Wprowadzenie do narzędzi Microsoft Spark
Microsoft Spark Utilities (MSSparkUtils) to wbudowany pakiet ułatwiający łatwe wykonywanie typowych zadań. Narzędzia MSSparkUtils umożliwiają pracę z systemami plików, uzyskiwanie zmiennych środowiskowych, łączenie notesów i pracę z wpisami tajnymi. Narzędzia MSSparkUtils są dostępne w PySpark (Python)potokach , Scala, .NET Spark (C#)i i R (Preview) Synapse.
Wymagania wstępne
Konfigurowanie dostępu do usługi Azure Data Lake Storage Gen2
Notesy usługi Synapse używają przekazywania usługi Microsoft Entra w celu uzyskania dostępu do kont usługi ADLS Gen2. Aby uzyskać dostęp do konta usługi ADLS Gen2 (lub folderu), musisz być współautorem danych obiektu blob usługi Storage.
Potoki usługi Synapse używają tożsamości usługi zarządzanej (MSI) obszaru roboczego do uzyskiwania dostępu do kont magazynu. Aby używać narzędzi MSSparkUtils w działaniach potoku, tożsamość obszaru roboczego musi być współautorem danych obiektu blob usługi Storage, aby uzyskać dostęp do konta usługi ADLS Gen2 (lub folderu).
Wykonaj następujące kroki, aby upewnić się, że identyfikator Entra firmy Microsoft i plik MSI obszaru roboczego mają dostęp do konta usługi ADLS Gen2:
Otwórz witrynę Azure Portal i konto magazynu, do którego chcesz uzyskać dostęp. Możesz przejść do określonego kontenera, do którego chcesz uzyskać dostęp.
Wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami) z panelu po lewej stronie.
Kliknij pozycję Dodaj>Dodaj przypisanie roli, aby otworzyć stronę Dodawanie przypisania roli.
Przypisz następującą rolę. Aby uzyskać szczegółowe instrukcje, zobacz Przypisywanie ról platformy Azure przy użyciu witryny Azure Portal.
Ustawienie Wartość Rola Współautor danych w usłudze Blob Storage Przypisz dostęp do IDENTYFIKATOR UŻYTKOWNIKA i TOŻSAMOŚĆ ZARZĄDZANA Elementy członkowskie twoje konto Microsoft Entra i tożsamość obszaru roboczego Uwaga
Nazwa tożsamości zarządzanej jest również nazwą obszaru roboczego.

Wybierz pozycję Zapisz.
Dostęp do danych w usłudze ADLS Gen2 można uzyskać za pomocą usługi Synapse Spark za pomocą następującego adresu URL:
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Konfigurowanie dostępu do usługi Azure Blob Storage
Usługa Synapse używa sygnatury dostępu współdzielonego (SAS) do uzyskiwania dostępu do usługi Azure Blob Storage. Aby uniknąć uwidaczniania kluczy SAS w kodzie, zalecamy utworzenie nowej połączonej usługi w obszarze roboczym usługi Synapse na koncie usługi Azure Blob Storage, do którego chcesz uzyskać dostęp.
Wykonaj następujące kroki, aby dodać nową połączoną usługę dla konta usługi Azure Blob Storage:
- Otwórz program Azure Synapse Studio.
- Wybierz pozycję Zarządzaj w panelu po lewej stronie i wybierz pozycję Połączone usługi w obszarze Połączenia zewnętrzne.
- Wyszukaj usługę Azure Blob Storage w panelu Nowa połączona usługa po prawej stronie.
- Wybierz Kontynuuj.
- Wybierz konto usługi Azure Blob Storage, aby uzyskać dostęp i skonfigurować połączoną nazwę usługi. Zasugeruj użycie klucza konta dla metody uwierzytelniania.
- Wybierz pozycję Testuj połączenie , aby sprawdzić, czy ustawienia są poprawne.
- Wybierz pozycję Utwórz najpierw i kliknij pozycję Opublikuj wszystko , aby zapisać zmiany.
