Wykonywanie zapytań względem plików usługi Delta Lake (wersja 1) przy użyciu bezserwerowej puli SQL w usłudze Azure Synapse Analytics
W tym artykule dowiesz się, jak napisać zapytanie przy użyciu bezserwerowej puli SQL synapse w celu odczytywania plików usługi Delta Lake. Usługa Delta Lake to warstwa magazynu typu open source, która oferuje transakcje ACID (niepodzielność, spójność, izolacja i trwałość) do obciążeń platformy Apache Spark i danych big data. Możesz dowiedzieć się więcej na temat wykonywania zapytań dotyczących tabel usługi Delta Lake.
Ważne
Bezserwerowe pule SQL mogą wysyłać zapytania do usługi Delta Lake w wersji 1.0. Zmiany wprowadzone od wersji usługi Delta Lake 1.2 (na przykład zmiany nazw kolumn) nie są obsługiwane w trybie bezserwerowym. Jeśli używasz wyższych wersji funkcji Delta z wektorami usuwania, punktami kontrolnymi w wersji 2 i innymi, rozważ użycie innego aparatu zapytań, takiego jak punkt końcowy SQL usługi Microsoft Fabric dla usługi Lakehouse.
Bezserwerowa pula SQL w obszarze roboczym usługi Synapse umożliwia odczytywanie danych przechowywanych w formacie usługi Delta Lake i obsługiwanie ich do narzędzi raportowania. Bezserwerowa pula SQL może odczytywać pliki usługi Delta Lake utworzone przy użyciu platformy Apache Spark, usługi Azure Databricks lub dowolnego innego producenta formatu usługi Delta Lake.
Pule platformy Apache Spark w usłudze Azure Synapse umożliwiają inżynierom danych modyfikowanie plików usługi Delta Lake przy użyciu języków Scala, PySpark i .NET. Bezserwerowe pule SQL ułatwiają analitykom danych tworzenie raportów dotyczących plików usługi Delta Lake utworzonych przez inżynierów danych.
Ważne
Wykonywanie zapytań dotyczących formatu usługi Delta Lake przy użyciu bezserwerowej puli SQL jest ogólnie dostępne . Jednak wykonywanie zapytań względem tabel delta platformy Spark jest nadal dostępne w publicznej wersji zapoznawczej i nie jest gotowe do produkcji. Istnieją znane problemy, które mogą wystąpić w przypadku wykonywania zapytań dotyczących tabel różnicowych utworzonych przy użyciu pul platformy Spark. Zapoznaj się ze znanymi problemami w samodzielnej pomocy bezserwerowej puli SQL.
Wymagania wstępne
Ważne
Źródła danych można tworzyć tylko w niestandardowych bazach danych (nie w bazie danych master lub bazach danych replikowanych z pul platformy Apache Spark).
Aby użyć przykładów w tym artykule, należy wykonać następujące czynności:
- Utwórz bazę danych ze źródłem danych, które odwołuje się do konta magazynu Yellow Taxi w Nowym Jorku.
- Zainicjuj obiekty, wykonując skrypt instalacji w bazie danych utworzonej w kroku 1. Ten skrypt instalacyjny utworzy źródła danych, poświadczenia o zakresie bazy danych i zewnętrzne formaty plików, które są używane w tych przykładach.
Jeśli baza danych została utworzona i przełączyła kontekst do bazy danych (używając USE database_name instrukcji lub listy rozwijanej do wybierania bazy danych w edytorze zapytań), możesz utworzyć zewnętrzne źródło danych zawierające główny identyfikator URI zestawu danych i użyć go do wykonywania zapytań względem plików usługi Delta Lake. Na przykład:
CREATE EXTERNAL DATA SOURCE DeltaLakeStorage
WITH ( LOCATION = 'https://<yourstorageaccount>.blob.core.windows.net/delta-lake/' );
GO
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
) as rows;
Jeśli źródło danych jest chronione przy użyciu klucza sygnatury dostępu współdzielonego lub tożsamości niestandardowej, możesz skonfigurować źródło danych przy użyciu poświadczeń o zakresie bazy danych.
