Jak używać zestawu OPENROWSET przy użyciu bezserwerowej puli SQL w usłudze Azure Synapse Analytics
Funkcja OPENROWSET(BULK...) umożliwia dostęp do plików w usłudze Azure Storage. OPENROWSET funkcja odczytuje zawartość zdalnego źródła danych (na przykład pliku) i zwraca zawartość jako zestaw wierszy. W ramach bezserwerowego zasobu puli SQL dostęp do dostawcy zestawów wierszy zbiorczych OPENROWSET jest uzyskiwany przez wywołanie funkcji OPENROWSET i określenie opcji BULK.
Funkcję OPENROWSET można odwołać w FROM klauzuli zapytania tak, jakby była to nazwa OPENROWSETtabeli . Obsługuje operacje zbiorcze za pośrednictwem wbudowanego dostawcy BULK, który umożliwia odczytywanie i zwracanie danych z pliku jako zestawu wierszy.
Uwaga
Funkcja OPENROWSET nie jest obsługiwana w dedykowanej puli SQL.
Źródło danych
Funkcja OPENROWSET w usłudze Synapse SQL odczytuje zawartość plików ze źródła danych. Źródło danych jest kontem usługi Azure Storage i może być jawnie przywołyane w OPENROWSET funkcji lub może być dynamicznie wnioskowane z adresu URL plików, które chcesz odczytać.
Funkcja OPENROWSET może opcjonalnie zawierać DATA_SOURCE parametr określający źródło danych zawierające pliki.
OPENROWSETbezDATA_SOURCEmożliwości bezpośredniego odczytywania zawartości plików z lokalizacji adresu URL określonej jakoBULKopcja:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
Jest to szybki i łatwy sposób odczytywania zawartości plików bez wstępnej konfiguracji. Ta opcja umożliwia korzystanie z opcji uwierzytelniania podstawowego w celu uzyskania dostępu do magazynu (Przekazywanie firmy Microsoft dla usługi Microsoft Entra logins i tokenu SAS dla identyfikatorów logowania SQL).
OPENROWSETDATA_SOURCEza pomocą polecenia można uzyskiwać dostęp do plików na określonym koncie magazynu:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]Ta opcja umożliwia skonfigurowanie lokalizacji konta magazynu w źródle danych i określenie metody uwierzytelniania, która ma być używana do uzyskiwania dostępu do magazynu.
Ważne
OPENROWSETbezDATA_SOURCEzapewnia szybki i łatwy sposób uzyskiwania dostępu do plików magazynu, ale oferuje ograniczone opcje uwierzytelniania. Na przykład podmioty zabezpieczeń firmy Microsoft Entra mogą uzyskiwać dostęp do plików tylko przy użyciu tożsamości Microsoft Entra lub publicznie dostępnych plików. Jeśli potrzebujesz bardziej zaawansowanych opcji uwierzytelniania, użyjDATA_SOURCEopcji i zdefiniuj poświadczenia, których chcesz użyć do uzyskiwania dostępu do magazynu.
Zabezpieczenia
Użytkownik bazy danych musi mieć ADMINISTER BULK OPERATIONS uprawnienia do korzystania z OPENROWSET funkcji.
Administrator magazynu musi również zezwolić użytkownikowi na dostęp do plików, podając prawidłowy token SAS lub włączając podmiot zabezpieczeń firmy Microsoft w celu uzyskania dostępu do plików magazynu. Dowiedz się więcej o kontroli dostępu do magazynu w tym artykule.
