Wskazówki dotyczące projektowania dotyczące używania replikowanych tabel w puli SQL usługi Synapse
Ten artykuł zawiera zalecenia dotyczące projektowania replikowanych tabel w schemacie puli SQL usługi Synapse. Skorzystaj z tych zaleceń, aby zwiększyć wydajność zapytań, zmniejszając przenoszenie danych i złożoność zapytań.
Wymagania wstępne
W tym artykule założono, że znasz pojęcia dotyczące dystrybucji danych i przenoszenia danych w puli SQL. Aby uzyskać więcej informacji, zobacz artykuł dotyczący architektury .
W ramach projektowania tabel dowiedz się, jak najwięcej o danych i sposobie wykonywania zapytań dotyczących danych. Rozważmy na przykład następujące pytania:
- Jak duża jest tabela?
- Jak często jest odświeżona tabela?
- Czy mam tabele faktów i wymiarów w puli SQL?
Co to jest replikowana tabela?
Tabela replikowana zawiera pełną kopię tabeli dostępnej w każdym węźle obliczeniowym. Replikowanie tabeli eliminuje konieczność przesyłania danych między węzłami obliczeniowymi przed operacją sprzężenia lub agregacji. Ponieważ tabela ma wiele kopii, replikowane tabele działają najlepiej, gdy rozmiar tabeli jest mniejszy niż 2 GB skompresowany. 2 GB nie jest twardym limitem. Jeśli dane są statyczne i nie zmieniają się, można replikować większe tabele.
Na poniższym diagramie przedstawiono zreplikowana tabelę, która jest dostępna w każdym węźle obliczeniowym. W puli SQL replikowana tabela jest w pełni kopiowana do bazy danych dystrybucji w każdym węźle obliczeniowym.

Zreplikowane tabele działają dobrze w przypadku tabel wymiarów w schemacie gwiazdy. Tabele wymiarów są zwykle łączone z tabelami faktów, które są dystrybuowane inaczej niż tabela wymiarów. Wymiary są zwykle rozmiarem, który sprawia, że można przechowywać i obsługiwać wiele kopii. Wymiary przechowują opisowe dane, które zmieniają się powoli, takie jak nazwa i adres klienta oraz szczegóły produktu. Powoli zmieniający się charakter danych prowadzi do mniejszej konserwacji replikowanej tabeli.
Rozważ użycie zreplikowanej tabeli, gdy:
- Rozmiar tabeli na dysku jest mniejszy niż 2 GB, niezależnie od liczby wierszy. Aby znaleźć rozmiar tabeli, możesz użyć polecenia DBCC PDW_SHOWSPACEUSED :
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - Tabela jest używana w sprzężeniach, które w przeciwnym razie wymagają przenoszenia danych. Podczas łączenia tabel, które nie są dystrybuowane w tej samej kolumnie, na przykład tabeli rozproszonej przy użyciu skrótów do tabeli z działaniem okrężnym, przenoszenie danych jest wymagane do ukończenia zapytania. Jeśli jedna z tabel jest mała, rozważ zreplikowane tabele. W większości przypadków zalecamy używanie tabel replikowanych zamiast tabel okrężnych. Aby wyświetlić operacje przenoszenia danych w planach zapytań, użyj sys.dm_pdw_request_steps. BroadcastMoveOperation to typowa operacja przenoszenia danych, którą można wyeliminować przy użyciu replikowanej tabeli.
Zreplikowane tabele mogą nie przynieść najlepszej wydajności zapytań, gdy:
- Tabela zawiera częste operacje wstawiania, aktualizowania i usuwania. Operacje języka manipulowania danymi (DML) wymagają ponownego skompilowania replikowanej tabeli. Ponowne kompilowanie często może spowodować niższą wydajność.
- Pula SQL jest często skalowana. Skalowanie puli SQL zmienia liczbę węzłów obliczeniowych, co powoduje ponowne skompilowanie replikowanej tabeli.
- Tabela zawiera dużą liczbę kolumn, ale operacje na danych zwykle uzyskują dostęp tylko do niewielkiej liczby kolumn. W tym scenariuszu zamiast replikować całą tabelę, może być bardziej efektywne dystrybuowanie tabeli, a następnie utworzenie indeksu w często używanych kolumnach. Jeśli zapytanie wymaga przenoszenia danych, pula SQL przenosi tylko dane dla żądanych kolumn.
Napiwek
Aby uzyskać więcej wskazówek dotyczących indeksowania i replikowanych tabel, zobacz Ściągawka dla dedykowanej puli SQL (dawniej SQL DW) w usłudze Azure Synapse Analytics.
Używanie replikowanych tabel z prostymi predykatami zapytań
Zanim zdecydujesz się dystrybuować lub replikować tabelę, zastanów się nad typami zapytań, które mają być uruchamiane względem tabeli. Zawsze, gdy jest to możliwe,
- Używaj replikowanych tabel dla zapytań z prostymi predykatami zapytań, takimi jak równość lub nierówności.