Możesz utworzyć zewnętrzne źródło danych z lokalizacją wskazującą folder główny magazynu. Po utworzeniu zewnętrznego źródła danych użyj źródła danych i ścieżki względnej do pliku w OPENROWSET funkcji. W ten sposób nie trzeba używać pełnego bezwzględnego identyfikatora URI do plików. Następnie można zdefiniować poświadczenia niestandardowe, aby uzyskać dostęp do lokalizacji magazynu.
Odczytywanie folderu usługi Delta Lake
Ważne
Użyj skryptu konfiguracji w wymaganiach wstępnych, aby skonfigurować przykładowe źródła danych i tabele.
Funkcja OPENROWSET umożliwia odczytywanie zawartości plików usługi Delta Lake przez podanie adresu URL do folderu głównego.
Najprostszym sposobem wyświetlenia zawartości DELTA pliku jest podanie adresu URL pliku do funkcji OPENROWSET i określenie DELTA formatu. Jeśli plik jest publicznie dostępny lub jeśli tożsamość firmy Microsoft Entra może uzyskać dostęp do tego pliku, powinna być widoczna zawartość pliku przy użyciu zapytania, takiego jak pokazany w poniższym przykładzie:
SELECT TOP 10 *
FROM OPENROWSET(
BULK '/covid/',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta') as rows;
Nazwy kolumn i typy danych są automatycznie odczytywane z plików usługi Delta Lake. Funkcja OPENROWSET używa najlepszych typów odgadnięcia, takich jak VARCHAR(1000) dla kolumn ciągu.
Identyfikator URI w OPENROWSET funkcji musi odwoływać się do głównego folderu usługi Delta Lake, który zawiera podfolder o nazwie _delta_log.
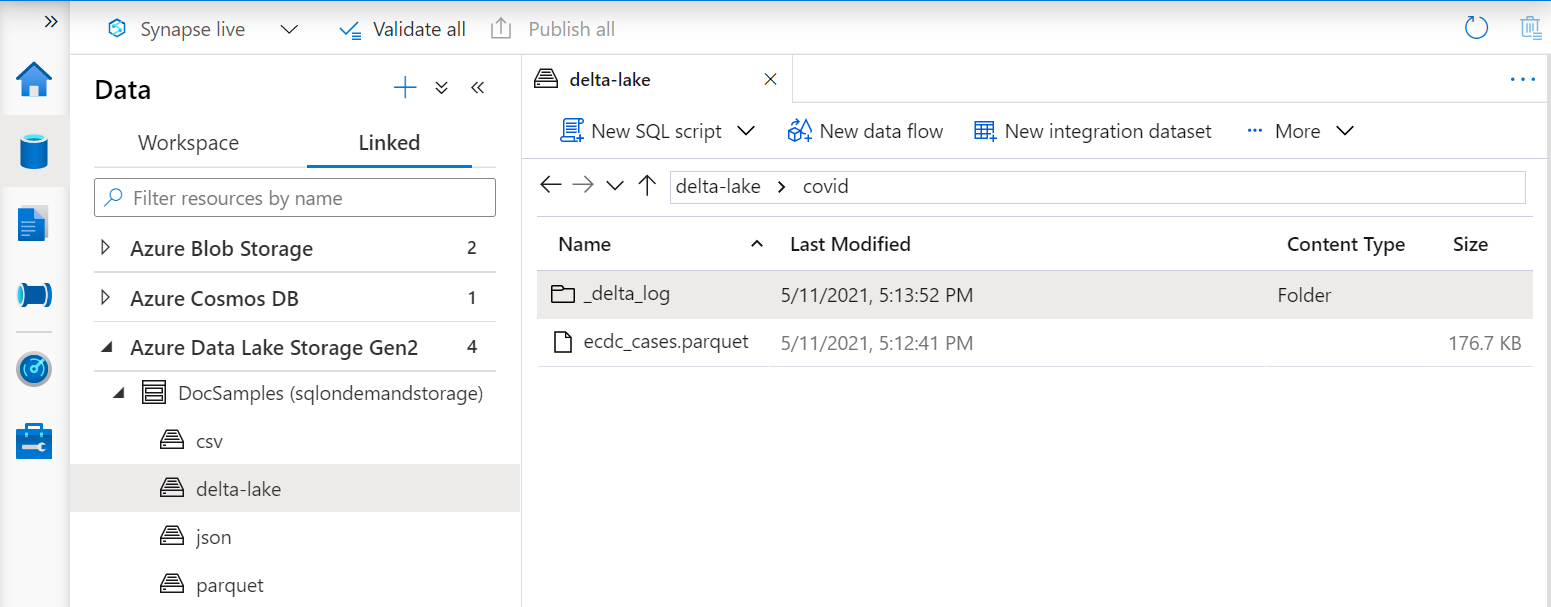
Jeśli nie masz tego podfolderu, nie używasz formatu usługi Delta Lake. Możesz przekonwertować zwykłe pliki Parquet w folderze na format usługi Delta Lake przy użyciu skryptu podobnego do następującego przykładowego skryptu języka Python platformy Apache Spark:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/covid`")
Aby zwiększyć wydajność zapytań, rozważ określenie jawnych typów w klauzuli WITH.