OPENROWSET Użyj następujących reguł, aby określić sposób uwierzytelniania w magazynie:
- W
OPENROWSETprzypadku bezDATA_SOURCEmechanizmu uwierzytelniania zależy od typu wywołującego.- Każdy użytkownik może używać
OPENROWSETbezDATA_SOURCEkonieczności odczytywania publicznie dostępnych plików w usłudze Azure Storage. - Identyfikatory logowania firmy Microsoft Entra mogą uzyskiwać dostęp do chronionych plików przy użyciu własnej tożsamości firmy Microsoft Entra, jeśli usługa Azure Storage umożliwia użytkownikowi Firmy Microsoft Entra dostęp do bazowych plików (na przykład jeśli obiekt wywołujący ma
Storage Readeruprawnienia do usługi Azure Storage). - Identyfikatory logowania SQL mogą być również używane
OPENROWSETbezDATA_SOURCEdostępu do publicznie dostępnych plików, plików chronionych przy użyciu tokenu SAS lub tożsamości zarządzanej obszaru roboczego usługi Synapse. Aby zezwolić na dostęp do plików magazynu, należy utworzyć poświadczenia o zakresie serwera.
- Każdy użytkownik może używać
- W
OPENROWSETprzypadkuDATA_SOURCEmechanizmu uwierzytelniania jest definiowany w poświadczeniu o zakresie bazy danych przypisanym do przywoływanych źródeł danych. Ta opcja umożliwia dostęp do publicznie dostępnego magazynu lub uzyskiwania dostępu do magazynu przy użyciu tokenu SAS, tożsamości zarządzanej obszaru roboczego lub tożsamości obiektu wywołującego firmy Microsoft Entra (jeśli obiekt wywołujący jest podmiotem zabezpieczeń firmy Microsoft). JeśliDATA_SOURCEodwołuje się do usługi Azure Storage, która nie jest publiczna, musisz utworzyć poświadczenia o zakresie bazy danych i odwołać się do niej,DATA SOURCEaby zezwolić na dostęp do plików magazynu.
Obiekt wywołujący musi mieć REFERENCES uprawnienia do poświadczeń, aby używać go do uwierzytelniania w magazynie.
Składnia
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
Argumenty
Istnieją trzy opcje plików wejściowych, które zawierają dane docelowe do wykonywania zapytań. Prawidłowe wartości to:
"CSV" — zawiera dowolny rozdzielany plik tekstowy z separatorami wierszy/kolumn. Dowolny znak może być używany jako separator pola, taki jak TSV: FIELDTERMINATOR = tab.
"PARQUET" — plik binarny w formacie Parquet.
"DELTA" — zestaw plików Parquet zorganizowanych w formacie usługi Delta Lake (wersja zapoznawcza).
Wartości z pustymi spacjami nie są prawidłowe. Na przykład "CSV" nie jest prawidłową wartością.
"unstructured_data_path"
Unstructured_data_path, która ustanawia ścieżkę do danych, może być ścieżką bezwzględną lub względną:
- Ścieżka bezwzględna w formacie
\<prefix>://\<storage_account_path>/\<storage_path>umożliwia użytkownikowi bezpośrednie odczytywanie plików. - Ścieżka względna w formacie
<storage_path>, który musi być używany z parametremDATA_SOURCEi opisuje wzorzec pliku w <storage_account_path> lokalizacji zdefiniowanej w plikuEXTERNAL DATA SOURCE.
Poniżej znajdziesz odpowiednie <wartości ścieżki> konta magazynu, które będą łączyć się z konkretnym zewnętrznym źródłem danych.
| Zewnętrzne źródło danych | Prefiks | Ścieżka konta magazynu |
|---|---|---|
| Azure Blob Storage | http[s] | <>storage_account.blob.core.windows.net/path/file |
| Azure Blob Storage | wasb[s] | <container>@<storage_account.blob.core.windows.net/path/file> |
| Azure Data Lake Store Gen1 | http[s] | <>storage_account.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <>storage_account.dfs.core.windows.net/path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <>file_system@<account_name.dfs.core.windows.net/path/file> |
"<storage_path>"
Określa ścieżkę w magazynie wskazującą folder lub plik, który chcesz odczytać. Jeśli ścieżka wskazuje kontener lub folder, wszystkie pliki będą odczytywane z tego określonego kontenera lub folderu. Pliki w podfolderach nie będą uwzględniane.
Za pomocą symboli wieloznacznych można użyć wielu plików lub folderów. Użycie wielu niebezpieczonych symboli wieloznacznych jest dozwolone.
