
Nowoczesny projekt
Jak zaprojektować aplikację natywną dla chmury? Jak wyglądałaby Twoja architektura? Jakie zasady, wzorce i najlepsze rozwiązania należy przestrzegać? Jakie kwestie związane z infrastrukturą i operacjami byłyby ważne?
Aplikacja dwunastoskładnikowa
Powszechnie akceptowaną metodologią tworzenia aplikacji opartych na chmurze jest dwunastoskładnikowa aplikacja. Opisano w nim zestaw zasad i praktyk, które deweloperzy przestrzegają w celu konstruowania aplikacji zoptymalizowanych pod kątem nowoczesnych środowisk w chmurze. Szczególną uwagę należy zwrócić na przenośność w środowiskach i automatyzację deklaracyjną.
Chociaż ma zastosowanie do dowolnej aplikacji internetowej, wielu praktyków uważa, że Dwanaście czynników stanowi solidną podstawę do tworzenia aplikacji natywnych dla chmury. Systemy oparte na tych zasadach umożliwiają szybkie wdrażanie i skalowanie oraz dodawanie funkcji w celu szybkiego reagowania na zmiany na rynku.
W poniższej tabeli przedstawiono metodologię Dwunastoskładnikową:
| Współczynnik | Wyjaśnienie |
|---|---|
| 1 — Podstawa kodu | Pojedyncza baza kodu dla każdej mikrousługi przechowywanej we własnym repozytorium. Śledzone za pomocą kontroli wersji może być wdrażane w wielu środowiskach (QA, Staging, Production). |
| 2 — Zależności | Każda mikrousługa izoluje i pakuje własne zależności, obejmując zmiany bez wpływu na cały system. |
| 3 — Konfiguracje | Informacje o konfiguracji są przenoszone z mikrousługi i zewnętrznie za pomocą narzędzia do zarządzania konfiguracją poza kodem. To samo wdrożenie może propagować w różnych środowiskach z zastosowaną poprawną konfiguracją. |
| 4 — Usługi zapasowe | Zasoby pomocnicze (magazyny danych, pamięci podręczne, brokery komunikatów) powinny być udostępniane za pośrednictwem adresowego adresu URL. Powoduje to oddzielenie zasobu od aplikacji, co umożliwia jego wymianę. |
| 5 — Kompilacja, Wydanie, Uruchamianie | Każda wersja musi wymuszać ścisłe rozdzielenie między etapami kompilacji, wydania i uruchamiania. Każdy z nich powinien być oznaczony unikatowym identyfikatorem i obsługiwać możliwość wycofywania. Nowoczesne systemy ciągłej integracji/ciągłego wdrażania pomagają spełnić tę zasadę. |
| 6 — Procesy | Każda mikrousługa powinna być wykonywana we własnym procesie izolowanym od innych uruchomionych usług. Zewnętrznie wymagany stan do usługi zapasowej, takiej jak rozproszona pamięć podręczna lub magazyn danych. |
| 7 — Powiązanie portu | Każda mikrousługa powinna być samodzielnie zawarta w interfejsach i funkcjach udostępnianych na własnym porcie. Zapewnia to izolację od innych mikrousług. |
| 8 — Współbieżność | Gdy pojemność musi wzrosnąć, przeprowadź skalowanie usług w poziomie w wielu identycznych procesach (kopiach), w przeciwieństwie do skalowania w górę pojedynczego dużego wystąpienia na najbardziej wydajnej dostępnej maszynie. Twórz aplikację tak, aby mogła być współbieżna, co pozwala bezproblemowo skalować w górę w środowiskach chmury. |
| 9 — Rozproszenie | Wystąpienia usług powinny być jednorazowe. Preferuj szybkie uruchamianie, aby zwiększyć możliwości skalowalności i bezproblemowe zamknięcia, aby opuścić system w prawidłowym stanie. Kontenery platformy Docker wraz z orkiestratorem z natury spełniają to wymaganie. |
| 10 — Parzystość dev/Prod | Zachowaj środowiska w całym cyklu życia aplikacji tak samo, jak to możliwe, unikając kosztownych skrótów. W tym miejscu wdrożenie kontenerów może znacznie przyczynić się poprzez promowanie tego samego środowiska wykonywania. |
| 11 — Rejestrowanie | Traktuj dzienniki generowane przez mikrousługi jako strumienie zdarzeń. Przetwarzaj je za pomocą agregatora zdarzeń. Propagacja danych dziennika do narzędzi do zarządzania danymi/dziennikami, takich jak Azure Monitor lub Splunk, i ostatecznie do długoterminowego archiwizowania. |
| 12 — procesy Administracja | Uruchom zadania administracyjne/zarządzania, takie jak oczyszczanie danych lub analiza obliczeniowa, jako jednorazowe procesy. Użyj niezależnych narzędzi do wywoływania tych zadań ze środowiska produkcyjnego, ale niezależnie od aplikacji. |
W książce Beyond the Twelve-Factor App, autor Kevin Hoffman szczegóły każdego z oryginalnych 12 czynników (napisanych w 2011 roku). Ponadto omawia trzy dodatkowe czynniki odzwierciedlające dzisiejszy nowoczesny projekt aplikacji w chmurze.
