Wprowadzenie do instalacji/odinstalowywanie interfejsów API w usłudze Azure Synapse Analytics
Zespół usługi Azure Synapse Studio utworzył dwa nowe interfejsy API instalacji/odinstalowywanie w pakiecie Microsoft Spark Utilities (mssparkutils). Te interfejsy API umożliwiają dołączanie magazynu zdalnego (Azure Blob Storage lub Azure Data Lake Storage Gen2) do wszystkich węzłów roboczych (węzłów sterownika i węzłów roboczych). Po zainstalowaniu magazynu można użyć lokalnego interfejsu API plików, aby uzyskać dostęp do danych tak, jakby był przechowywany w lokalnym systemie plików. Aby uzyskać więcej informacji, zobacz Wprowadzenie do programu Microsoft Spark Utilities.
W tym artykule pokazano, jak używać interfejsów API instalacji/odinstalowania w obszarze roboczym. Dowiesz się:
- Jak zainstalować usługę Data Lake Storage Gen2 lub Blob Storage.
- Jak uzyskać dostęp do plików w punkcie instalacji za pośrednictwem lokalnego interfejsu API systemu plików.
- Jak uzyskać dostęp do plików w punkcie instalacji przy użyciu interfejsu
mssparkutils fsAPI. - Jak uzyskać dostęp do plików w punkcie instalacji przy użyciu interfejsu API odczytu platformy Spark.
- Jak odinstalować punkt instalacji.
Ostrzeżenie
Instalowanie udziału plików platformy Azure jest tymczasowo wyłączone. Zamiast tego możesz użyć instalowania usługi Data Lake Storage Gen2 lub usługi Azure Blob Storage, zgodnie z opisem w następnej sekcji.
Magazyn usługi Azure Data Lake Storage Gen1 nie jest obsługiwany. Migrację do usługi Data Lake Storage Gen2 można przeprowadzić, postępując zgodnie ze wskazówkami dotyczącymi migracji usługi Azure Data Lake Storage Gen1 do generacji 2 przed użyciem interfejsów API instalacji.
Instalowanie magazynu
W tej sekcji pokazano, jak zainstalować usługę Data Lake Storage Gen2 krok po kroku jako przykład. Instalowanie usługi Blob Storage działa podobnie.
W przykładzie przyjęto założenie, że masz jedno konto usługi Data Lake Storage Gen2 o nazwie storegen2. Konto ma jeden kontener o nazwie mycontainer , do którego chcesz zainstalować aplikację /test w puli platformy Spark.
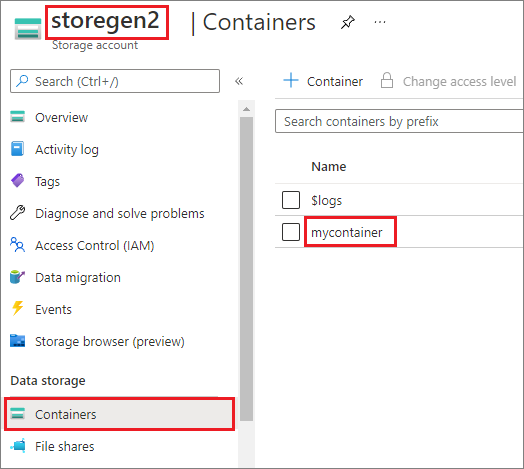
Aby zainstalować kontener o nazwie mycontainer, najpierw należy sprawdzić, mssparkutils czy masz uprawnienia dostępu do kontenera. Obecnie usługa Azure Synapse Analytics obsługuje trzy metody uwierzytelniania dla operacji instalacji wyzwalacza: linkedService, accountKeyi sastoken.
Instalowanie przy użyciu połączonej usługi (zalecane)
Zalecamy instalację wyzwalacza za pośrednictwem połączonej usługi. Ta metoda pozwala uniknąć wycieków zabezpieczeń, ponieważ mssparkutils nie przechowuje żadnych wartości wpisów tajnych ani uwierzytelniania.
mssparkutils Zamiast tego zawsze pobiera wartości uwierzytelniania z połączonej usługi w celu żądania danych obiektów blob z magazynu zdalnego.