Poniżej przedstawiono przykład odczytujący wszystkie pliki CSV rozpoczynające się od populacji ze wszystkich folderów rozpoczynających się od /csv/population:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
Jeśli określisz unstructured_data_path jako folder, zapytanie bezserwerowej puli SQL pobierze pliki z tego folderu.
Możesz poinstruować bezserwerową pulę SQL, aby przechodziła przez foldery, określając /* na końcu ścieżki, jak na przykład: https://sqlondemandstorage.blob.core.windows.net/csv/population/**
Uwaga
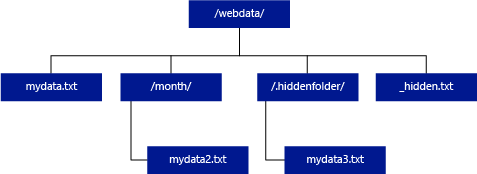
W przeciwieństwie do usług Hadoop i PolyBase bezserwerowa pula SQL nie zwraca podfolderów, chyba że określisz /** na końcu ścieżki. Podobnie jak w przypadku usług Hadoop i PolyBase, nie zwraca plików, dla których nazwa pliku zaczyna się podkreśleniem (_) ani kropką (.).
W poniższym przykładzie, jeśli unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/, zapytanie bezserwerowej puli SQL zwróci wiersze z mydata.txt. Nie zwróci mydata2.txt i mydata3.txt, ponieważ znajdują się one w podfolderze.
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
Klauzula WITH umożliwia określenie kolumn, które mają być odczytywane z plików.
W przypadku plików danych CSV, aby odczytać wszystkie kolumny, podaj nazwy kolumn i ich typy danych. Jeśli chcesz, aby podzbiór kolumn używał liczb porządkowych, aby wybrać kolumny z plików danych źródłowych według porządkowych. Kolumny będą powiązane z oznaczeniem porządkowym. Jeśli jest używana HEADER_ROW = TRUE, powiązanie kolumny jest wykonywane według nazwy kolumny zamiast położenia porządkowego.
Napiwek
Można również pominąć klauzulę WITH dla plików CSV. Typy danych zostaną automatycznie wywnioskowane z zawartości pliku. Możesz użyć HEADER_ROW argumentu, aby określić istnienie wiersza nagłówka, w którym nazwy kolumn będą odczytywane z wiersza nagłówka. Aby uzyskać szczegółowe informacje, sprawdź automatyczne odnajdywanie schematów.
W przypadku plików Parquet lub Delta Lake podaj nazwy kolumn, które pasują do nazw kolumn w plikach danych źródłowych. Kolumny będą powiązane według nazwy i uwzględnia wielkość liter. Jeśli klauzula WITH zostanie pominięta, zostaną zwrócone wszystkie kolumny z plików Parquet.
Ważne
W nazwach kolumn w plikach Parquet i Delta Lake jest rozróżniana wielkość liter. Jeśli określisz nazwę kolumny z wielkością liter inną niż wielkość liter nazwy kolumny w plikach,
NULLwartości zostaną zwrócone dla tej kolumny.
column_name = nazwa kolumny wyjściowej. Jeśli ta nazwa zostanie podana, zastąpi nazwę kolumny w pliku źródłowym i nazwę kolumny podaną w ścieżce JSON, jeśli istnieje. Jeśli json_path nie zostanie podana, zostanie ona automatycznie dodana jako "$.column_name". Sprawdź json_path argument pod kątem zachowania.
column_type = Typ danych dla kolumny wyjściowej. W tym miejscu odbędzie się niejawna konwersja typu danych.
column_ordinal = liczba porządkowa kolumny w plikach źródłowych. Ten argument jest ignorowany dla plików Parquet, ponieważ powiązanie jest wykonywane według nazwy. Poniższy przykład zwraca drugą kolumnę tylko z pliku CSV:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = wyrażenie ścieżki JSON do kolumny lub właściwości zagnieżdżonej. Domyślny tryb ścieżki jest opóźniony.