Uwaga
Bezserwerowa pula SQL usługi Synapse używa wnioskowania schematu do automatycznego określania kolumn i ich typów. Reguły wnioskowania schematu są takie same jak w przypadku plików Parquet. W przypadku mapowania typu usługi Delta Lake na natywny typ SQL mapowanie typu sprawdzania dla parquet.
Upewnij się, że masz dostęp do pliku. Jeśli plik jest chroniony przy użyciu klucza sygnatury dostępu współdzielonego lub niestandardowej tożsamości platformy Azure, musisz skonfigurować poświadczenia na poziomie serwera na potrzeby logowania sql.
Ważne
Upewnij się, że używasz sortowania bazy danych UTF-8 (na przykład Latin1_General_100_BIN2_UTF8), ponieważ wartości ciągów w plikach usługi Delta Lake są kodowane przy użyciu kodowania UTF-8.
Niezgodność między kodowaniem tekstu w pliku usługi Delta Lake a sortowaniem może spowodować nieoczekiwane błędy konwersji.
Domyślne sortowanie bieżącej bazy danych można łatwo zmienić przy użyciu następującej instrukcji języka T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_BIN2_UTF8; Aby uzyskać więcej informacji na temat sortowania, zobacz Typy sortowania obsługiwane dla usługi Synapse SQL.
Jawne określanie schematu
OPENROWSET Umożliwia jawne określenie kolumn, które mają być odczytywane z pliku przy użyciu WITH klauzuli :
SELECT TOP 10 *
FROM OPENROWSET(
BULK 'covid',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT = 'delta'
)
WITH ( date_rep date,
cases int,
geo_id varchar(6)
) as rows;
Dzięki jawnej specyfikacji schematu zestawu wyników można zminimalizować rozmiary typów i użyć bardziej precyzyjnych typów VARCHAR(6) dla kolumn ciągów zamiast pesymistycznej VARCHAR(1000). Minimalizacja typów może znacznie poprawić wydajność zapytań.
Ważne
Upewnij się, że jawnie określasz sortowanie UTF-8 (na przykład Latin1_General_100_BIN2_UTF8) dla wszystkich kolumn ciągu w WITH klauzuli lub ustaw sortowanie UTF-8 na poziomie bazy danych.
Niezgodność między kodowaniem tekstu w sortowaniu kolumn pliku i ciągu może spowodować nieoczekiwane błędy konwersji.
Domyślne sortowanie bieżącej bazy danych można łatwo zmienić przy użyciu następującej instrukcji języka T-SQL:
alter database current collate Latin1_General_100_BIN2_UTF8 Sortowanie typów kolumn można łatwo ustawić przy użyciu następującej definicji: geo_id varchar(6) collate Latin1_General_100_BIN2_UTF8
Zestaw danych
W tym przykładzie używany jest zestaw danych żółtych taksówek w nowym jorku. Oryginalny PARQUET zestaw danych jest konwertowany na DELTA format, a DELTA wersja jest używana w przykładach.
Wykonywanie zapytań dotyczących danych partycjonowanych
Zestaw danych podany w tym przykładzie jest podzielony (podzielony na partycje) na oddzielne podfoldery.
W przeciwieństwie do parquet, nie trzeba kierować określonych partycji przy użyciu FILEPATH funkcji . Funkcja OPENROWSET będzie identyfikować kolumny partycjonowania w strukturze folderów usługi Delta Lake i umożliwia bezpośrednie wykonywanie zapytań dotyczących danych przy użyciu tych kolumn. W tym przykładzie przedstawiono kwoty taryf według roku, miesiąca i payment_type w ciągu pierwszych trzech miesięcy 2017 r.