- Użyj tabel rozproszonych dla zapytań ze złożonymi predykatami zapytań, takimi jak LIKE lub NOT LIKE.
Zapytania intensywnie korzystające z procesora CPU działają najlepiej, gdy praca jest dystrybuowana we wszystkich węzłach obliczeniowych. Na przykład zapytania uruchamiające obliczenia w każdym wierszu tabeli działają lepiej w tabelach rozproszonych niż zreplikowane tabele. Ponieważ replikowana tabela jest przechowywana w całości w każdym węźle obliczeniowym, zapytanie intensywnie korzystające z procesora CPU względem replikowanej tabeli jest uruchamiane względem całej tabeli w każdym węźle obliczeniowym. Dodatkowe obliczenia mogą spowolnić wydajność zapytań.
Na przykład to zapytanie ma złożony predykat. Działa szybciej, gdy dane są w tabeli rozproszonej zamiast zreplikowanej tabeli. W tym przykładzie dane mogą być rozproszone z działaniem okrężnym.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Konwertowanie istniejących tabel działania okrężnego na tabele replikowane
Jeśli masz już tabele okrężne, zalecamy przekonwertowanie ich na zreplikowane tabele, jeśli spełniają kryteria opisane w tym artykule. Zreplikowane tabele zwiększają wydajność w tabelach z działaniem okrężnym, ponieważ eliminują potrzebę przenoszenia danych. Tabela okrężna zawsze wymaga przenoszenia danych do sprzężeń.
W tym przykładzie użyto funkcji CTAS do zmiany DimSalesTerritory tabeli na zreplikowanej tabeli. Ten przykład działa niezależnie od tego, czy DimSalesTerritory jest rozproszony skrót, czy działanie okrężne.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Przykład wydajności zapytań dla działania okrężnego i replikowanego
Replikowana tabela nie wymaga przenoszenia danych do sprzężeń, ponieważ cała tabela jest już obecna w każdym węźle obliczeniowym. Jeśli tabele wymiarów są rozproszone w trybie okrężnym, sprzężenie kopiuje tabelę wymiarów w całości do każdego węzła obliczeniowego. Aby przenieść dane, plan zapytania zawiera operację o nazwie BroadcastMoveOperation. Ten typ operacji przenoszenia danych spowalnia wydajność zapytań i jest wyeliminowany przy użyciu replikowanych tabel. Aby wyświetlić kroki planu zapytania, użyj widoku katalogu systemu sys.dm_pdw_request_steps .
Na przykład w poniższym zapytaniu względem schematu AdventureWorks FactInternetSales tabela jest rozproszona skrótem. Tabele DimDate i DimSalesTerritory to mniejsze tabele wymiarów. To zapytanie zwraca łączną sprzedaż w Ameryka Północna dla roku obrachunkowego 2004:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
Utworzyliśmy DimDate ponownie tabele okrężne i DimSalesTerritory jako tabele z działaniem okrężnym. W związku z tym zapytanie pokazało następujący plan zapytania, który ma wiele operacji przenoszenia emisji:
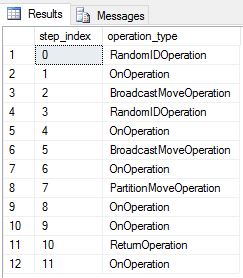
Utworzyliśmy DimDate ponownie tabele replikowane i DimSalesTerritory uruchomiliśmy je ponownie. Wynikowy plan zapytania jest znacznie krótszy i nie ma żadnych ruchów emisji.
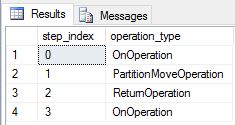
Zagadnienia dotyczące wydajności modyfikowania replikowanych tabel
Pula SQL implementuje zreplikowana tabelę, utrzymując wersję główną tabeli. Kopiuje wersję główną do pierwszej bazy danych dystrybucji w każdym węźle obliczeniowym. Po zmianie wersja główna zostanie najpierw zaktualizowana, a następnie ponownie skompilowane tabele w każdym węźle obliczeniowym. Ponowne kompilowanie replikowanej tabeli obejmuje kopiowanie tabeli do każdego węzła obliczeniowego, a następnie kompilowanie indeksów. Na przykład replikowana tabela na dw2000c ma pięć kopii danych. Kopia główna i pełna kopia w każdym węźle obliczeniowym. Wszystkie dane są przechowywane w bazach danych dystrybucji. Pula SQL używa tego modelu do obsługi szybszych instrukcji modyfikacji danych i elastycznych operacji skalowania.