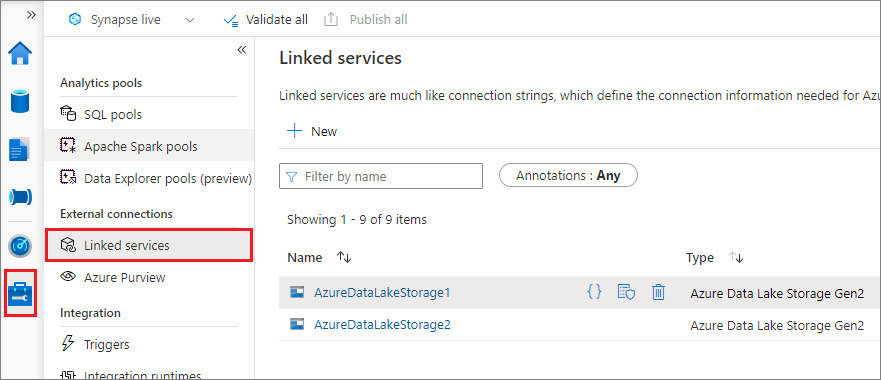
Możesz utworzyć połączoną usługę dla usługi Data Lake Storage Gen2 lub Blob Storage. Obecnie usługa Azure Synapse Analytics obsługuje dwie metody uwierzytelniania podczas tworzenia połączonej usługi:
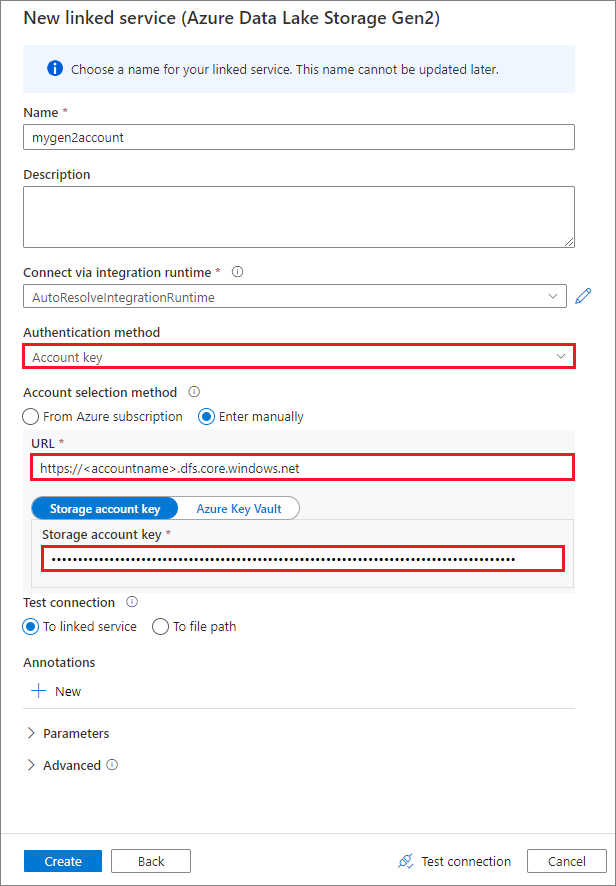
Tworzenie połączonej usługi przy użyciu klucza konta
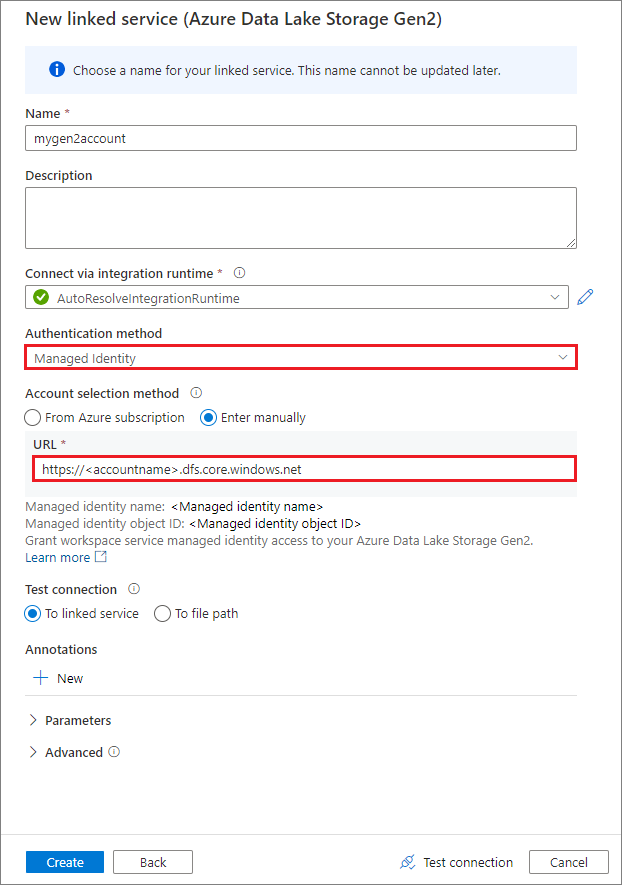
Tworzenie połączonej usługi przy użyciu tożsamości zarządzanej przypisanej przez system
Ważne
- Jeśli powyższa utworzona połączona usługa z usługą Azure Data Lake Storage Gen2 używa zarządzanego prywatnego punktu końcowego (z identyfikatorem URI systemu dfs ), należy utworzyć kolejny pomocniczy prywatny punkt końcowy zarządzany przy użyciu opcji usługi Azure Blob Storage (z identyfikatorem URI obiektu blob ), aby upewnić się, że wewnętrzny kod fsspec/adlfs może nawiązać połączenie przy użyciu interfejsu BlobServiceClient .
- W przypadku nieprawidłowego skonfigurowania pomocniczego zarządzanego prywatnego punktu końcowego zostanie wyświetlony komunikat o błędzie, taki jak ServiceRequestError: Nie można nawiązać połączenia z hostem [storageaccountname].blob.core.windows.net:443 ssl:True [Nazwa lub usługa nie jest znana]
Uwaga