Uwaga
W trybie ścisłym zapytanie zakończy się niepowodzeniem z powodu błędu, jeśli podana ścieżka nie istnieje. Zapytanie w trybie lax powiedzie się, a wyrażenie ścieżki JSON zwróci wartość NULL.
<bulk_options>
FIELDTERMINATOR ='field_terminator'
Określa terminator pola, który ma być używany. Domyślnym terminatorem pola jest przecinek (",").
ROWTERMINATOR ='row_terminator''
Określa terminator wierszy do użycia. Jeśli terminator wierszy nie zostanie określony, zostanie użyty jeden z domyślnych terminatorów. Domyślne terminatory dla PARSER_VERSION = '1.0' to \r\n, \n i \r. Domyślne terminatory dla PARSER_VERSION = '2.0' to \r\n i \n.
Uwaga
Jeśli używasz PARSER_VERSION='1.0' i określ \n (nowy wiersz) jako terminator wiersza, zostanie on automatycznie poprzedzony znakiem \r (powrotu karetki), co powoduje zakończenie wiersza \r\n.
ESCAPE_CHAR = 'char'
Określa znak w pliku, który jest używany do ucieczki siebie i wszystkich wartości ograniczników w pliku. Jeśli znak ucieczki następuje po wartości innej niż sama lub którejkolwiek z wartości ograniczników, znak ucieczki zostanie porzucony podczas odczytywania wartości.
Parametr ESCAPECHAR zostanie zastosowany niezależnie od tego, czy parametr FIELDQUOTE jest czy nie jest włączony. Nie będzie używany do ucieczki znaku cudzysłów. Znak cudzysłów musi zostać uniknięta innym znakiem cudzysłów. Znak cudzysłów może pojawić się w wartości kolumny tylko wtedy, gdy wartość jest hermetyzowana znakami cudzysłów.
FIRSTROW = 'first_row'
Określa liczbę pierwszego wiersza do załadowania. Wartość domyślna to 1 i wskazuje pierwszy wiersz w określonym pliku danych. Liczby wierszy są określane przez zliczanie terminatorów wierszy. FIRSTROW jest oparty na 1.
FIELDQUOTE = 'field_quote'
Określa znak, który będzie używany jako znak cudzysłowu w pliku CSV. Jeśli nie zostanie określony, zostanie użyty znak cudzysłowu (").
DATA_COMPRESSION = 'data_compression_method'
Określa metodę kompresji. Obsługiwane tylko w PARSER_VERSION='1.0'. Obsługiwana jest następująca metoda kompresji:
- GZIP
PARSER_VERSION = 'parser_version'
Określa wersję analizatora, która ma być używana podczas odczytywania plików. Obecnie obsługiwane wersje analizatora CSV to 1.0 i 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
Analizator CSV w wersji 1.0 jest domyślny i rozbudowany. Wersja 2.0 została utworzona pod kątem wydajności i nie obsługuje wszystkich opcji i kodowań.
Specyfikator analizatora CSV w wersji 1.0:
- Następujące opcje nie są obsługiwane: HEADER_ROW.
- Domyślne terminatory to \r\n, \n i \r.
- Jeśli określisz \n (nowy wiersz) jako terminator wiersza, zostanie on automatycznie poprzedzony znakiem \r (powrotu karetki), co powoduje zakończenie wiersza \r\n.
Specyfikator analizatora CSV w wersji 2.0:
- Nie wszystkie typy danych są obsługiwane.
- Maksymalna długość kolumny znaków wynosi 8000.
- Maksymalny limit rozmiaru wiersza wynosi 8 MB.
- Następujące opcje nie są obsługiwane: DATA_COMPRESSION.
- Ciąg pusty ("") jest interpretowany jako pusty ciąg.
- Opcja DATEFORMAT SET nie jest honorowana.