| Nowy czynnik | Wyjaśnienie |
|---|---|
| 13 — Najpierw interfejs API | Utwórz wszystko jako usługę. Załóżmy, że kod będzie używany przez klienta frontonu, bramę lub inną usługę. |
| 14 — Telemetria | Na stacji roboczej masz głęboki wgląd w aplikację i jej zachowanie. W chmurze nie. Upewnij się, że projekt zawiera kolekcję danych monitorowania, specyficznych dla domeny i kondycji/systemu. |
| 15 — Uwierzytelnianie/autoryzacja | Zaimplementuj tożsamość od początku. Rozważ użycie funkcji kontroli dostępu opartej na rolach (kontroli dostępu opartej na rolach) dostępnych w chmurach publicznych. |
Będziemy odnosić się do wielu z 12+ czynników w tym rozdziale i w całej książce.
Dobrze zaprojektowana struktura platformy Azure
Projektowanie i wdrażanie obciążeń opartych na chmurze może być trudne, szczególnie w przypadku implementowania architektury natywnej dla chmury. Firma Microsoft udostępnia standardowe rozwiązania branżowe, które ułatwiają Tobie i Twojemu zespołowi dostarczanie niezawodnych rozwiązań w chmurze.
Platforma Microsoft Well-Architected Framework udostępnia zestaw wskazówek, które mogą służyć do poprawy jakości obciążenia natywnego dla chmury. Struktura opiera się na pięciu filarach doskonałości architektury:
| Założenia | opis |
|---|---|
| Zarządzanie kosztami | Skoncentruj się na wczesnym generowaniu wartości przyrostowej. Zastosuj zasady Build-Measure-Learn , aby przyspieszyć czas obrotu przy jednoczesnym unikaniu rozwiązań intensywnie korzystających z kapitału. Korzystając ze strategii płatności zgodnie z rzeczywistym użyciem, zainwestuj w miarę skalowania w poziomie, zamiast dostarczać duże inwestycje z góry. |
| Bezpieczeństwo operacyjne | Zautomatyzuj środowisko i operacje, aby zwiększyć szybkość i zmniejszyć liczbę błędów ludzkich. Szybkie wycofywanie lub przekazywanie aktualizacji problemów. Zaimplementuj monitorowanie i diagnostykę od samego początku. |
| Wydajność | Efektywne spełnianie wymagań związanych z obciążeniami. Faworyzowanie skalowania w poziomie (skalowanie w poziomie) i projektowanie go w systemach. Stale przeprowadzaj testy wydajności i obciążenia, aby zidentyfikować potencjalne wąskie gardła. |
| Niezawodność | Twórz obciążenia, które są zarówno odporne, jak i dostępne. Odporność umożliwia obciążeniom odzyskiwanie po awariach i kontynuowanie działania. Dostępność zapewnia użytkownikom dostęp do obciążenia przez cały czas. Zaprojektuj aplikacje, aby oczekiwać awarii i odzyskać je. |
| Bezpieczeństwo | Zaimplementuj zabezpieczenia w całym cyklu życia aplikacji— od projektowania i implementacji po wdrażanie i operacje. Należy zwrócić szczególną uwagę na zarządzanie tożsamościami, dostęp do infrastruktury, zabezpieczenia aplikacji oraz niezależność i szyfrowanie danych. |
Aby rozpocząć pracę, firma Microsoft udostępnia zestaw ocen online, które ułatwiają ocenę bieżących obciążeń w chmurze pod kątem pięciu dobrze zaprojektowanych filarów.
Mikrousługi
Systemy natywne dla chmury obejmują mikrousługi, popularny styl architektury do tworzenia nowoczesnych aplikacji.
Zbudowany jako rozproszony zestaw małych, niezależnych usług, które współdziałają za pośrednictwem udostępnionej sieci szkieletowej, mikrousługi mają następujące cechy:
Każda z nich implementuje określoną funkcję biznesową w większym kontekście domeny.
Każda z nich jest opracowywana autonomicznie i może być wdrażana niezależnie.
Każda z nich samodzielnie hermetyzuje własną technologię przechowywania danych, zależności i platformę programowania.
Każdy działa we własnym procesie i komunikuje się z innymi przy użyciu standardowych protokołów komunikacyjnych, takich jak HTTP/HTTPS, gRPC, WebSockets lub AMQP.
Tworzą razem, aby utworzyć aplikację.
Rysunek 1–4 kontrastuje z podejściem do aplikacji monolitycznej przy użyciu podejścia mikrousług. Zwróć uwagę, że monolit składa się z architektury warstwowej, która jest wykonywana w jednym procesie. Zwykle korzysta z relacyjnej bazy danych. Jednak podejście mikrousług dzieli funkcje na niezależne usługi, z których każda ma własną logikę, stan i dane. Każda mikrousługa hostuje własny magazyn danych.