Dostęp do danych w usłudze Azure Blob Storage można uzyskać za pomocą usługi Synapse Spark, korzystając z następującego adresu URL:
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
Oto przykład kodu:
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Konfigurowanie dostępu do usługi Azure Key Vault
Możesz dodać usługę Azure Key Vault jako połączoną usługę, aby zarządzać poświadczeniami w usłudze Synapse. Wykonaj następujące kroki, aby dodać usługę Azure Key Vault jako połączoną usługę Synapse:
Otwórz program Azure Synapse Studio.
Wybierz pozycję Zarządzaj w panelu po lewej stronie i wybierz pozycję Połączone usługi w obszarze Połączenia zewnętrzne.
Wyszukaj usługę Azure Key Vault w panelu Nowa połączona usługa po prawej stronie.
Wybierz konto usługi Azure Key Vault, aby uzyskać dostęp i skonfigurować połączoną nazwę usługi.
Wybierz pozycję Testuj połączenie , aby sprawdzić, czy ustawienia są poprawne.
Wybierz pozycję Utwórz najpierw, a następnie kliknij pozycję Opublikuj wszystko , aby zapisać zmianę.
Notesy usługi Synapse używają przekazywania usługi Microsoft Entra w celu uzyskania dostępu do usługi Azure Key Vault. Potoki usługi Synapse używają tożsamości obszaru roboczego (MSI) do uzyskiwania dostępu do usługi Azure Key Vault. Aby upewnić się, że kod działa zarówno w notesie, jak i w potoku usługi Synapse, zalecamy przyznanie uprawnień dostępu do wpisu tajnego zarówno dla konta Microsoft Entra, jak i tożsamości obszaru roboczego.
Wykonaj następujące kroki, aby udzielić tajnego dostępu do tożsamości obszaru roboczego:
- Otwórz witrynę Azure Portal i usługę Azure Key Vault, do której chcesz uzyskać dostęp.
- Wybierz zasady dostępu z panelu po lewej stronie.
- Wybierz pozycję Dodaj zasady dostępu:
- Wybierz pozycję Klucz, Wpis tajny i Zarządzanie certyfikatami jako szablon konfiguracji.
- Wybierz swoje konto Microsoft Entra i tożsamość obszaru roboczego (taką samą jak nazwa obszaru roboczego) w wybierz podmiot zabezpieczeń lub upewnij się, że jest już przypisana.
- Wybierz pozycję Wybierz i dodaj.
- Wybierz przycisk Zapisz, aby zatwierdzić zmiany.
Narzędzia systemu plików
mssparkutils.fs Udostępnia narzędzia do pracy z różnymi systemami plików, w tym z usługą Azure Data Lake Storage Gen2 (ADLS Gen2) i usługą Azure Blob Storage. Upewnij się, że odpowiednio skonfigurowaliśmy dostęp do usług Azure Data Lake Storage Gen2 i Azure Blob Storage .
Uruchom następujące polecenia, aby uzyskać przegląd dostępnych metod:
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
Wyniki:
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
Lista plików
Wyświetl listę zawartości katalogu.
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
Wyświetlanie właściwości pliku
Zwraca właściwości pliku, w tym nazwę pliku, ścieżkę pliku, rozmiar pliku, czas modyfikacji pliku oraz to, czy jest to katalog i plik.
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
Tworzenie nowego katalogu
Tworzy dany katalog, jeśli nie istnieje i jakiekolwiek niezbędne katalogi nadrzędne.
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
Kopiuj plik
Kopiuje plik lub katalog. Obsługuje kopiowanie między systemami plików.
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
Wydajny plik kopiowania
Ta metoda zapewnia szybszy sposób kopiowania lub przenoszenia plików, szczególnie dużych ilości danych.
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Uwaga
Metoda obsługuje tylko w środowisku Azure Synapse Runtime dla platformy Apache Spark 3.3 i środowiska Uruchomieniowego usługi Azure Synapse dla platformy Apache Spark 3.4.
Podgląd zawartości pliku
Zwraca do pierwszych bajtów "maxBytes" danego pliku jako ciąg zakodowany w formacie UTF-8.
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
Przenieś plik
Przenosi plik lub katalog. Obsługuje przenoszenie między systemami plików.
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
Zapisywanie pliku
Zapisuje podany ciąg w pliku zakodowanym w formacie UTF-8.
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
Dołączanie zawartości do pliku
Dołącza dany ciąg do pliku zakodowanego w formacie UTF-8.