- Obsługiwany format dla typu danych DATE: RRRR-MM-DD
- Obsługiwany format dla typu danych TIME: HH:MM:SS[.fractional seconds]
- Obsługiwany format dla typu danych DATETIME2: RRRR-MM-DD HH:MM:SS[.fractional seconds]
- Domyślne terminatory to \r\n i \n.
HEADER_ROW = { TRUE | FALSE }
Określa, czy plik CSV zawiera wiersz nagłówka. Wartość domyślna jest FALSE. obsługiwana w PARSER_VERSION='2.0'. Jeśli wartość TRUE, nazwy kolumn będą odczytywane z pierwszego wiersza zgodnie z argumentem FIRSTROW. Jeśli określono wartość TRUE i schemat przy użyciu funkcji WITH, powiązanie nazw kolumn będzie wykonywane według nazwy kolumny, a nie pozycji porządkowych.
DATAFILETYPE = { 'char' | "widechar" }
Określa kodowanie: char jest używany dla UTF8, widechar jest używany dla plików UTF16.
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | "code_page" }
Określa stronę kodów danych w pliku danych. Wartość domyślna to 65001 (kodowanie UTF-8). Zobacz więcej szczegółów na temat tej opcji tutaj.
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
Ta opcja spowoduje wyłączenie sprawdzania modyfikacji pliku podczas wykonywania zapytania i odczytanie plików, które są aktualizowane podczas uruchamiania zapytania. Jest to przydatna opcja, gdy trzeba odczytywać pliki tylko do dołączania, które są dołączane podczas uruchamiania zapytania. W dołączanych plikach istniejąca zawartość nie jest aktualizowana i dodawane są tylko nowe wiersze. W związku z tym prawdopodobieństwo nieprawidłowych wyników jest zminimalizowane w porównaniu z plikami z możliwością aktualizacji. Ta opcja może umożliwić odczytywanie często dołączanych plików bez obsługi błędów. Zobacz więcej informacji w sekcji wykonywanie zapytań dotyczących dołączanych plików CSV.
Opcje odrzucania
Uwaga
Funkcja odrzuconych wierszy jest dostępna w publicznej wersji zapoznawczej. Należy pamiętać, że funkcja odrzuconych wierszy działa w przypadku rozdzielonych plików tekstowych i PARSER_VERSION 1.0.
Można określić parametry odrzucania, które określają, w jaki sposób usługa będzie obsługiwać zanieczyszczone rekordy pobierane z zewnętrznego źródła danych. Rekord danych jest uznawany za "zanieczyszczony", jeśli rzeczywiste typy danych nie są zgodne z definicjami kolumn tabeli zewnętrznej.
Jeśli nie określisz ani nie zmienisz opcji odrzucenia, usługa używa wartości domyślnych. Usługa użyje opcji odrzucenia, aby określić liczbę wierszy, które można odrzucić, zanim rzeczywiste zapytanie zakończy się niepowodzeniem. Zapytanie zwróci (częściowe) wyniki do momentu przekroczenia progu odrzucenia. Następnie kończy się niepowodzeniem z odpowiednim komunikatem o błędzie.
MAXERRORS = reject_value
Określa liczbę wierszy, które można odrzucić przed niepowodzeniem zapytania. WARTOŚĆ MAXERRORS musi być liczbą całkowitą z zakresu od 0 do 2 147 483 647.
ERRORFILE_DATA_SOURCE = źródło danych
Określa źródło danych, w którym powinny zostać zapisane odrzucone wiersze i odpowiedni plik błędu.