Jeśli utworzysz połączoną usługę przy użyciu tożsamości zarządzanej jako metody uwierzytelniania, upewnij się, że plik MSI obszaru roboczego ma rolę Współautor danych obiektu blob usługi Storage zainstalowanego kontenera.
Po pomyślnym utworzeniu połączonej usługi można łatwo zainstalować kontener w puli Spark przy użyciu następującego kodu w języku Python:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Uwaga
Może być konieczne zaimportowanie mssparkutils , jeśli nie jest dostępne:
from notebookutils import mssparkutils
Nie zalecamy instalowania folderu głównego niezależnie od używanej metody uwierzytelniania.
Parametry instalacji:
- fileCacheTimeout: obiekty blob będą domyślnie buforowane w lokalnym folderze tymczasowym przez 120 sekund. W tym czasie program blobfuse nie sprawdzi, czy plik jest aktualny, czy nie. Parametr można ustawić tak, aby zmienić domyślny limit czasu. Gdy wielu klientów modyfikuje pliki jednocześnie, aby uniknąć niespójności między plikami lokalnymi i zdalnymi, zalecamy skrócenie czasu pamięci podręcznej, a nawet zmianę jej na 0 i zawsze pobieranie najnowszych plików z serwera.
- limit czasu: limit czasu operacji instalacji wynosi domyślnie 120 sekund. Parametr można ustawić tak, aby zmienić domyślny limit czasu. W przypadku zbyt wielu funkcji wykonawczych lub limitu czasu instalacji zalecamy zwiększenie wartości.
