Buforowanie w aplikacji natywnej dla chmury
Napiwek
Ta zawartość jest fragmentem książki eBook, Architekting Cloud Native .NET Applications for Azure, dostępnej na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

Korzyści z buforowania są dobrze zrozumiałe. Technika ta działa przez tymczasowe kopiowanie często używanych danych z magazynu danych zaplecza do szybkiego przechowywania znajdującego się bliżej aplikacji. Buforowanie jest często implementowana tam, gdzie...
- Dane pozostają stosunkowo statyczne.
- Dostęp do danych jest powolny, szczególnie w porównaniu z szybkością pamięci podręcznej.
- Dane podlegają wysokim poziomom rywalizacji.
Dlaczego?
Zgodnie ze wskazówkami dotyczącymi buforowania firmy Microsoft buforowanie może zwiększyć wydajność, skalowalność i dostępność poszczególnych mikrousług i całego systemu. Zmniejsza to opóźnienia i rywalizację o obsługę dużych ilości współbieżnych żądań do magazynu danych. Wraz ze wzrostem ilości danych i liczbą użytkowników tym większe są korzyści wynikające z buforowania.
Buforowanie jest najbardziej efektywna, gdy klient wielokrotnie odczytuje dane, które są niezmienne lub które zmieniają się rzadko. Przykłady obejmują informacje referencyjne, takie jak informacje o produkcie i cenach, lub udostępnione zasoby statyczne, które są kosztowne do konstruowania.
Chociaż mikrousługi powinny być bezstanowe, rozproszona pamięć podręczna może obsługiwać współbieżny dostęp do danych stanu sesji, jeśli jest to absolutnie wymagane.
Należy również rozważyć buforowanie, aby uniknąć powtarzających się obliczeń. Jeśli operacja przekształca dane lub wykonuje skomplikowane obliczenia, buforuj wynik dla kolejnych żądań.
Architektura buforowania
Aplikacje natywne dla chmury zwykle implementują architekturę rozproszonego buforowania. Pamięć podręczna jest hostowana jako oparta na chmurze usługa zapasowa oddzielona od mikrousług. Rysunek 5–15 przedstawia architekturę.
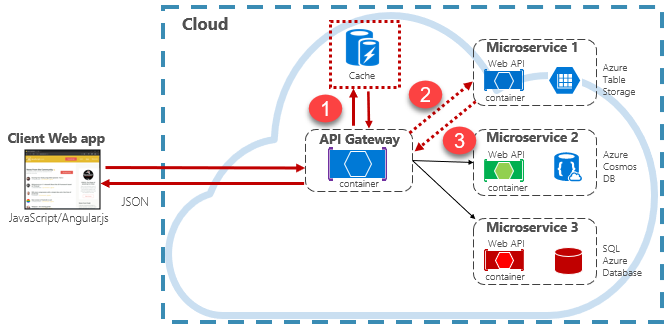
Rysunek 5–15: Buforowanie w aplikacji natywnej w chmurze
Na poprzedniej ilustracji zwróć uwagę, jak pamięć podręczna jest niezależna od mikrousług i współdzielona przez te mikrousługi. W tym scenariuszu pamięć podręczna jest wywoływana przez bramę interfejsu API. Zgodnie z opisem w rozdziale 4 brama służy jako fronton dla wszystkich żądań przychodzących. Rozproszona pamięć podręczna zwiększa czas reakcji systemu, zwracając buforowane dane, gdy jest to możliwe. Ponadto oddzielenie pamięci podręcznej od usług umożliwia niezależne skalowanie pamięci podręcznej w górę lub w poziomie w celu spełnienia zwiększonego zapotrzebowania na ruch.
Na poprzedniej ilustracji przedstawiono typowy wzorzec buforowania znany jako wzorzec z odkładaniem do pamięci podręcznej. W przypadku żądania przychodzącego należy najpierw wysłać zapytanie do pamięci podręcznej (krok 1) odpowiedzi. W przypadku znalezienia dane są zwracane natychmiast. Jeśli dane nie istnieją w pamięci podręcznej (znane jako miss pamięci podręcznej), są pobierane z lokalnej bazy danych w usłudze podrzędnej (krok 2). Następnie jest zapisywany w pamięci podręcznej dla przyszłych żądań (krok 3) i zwracany do elementu wywołującego. Należy zachować ostrożność w celu okresowego eksmisji buforowanych danych, aby system pozostał terminowo i spójny.
W miarę rozwoju udostępnionej pamięci podręcznej może okazać się korzystne podzielenie danych na wiele węzłów. Może to pomóc zminimalizować rywalizację i zwiększyć skalowalność. Wiele usługa buforowania obsługuje możliwość dynamicznego dodawania i usuwania węzłów oraz ponownego równoważenia danych między partycjami. Takie podejście zwykle obejmuje klastrowanie. Klastrowanie uwidacznia kolekcję węzłów federacyjnych jako bezproblemową, pojedynczą pamięć podręczną. Jednak dane są rozproszone wewnętrznie w węzłach zgodnie ze wstępnie zdefiniowaną strategią dystrybucji, która równoważy obciążenie.
Azure Cache for Redis
Azure Cache for Redis to bezpieczna usługa brokera buforowania danych i obsługi komunikatów, w pełni zarządzana przez firmę Microsoft. Używane jako oferta typu platforma jako usługa (PaaS) zapewnia dostęp do danych o wysokiej przepływności i małych opóźnieniach. Usługa jest dostępna dla dowolnej aplikacji na platformie Azure lub poza platformą Azure.
Usługa Azure Cache for Redis zarządza dostępem do serwerów Redis typu open source hostowanych w centrach danych platformy Azure. Usługa działa jako fasada zapewniająca zarządzanie, kontrolę dostępu i zabezpieczenia. Usługa natywnie obsługuje bogaty zestaw struktur danych, w tym ciągi, skróty, listy i zestawy. Jeśli aplikacja korzysta już z usługi Redis, będzie działać tak samo jak w przypadku usługi Azure Cache for Redis.
Usługa Azure Cache for Redis to więcej niż prosty serwer pamięci podręcznej. Może obsługiwać wiele scenariuszy, aby ulepszyć architekturę mikrousług:
- Magazyn danych w pamięci
- Rozproszona nierelacyjna baza danych
- Broker komunikatów
- Serwer konfiguracji lub odnajdywania
W przypadku zaawansowanych scenariuszy kopia buforowanych danych może być utrwalana na dysku. Jeśli katastrofalne zdarzenie wyłączy zarówno pamięć podręczną podstawową, jak i replikę, pamięć podręczna zostanie zrekonstruowana z najnowszej migawki.
Usługa Azure Redis Cache jest dostępna w wielu wstępnie zdefiniowanych konfiguracjach i warstwach cenowych. Warstwa Premium oferuje wiele funkcji na poziomie przedsiębiorstwa, takich jak klastrowanie, trwałość danych, replikacja geograficzna i izolacja sieci wirtualnej.