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Uwaga
mssparkutils.fs.append()imssparkutils.fs.put()nie obsługują równoczesnego zapisu w tym samym pliku z powodu braku gwarancji niepodzielności.- W przypadku używania interfejsu
mssparkutils.fs.appendAPI wforpętli do zapisu w tym samym pliku zalecamy dodaniesleepinstrukcji około 0,5s~1s między zapisami cyklicznym. Dzieje się tak dlatego, żemssparkutils.fs.appendwewnętrznaflushoperacja interfejsu API jest asynchroniczna, dlatego krótkie opóźnienie pomaga zapewnić integralność danych.
Usuwanie pliku lub katalogu
Usuwa plik lub katalog.
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Narzędzia notesu
Nieobsługiwane.
Możesz użyć narzędzi notesu MSSparkUtils, aby uruchomić notes lub zamknąć notes z wartością. Uruchom następujące polecenie, aby uzyskać przegląd dostępnych metod:
mssparkutils.notebook.help()
Pobierz wyniki:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Uwaga
Narzędzia notesu nie mają zastosowania do definicji zadań platformy Apache Spark (SJD).
Odwołanie do notesu
Odwołuj się do notesu i zwraca jego wartość zakończenia. Wywołania funkcji zagnieżdżania można uruchamiać w notesie interaktywnie lub w potoku. Przywoływany notes zostanie uruchomiony w puli Platformy Spark, której notes wywołuje tę funkcję.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Na przykład:
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
Po zakończeniu przebiegu zostanie wyświetlony link migawki o nazwie "Wyświetl uruchomienie notesu: nazwa notesu" wyświetlany w danych wyjściowych komórki. Możesz kliknąć link, aby wyświetlić migawkę dla tego konkretnego przebiegu.

Odwołanie do uruchamiania wielu notesów równolegle
Metoda mssparkutils.notebook.runMultiple() umożliwia równoległe uruchamianie wielu notesów lub ze wstępnie zdefiniowaną strukturą topologiczną. Interfejs API korzysta z mechanizmu implementacji wielowątowej w ramach sesji platformy Spark, co oznacza, że zasoby obliczeniowe są współużytkowane przez przebiegi notesu referencyjnego.
Za pomocą mssparkutils.notebook.runMultiple()programu można wykonywać następujące czynności:
Wykonaj wiele notesów jednocześnie bez oczekiwania na zakończenie każdego z nich.
Określ zależności i kolejność wykonywania notesów przy użyciu prostego formatu JSON.
Optymalizowanie korzystania z zasobów obliczeniowych platformy Spark i zmniejszanie kosztów projektów usługi Synapse.
Wyświetl migawki każdego rekordu przebiegu notesu w danych wyjściowych i wygodnie debuguj/monitoruj zadania notesu.
Pobierz wartość zakończenia każdej aktywności wykonawczej i użyj ich w zadaniach podrzędnych.
Możesz również spróbować uruchomić plik mssparkutils.notebook.help("runMultiple"), aby znaleźć przykład i szczegółowe użycie.
Oto prosty przykład uruchamiania listy notesów równolegle przy użyciu tej metody:
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
Wynik wykonania z notesu głównego wygląda następująco:

Poniżej przedstawiono przykład uruchamiania notesów ze strukturą topologiczną przy użyciu polecenia mssparkutils.notebook.runMultiple(). Ta metoda umożliwia łatwe organizowanie notesów za pomocą środowiska kodu.
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Uwaga
- Metoda obsługuje tylko w środowisku Azure Synapse Runtime dla platformy Apache Spark 3.3 i środowiska Uruchomieniowego usługi Azure Synapse dla platformy Apache Spark 3.4.
- Stopień równoległości przebiegu wielu notesów jest ograniczony do całkowitego dostępnego zasobu obliczeniowego sesji platformy Spark.
Zamykanie notesu
Zamyka notes z wartością. Wywołania funkcji zagnieżdżania można uruchamiać w notesie interaktywnie lub w potoku.
Po interakcyjnym wywołaniu funkcji exit() z notesu usługa Azure Synapse zgłosi wyjątek, pomija uruchomione komórki podrzędne i utrzymuje sesję platformy Spark przy życiu.
