Poza migracją Oracle zaimplementuj nowoczesny magazyn danych na platformie Microsoft Azure
Ten artykuł jest częścią siedmiu części siedmioczęściowej serii, która zawiera wskazówki dotyczące migracji z bazy danych Oracle do usługi Azure Synapse Analytics. Celem tego artykułu jest najlepsze rozwiązania dotyczące implementowania nowoczesnych magazynów danych.
Poza migracją magazynu danych na platformę Azure
Kluczowym powodem migracji istniejącego magazynu danych do usługi Azure Synapse Analytics jest wykorzystanie globalnie bezpiecznej, skalowalnej, taniej, natywnej dla chmury, bazy danych analitycznych z płatnością zgodnie z rzeczywistym użyciem. Dzięki usłudze Azure Synapse możesz zintegrować zmigrowany magazyn danych z kompletnym ekosystemem analitycznym platformy Microsoft Azure, aby skorzystać z innych technologii firmy Microsoft i zmodernizować zmigrowany magazyn danych. Technologie te obejmują:
Usługa Azure Data Lake Storage umożliwia ekonomiczne pozyskiwanie danych, przemieszczanie, czyszczenie i przekształcanie. Usługa Data Lake Storage może zwolnić pojemność magazynu danych zajmowaną przez szybko rosnące tabele przejściowe.
Usługa Azure Data Factory umożliwia współpracę it i samoobsługową integrację danych z łącznikami do chmurowych i lokalnych źródeł danych oraz danych przesyłanych strumieniowo.
Common Data Model do udostępniania spójnych zaufanych danych w wielu technologiach, w tym:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Platforma obsługi klienta firmy Adobe
- Azure IoT
- Partnerzy niezależnego dostawcy oprogramowania firmy Microsoft
Technologie nauki o danych firmy Microsoft, w tym:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark jako usługa)
- Notesy programu Jupyter
- RStudio
- ML.NET
- Platforma .NET dla platformy Apache Spark, która umożliwia analitykom danych korzystanie z danych usługi Azure Synapse do trenowania modeli uczenia maszynowego na dużą skalę.
Usługa Azure HDInsight do przetwarzania dużych ilości danych oraz łączenia danych big data z danymi usługi Azure Synapse przez utworzenie logicznego magazynu danych przy użyciu technologii PolyBase.
Usługi Azure Event Hubs, Azure Stream Analytics i Apache Kafka umożliwiają integrację danych przesyłania strumieniowego na żywo z usługi Azure Synapse.
Wzrost danych big data doprowadził do ostrego zapotrzebowania na uczenie maszynowe, aby umożliwić niestandardowe, wytrenowane modele uczenia maszynowego do użycia w usłudze Azure Synapse. Modele uczenia maszynowego umożliwiają wykonywanie analiz w bazie danych na dużą skalę w partiach na podstawie zdarzeń i na żądanie. Możliwość korzystania z analizy w bazie danych w usłudze Azure Synapse z wielu narzędzi do analizy biznesowej i aplikacji gwarantuje również spójne przewidywania i zalecenia.
Ponadto możesz zintegrować usługę Azure Synapse z narzędziami partnerskimi firmy Microsoft na platformie Azure, aby skrócić czas na wartość.
Przyjrzyjmy się bliżej sposobom korzystania z technologii w ekosystemie analitycznym firmy Microsoft w celu modernizacji magazynu danych po przeprowadzeniu migracji do usługi Azure Synapse.
Odciążanie danych przemieszczania i przetwarzania ETL do usług Data Lake Storage i Data Factory
Transformacja cyfrowa stworzyła kluczowe wyzwanie dla przedsiębiorstw, generując potok nowych danych do przechwytywania i analizy. Dobrym przykładem jest utworzenie danych transakcji przez otwarcie systemów przetwarzania transakcyjnego online (OLTP) w celu uzyskania dostępu do usług z urządzeń przenośnych. Większość tych danych znajduje drogę do magazynów danych, a systemy OLTP są głównym źródłem. Dzięki tym, że klienci napędzają teraz szybkość transakcji, a nie pracowników, ilość danych w tabelach przejściowych magazynu danych szybko rośnie.
Dzięki szybkiemu napływowi danych do przedsiębiorstwa wraz z nowymi źródłami danych, takimi jak Internet rzeczy (IoT), firmy muszą znaleźć sposoby skalowania w górę przetwarzania ETL integracji danych. Jedną z metod jest odciążanie pozyskiwania, czyszczenia danych, przekształcania i integracji z usługą Data Lake i przetwarzanie danych na dużą skalę w ramach programu modernizacji magazynu danych.
Po przeprowadzeniu migracji magazynu danych do usługi Azure Synapse firma Microsoft może zmodernizować przetwarzanie ETL przez pozyskiwanie i przemieszczanie danych w usłudze Data Lake Storage. Następnie możesz wyczyścić, przekształcić i zintegrować dane na dużą skalę przy użyciu usługi Data Factory przed załadowaniem ich do usługi Azure Synapse równolegle przy użyciu technologii PolyBase.
W przypadku strategii ELT rozważ odciążanie przetwarzania ELT do usługi Data Lake Storage w celu łatwego skalowania w miarę wzrostu ilości lub częstotliwości danych.
Microsoft Azure Data Factory
Usługa Azure Data Factory to usługa integracji danych hybrydowych z płatnością zgodnie z rzeczywistym użyciem na potrzeby wysoce skalowalnego przetwarzania ETL i ELT. Usługa Data Factory udostępnia internetowy interfejs użytkownika umożliwiający tworzenie potoków integracji danych bez kodu. Za pomocą usługi Data Factory można wykonywać następujące czynności:
Twórz skalowalne potoki integracji danych bez kodu.
Łatwe uzyskiwanie danych na dużą skalę.
Płacisz wyłącznie za rzeczywiste użycie.
Nawiąż połączenie z lokalnymi, chmurowymi i opartymi na modelu SaaS źródłami danych.
Pozyskiwanie, przenoszenie, czyszczenie, przekształcanie, integrowanie i analizowanie danych w chmurze i lokalnych na dużą skalę.
Bezproblemowe tworzenie, monitorowanie i zarządzanie potokami obejmującymi magazyny danych zarówno lokalnie, jak i w chmurze.