- zakres: parametr zakresu służy do określania zakresu instalacji. Wartość domyślna to "job". Jeśli zakres jest ustawiony na "zadanie", instalacja jest widoczna tylko dla bieżącego klastra. Jeśli zakres jest ustawiony na "obszar roboczy", instalacja jest widoczna dla wszystkich notesów w bieżącym obszarze roboczym, a punkt instalacji zostanie utworzony automatycznie, jeśli nie istnieje. Dodaj te same parametry do interfejsu API odinstalowania, aby odinstalować punkt instalacji. Instalacja na poziomie obszaru roboczego jest obsługiwana tylko w przypadku uwierzytelniania połączonej usługi.
Możesz użyć tych parametrów w następujący sposób:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Instalowanie za pomocą tokenu sygnatury dostępu współdzielonego lub klucza konta
Oprócz instalowania za pośrednictwem połączonej usługi program mssparkutils obsługuje jawne przekazywanie klucza konta lub tokenu sygnatury dostępu współdzielonego (SAS) jako parametru w celu zainstalowania obiektu docelowego.
Ze względów bezpieczeństwa zalecamy przechowywanie kluczy konta lub tokenów SAS w usłudze Azure Key Vault (jak pokazano na poniższym przykładowym zrzucie ekranu). Następnie możesz je pobrać przy użyciu interfejsu mssparkutil.credentials.getSecret API. Aby uzyskać więcej informacji, zobacz Zarządzanie kluczami konta magazynu przy użyciu usługi Key Vault i interfejsu wiersza polecenia platformy Azure (starsza wersja).
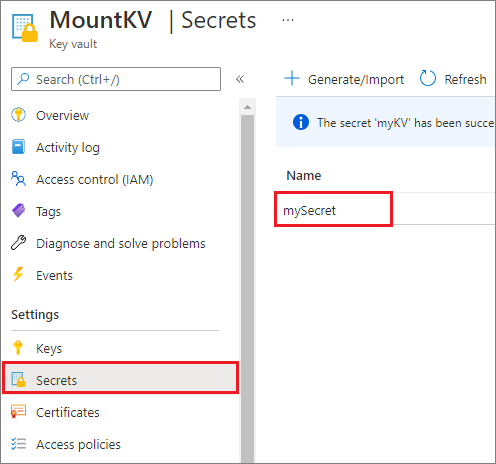
Oto przykładowy kod:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Uwaga
Ze względów bezpieczeństwa nie przechowuj poświadczeń w kodzie.
Uzyskiwanie dostępu do plików w punkcie instalacji przy użyciu interfejsu API mssparkutils fs
Głównym celem operacji instalacji jest umożliwianie klientom dostępu do danych przechowywanych na koncie magazynu zdalnego przy użyciu lokalnego interfejsu API systemu plików. Dostęp do danych można również uzyskać przy użyciu interfejsu mssparkutils fs API z instalowaną ścieżką jako parametrem. Format ścieżki używany w tym miejscu jest nieco inny.
Zakładając, że kontener usługi Data Lake Storage Gen2 został zainstalowany w usłudze mycontainer do /test przy użyciu interfejsu API instalacji. Podczas uzyskiwania dostępu do danych za pośrednictwem lokalnego interfejsu API systemu plików:
- W przypadku wersji platformy Spark mniejszej lub równej 3.3 format ścieżki to
/synfs/{jobId}/test/{filename}. - W przypadku wersji platformy Spark większej lub równej 3.4 format ścieżki to
/synfs/notebook/{jobId}/test/{filename}.
Zalecamy użycie elementu , mssparkutils.fs.getMountPath() aby uzyskać dokładną ścieżkę:
path = mssparkutils.fs.getMountPath("/test")
Uwaga
Podczas instalowania magazynu z workspace zakresem punkt instalacji jest tworzony w folderze /synfs/workspace . I musisz użyć mssparkutils.fs.getMountPath("/test", "workspace") polecenia , aby uzyskać dokładną ścieżkę.