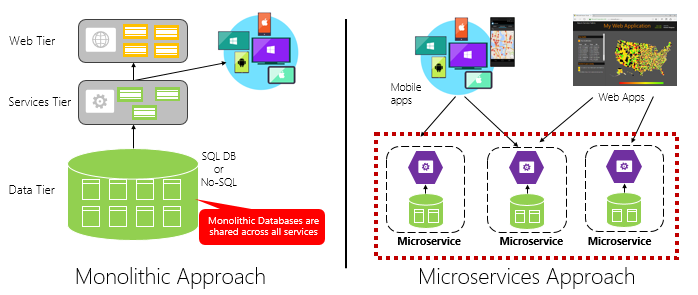
Rysunek 1–4. Architektura monolityczna a mikrousług
Zwróć uwagę, jak mikrousługi promują zasadę Procesów z dwunastoskładnikowej aplikacji omówionej wcześniej w rozdziale.
Element Factor #6 określa "Każda mikrousługa powinna być wykonywana we własnym procesie, odizolowana od innych uruchomionych usług".
Dlaczego mikrousługi?
Mikrousługi zapewniają elastyczność.
Wcześniej w rozdziale porównaliśmy aplikację do handlu elektronicznego utworzoną jako monolityczną aplikację z mikrousługami. W tym przykładzie przedstawiono pewne wyraźne korzyści:
Każda mikrousługa ma autonomiczny cykl życia i może ewoluować niezależnie i często wdrażać. Nie musisz czekać na kwartalną wersję, aby wdrożyć nową funkcję lub aktualizację. Możesz zaktualizować mały obszar aplikacji na żywo z mniejszym ryzykiem zakłócania całego systemu. Aktualizację można wykonać bez pełnego ponownego wdrożenia aplikacji.
Każda mikrousługa może być skalowana niezależnie. Zamiast skalować całą aplikację jako pojedynczą jednostkę, można skalować w poziomie tylko te usługi, które wymagają większej mocy obliczeniowej w celu spełnienia żądanych poziomów wydajności i umów dotyczących poziomu usług. Precyzyjne skalowanie zapewnia większą kontrolę nad systemem i pomaga zmniejszyć ogólne koszty podczas skalowania części systemu, a nie wszystkiego.
Doskonałym przewodnikiem referencyjnym dotyczącym rozumienia mikrousług jest mikrousługi platformy .NET: architektura konteneryzowanych aplikacji .NET. Książka zawiera szczegółowe informacje na temat projektowania i architektury mikrousług. Jest to uzupełnienie architektury referencyjnej mikrousługi pełnego stosu dostępnej w ramach bezpłatnego pobierania od firmy Microsoft.
Tworzenie mikrousług
Mikrousługi można tworzyć na dowolnej nowoczesnej platformie programistycznej.
Platforma Microsoft .NET jest doskonałym wyborem. Bezpłatne i open source ma wiele wbudowanych funkcji, które upraszczają tworzenie mikrousług. Platforma .NET jest międzyplatformowa. Aplikacje można tworzyć i uruchamiać w systemach Windows, macOS i większości smaków systemu Linux.
Platforma .NET jest wysoce wydajna i uzyskała dobre wyniki w porównaniu z Node.js i innymi konkurencyjnymi platformami. Co ciekawe, TechEmpower przeprowadził obszerny zestaw testów porównawczych wydajności w wielu platformach i strukturach aplikacji internetowych. Platforma .NET zdobyła wynik w pierwszej 10 - o ponad Node.js i innych konkurencyjnych platformach.
Platforma .NET jest utrzymywana przez firmę Microsoft i społeczność platformy .NET w witrynie GitHub.
Wyzwania związane z mikrousługą
Chociaż rozproszone mikrousługi natywne dla chmury mogą zapewnić ogromną elastyczność i szybkość, stanowią one wiele wyzwań:
Komunikacja
W jaki sposób aplikacje klienckie frontonu będą komunikować się z mikrousługami opartymi na rdzeniach zaplecza? Czy zezwolisz na bezpośrednią komunikację? A może możesz abstrakcić mikrousługi zaplecza z fasadą bramy, która zapewnia elastyczność, kontrolę i bezpieczeństwo?
Jak mikrousługi podstawowe zaplecza komunikują się ze sobą? Czy zezwolisz na bezpośrednie wywołania HTTP, które mogą zwiększyć sprzężenie i wpływać na wydajność i elastyczność? Możesz też rozważyć oddzielenie komunikatów za pomocą technologii kolejki i tematów?
Komunikacja jest omówiona w rozdziale Wzorce komunikacji natywnej dla chmury.
Odporność
Architektura mikrousług przenosi system z procesu do komunikacji sieciowej poza procesem. W architekturze rozproszonej co się stanie, gdy usługa B nie odpowiada na wywołanie sieciowe z usługi A? A co się stanie, gdy usługa C stanie się tymczasowo niedostępna, a inne usługi wywołujące ją staną się zablokowane?
Odporność jest omówiona w rozdziale Odporność natywna dla chmury.
Dane rozproszone
Zgodnie z projektem każda mikrousługa hermetyzuje własne dane, ujawniając operacje za pośrednictwem interfejsu publicznego. Jeśli tak, w jaki sposób wykonujesz zapytania o dane lub implementujesz transakcję w wielu usługach?
Dane rozproszone zostały omówione w rozdziale Wzorce danych natywnych dla chmury .