Włącz skalowanie z płatnością zgodnie z rzeczywistym użyciem zgodnie z rozwojem klientów.
Możesz użyć tych funkcji bez pisania kodu lub dodać kod niestandardowy do potoków usługi Data Factory. Poniższy zrzut ekranu przedstawia przykładowy potok usługi Data Factory.

Napiwek
Usługa Data Factory umożliwia tworzenie skalowalnych potoków integracji danych bez kodu.
Zaimplementuj tworzenie potoku usługi Data Factory z dowolnego z kilku miejsc, w tym:
Witryna Microsoft Azure Portal.
Microsoft Azure PowerShell.
Programowo z platformy .NET i języka Python przy użyciu zestawu SDK w wielu językach.
Szablony usługi Azure Resource Manager (ARM).
Interfejsy API REST.
Napiwek
Usługa Data Factory może łączyć się z danymi lokalnymi, w chmurze i SaaS.
Deweloperzy i analitycy danych, którzy wolą pisać kod, mogą łatwo tworzyć potoki usługi Data Factory w językach Java, Python i .NET przy użyciu zestawów SDK (software development kit) dostępnych dla tych języków programowania. Potoki usługi Data Factory mogą być hybrydowymi potokami danych, ponieważ mogą łączyć się, pozyskiwać, czyścić, przekształcać i analizować dane w lokalnych centrach danych, platformie Microsoft Azure, innych chmurach i ofertach SaaS.
Po opracowaniu potoków usługi Data Factory w celu zintegrowania i analizowania danych można wdrożyć te potoki globalnie i zaplanować ich uruchamianie w partii, wywoływać je na żądanie jako usługę lub uruchamiać je w czasie rzeczywistym na podstawie zdarzeń. Potok usługi Data Factory może być również uruchamiany na co najmniej jednym aparatze wykonywania i monitorować wykonywanie w celu zapewnienia wydajności i śledzenia błędów.
Napiwek
W usłudze Azure Data Factory potoki kontrolują integrację i analizę danych. Usługa Data Factory to oprogramowanie do integracji danych klasy korporacyjnej przeznaczone dla specjalistów IT i ma możliwość uzdatniania danych dla użytkowników biznesowych.
Przypadki użycia
Usługa Data Factory obsługuje wiele przypadków użycia, takich jak:
Przygotowywanie, integrowanie i wzbogacanie danych z chmurowych i lokalnych źródeł danych w celu wypełnienia migrowanego magazynu danych i składnic danych w usłudze Microsoft Azure Synapse.
Przygotowywanie, integrowanie i wzbogacanie danych z chmurowych i lokalnych źródeł danych w celu utworzenia danych szkoleniowych do użycia podczas opracowywania modeli uczenia maszynowego i ponownego trenowania modeli analitycznych.
Organizowanie przygotowywania i analizy danych w celu tworzenia predykcyjnych i preskrypcyjnych potoków analitycznych na potrzeby przetwarzania i analizowania danych w partiach, takich jak analiza tonacji. Działanie na podstawie wyników analizy lub wypełnienie magazynu danych wynikami.
Przygotowywanie, integrowanie i wzbogacanie danych dla aplikacji biznesowych opartych na danych działających w chmurze platformy Azure na podstawie operacyjnych magazynów danych, takich jak Usługa Azure Cosmos DB.
Napiwek
Tworzenie zestawów danych szkoleniowych w nauce o danych w celu opracowywania modeli uczenia maszynowego.
Źródła danych
Usługa Data Factory umożliwia korzystanie z łączników zarówno z chmurowych, jak i lokalnych źródeł danych. Oprogramowanie agenta, znane jako własne środowisko Integration Runtime, bezpiecznie uzyskuje dostęp do lokalnych źródeł danych i obsługuje bezpieczny, skalowalny transfer danych.
Przekształcanie danych przy użyciu usługi Azure Data Factory
W potoku usługi Data Factory można pozyskiwać, czyścić, przekształcać, integrować i analizować dowolne typy danych z tych źródeł. Dane mogą być ustrukturyzowane, częściowo ustrukturyzowane, takie jak JSON lub Avro, lub bez struktury.
Bez pisania kodu profesjonalni deweloperzy ETL mogą używać przepływów mapowania usługi Data Factory do filtrowania, dzielenia, łączenia kilku typów, wyszukiwania, przestawnego, przestawnego, sortowania, łączenia i agregowania danych. Ponadto usługa Data Factory obsługuje klucze zastępcze, wiele opcji przetwarzania zapisu, takich jak wstawianie, upsert, aktualizacja, rekreacja tabel i obcinanie tabel oraz kilka typów docelowych magazynów danych , nazywanych również ujściami. Deweloperzy ETL mogą również tworzyć agregacje, w tym agregacje szeregów czasowych, które wymagają, aby okno było umieszczane w kolumnach danych.
Napiwek
Profesjonalni deweloperzy ETL mogą używać przepływów mapowania danych usługi Data Factory do czyszczenia, przekształcania i integrowania danych bez konieczności pisania kodu.
Przepływy danych mapowania, które przekształcają dane jako działania w potoku usługi Data Factory, a w razie potrzeby można uwzględnić wiele przepływów danych mapowania w jednym potoku. W ten sposób można zarządzać złożonością, dzieląc trudne zadania przekształcania danych i integracji na mniejsze przepływy danych mapowania, które można połączyć. W razie potrzeby możesz dodać kod niestandardowy. Oprócz tej funkcji przepływy danych mapowania usługi Data Factory obejmują następujące możliwości:
Definiowanie wyrażeń w celu czyszczenia i przekształcania danych, agregacji obliczeniowych i wzbogacania danych. Na przykład te wyrażenia mogą wykonywać inżynierię cech w polu daty, aby podzielić je na wiele pól w celu utworzenia danych szkoleniowych podczas opracowywania modelu uczenia maszynowego. Wyrażenia można tworzyć z bogatego zestawu funkcji, które obejmują matematyczne, czasowe, podzielone, scalanie, łączenie ciągów, warunki, dopasowanie wzorca, zamianę i wiele innych funkcji.
Automatycznie obsłuż dryf schematu, aby potoki przekształcania danych mogły uniknąć wpływu zmian schematu w źródłach danych. Ta możliwość jest szczególnie ważna w przypadku przesyłania strumieniowego danych IoT, gdzie zmiany schematu mogą wystąpić bez powiadomienia, jeśli urządzenia są uaktualnione lub gdy odczyty są pomijane przez urządzenia bramy zbierające dane IoT.