Ponowne kompilowanie asynchroniczne jest wyzwalane przez pierwsze zapytanie względem replikowanej tabeli po:
- Dane są ładowane lub modyfikowane
- Wystąpienie usługi Synapse SQL jest skalowane na inny poziom
- Zaktualizowano definicję tabeli
Ponowne kompilacje nie są wymagane po:
- Operacja wstrzymywania
- Wznów operację
Ponowne kompilowanie nie następuje natychmiast po zmodyfikowaniu danych. Zamiast tego ponowne kompilowanie jest wyzwalane przy pierwszym wybraniu zapytania z tabeli. Zapytanie, które wyzwoliło ponowną kompilację, odczytuje natychmiast z wersji głównej tabeli, podczas gdy dane są asynchronicznie kopiowane do każdego węzła obliczeniowego. Do czasu ukończenia kopiowania danych kolejne zapytania będą nadal używać głównej wersji tabeli. Jeśli jakiekolwiek działanie ma miejsce w przypadku replikowanej tabeli, która wymusza kolejną ponowną kompilację, kopia danych zostanie unieważniona, a następna instrukcja select wyzwoli skopiowanie danych ponownie.
Używanie indeksów konserwatywnie
Standardowe praktyki indeksowania mają zastosowanie do replikowanych tabel. Pula SQL ponownie kompiluje każdy zreplikowany indeks tabeli w ramach odbudowy. Używaj indeksów tylko wtedy, gdy wydajność przewyższa koszt odbudowy indeksów.
Ładowanie danych wsadowych
Podczas ładowania danych do replikowanych tabel spróbuj zminimalizować ponowne kompilowanie przez dzielenie obciążeń na partie. Przed uruchomieniem instrukcji select wykonaj wszystkie obciążenia wsadowe.
Na przykład ten wzorzec ładowania ładuje dane z czterech źródeł i wywołuje cztery ponowne kompilacje.
- Załaduj ze źródła 1.
- Wybierz instrukcję wyzwalaczy ponownej kompilacji 1.
- Załaduj ze źródła 2.
- Wybierz wyzwalacze instrukcji skompiluj ponownie 2.
- Załaduj ze źródła 3.
- Wybierz wyzwalacze instrukcji skompiluj ponownie 3.
- Załaduj ze źródła 4.
- Wybierz wyzwalacze instrukcji ponownej kompilacji 4.
Na przykład ten wzorzec ładowania ładuje dane z czterech źródeł, ale wywołuje tylko jedną ponowną kompilację.
- Załaduj ze źródła 1.
- Załaduj ze źródła 2.
- Załaduj ze źródła 3.
- Załaduj ze źródła 4.
- Wybierz wyzwalacze instrukcji ponownej kompilacji.
Ponowne kompilowanie replikowanej tabeli po załadowaniu wsadowym
Aby zapewnić spójne czasy wykonywania zapytań, rozważ wymuszenie kompilacji replikowanych tabel po załadowaniu wsadowym. W przeciwnym razie pierwsze zapytanie będzie nadal używać przenoszenia danych do ukończenia zapytania.
Operacja „Skompilowana pamięć podręczna tabel” może wykonać maksymalnie dwie operacje jednocześnie. Jeśli na przykład spróbujesz ponownie skompilować pamięć podręczną dla pięciu tabel, system użyje statycznegorc20 (którego nie można zmodyfikować) w celu współbieżnego kompilowania dwóch tabel w tym czasie. Dlatego zaleca się unikanie używania dużych replikowanych tabel przekraczających 2 GB, ponieważ może to spowolnić ponowne kompilowanie pamięci podręcznej w węzłach i wydłużyć całkowity czas.
To zapytanie używa sys.pdw_replicated_table_cache_state widoku DMV, aby wyświetlić listę zreplikowanych tabel, które zostały zmodyfikowane, ale nie zostały ponownie skompilowane.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Aby wyzwolić ponowną kompilację, uruchom następującą instrukcję w każdej tabeli w poprzednich danych wyjściowych.
SELECT TOP 1 * FROM [ReplicatedTable]
Uwaga
Jeśli planujesz ponownie skompilować statystyki niebuforowanej tabeli zreplikowanej, przed wyzwoleniem pamięci podręcznej pamiętaj o zaktualizowaniu statystyk. Aktualizowanie statystyk spowoduje unieważnienie pamięci podręcznej, dlatego sekwencja jest ważna.
Przykład: Rozpocznij od UPDATE STATISTICS, a następnie wyzwól ponowne kompilowanie pamięci podręcznej. W poniższych przykładach poprawna próbka aktualizuje statystyki, a następnie wyzwala ponowne kompilowanie pamięci podręcznej.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Aby monitorować proces ponownego kompilowania, można użyć sys.dm_pdw_exec_requests, gdzie command rozpocznie się od "BuildReplicatedTableCache". Na przykład:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Napiwek
Zapytania dotyczące rozmiaru tabel mogą służyć do sprawdzania, które tabele mają zreplikowane zasady dystrybucji i które są większe niż 2 GB.
Następne kroki
Aby utworzyć zreplikowana tabelę, użyj jednej z następujących instrukcji:
Aby zapoznać się z omówieniem tabel rozproszonych, zobacz tabele rozproszone.