SELECT
YEAR(pickup_datetime) AS year,
passenger_count,
COUNT(*) AS cnt
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
WHERE
nyc.year = 2017
AND nyc.month IN (1, 2, 3)
AND pickup_datetime BETWEEN CAST('1/1/2017' AS datetime) AND CAST('3/31/2017' AS datetime)
GROUP BY
passenger_count,
YEAR(pickup_datetime)
ORDER BY
YEAR(pickup_datetime),
passenger_count;
Funkcja OPENROWSET wyeliminowa partycje, które nie pasują do klauzuli year i month w klauzuli where. Ta technika oczyszczania plików/partycji znacznie zmniejszy zestaw danych, poprawi wydajność i obniży koszt zapytania.
Nazwa folderu w OPENROWSET funkcji (yellow w tym przykładzie) jest połączona przy użyciu LOCATION elementu w DeltaLakeStorage źródle danych i musi odwoływać się do głównego folderu usługi Delta Lake zawierającego podfolder o nazwie _delta_log.
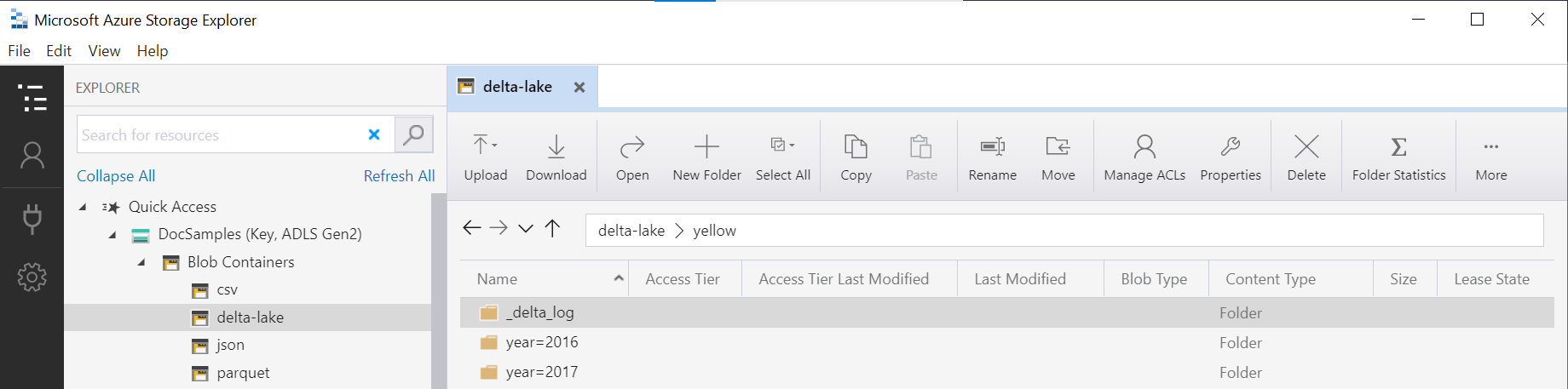
Jeśli nie masz tego podfolderu, nie używasz formatu usługi Delta Lake. Możesz przekonwertować zwykłe pliki Parquet w folderze na format usługi Delta Lake przy użyciu następującego skryptu języka Python platformy Apache Spark:
%%pyspark
from delta.tables import DeltaTable
deltaTable = DeltaTable.convertToDelta(spark, "parquet.`abfss://delta-lake@sqlondemandstorage.dfs.core.windows.net/yellow`", "year INT, month INT")
Drugi argument DeltaTable.convertToDeltaLake funkcji reprezentuje kolumny partycjonowania (rok i miesiąc), które są częścią wzorca folderu (year=*/month=* w tym przykładzie) i ich typów.
Ograniczenia
- Zapoznaj się z ograniczeniami i znanymi problemami na stronie samodzielnej pomocy bezserwerowej puli SQL usługi Synapse.
Powiązana zawartość
Przejdź do następnego artykułu, aby dowiedzieć się, jak wykonywać zapytania dotyczące typów zagnieżdżonych Parquet. Jeśli chcesz kontynuować tworzenie rozwiązania usługi Delta Lake, dowiedz się, jak tworzyć widoki lub tabele zewnętrzne w folderze usługi Delta Lake.