Wpisy tajne
W jaki sposób mikrousługi będą bezpiecznie przechowywać wpisy tajne i poufne dane konfiguracji oraz zarządzać nimi?
Wpisy tajne zostały szczegółowo omówione w zabezpieczeniach natywnych dla chmury.
Zarządzanie złożonością przy użyciu języka Dapr
Dapr to rozproszone środowisko uruchomieniowe aplikacji typu open source. Dzięki architekturze składników podłączanych znacznie upraszcza ona instalację wodną za aplikacjami rozproszonymi. Zapewnia ona dynamiczny klej, który wiąże aplikację ze wstępnie utworzonymi funkcjami i składnikami infrastruktury ze środowiska uruchomieniowego języka Dapr. Rysunek 1–5 przedstawia Dapr z 20 000 stóp.
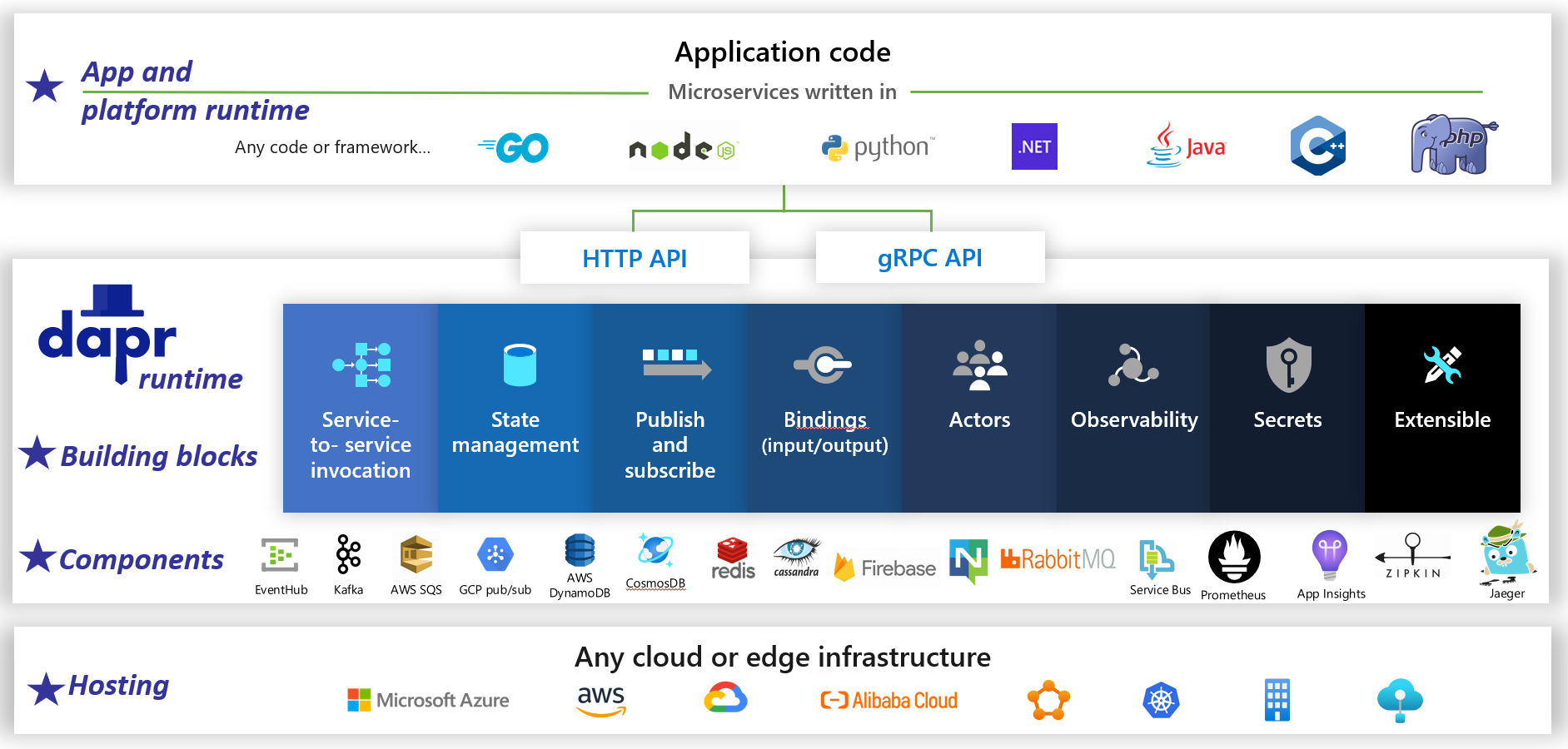 Rysunek 1–5. Dapr na 20.000 stóp.
Rysunek 1–5. Dapr na 20.000 stóp.
W górnym wierszu rysunku zwróć uwagę, jak język Dapr udostępnia zestawy SDK specyficzne dla języka dla popularnych platform programistycznych. Język Dapr w wersji 1 obejmuje obsługę platform .NET, Go, Node.js, Python, PHP, Java i JavaScript.