ERRORFILE_LOCATION = lokalizacja katalogu
Określa katalog w DATA_SOURCE lub ERROR_FILE_DATASOURCE, jeśli określono, że odrzucone wiersze i odpowiedni plik błędu powinny zostać zapisane. Jeśli określona ścieżka nie istnieje, usługa utworzy jedną w Twoim imieniu. Katalog podrzędny jest tworzony z nazwą "rejectedrows". Znak "" gwarantuje, że katalog zostanie uniknięty dla innego przetwarzania danych, chyba że jawnie nazwany w parametrze location. W tym katalogu istnieje folder utworzony na podstawie czasu przesłania obciążenia w formacie YearMonthDay_HourMinuteSecond_StatementID (np. 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891). Możesz użyć identyfikatora instrukcji, aby skorelować folder z zapytaniem, które je wygenerowało. W tym folderze zapisywane są dwa pliki: error.json plik i plik danych.
error.json plik zawiera tablicę json z napotkanymi błędami związanymi z odrzuconymi wierszami. Każdy element reprezentujący błąd zawiera następujące atrybuty:
| Atrybut | opis |
|---|---|
| Błąd | Przyczyna odrzucenia wiersza. |
| Wiersz | Odrzucona liczba porządkowa wierszy w pliku. |
| Kolumna | Odrzucony numer porządkowy kolumny. |
| Wartość | Odrzucona wartość kolumny. Jeśli wartość jest większa niż 100 znaków, zostaną wyświetlone tylko pierwsze 100 znaków. |
| Plik | Ścieżka do pliku, do którego należy wiersz. |
Szybkie analizowanie tekstu rozdzielanego
Istnieją dwie wersje analizatora tekstu rozdzielanego, których można użyć. Analizator CSV w wersji 1.0 jest domyślny i jest bogaty w funkcję, podczas gdy analizator w wersji 2.0 jest tworzony pod kątem wydajności. Poprawa wydajności analizatora 2.0 pochodzi z zaawansowanych technik analizowania i wielowątkowego. Różnica szybkości będzie większa w miarę wzrostu rozmiaru pliku.
Automatyczne odnajdywanie schematów
Możesz łatwo wysyłać zapytania zarówno do plików CSV, jak i Parquet bez znajomości lub określania schematu, pomijając klauzulę WITH. Nazwy kolumn i typy danych zostaną wywnioskowane z plików.
Pliki Parquet zawierają metadane kolumn, które będą odczytywane, mapowania typów można znaleźć w mapowaniach typów dla Parquet. Sprawdź odczytywanie plików Parquet bez określania schematu dla przykładów.
W przypadku plików CSV nazwy kolumn można odczytać z wiersza nagłówka. Można określić, czy wiersz nagłówka istnieje przy użyciu argumentu HEADER_ROW. Jeśli HEADER_ROW = FALSE, nazwy kolumn ogólnych będą używane: C1, C2, ... Cn, gdzie n jest liczbą kolumn w pliku. Typy danych zostaną wywnioskowane z pierwszych 100 wierszy danych. Sprawdź odczytywanie plików CSV bez określania schematu dla przykładów.
Należy pamiętać, że jeśli odczytujesz jednocześnie liczbę plików, schemat zostanie wywnioskowany z pierwszej usługi plików pobieranej z magazynu. Może to oznaczać, że niektóre oczekiwane kolumny zostaną pominięte, ponieważ plik używany przez usługę do zdefiniowania schematu nie zawiera tych kolumn. W takim przypadku użyj klauzuli OPENROWSET WITH.
Ważne
Istnieją przypadki, gdy nie można wywnioskować odpowiedniego typu danych z powodu braku informacji, a zamiast tego zostanie użyty większy typ danych. Zapewnia to obciążenie wydajności i jest szczególnie ważne w przypadku kolumn znaków, które będą wnioskowane jako varchar(8000). Aby uzyskać optymalną wydajność, sprawdź typy danych wywnioskowanych i użyj odpowiednich typów danych.