Podczas organizowania notesu, który wywołuje
exit()funkcję w potoku usługi Synapse, usługa Azure Synapse zwróci wartość zakończenia, ukończy uruchomienie potoku i zatrzyma sesję platformy Spark.Po wywołaniu
exit()funkcji w przywoływanym notesie usługa Azure Synapse zatrzyma dalsze wykonywanie w przywoływanym notesie i będzie nadal uruchamiać następne komórki w notesie, który wywołujerun()funkcję. Na przykład: Notes1 ma trzy komórki i wywołujeexit()funkcję w drugiej komórce. Notes2 zawiera pięć komórek i wywołańrun(notebook1)w trzeciej komórce. Po uruchomieniu notesu Notebook2 notes1 zostanie zatrzymany w drugiej komórce po naciśnięciuexit()funkcji. Notes2 będzie nadal działać w czwartej komórce i piątej komórce.
mssparkutils.notebook.exit("value string")
Na przykład:
Przykład1 notes znajduje się w folderze/ z następującymi dwoma komórkami:
- komórka 1 definiuje parametr wejściowy z wartością domyślną ustawioną na 10.
- komórka 2 zamyka notes z danymi wejściowymi jako wartością zakończenia.
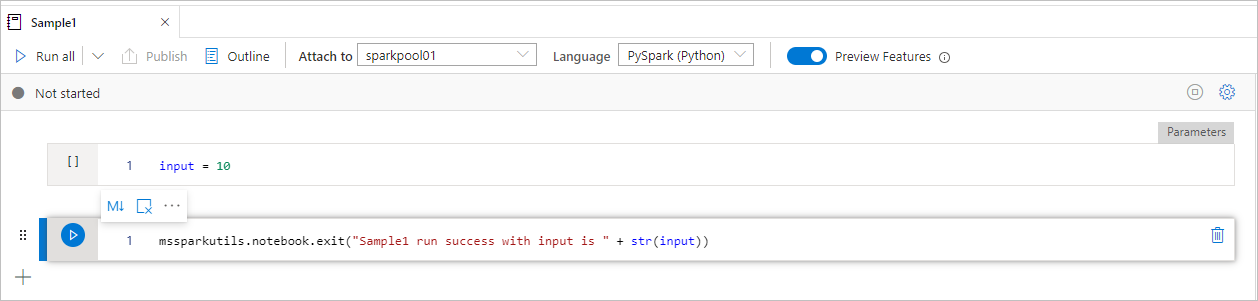
Przykład1 można uruchomić w innym notesie z wartościami domyślnymi:
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Wyniki:
Sample1 run success with input is 10
Przykład1 można uruchomić w innym notesie i ustawić wartość wejściową na 20:
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
Wyniki:
Sample1 run success with input is 20
Możesz użyć narzędzi notesu MSSparkUtils, aby uruchomić notes lub zamknąć notes z wartością. Uruchom następujące polecenie, aby uzyskać przegląd dostępnych metod:
mssparkutils.notebook.help()
Pobierz wyniki:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Odwołanie do notesu
Odwołuj się do notesu i zwraca jego wartość zakończenia. Wywołania funkcji zagnieżdżania można uruchamiać w notesie interaktywnie lub w potoku. Przywoływany notes zostanie uruchomiony w puli Platformy Spark, której notes wywołuje tę funkcję.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Na przykład:
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
Po zakończeniu przebiegu zostanie wyświetlony link migawki o nazwie "Wyświetl uruchomienie notesu: nazwa notesu" wyświetlany w danych wyjściowych komórki. Możesz kliknąć link, aby wyświetlić migawkę dla tego konkretnego przebiegu.