Partycjonowanie danych w celu umożliwienia równoległego uruchamiania przekształceń na dużą skalę.
Sprawdź dane przesyłane strumieniowo, aby wyświetlić metadane przekształcanego strumienia.
Napiwek
Usługa Data Factory obsługuje możliwość automatycznego wykrywania zmian schematu w danych przychodzących, takich jak dane przesyłane strumieniowo, i zarządzanie nimi.
Poniższy zrzut ekranu przedstawia przykładowy przepływ danych mapowania usługi Data Factory.

Inżynierowie danych mogą profilować jakość danych i wyświetlać wyniki poszczególnych przekształceń danych, włączając możliwość debugowania podczas opracowywania.
Napiwek
Usługa Data Factory może również partycjonować dane, aby umożliwić uruchamianie przetwarzania ETL na dużą skalę.
W razie potrzeby możesz rozszerzyć funkcje przekształcania i analityczne usługi Data Factory, dodając połączoną usługę zawierającą kod do potoku. Na przykład notes puli Platformy Spark usługi Azure Synapse Spark może zawierać kod języka Python, który używa wytrenowanego modelu do oceniania danych zintegrowanych z przepływem danych mapowania.
Zintegrowane dane i wyniki analizy można przechowywać w potoku usługi Data Factory w co najmniej jednym magazynie danych, takim jak Data Lake Storage, Azure Synapse lub tabele Hive w usłudze HDInsight. Możesz również wywołać inne działania w celu wykonywania szczegółowych informacji generowanych przez potok analityczny usługi Data Factory.
Napiwek
Potoki usługi Data Factory są rozszerzalne, ponieważ usługa Data Factory umożliwia pisanie własnego kodu i uruchamianie go w ramach potoku.
Korzystanie z platformy Spark do skalowania integracji danych
W czasie wykonywania usługa Data Factory wewnętrznie używa pul platformy Azure Synapse Spark, które są ofertą platformy Spark jako usługi firmy Microsoft, w celu czyszczenia i integrowania danych w chmurze platformy Azure. Możesz wyczyścić, zintegrować i analizować duże ilości danych o dużej szybkości, takich jak dane strumienia kliknięć, na dużą skalę. Firma Microsoft zamierza również uruchamiać potoki usługi Data Factory w innych dystrybucjach platformy Spark. Oprócz uruchamiania zadań ETL na platformie Spark usługa Data Factory może wywoływać skrypty pig i zapytania hive w celu uzyskiwania dostępu do danych przechowywanych w usłudze HDInsight i przekształcania ich.
Łączenie samoobsługowego przygotowywania danych i przetwarzania ETL usługi Data Factory przy użyciu przepływów danych uzdatniania
Uzdatnianie danych umożliwia użytkownikom biznesowym, znanym również jako integratorzy danych i inżynierowie danych obywateli, korzystanie z platformy do wizualnego odnajdywania, eksplorowania i przygotowywania danych na dużą skalę bez konieczności pisania kodu. Ta funkcja usługi Data Factory jest łatwa w użyciu i jest podobna do przepływów danych programu Microsoft Excel Power Query lub Microsoft Power BI, w których użytkownicy biznesowi samoobsługi używają interfejsu użytkownika w stylu arkusza kalkulacyjnego z przekształceniami rozwijanymi w celu przygotowania i zintegrowania danych. Poniższy zrzut ekranu przedstawia przykładowy przepływ danych uzdatniania usługi Data Factory.

W przeciwieństwie do programu Excel i usługi Power BI przepływy danych w usłudze Data Factory używają dodatku Power Query do generowania kodu W języku M, a następnie tłumaczenia ich na zadanie spark w dużej ilości równoległej w pamięci na potrzeby wykonywania w skali chmury. Połączenie przepływów danych mapowania i uzdatniania przepływów danych w usłudze Data Factory umożliwia profesjonalnym deweloperom ETL i użytkownikom biznesowym współpracę w celu przygotowania, zintegrowania i analizowania danych do wspólnego celu biznesowego. Powyższy diagram przepływów mapowania danych usługi Data Factory pokazuje, jak można połączyć notesy puli usługi Data Factory i usługi Azure Synapse Spark w tym samym potoku usługi Data Factory. Kombinacja mapowania i uzdatniania przepływów danych w usłudze Data Factory pomaga użytkownikom IT i użytkownikom biznesowym na bieżąco z tym, jakie przepływy danych zostały utworzone, i obsługuje ponowne użycie przepływu danych w celu zminimalizowania ponownego wynalezienia i zmaksymalizowania produktywności i spójności.
Napiwek
Usługa Data Factory obsługuje zarówno uzdatnianie przepływów danych, jak i przepływy mapowania danych, dzięki czemu użytkownicy biznesowi i użytkownicy IT mogą integrować dane ze wspólną platformą.
Łączenie danych i analiz w potokach analitycznych
Oprócz czyszczenia i przekształcania danych usługa Data Factory może łączyć integrację i analizę danych w tym samym potoku. Za pomocą usługi Data Factory można tworzyć zarówno potoki integracji danych, jak i potoki analityczne, czyli rozszerzenie poprzedniego. Możesz porzucić model analityczny w potoku, aby utworzyć potok analityczny, który generuje czyste, zintegrowane dane dla przewidywań lub zaleceń. Następnie możesz natychmiast wykonywać działania na temat przewidywań lub zaleceń albo przechowywać je w magazynie danych, aby zapewnić nowe szczegółowe informacje i zalecenia, które można wyświetlić w narzędziach analizy biznesowej.
Aby ocenić dane wsadowe, możesz opracować model analityczny, który wywołujesz jako usługę w potoku usługi Data Factory. Modele analityczne można tworzyć bez użycia kodu za pomocą usługi Azure Machine Learning Studio lub zestawu SDK usługi Azure Machine Learning przy użyciu notesów puli platformy Azure Synapse Spark lub języka R w programie RStudio. Po uruchomieniu potoków uczenia maszynowego platformy Spark w notesach puli platformy Azure Synapse Spark analiza odbywa się na dużą skalę.