Jeśli chcesz uzyskać dostęp do danych przy użyciu interfejsu mssparkutils fs API, format ścieżki wygląda następująco: synfs:/notebook/{jobId}/test/{filename}. Można zobaczyć, że synfs jest używany jako schemat w tym przypadku, zamiast części zainstalowanej ścieżki. Oczywiście można również użyć lokalnego schematu systemu plików, aby uzyskać dostęp do danych. Na przykład file:/synfs/notebook/{jobId}/test/{filename}.
W poniższych trzech przykładach pokazano, jak uzyskać dostęp do pliku ze ścieżką punktu instalacji przy użyciu polecenia mssparkutils fs.
Katalogi listy:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Odczytywanie zawartości pliku:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Utwórz katalog:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Uzyskiwanie dostępu do plików w punkcie instalacji przy użyciu interfejsu API odczytu platformy Spark
Możesz podać parametr, aby uzyskać dostęp do danych za pośrednictwem interfejsu API odczytu platformy Spark. Format ścieżki jest taki sam, gdy używasz interfejsu mssparkutils fs API.
Odczytywanie pliku z zainstalowanego konta magazynu usługi Data Lake Storage Gen2
W poniższym przykładzie przyjęto założenie, że konto magazynu usługi Data Lake Storage Gen2 zostało już zainstalowane, a następnie odczytasz plik przy użyciu ścieżki instalacji:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Uwaga
Podczas instalowania magazynu przy użyciu połączonej usługi należy zawsze jawnie ustawić konfigurację połączonej usługi spark przed użyciem schematu synfs w celu uzyskania dostępu do danych. Aby uzyskać szczegółowe informacje, zobacz Magazyn usługi ADLS Gen2 z połączonymi usługami .
Odczytywanie pliku z zainstalowanego konta usługi Blob Storage
Jeśli konto usługi Blob Storage jest zainstalowane i chcesz uzyskać do niego dostęp przy użyciu mssparkutils interfejsu API platformy Spark lub interfejsu API platformy Spark, musisz jawnie skonfigurować token SAS za pomocą konfiguracji platformy Spark przed podjęciem próby zainstalowania kontenera przy użyciu interfejsu API instalacji:
Aby uzyskać dostęp do konta usługi Blob Storage przy użyciu interfejsu
mssparkutilsAPI platformy Spark lub interfejsu API platformy Spark po zainstalowaniu wyzwalacza, zaktualizuj konfigurację platformy Spark, jak pokazano w poniższym przykładzie kodu. Ten krok można pominąć, jeśli chcesz uzyskać dostęp do konfiguracji platformy Spark tylko przy użyciu lokalnego interfejsu API plików po zainstalowaniu.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Utwórz połączoną usługę
myblobstorageaccounti zainstaluj konto usługi Blob Storage przy użyciu połączonej usługi:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Zainstaluj kontener usługi Blob Storage, a następnie odczytaj plik przy użyciu ścieżki instalacji za pośrednictwem lokalnego interfejsu API plików:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Odczytywanie danych z zainstalowanego kontenera usługi Blob Storage za pośrednictwem interfejsu API odczytu platformy Spark:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Odinstalowywanie punktu instalacji
Użyj następującego kodu, aby odinstalować punkt instalacji (/test w tym przykładzie):
mssparkutils.fs.unmount("/test")
Znane ograniczenia
Mechanizm odinstalowania nie jest automatyczny. Po zakończeniu działania aplikacji, aby odinstalować punkt instalacji, aby zwolnić miejsce na dysku, musisz jawnie wywołać odinstalowywanie interfejsu API w kodzie. W przeciwnym razie punkt instalacji nadal będzie istnieć w węźle po zakończeniu działania aplikacji.
Instalowanie konta magazynu usługi Data Lake Storage Gen1 nie jest obecnie obsługiwane.