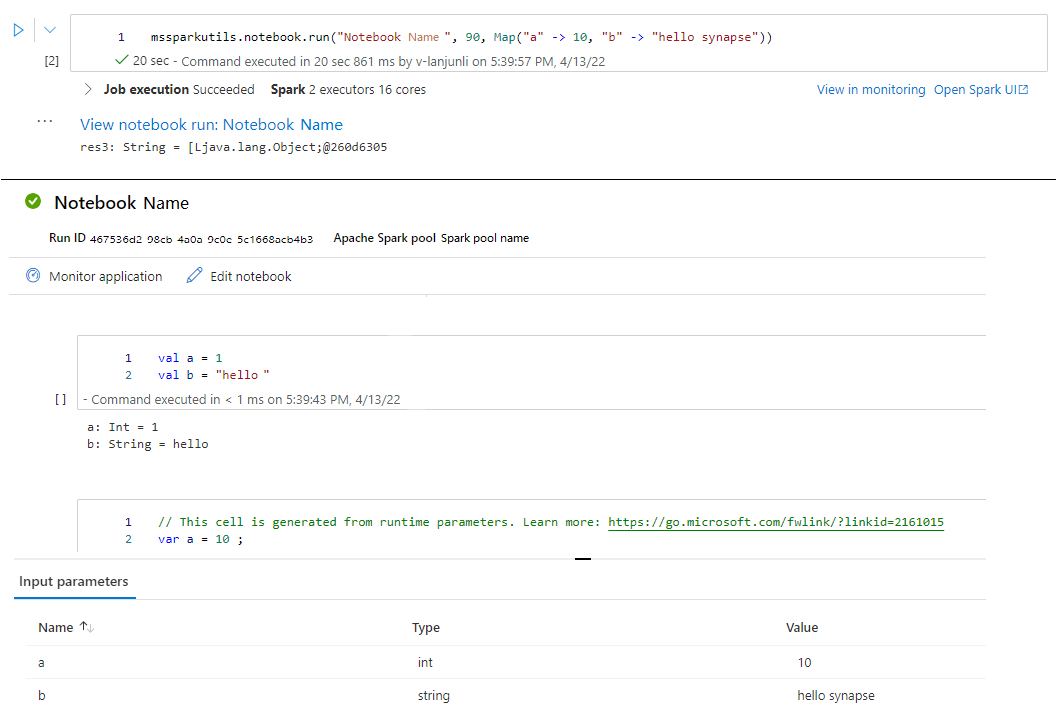
Zamykanie notesu
Zamyka notes z wartością. Wywołania funkcji zagnieżdżania można uruchamiać w notesie interaktywnie lub w potoku.
W przypadku interakcyjnego
exit()wywoływania funkcji usługa Azure Synapse zgłosi wyjątek, pomija uruchomione komórki podrzędne i utrzymuje sesję platformy Spark przy życiu.Podczas organizowania notesu, który wywołuje
exit()funkcję w potoku usługi Synapse, usługa Azure Synapse zwróci wartość zakończenia, ukończy uruchomienie potoku i zatrzyma sesję platformy Spark.Po wywołaniu
exit()funkcji w przywoływanym notesie usługa Azure Synapse zatrzyma dalsze wykonywanie w przywoływanym notesie i będzie nadal uruchamiać następne komórki w notesie, który wywołujerun()funkcję. Na przykład: Notes1 ma trzy komórki i wywołujeexit()funkcję w drugiej komórce. Notes2 zawiera pięć komórek i wywołańrun(notebook1)w trzeciej komórce. Po uruchomieniu notesu Notebook2 notes1 zostanie zatrzymany w drugiej komórce po naciśnięciuexit()funkcji. Notes2 będzie nadal działać w czwartej komórce i piątej komórce.
mssparkutils.notebook.exit("value string")
Na przykład:
Przykład1 notes znajduje się w folderze mssparkutils/folder/ z następującymi dwoma komórkami:
- komórka 1 definiuje parametr wejściowy z wartością domyślną ustawioną na 10.
- komórka 2 zamyka notes z danymi wejściowymi jako wartością zakończenia.
Przykład1 można uruchomić w innym notesie z wartościami domyślnymi:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
Wyniki:
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
Przykład1 można uruchomić w innym notesie i ustawić wartość wejściową na 20:
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
Wyniki:
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
Możesz użyć narzędzi notesu MSSparkUtils, aby uruchomić notes lub zamknąć notes z wartością. Uruchom następujące polecenie, aby uzyskać przegląd dostępnych metod:
mssparkutils.notebook.help()
Pobierz wyniki:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Odwołanie do notesu
Odwołuj się do notesu i zwraca jego wartość zakończenia. Wywołania funkcji zagnieżdżania można uruchamiać w notesie interaktywnie lub w potoku. Przywoływany notes zostanie uruchomiony w puli Platformy Spark, której notes wywołuje tę funkcję.