Zintegrowane dane i dowolny potok analityczny usługi Data Factory można przechowywać w co najmniej jednym magazynie danych, takim jak Data Lake Storage, Azure Synapse lub Tabele Hive w usłudze HDInsight. Możesz również wywołać inne działania w celu wykonywania szczegółowych informacji generowanych przez potok analityczny usługi Data Factory.
Używanie bazy danych lake do udostępniania spójnych zaufanych danych
Kluczowym celem każdej konfiguracji integracji danych jest możliwość integrowania danych raz i ponownego użycia ich wszędzie, a nie tylko w magazynie danych. Na przykład możesz chcieć użyć zintegrowanych danych w nauce o danych. Ponowne użycie pozwala uniknąć ponownego wymyślania i zapewnia spójne, powszechnie zrozumiałe dane, którym każdy może ufać.
Model Common Data Model opisuje podstawowe jednostki danych, które mogą być współużytkowane i ponownie używane w przedsiębiorstwie. Aby użyć ponownie, usługa Common Data Model ustanawia zestaw wspólnych nazw danych i definicji opisujących jednostki danych logicznych. Przykłady typowych nazw danych to Klient, Konto, Produkt, Dostawca, Zamówienia, Płatności i Zwroty. Specjaliści IT i biznesowi mogą używać oprogramowania do integracji danych, aby tworzyć i przechowywać wspólne zasoby danych, aby zmaksymalizować ich ponowne użycie i zwiększyć spójność wszędzie.
Usługa Azure Synapse udostępnia szablony baz danych specyficzne dla branży, które ułatwiają standaryzację danych w jeziorze. Szablony baz danych usługi Lake udostępniają schematy dla wstępnie zdefiniowanych obszarów biznesowych, umożliwiając ładowanie danych do bazy danych lake w sposób ustrukturyzowany. Moc przychodzi, gdy używasz oprogramowania do integracji danych do tworzenia wspólnych zasobów danych bazy danych typu lake, co powoduje samodzielne opisywanie zaufanych danych, które mogą być używane przez aplikacje i systemy analityczne. Wspólne zasoby danych można tworzyć w usłudze Data Lake Storage przy użyciu usługi Data Factory.
Napiwek
Usługa Data Lake Storage jest magazynem udostępnionym, który stanowi podstawę usług Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark i HDInsight.
Usługi Power BI, Azure Synapse Spark, Azure Synapse i Azure Machine Learning mogą korzystać z typowych zasobów danych. Na poniższym diagramie przedstawiono sposób użycia bazy danych lake w usłudze Azure Synapse.
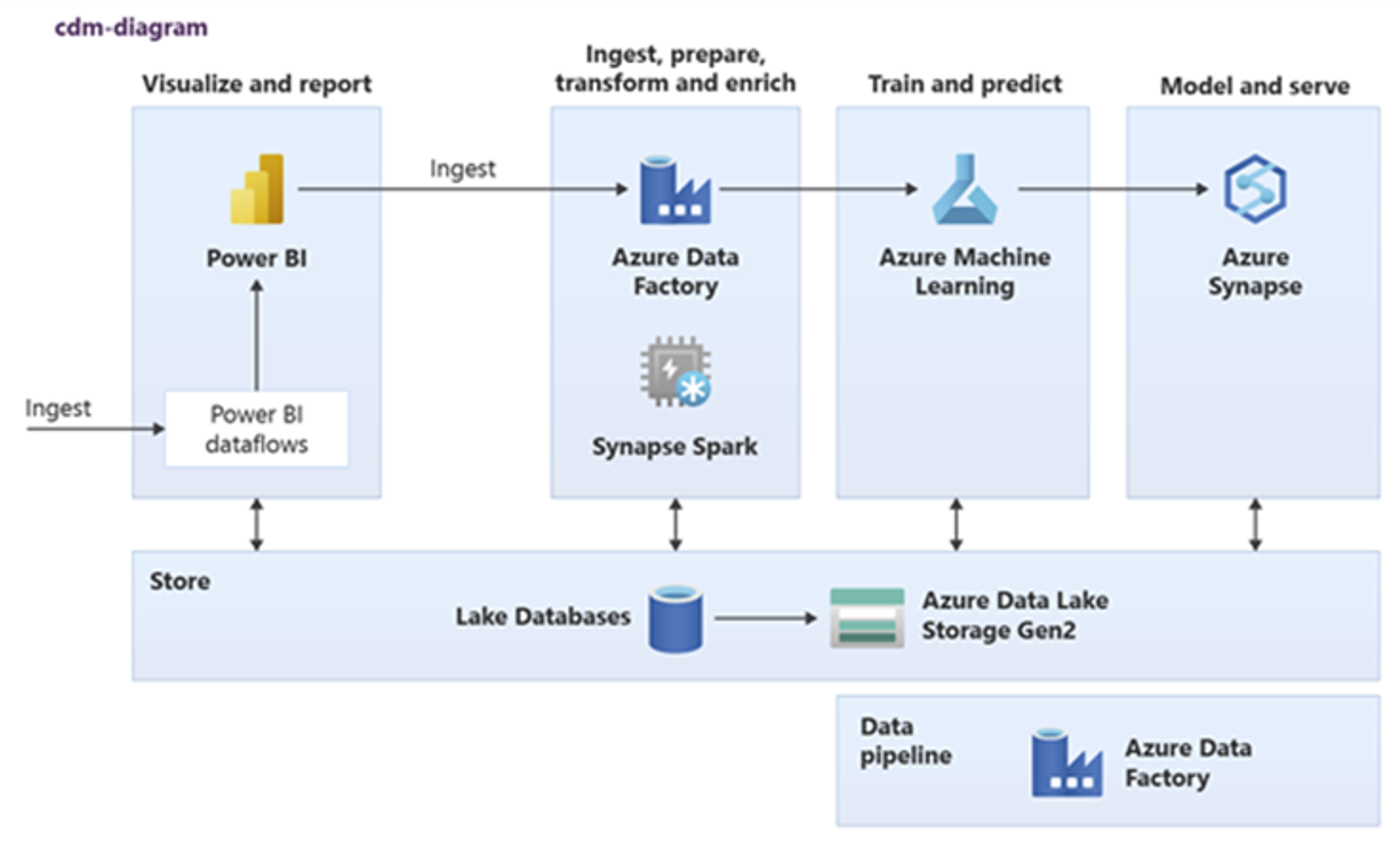
Napiwek
Integrowanie danych w celu utworzenia jednostek logicznych bazy danych typu lake w magazynie udostępnionym w celu zmaksymalizowania ponownego użycia wspólnych zasobów danych.