Zestawy SDK specyficzne dla języka zwiększają środowisko deweloperskie, ale język Dapr jest niezależny od platformy. Pod maską model programowania Dapr uwidacznia możliwości za pośrednictwem standardowych protokołów komunikacyjnych HTTP/gRPC. Każda platforma programistyczna może wywoływać język Dapr za pośrednictwem natywnych interfejsów API HTTP i gRPC.
Niebieskie pola na środku rysunku reprezentują bloki konstrukcyjne Języka Dapr. Każdy uwidacznia wstępnie skompilowany kod kanalizacji dla funkcji aplikacji rozproszonej, którą aplikacja może wykorzystywać.
Wiersz składników reprezentuje duży zestaw wstępnie zdefiniowanych składników infrastruktury, z których aplikacja może korzystać. Pomyśl o składnikach jako kodzie infrastruktury, którego nie trzeba pisać.
W dolnym wierszu wyróżniono przenośność języka Dapr i różnych środowisk, w których może działać.
Patrząc w przyszłość, Dapr ma potencjał, aby mieć głęboki wpływ na tworzenie aplikacji natywnych dla chmury.
Kontenery
To naturalne, aby usłyszeć termin kontener wymieniony w dowolnej konwersacji natywnej w chmurze. W książce Cloud Native Patterns, autor Cornelia Davis zauważa, że "Kontenery są doskonałym elementem oprogramowania natywnego dla chmury". Cloud Native Computing Foundation umieszcza konteneryzację mikrousług jako pierwszy krok w mapie szlaków natywnych dla chmury — wskazówki dla przedsiębiorstw rozpoczynających swoją podróż natywną dla chmury.
{kind=link}
Konteneryzowanie mikrousługi jest proste i proste. Kod, jego zależności i środowisko uruchomieniowe są pakowane do pliku binarnego nazywanego obrazem kontenera. Obrazy są przechowywane w rejestrze kontenerów, który działa jako repozytorium lub biblioteka obrazów. Rejestr może znajdować się na komputerze dewelopera, w centrum danych lub w chmurze publicznej. Sama platforma Docker obsługuje rejestr publiczny za pośrednictwem usługi Docker Hub. Chmura platformy Azure zawiera prywatny rejestr kontenerów do przechowywania obrazów kontenerów w pobliżu aplikacji w chmurze, które będą je uruchamiać.
Po uruchomieniu lub skalowaniu aplikacji obraz kontenera zostanie przekształcony w uruchomione wystąpienie kontenera. Wystąpienie jest uruchamiane na dowolnym komputerze z zainstalowanym aparatem środowiska uruchomieniowego kontenera. W razie potrzeby można mieć dowolną liczbę wystąpień usługi konteneryzowanej.
Rysunek 1–6 przedstawia trzy różne mikrousługi, z których każda jest w swoim kontenerze, wszystkie uruchomione na jednym hoście.
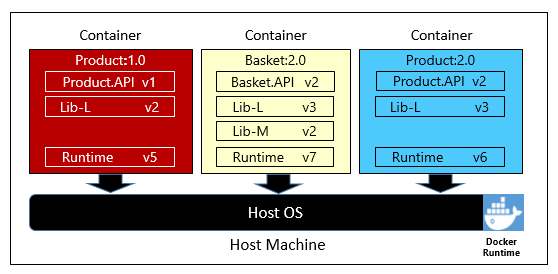
Rysunek 1–6. Wiele kontenerów uruchomionych na hoście kontenera
Zwróć uwagę, że każdy kontener zachowuje własny zestaw zależności i środowiska uruchomieniowego, który może się różnić od siebie. W tym miejscu widzimy różne wersje mikrousługi Product uruchomionej na tym samym hoście. Każdy kontener udostępnia fragment bazowego systemu operacyjnego hosta, pamięci i procesora, ale jest odizolowany od siebie.
Zwróć uwagę, jak dobrze model kontenera obejmuje zasadę Zależności z aplikacji Dwunastoskładnikowej.
Składnik #2 określa, że "Każda mikrousługa izoluje i pakuje własne zależności, obejmując zmiany bez wpływu na cały system".
Kontenery obsługują obciążenia systemów Linux i Windows. Chmura platformy Azure otwarcie obejmuje oba te rozwiązania. Co ciekawe, jest to system Linux, a nie Windows Server, który stał się bardziej popularnym systemem operacyjnym na platformie Azure.
Chociaż istnieje kilku dostawców kontenerów, platforma Docker uchwyciła udział lwa na rynku. Firma napędza ruch kontenerów oprogramowania. Stało się to de facto standardem tworzenia pakietów, wdrażania i uruchamiania aplikacji natywnych dla chmury.
Dlaczego kontenery?
Kontenery zapewniają przenośność i gwarantują spójność w różnych środowiskach. Hermetyzując wszystko w jednym pakiecie, należy odizolować mikrousługę i jej zależności od podstawowej infrastruktury.
Kontener można wdrożyć w dowolnym środowisku hostujący aparat środowiska uruchomieniowego platformy Docker. Konteneryzowane obciążenia eliminują również wydatki na wstępne konfigurowanie każdego środowiska za pomocą struktur, bibliotek oprogramowania i aparatów środowiska uruchomieniowego.