Mapowanie typów dla parquet
Pliki Parquet i Delta Lake zawierają opisy typów dla każdej kolumny. W poniższej tabeli opisano sposób mapowania typów Parquet na typy natywne SQL.
| Typ Parquet | Typ logiczny Parquet (adnotacja) | Typ danych SQL |
|---|---|---|
| BOOLOWSKI | bitowe | |
| PLIK BINARNY/BYTE_ARRAY | varbinary | |
| PODWÓJNY | liczba zmiennoprzecinkowa | |
| SPŁAWIK | rzeczywiste | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | dane binarne | |
| DWÓJKOWY | UTF8 | varchar *(sortowanie UTF8) |
| DWÓJKOWY | STRUNA | varchar *(sortowanie UTF8) |
| DWÓJKOWY | ENUM | varchar *(sortowanie UTF8) |
| FIXED_LEN_BYTE_ARRAY | Identyfikator UUID | uniqueidentifier |
| DWÓJKOWY | DZIESIĘTNY | decimal |
| DWÓJKOWY | JSON | varchar(8000) *(sortowanie UTF8) |
| DWÓJKOWY | BSON | Nieobsługiwane |
| FIXED_LEN_BYTE_ARRAY | DZIESIĘTNY | decimal |
| BYTE_ARRAY | INTERWAŁ | Nieobsługiwane |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATE | data |
| INT32 | DZIESIĘTNY | decimal |
| INT32 | TIME (MILLIS) | time |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, false) | dziesiętne (20,0) |
| INT64 | DZIESIĘTNY | decimal |
| INT64 | CZAS (MIKROS) | time |
| INT64 | TIME (NANOS) | Nieobsługiwane |
| INT64 | SYGNATURA CZASOWA (znormalizowana do utc) (MILLIS/MICROS) | datetime2 |
| INT64 | SYGNATURA CZASOWA (nie znormalizowana do utc) (MILLIS/MICROS) | bigint — upewnij się, że jawnie dostosujesz bigint wartość z przesunięciem strefy czasowej przed przekonwertowaniem jej na wartość typu data/godzina. |
| INT64 | SYGNATURA CZASOWA (NANOS) | Nieobsługiwane |
| Typ złożony | LISTA | varchar(8000), serializowany do formatu JSON |
| Typ złożony | MAPA | varchar(8000), serializowany do formatu JSON |
Przykłady
Odczytywanie plików CSV bez określania schematu
Poniższy przykład odczytuje plik CSV zawierający wiersz nagłówka bez określania nazw kolumn i typów danych:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
Poniższy przykład odczytuje plik CSV, który nie zawiera wiersza nagłówka bez określania nazw kolumn i typów danych:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
Odczytywanie plików Parquet bez określania schematu
Poniższy przykład zwraca wszystkie kolumny pierwszego wiersza z zestawu danych spisu w formacie Parquet i bez określania nazw kolumn i typów danych:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
Odczytywanie plików usługi Delta Lake bez określania schematu
Poniższy przykład zwraca wszystkie kolumny pierwszego wiersza z zestawu danych spisu w formacie usługi Delta Lake i bez określania nazw kolumn i typów danych:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
Odczytywanie określonych kolumn z pliku CSV
Poniższy przykład zwraca tylko dwie kolumny z liczbami porządkowymi 1 i 4 z populacji*.csv plików. Ponieważ w plikach nie ma wiersza nagłówka, rozpoczyna odczytywanie z pierwszego wiersza:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
Odczytywanie określonych kolumn z pliku Parquet
Poniższy przykład zwraca tylko dwie kolumny pierwszego wiersza z zestawu danych spisu w formacie Parquet:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
Określanie kolumn przy użyciu ścieżek JSON
W poniższym przykładzie pokazano, jak można używać wyrażeń ścieżki JSON w klauzuli WITH i demonstruje różnicę między trybami ścieżek ścisłych i lax:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
Określanie wielu plików/folderów w ścieżce ZBIORCZEj
W poniższym przykładzie pokazano, jak można używać wielu ścieżek plików/folderów w parametrze BULK:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
Następne kroki
Aby uzyskać więcej przykładów, zobacz przewodnik Szybki start dotyczący magazynu danych zapytań, aby dowiedzieć się, jak odczytywać OPENROWSET formaty plików CSV, PARQUET, DELTA LAKE i JSON . Sprawdź najlepsze rozwiązania dotyczące osiągnięcia optymalnej wydajności. Możesz również dowiedzieć się, jak zapisać wyniki zapytania w usłudze Azure Storage przy użyciu instrukcji CETAS.