Integracja z technologiami nauki o danych firmy Microsoft na platformie Azure
Innym kluczowym celem modernizacji magazynu danych jest uzyskanie szczegółowych informacji o przewagi konkurencyjnej. Szczegółowe informacje można tworzyć, integrując zmigrowany magazyn danych z technologią nauki o danych firmy Microsoft i innych firm na platformie Azure. W poniższych sekcjach opisano technologie uczenia maszynowego i nauki o danych oferowane przez firmę Microsoft, aby zobaczyć, jak można ich używać z usługą Azure Synapse w nowoczesnym środowisku magazynu danych.
Technologie firmy Microsoft do nauki o danych na platformie Azure
Firma Microsoft oferuje szereg technologii, które obsługują analizę z wyprzedzeniem. Dzięki tym technologiom można tworzyć modele analityczne predykcyjne przy użyciu uczenia maszynowego lub analizować dane bez struktury przy użyciu uczenia głębokiego. Technologie obejmują:
Azure Machine Learning Studio
Azure Machine Learning
Notesy puli platformy Spark w usłudze Azure Synapse
ML.NET (interfejs API, interfejs wiersza polecenia lub ML.NET Model Builder dla programu Visual Studio)
Platforma .NET dla platformy Apache Spark
Analitycy danych mogą używać narzędzi RStudio (R) i Jupyter Notebooks (Python) do tworzenia modeli analitycznych lub mogą używać struktur, takich jak Keras lub TensorFlow.
Napiwek
Opracowywanie modeli uczenia maszynowego przy użyciu podejścia bez/niskiego poziomu kodu lub przy użyciu języków programowania, takich jak Python, R i .NET.
Azure Machine Learning Studio
Azure Machine Learning Studio to w pełni zarządzana usługa w chmurze, która umożliwia tworzenie, wdrażanie i udostępnianie analiz predykcyjnych przy użyciu interfejsu użytkownika opartego na przeciąganiu i upuszczaniu. Poniższy zrzut ekranu przedstawia interfejs użytkownika usługi Azure Machine Learning Studio.

Azure Machine Learning
Usługa Azure Machine Learning udostępnia zestaw SDK i usługi dla języka Python, które obsługują, mogą pomóc w szybkim przygotowaniu danych, a także wytrenować i wdrożyć modele uczenia maszynowego. Usługi Azure Machine Learning można używać w notesach platformy Azure przy użyciu notesu Jupyter Notebook z platformami typu open source, takimi jak PyTorch, TensorFlow, scikit-learn lub Spark MLlib — biblioteka uczenia maszynowego dla platformy Spark.
Napiwek
Usługa Azure Machine Learning udostępnia zestaw SDK do tworzenia modeli uczenia maszynowego przy użyciu kilku platform typu open source.
Za pomocą usługi Azure Machine Learning można również tworzyć potoki uczenia maszynowego, które zarządzają kompleksowego przepływu pracy, programowo skalowane w chmurze i wdrażają modele zarówno w chmurze, jak i na brzegu. Usługa Azure Machine Learning zawiera obszary robocze, które są przestrzeniami logicznymi, które można programowo lub ręcznie utworzyć w witrynie Azure Portal. Te obszary robocze zapewniają cele obliczeniowe, eksperymenty, magazyny danych, wytrenowane modele uczenia maszynowego, obrazy platformy Docker i wdrożone usługi w jednym miejscu, aby umożliwić zespołom pracę razem. Usługę Azure Machine Learning w programie Visual Studio można używać z rozszerzeniem Visual Studio for AI.
Napiwek
Organizowanie powiązanych magazynów danych, eksperymentów, wytrenowanych modeli, obrazów platformy Docker i wdrożonych usług w obszarach roboczych oraz zarządzanie nimi.
Notesy puli platformy Spark w usłudze Azure Synapse
Notes puli platformy Spark usługi Azure Synapse Spark to zoptymalizowana pod kątem platformy Azure usługa Apache Spark. Notesy puli platformy Spark w usłudze Azure Synapse:
Inżynierowie danych mogą tworzyć i uruchamiać skalowalne zadania przygotowywania danych przy użyciu usługi Data Factory.
Analitycy danych mogą tworzyć i uruchamiać modele uczenia maszynowego na dużą skalę przy użyciu notesów napisanych w językach takich jak Scala, R, Python, Java i SQL w celu wizualizacji wyników.
Napiwek
Usługa Azure Synapse Spark to dynamicznie skalowalna oferta spark jako usługa firmy Microsoft, platforma Spark oferuje skalowalne wykonywanie przygotowywania danych, tworzenia modeli i wdrażania modelu.
Zadania uruchomione w notesach puli Platformy Spark usługi Azure Synapse mogą pobierać, przetwarzać i analizować dane na dużą skalę z usługi Azure Blob Storage, Data Lake Storage, Azure Synapse, HDInsight i przesyłania strumieniowego danych, takich jak Apache Kafka.
Napiwek
Platforma Azure Synapse Spark może uzyskiwać dostęp do danych w wielu magazynach danych ekosystemu analitycznego firmy Microsoft na platformie Azure.
Notesy puli platformy Azure Synapse Spark obsługują skalowanie automatyczne i automatyczne kończenie w celu zmniejszenia całkowitego kosztu posiadania (TCO). Analitycy danych mogą zarządzać cyklem życia uczenia maszynowego za pomocą platformy open source MLflow.
ML.NET
ML.NET to międzyplatformowa platforma uczenia maszynowego typu open source dla systemów Windows, Linux, macOS. Firma Microsoft utworzyła ML.NET, aby deweloperzy platformy .NET mogli używać istniejących narzędzi, takich jak ML.NET Model Builder dla programu Visual Studio, do tworzenia niestandardowych modeli uczenia maszynowego i integrowania ich z aplikacjami platformy .NET.
Napiwek
Firma Microsoft rozszerzyła możliwości uczenia maszynowego dla deweloperów platformy .NET.