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
Na przykład:
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
Po zakończeniu przebiegu zostanie wyświetlony link migawki o nazwie "Wyświetl uruchomienie notesu: nazwa notesu" wyświetlany w danych wyjściowych komórki. Możesz kliknąć link, aby wyświetlić migawkę dla tego konkretnego przebiegu.
Zamykanie notesu
Zamyka notes z wartością. Wywołania funkcji zagnieżdżania można uruchamiać w notesie interaktywnie lub w potoku.
W przypadku interakcyjnego
exit()wywoływania funkcji usługa Azure Synapse zgłosi wyjątek, pomija uruchomione komórki podrzędne i utrzymuje sesję platformy Spark przy życiu.Podczas organizowania notesu, który wywołuje
exit()funkcję w potoku usługi Synapse, usługa Azure Synapse zwróci wartość zakończenia, ukończy uruchomienie potoku i zatrzyma sesję platformy Spark.Po wywołaniu
exit()funkcji w przywoływanym notesie usługa Azure Synapse zatrzyma dalsze wykonywanie w przywoływanym notesie i będzie nadal uruchamiać następne komórki w notesie, który wywołujerun()funkcję. Na przykład: Notes1 ma trzy komórki i wywołujeexit()funkcję w drugiej komórce. Notes2 zawiera pięć komórek i wywołańrun(notebook1)w trzeciej komórce. Po uruchomieniu notesu Notebook2 notes1 zostanie zatrzymany w drugiej komórce po naciśnięciuexit()funkcji. Notes2 będzie nadal działać w czwartej komórce i piątej komórce.
mssparkutils.notebook.exit("value string")
Na przykład:
Przykład1 notes znajduje się w folderze/ z następującymi dwoma komórkami:
- komórka 1 definiuje parametr wejściowy z wartością domyślną ustawioną na 10.
- komórka 2 zamyka notes z danymi wejściowymi jako wartością zakończenia.
Przykład1 można uruchomić w innym notesie z wartościami domyślnymi:
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
Wyniki:
Sample1 run success with input is 10
Przykład1 można uruchomić w innym notesie i ustawić wartość wejściową na 20:
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
Wyniki:
Sample1 run success with input is 20
Narzędzia poświadczeń
Możesz użyć narzędzi MSSparkUtils Credentials, aby uzyskać tokeny dostępu połączonych usług i zarządzać wpisami tajnymi w usłudze Azure Key Vault.
Uruchom następujące polecenie, aby uzyskać przegląd dostępnych metod:
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
Uzyskaj wynik:
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Uwaga
Obecnie polecenie getSecretWithLS(linkedService, secret) nie jest obsługiwane w języku C#.
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
Uzyskiwanie tokenu
Zwraca token Microsoft Entra dla danej grupy odbiorców, nazwę (opcjonalnie). Poniższa tabela zawiera listę wszystkich dostępnych typów odbiorców:
| Typ odbiorców | Literał ciągu do użycia w wywołaniu interfejsu API |
|---|---|
| Azure Storage | Storage |
| Azure Key Vault | Vault |
| Zarządzanie platformą Azure | AzureManagement |
| Usługa Azure SQL Data Warehouse (dedykowana i bezserwerowa) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Azure Data Explorer | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
Weryfikowanie tokenu
Zwraca wartość true, jeśli token nie wygasł.
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
Pobieranie parametry połączenia lub poświadczeń dla połączonej usługi
Zwraca parametry połączenia lub poświadczenia dla połączonej usługi.
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
Uzyskiwanie wpisu tajnego przy użyciu tożsamości obszaru roboczego
Zwraca wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu tożsamości obszaru roboczego. Upewnij się, że odpowiednio skonfigurowaliśmy dostęp do usługi Azure Key Vault .
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
Uzyskiwanie wpisu tajnego przy użyciu poświadczeń użytkownika
Zwraca wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu poświadczeń użytkownika.
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
Umieszczanie wpisu tajnego przy użyciu tożsamości obszaru roboczego
Umieszcza wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu tożsamości obszaru roboczego. Upewnij się, że odpowiednio skonfigurowaliśmy dostęp do usługi Azure Key Vault .
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Umieszczanie wpisu tajnego przy użyciu tożsamości obszaru roboczego
Umieszcza wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu tożsamości obszaru roboczego. Upewnij się, że odpowiednio skonfigurowaliśmy dostęp do usługi Azure Key Vault .