Dzięki udostępnieniu bazowego systemu operacyjnego i zasobów hosta kontener ma znacznie mniejszy rozmiar niż pełna maszyna wirtualna. Mniejszy rozmiar zwiększa gęstość lub liczbę mikrousług, które dany host może uruchomić jednocześnie.
Aranżacja kontenerów
Narzędzia, takie jak Platforma Docker, tworzą obrazy i uruchamiają kontenery, ale potrzebne są również narzędzia do zarządzania nimi. Zarządzanie kontenerami odbywa się za pomocą specjalnego programu programowego nazywanego orkiestratorem kontenerów. W przypadku działania na dużą skalę z wieloma niezależnymi uruchomionymi kontenerami orkiestracja jest niezbędna.
Rysunek 1–7 przedstawia zadania zarządzania, które koordynatorzy kontenerów automatyzują.
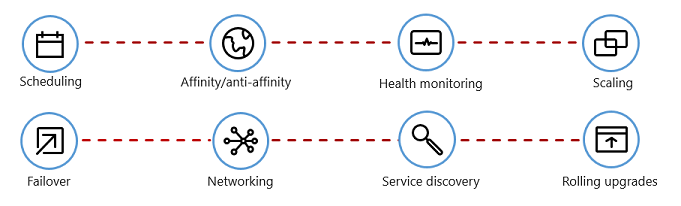
Rysunek 1–7. Co robią koordynatorzy kontenerów
W poniższej tabeli opisano typowe zadania orkiestracji.
| Zadania | Wyjaśnienie |
|---|---|
| Planowanie | Automatyczne aprowizuj wystąpienia kontenerów. |
| Koligacja/koligacja anty-koligacja | Aprowizuj kontenery w pobliżu lub daleko od siebie, pomagając w dostępności i wydajności. |
| Monitorowanie kondycji | Automatycznie wykrywaj i poprawiaj błędy. |
| Tryb failover | Automatyczne ponowne inicjowanie obsługi administracyjnej wystąpienia, które nie powiodło się na maszynie w dobrej kondycji. |
| Skalowanie | Automatyczne dodawanie lub usuwanie wystąpienia kontenera w celu spełnienia wymagań. |
| Sieć | Zarządzanie nakładką sieciową na potrzeby komunikacji kontenerów. |
| Odnajdywanie usług | Umożliwianie kontenerom lokalizowania siebie nawzajem. |
| Uaktualnienia stopniowe | Koordynuj uaktualnienia przyrostowe z zerowym przestojem wdrożenia. Automatycznie wycofaj problematyczne zmiany. |
Zwróć uwagę, w jaki sposób orkiestratory kontenerów stosują zasady Dysosability i Współbieżności z aplikacji Dwunastoskładnikowej.
Czynnik #9 określa, że "Wystąpienia usług powinny być jednorazowe, faworyzując szybkie uruchamianie w celu zwiększenia możliwości skalowalności i bezproblemowych wyłączeń w celu opuszczenia systemu w prawidłowym stanie"." Kontenery platformy Docker wraz z orkiestratorem z natury spełniają to wymaganie.
Czynnik #8 określa, że "Usługi są skalowane w poziomie w dużej liczbie małych identycznych procesów (kopii), w przeciwieństwie do skalowania w górę pojedynczego dużego wystąpienia na najbardziej wydajnej dostępnej maszynie".
Chociaż istnieje kilka orkiestratorów kontenerów, platforma Kubernetes stała się de facto standardem dla świata natywnego dla chmury. Jest to przenośna, rozszerzalna platforma typu open source do zarządzania konteneryzowanymi obciążeniami.
Możesz hostować własne wystąpienie platformy Kubernetes, ale wówczas będziesz odpowiedzialny za aprowizowanie zasobów i zarządzanie nimi — co może być złożone. Chmura platformy Azure oferuje platformę Kubernetes jako usługę zarządzaną. Usługi Azure Kubernetes Service (AKS) i Azure Red Hat OpenShift (ARO) umożliwiają pełne wykorzystanie funkcji i możliwości platformy Kubernetes jako usługi zarządzanej bez konieczności instalowania i konserwacji.
Orkiestracja kontenerów szczegółowo opisano w temacie Scaling Cloud-Native Applications (Skalowanie aplikacji natywnych dla chmury).
Usługi zapasowe
Systemy natywne dla chmury zależą od wielu różnych zasobów pomocniczych, takich jak magazyny danych, brokerzy komunikatów, monitorowanie i usługi tożsamości. Te usługi są nazywane usługami zapasowymi.
Rysunek 1–8 przedstawia wiele typowych usług zapasowych używanych przez systemy natywne dla chmury.
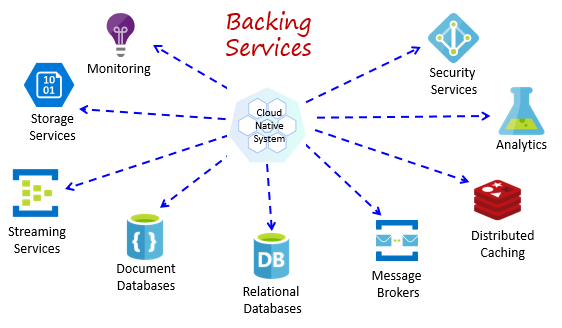
Rysunek 1–8. Typowe usługi tworzenia kopii zapasowych
Możesz hostować własne usługi zapasowe, ale wtedy będziesz odpowiedzialny za licencjonowanie, aprowizowanie i zarządzanie tymi zasobami.