Platforma .NET dla platformy Apache Spark
Platforma .NET dla platformy Apache Spark rozszerza obsługę platformy Spark poza językiem R, Scala, Python i Java na platformę .NET i ma na celu udostępnienie platformy Spark deweloperom platformy .NET we wszystkich interfejsach API platformy Spark. Chociaż platforma .NET dla platformy Apache Spark jest obecnie dostępna tylko na platformie Apache Spark w usłudze HDInsight, firma Microsoft zamierza udostępnić platformę .NET dla platformy Apache Spark w notesach puli platformy Azure Synapse Spark.
Korzystanie z usługi Azure Synapse Analytics z magazynem danych
Aby połączyć modele uczenia maszynowego z usługą Azure Synapse, możesz:
Używaj modeli uczenia maszynowego w partiach lub w czasie rzeczywistym na danych przesyłanych strumieniowo, aby tworzyć nowe szczegółowe informacje i dodawać te szczegółowe informacje do tego, co już wiesz w usłudze Azure Synapse.
Użyj danych w usłudze Azure Synapse, aby opracowywać i trenować nowe modele predykcyjne na potrzeby wdrażania w innym miejscu, na przykład w innych aplikacjach.
Wdrażanie modeli uczenia maszynowego, w tym modeli wytrenowanych gdzie indziej, w usłudze Azure Synapse w celu analizowania danych w magazynie danych i podwyższania nowej wartości biznesowej.
Napiwek
Trenowanie, testowanie, ocenianie i uruchamianie modeli uczenia maszynowego na dużą skalę w notesach puli platformy Spark w usłudze Azure Synapse przy użyciu danych w usłudze Azure Synapse.
Analitycy danych mogą używać notesów puli RStudio, Jupyter Notebook i Azure Synapse Spark wraz z usługą Azure Machine Learning do tworzenia modeli uczenia maszynowego uruchamianych na dużą skalę w notesach puli platformy Azure Synapse Spark przy użyciu danych w usłudze Azure Synapse. Na przykład analitycy danych mogą utworzyć nienadzorowany model w celu segmentowania klientów w celu prowadzenia różnych kampanii marketingowych. Użyj nadzorowanego uczenia maszynowego, aby wytrenować model, aby przewidzieć określony wynik, na przykład przewidzieć skłonność klienta do rezygnacji lub zalecić kolejną najlepszą ofertę dla klienta, aby spróbować zwiększyć ich wartość. Na poniższym diagramie przedstawiono sposób użycia usługi Azure Synapse na potrzeby usługi Azure Machine Learning.
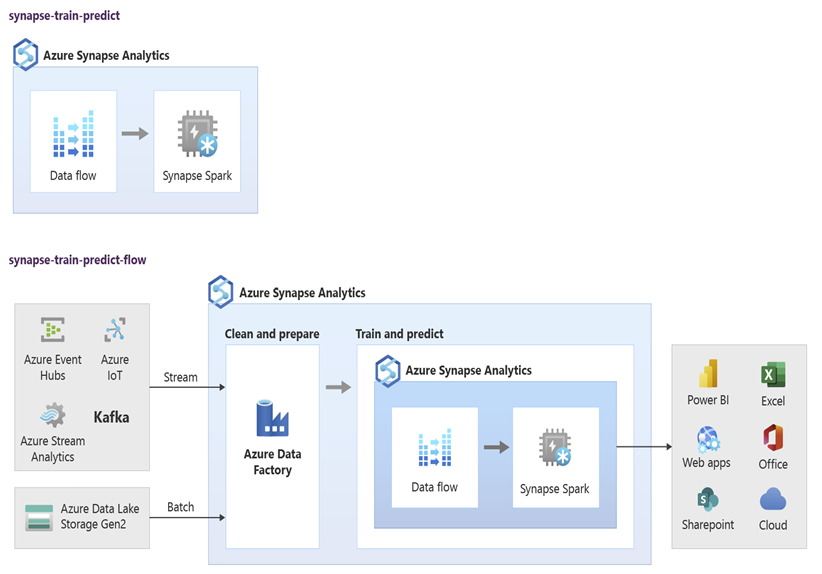
W innym scenariuszu możesz pozyskać sieć społecznościową lub przejrzeć dane witryny internetowej w usłudze Data Lake Storage, a następnie przygotować i przeanalizować dane na dużą skalę w notesie puli platformy Azure Synapse Spark przy użyciu przetwarzania języka naturalnego, aby ocenić tonację klientów na temat produktów lub marki. Następnie możesz dodać te wyniki do magazynu danych. Korzystając z analizy danych big data, aby zrozumieć wpływ negatywnych nastrojów sprzedaży produktów, należy dodać je do tego, co już znasz w magazynie danych.
Napiwek
Tworzenie nowych szczegółowych informacji przy użyciu uczenia maszynowego na platformie Azure w partiach lub w czasie rzeczywistym oraz dodawanie ich do znanych informacji w magazynie danych.
Integrowanie danych przesyłania strumieniowego na żywo z usługą Azure Synapse Analytics
Podczas analizowania danych w nowoczesnym magazynie danych musisz mieć możliwość analizowania danych przesyłanych strumieniowo w czasie rzeczywistym i dołączania ich do danych historycznych w magazynie danych. Przykładem jest połączenie danych IoT z danymi produktu lub zasobu.
Napiwek
Zintegruj magazyn danych z danymi przesyłanymi strumieniowo z urządzeń IoT lub strumieni kliknięć.
Po pomyślnym zmigrowaniu magazynu danych do usługi Azure Synapse możesz wprowadzić integrację danych przesyłania strumieniowego na żywo w ramach ćwiczenia modernizacji magazynu danych, korzystając z dodatkowych funkcji w usłudze Azure Synapse. W tym celu pozyskiwanie danych przesyłanych strumieniowo za pośrednictwem usługi Event Hubs, innych technologii, takich jak Apache Kafka, lub potencjalnie istniejącego narzędzia ETL, jeśli obsługuje źródła danych przesyłanych strumieniowo. Przechowywanie danych w usłudze Data Lake Storage. Następnie utwórz tabelę zewnętrzną w usłudze Azure Synapse przy użyciu technologii PolyBase i wskaż ją w strumieniu do usługi Data Lake Storage, aby magazyn danych zawierał teraz nowe tabele, które zapewniają dostęp do danych przesyłanych strumieniowo w czasie rzeczywistym. Wykonaj zapytanie względem tabeli zewnętrznej tak, jakby dane znajdowały się w magazynie danych przy użyciu standardowego języka T-SQL z dowolnego narzędzia analizy biznesowej, które ma dostęp do usługi Azure Synapse. Możesz również dołączyć dane przesyłane strumieniowo do innych tabel z danymi historycznymi, aby utworzyć widoki, które łączą dane przesyłania strumieniowego na żywo z danymi historycznymi, aby ułatwić użytkownikom biznesowym dostęp do danych.