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
Umieszczanie wpisu tajnego przy użyciu tożsamości obszaru roboczego
Umieszcza wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu tożsamości obszaru roboczego. Upewnij się, że odpowiednio skonfigurowaliśmy dostęp do usługi Azure Key Vault .
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
Umieszczanie wpisu tajnego przy użyciu poświadczeń użytkownika
Umieszcza wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu poświadczeń użytkownika.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Umieszczanie wpisu tajnego przy użyciu poświadczeń użytkownika
Umieszcza wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu poświadczeń użytkownika.
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
Umieszczanie wpisu tajnego przy użyciu poświadczeń użytkownika
Umieszcza wpis tajny usługi Azure Key Vault dla danej nazwy usługi Azure Key Vault, nazwy wpisu tajnego i połączonej nazwy usługi przy użyciu poświadczeń użytkownika.
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
Narzędzia środowiska
Uruchom następujące polecenia, aby zapoznać się z dostępnymi metodami:
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
Uzyskaj wynik:
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
Uzyskiwanie nazwy użytkownika
Zwraca bieżącą nazwę użytkownika.
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
Pobieranie identyfikatora użytkownika
Zwraca bieżący identyfikator użytkownika.
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
Uzyskiwanie identyfikatora zadania
Zwraca identyfikator zadania.
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
Uzyskiwanie nazwy obszaru roboczego
Zwraca nazwę obszaru roboczego.
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
Uzyskiwanie nazwy puli
Zwraca nazwę puli platformy Spark.
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
Pobieranie identyfikatora klastra
Zwraca bieżący identyfikator klastra.
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
Kontekst środowiska uruchomieniowego
Narzędzia środowiska uruchomieniowego mssparkutils uwidocznione 3 właściwości środowiska uruchomieniowego, można użyć kontekstu środowiska uruchomieniowego mssparkutils, aby uzyskać właściwości wymienione poniżej:
- Notebookname — nazwa bieżącego notesu będzie zawsze zwracać wartość zarówno dla trybu interaktywnego, jak i trybu potoku.
- Pipelinejobid — identyfikator uruchomienia potoku zwróci wartość w trybie potoku i zwróci pusty ciąg w trybie interaktywnym.
- Activityrunid — identyfikator uruchomienia działania notesu zwróci wartość w trybie potoku i zwróci pusty ciąg w trybie interaktywnym.
Obecnie kontekst środowiska uruchomieniowego obsługuje języki Python i Scala.
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
Zarządzanie sesją
Zatrzymywanie sesji interakcyjnej
Zamiast ręcznie klikać przycisk zatrzymywania, czasami bardziej wygodne jest zatrzymanie sesji interakcyjnej przez wywołanie interfejsu API w kodzie. W takich przypadkach udostępniamy interfejs API mssparkutils.session.stop() do obsługi zatrzymywania sesji interakcyjnej za pośrednictwem kodu, który jest dostępny dla języków Scala i Python.
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() Interfejs API zatrzyma bieżącą sesję interaktywną asynchronicznie w tle, zatrzymuje sesję platformy Spark i zasoby wydania zajmowane przez sesję, aby były dostępne dla innych sesji w tej samej puli.
Uwaga
Nie zalecamy wywoływania wbudowanych interfejsów API języka, takich jak sys.exit w języku Scala lub sys.exit() Python w kodzie, ponieważ takie interfejsy API po prostu zabijają proces interpretera, pozostawiając sesję platformy Spark żywą i zasoby nie są zwalniane.
Zależności pakietów
Jeśli chcesz opracowywać notesy lub zadania lokalnie i musisz odwoływać się do odpowiednich pakietów na potrzeby kompilacji/wskazówek środowiska IDE, możesz użyć następujących pakietów.
Następne kroki
- Zapoznaj się z przykładowymi notesami usługi Synapse
- Szybki start: tworzenie puli platformy Apache Spark w usłudze Azure Synapse Analytics przy użyciu narzędzi internetowych
- Co to jest platforma Apache Spark w usłudze Azure Synapse Analytics
- Azure Synapse Analytics
- Jak używać interfejsu API instalacji/odinstalowania plików w usłudze Synapse