Dostawcy usług w chmurze oferują bogaty asortyment zarządzanych usług zapasowych . Zamiast być właścicielem usługi, po prostu go używasz. Dostawca usług w chmurze obsługuje zasób na dużą skalę i ponosi odpowiedzialność za wydajność, bezpieczeństwo i konserwację. Monitorowanie, nadmiarowość i dostępność są wbudowane w usługę. Dostawcy gwarantują wydajność poziomu usług i w pełni obsługują swoje usługi zarządzane — otwórz bilet i rozwiążą twój problem.
Systemy natywne dla chmury preferują zarządzane usługi zapasowe od dostawców usług w chmurze. Oszczędności w czasie i pracy mogą być znaczące. Ryzyko operacyjne hostingu własnego i problemy mogą być kosztowne szybko.
Najlepszym rozwiązaniem jest traktowanie usługi zapasowej jako dołączonego zasobu, dynamicznie powiązanego z mikrousługą z informacjami o konfiguracji (adresem URL i poświadczeniami) przechowywanymi w konfiguracji zewnętrznej. Te wskazówki zostały opisane we wcześniejszej części rozdziału w aplikacji dwunastoskładnikowej.
Składnik #4 określa, że usługi zapasowe "powinny być uwidocznione za pośrednictwem adresowego adresu URL. Powoduje to oddzielenie zasobu od aplikacji, dzięki czemu może być wymienny".
Składnik #3 określa, że "Informacje o konfiguracji są przenoszone z mikrousługi i zewnętrznie za pomocą narzędzia do zarządzania konfiguracją poza kodem".
Za pomocą tego wzorca usługę zapasową można dołączać i odłączać bez zmian kodu. Możesz podwyższyć poziom mikrousługi z kontroli jakości do środowiska przejściowego. Należy zaktualizować konfigurację mikrousług, aby wskazywała usługi zapasowe w środowisku przejściowym i wprowadzała ustawienia do kontenera za pomocą zmiennej środowiskowej.
Dostawcy usług w chmurze udostępniają interfejsy API do komunikowania się z zastrzeżonymi usługami zapasowymi. Te biblioteki hermetyzują zastrzeżoną instalację wodną i złożoność. Jednak bezpośrednie komunikowanie się z tymi interfejsami API spowoduje ścisłe połączenie kodu z daną usługą zapasową. Jest to powszechnie akceptowana praktyka izolowania szczegółów implementacji interfejsu API dostawcy. Wprowadzenie do warstwy pośredniczącej lub pośredniego interfejsu API, uwidaczniania operacji ogólnych w kodzie usługi i opakowywanie kodu dostawcy wewnątrz niego. To luźne sprzężenie umożliwia zamianę jednej usługi zapasowej na inną lub przeniesienie kodu do innego środowiska chmury bez konieczności wprowadzania zmian w kodzie usługi mainline. Język Dapr, omówiony wcześniej, jest zgodny z tym modelem z zestawem wstępnie utworzonych bloków konstrukcyjnych.
Na ostatniej myśli, usługi wspierania również promować zasadę bezstanowości z Dwunastoskładnikowej Aplikacji, omówionej wcześniej w rozdziale.
Czynnik #6 określa, że "Każda mikrousługa powinna być wykonywana we własnym procesie, odizolowana od innych uruchomionych usług. Zewnętrznie wymagany stan do usługi zapasowej, takiej jak rozproszona pamięć podręczna lub magazyn danych.
Usługi zapasowe zostały omówione w wzorcach danych natywnych dla chmury i wzorcach komunikacji natywnej dla chmury.
Automation
Jak już wiesz, systemy natywne dla chmury obejmują mikrousługi, kontenery i nowoczesny projekt systemu w celu osiągnięcia szybkości i elastyczności. Ale to tylko część historii. Jak aprowizować środowiska chmury, na których działają te systemy? Jak szybko wdrażać funkcje i aktualizacje aplikacji? Jak zaokrąglić pełny obraz?
Wprowadź powszechnie akceptowaną praktykę infrastruktury jako kodu lub IaC.
Dzięki usłudze IaC automatyzujesz aprowizowanie platformy i wdrażanie aplikacji. Zasadniczo stosujesz praktyki inżynieryjne oprogramowania, takie jak testowanie i przechowywanie wersji w praktykach DevOps. Infrastruktura i wdrożenia są zautomatyzowane, spójne i powtarzalne.
Automatyzowanie infrastruktury
Narzędzia, takie jak Azure Resource Manager, Azure Bicep, Terraform z platformy HashiCorp i interfejs wiersza polecenia platformy Azure, umożliwiają deklaratywne tworzenie skryptów wymaganej infrastruktury w chmurze. Nazwy zasobów, lokalizacje, pojemności i wpisy tajne są sparametryzowane i dynamiczne. Skrypt jest wersjonowany i ewidencjonowany w kontroli źródła jako artefakt projektu. Skrypt jest wywoływany w celu aprowizacji spójnej i powtarzalnej infrastruktury w środowiskach systemowych, takich jak QA, przejściowe i produkcyjne.