Napiwek
Pozyskiwanie danych przesyłanych strumieniowo do usługi Data Lake Storage z usług Event Hubs lub Apache Kafka oraz uzyskiwanie dostępu do danych z usługi Azure Synapse przy użyciu tabel zewnętrznych technologii PolyBase.
Na poniższym diagramie magazyn danych w czasie rzeczywistym w usłudze Azure Synapse jest zintegrowany z danymi przesyłanymi strumieniowo w usłudze Data Lake Storage.
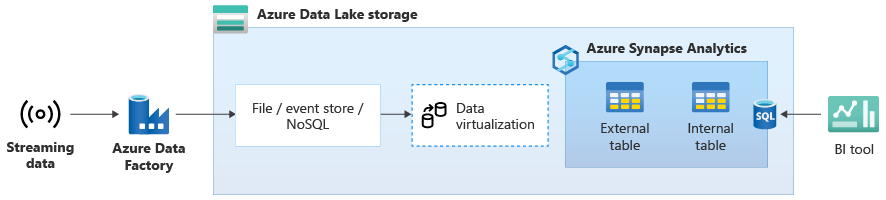
Tworzenie logicznego magazynu danych przy użyciu technologii PolyBase
Za pomocą technologii PolyBase można utworzyć logiczny magazyn danych, aby uprościć dostęp użytkowników do wielu magazynów danych analitycznych. Wiele firm przyjęło magazyny danych analitycznych "zoptymalizowane pod kątem obciążenia" w ciągu ostatnich kilku lat oprócz magazynów danych. Platformy analityczne na platformie Azure obejmują:
Usługa Data Lake Storage z notesem puli platformy Azure Synapse Spark (Spark jako usługa) na potrzeby analizy danych big data.
Usługa HDInsight (Hadoop jako usługa) również na potrzeby analizy danych big data.
Bazy danych NoSQL Graph do analizy grafów, które można wykonać w usłudze Azure Cosmos DB.
Event Hubs i Stream Analytics na potrzeby analizy danych w czasie rzeczywistym w ruchu.
Być może masz odpowiedniki tych platform innych niż Microsoft lub główny system zarządzania danymi (MDM), który musi mieć dostęp do spójnych zaufanych danych na klientach, dostawcach, produktach, zasobach i nie tylko.
Napiwek
Technologia PolyBase upraszcza dostęp do wielu bazowych magazynów danych analitycznych na platformie Azure w celu ułatwienia dostępu przez użytkowników biznesowych.
Te platformy analityczne pojawiły się z powodu eksplozji nowych źródeł danych w przedsiębiorstwie i poza nim oraz zapotrzebowania użytkowników biznesowych na przechwytywanie i analizowanie nowych danych. Nowe źródła danych obejmują:
Dane generowane przez maszynę, takie jak dane czujnika IoT i dane strumienia kliknięć.
Dane wygenerowane przez człowieka, takie jak dane sieci społecznościowej, przejrzyj dane witryny internetowej, przychodzącą wiadomość e-mail klienta, obrazy i wideo.
Inne dane zewnętrzne, takie jak otwarte dane rządowe i dane pogodowe.
Te nowe dane wykraczają poza ustrukturyzowane dane transakcji i główne źródła danych, które zwykle zawierają magazyny danych i często obejmują:
- Dane częściowo ustrukturyzowane, takie jak JSON, XML lub Avro.
- Dane bez struktury, takie jak tekst, głos, obraz lub wideo, które są bardziej złożone do przetwarzania i analizowania.
- Duże ilości danych, dane o dużej szybkości lub oba te dane.
W rezultacie pojawiły się nowe bardziej złożone rodzaje analizy, takie jak przetwarzanie języka naturalnego, analiza grafu, uczenie głębokie, analiza przesyłania strumieniowego lub złożona analiza dużych ilości danych strukturalnych. Tego rodzaju analizy zwykle nie są wykonywane w magazynie danych, więc nie jest zaskakujące, aby zobaczyć różne platformy analityczne dla różnych typów obciążeń analitycznych, jak pokazano na poniższym diagramie.
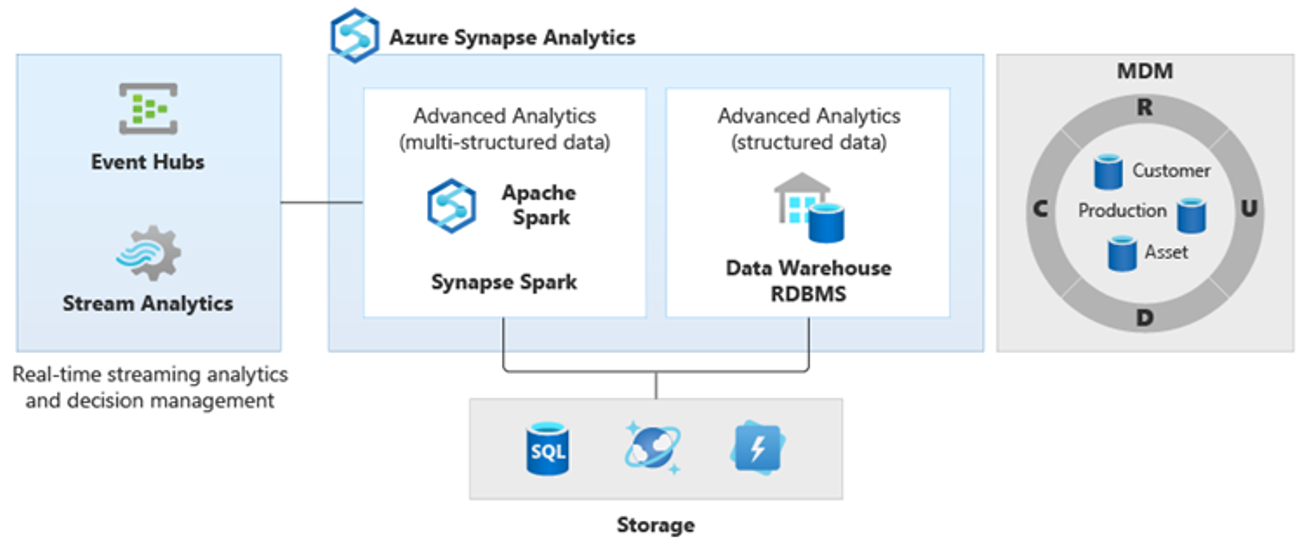
Napiwek
Możliwość tworzenia danych w wielu magazynach danych analitycznych wygląda podobnie do wszystkich w jednym systemie i dołączania ich do usługi Azure Synapse jest nazywana architekturą logicznego magazynu danych.