Pod maską, IaC jest idempotentny, co oznacza, że można uruchomić ten sam skrypt w i ponad bez skutków ubocznych. Jeśli zespół musi wprowadzić zmianę, edytuje i ponownie uruchamia skrypt. Dotyczy to tylko zaktualizowanych zasobów.
W artykule What is Infrastructure as Code (Co to jest infrastruktura jako kod), Author Sam Guckenheimer opisuje, w jaki sposób "Zespoły, które implementują IaC, mogą szybko i na dużą skalę dostarczać stabilne środowiska. Unikają ręcznej konfiguracji środowisk i wymuszają spójność, reprezentując żądany stan swoich środowisk za pomocą kodu. Wdrożenia infrastruktury za pomocą modelu IaC są powtarzalne i zapobiegają problemom w środowisku wykonywania spowodowanym przez dryfowanie konfiguracji lub brakujące zależności. Zespoły DevOps mogą współpracować z ujednoliconym zestawem rozwiązań i narzędzi, aby dostarczać aplikacje i ich infrastrukturę pomocniczą szybko, niezawodnie i na dużą skalę".
Automatyzowanie wdrożeń
Omówiona wcześniej aplikacja Dwunastoskładnikowa wywołuje oddzielne kroki podczas przekształcania ukończonego kodu w uruchomioną aplikację.
Składnik #5 określa, że "Każda wersja musi wymuszać ścisłe rozdzielenie między etapami kompilacji, wydania i uruchamiania. Każdy powinien być oznaczony unikatowym identyfikatorem i obsługiwać możliwość wycofywania.
Nowoczesne systemy ciągłej integracji/ciągłego wdrażania pomagają spełnić tę zasadę. Zapewniają one oddzielne kroki kompilacji i dostarczania, które pomagają zapewnić spójny i jakościowy kod, który jest łatwo dostępny dla użytkowników.
Rysunek 1–9 przedstawia rozdzielenie procesu wdrażania.
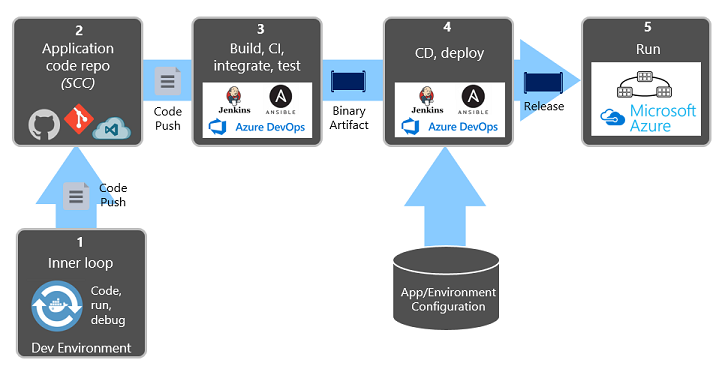
Rysunek 1–9. Kroki wdrażania w potoku ciągłej integracji/ciągłego wdrażania
Na poprzedniej ilustracji zwróć szczególną uwagę na rozdzielenie zadań:
- Deweloper tworzy funkcję w swoim środowisku projektowym, iterując przez to, co jest nazywane "wewnętrzną pętlą" kodu, uruchamiania i debugowania.
- Po zakończeniu ten kod jest wypychany do repozytorium kodu, takiego jak GitHub, Azure DevOps lub BitBucket.
- Wypychanie wyzwala etap kompilacji, który przekształca kod w artefakt binarny. Praca jest implementowana przy użyciu potoku ciągłej integracji. Automatycznie kompiluje, testuje i pakuje aplikację.
- Etap wydania pobiera artefakt binarny, stosuje informacje o konfiguracji aplikacji zewnętrznej i środowiska oraz tworzy niezmienną wersję. Wydanie jest wdrażane w określonym środowisku. Praca jest implementowana za pomocą potoku ciągłego dostarczania (CD). Każde wydanie powinno być możliwe do zidentyfikowania. Możesz powiedzieć: "To wdrożenie działa w wersji 2.1.1 aplikacji".
- Na koniec wydana funkcja jest uruchamiana w docelowym środowisku wykonywania. Wydania są niezmienne, co oznacza, że każda zmiana musi utworzyć nową wersję.
Stosując te praktyki, organizacje radykalnie ewoluowały, jak wysyłają oprogramowanie. Wiele z tych wersji zostało przeniesionych z kwartalnych wersji do aktualizacji na żądanie. Celem jest złapanie problemów na wczesnym etapie cyklu programowania, gdy są one tańsze do rozwiązania. Dłuższy czas trwania integracji, tym droższe problemy stają się rozwiązaniem. Dzięki spójności w procesie integracji zespoły mogą częściej zatwierdzać zmiany kodu, co prowadzi do lepszej współpracy i jakości oprogramowania.
Infrastruktura jako kod i automatyzacja wdrażania wraz z usługami GitHub i Azure DevOps zostały szczegółowo omówione w temacie DevOps.