Ponieważ te platformy generują nowe szczegółowe informacje, normalne jest, aby zobaczyć wymaganie połączenia nowych szczegółowych informacji z tym, co już wiesz w usłudze Azure Synapse, co zapewnia technologia PolyBase.
Korzystając z wirtualizacji danych polyBase w usłudze Azure Synapse, można zaimplementować logiczny magazyn danych, w którym dane w usłudze Azure Synapse są przyłączone do danych w innych magazynach danych analitycznych platformy Azure i lokalnych magazynach danych analitycznych, takich jak HDInsight, Azure Cosmos DB lub dane przesyłane strumieniowo do usługi Data Lake Storage z usługi Stream Analytics lub Event Hubs. Takie podejście zmniejsza złożoność użytkowników, którzy uzyskują dostęp do tabel zewnętrznych w usłudze Azure Synapse i nie muszą wiedzieć, że dane, do których uzyskuje dostęp, są przechowywane w wielu podstawowych systemach analitycznych. Na poniższym diagramie przedstawiono złożoną strukturę magazynu danych dostępną stosunkowo prostszą, ale wciąż zaawansowaną metodę interfejsu użytkownika.
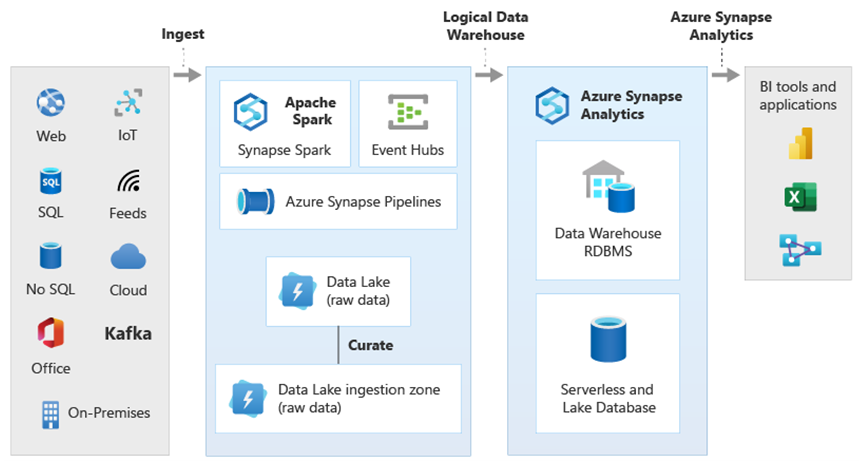
Na diagramie przedstawiono, w jaki sposób można połączyć inne technologie w ekosystemie analitycznym firmy Microsoft z możliwością architektury logicznego magazynu danych w usłudze Azure Synapse. Na przykład można pozyskiwać dane do usługi Data Lake Storage i przekształcać je przy użyciu usługi Data Factory w celu utworzenia zaufanych produktów danych reprezentujących jednostki danych logicznych bazy danych Usługi Microsoft Lake. Te zaufane, powszechnie zrozumiałe dane mogą być następnie używane i ponownie używane w różnych środowiskach analitycznych, takich jak azure Synapse, notesy puli Spark usługi Azure Synapse lub usługa Azure Cosmos DB. Wszystkie szczegółowe informacje utworzone w tych środowiskach są dostępne za pośrednictwem logicznej warstwy wirtualizacji danych magazynu danych, która jest możliwa przez program PolyBase.
Napiwek
Architektura logicznego magazynu danych upraszcza dostęp użytkowników biznesowych do danych i dodaje nową wartość do tego, co już znasz w magazynie danych.
Wnioski
Po przeprowadzeniu migracji magazynu danych do usługi Azure Synapse możesz skorzystać z innych technologii w ekosystemie analitycznym firmy Microsoft. Dzięki temu nie tylko zmodernizujesz magazyn danych, ale zapewniasz szczegółowe informacje utworzone w innych magazynach danych analitycznych platformy Azure w zintegrowanej architekturze analitycznej.
Przetwarzanie ETL można rozszerzyć w celu pozyskiwania danych dowolnego typu w usłudze Data Lake Storage, a następnie przygotować i zintegrować dane na dużą skalę przy użyciu usługi Data Factory, aby wygenerować zaufane, powszechnie zrozumiałe zasoby danych. Te zasoby mogą być używane przez magazyn danych i uzyskiwać do nich dostęp analitycy danych i inne aplikacje. Możesz tworzyć potoki analityczne zorientowane w czasie rzeczywistym i wsadowo oraz tworzyć modele uczenia maszynowego do uruchamiania w partiach, w czasie rzeczywistym na danych przesyłanych strumieniowo i na żądanie jako usługa.
Możesz użyć technologii PolyBase lub COPY INTO przejść poza magazyn danych, aby uprościć dostęp do szczegółowych informacji z wielu bazowych platform analitycznych na platformie Azure. W tym celu należy utworzyć całościowe zintegrowane widoki w logicznym magazynie danych, które obsługują dostęp do przesyłania strumieniowego, danych big data i tradycyjnych szczegółowych informacji magazynu danych z narzędzi i aplikacji analizy biznesowej.
Migrując magazyn danych do usługi Azure Synapse, możesz skorzystać z rozbudowanego ekosystemu analitycznego firmy Microsoft działającego na platformie Azure, aby zwiększyć nową wartość w firmie.
Następne kroki
Aby dowiedzieć się więcej na temat migracji do dedykowanej puli SQL, zobacz Migrowanie magazynu danych do dedykowanej puli SQL w usłudze Azure Synapse Analytics.